Benchmarking Frontier LLMs on Arabic Cultural and Sociolinguistic Knowledge: A Cross-Evaluation Framework with Human SME Ground Truth
Pith reviewed 2026-07-02 19:24 UTC · model grok-4.3
The pith
Human expert benchmarks show frontier LLMs fail automated grading of Arabic dialect responses primarily on tasks needing implicit cultural reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
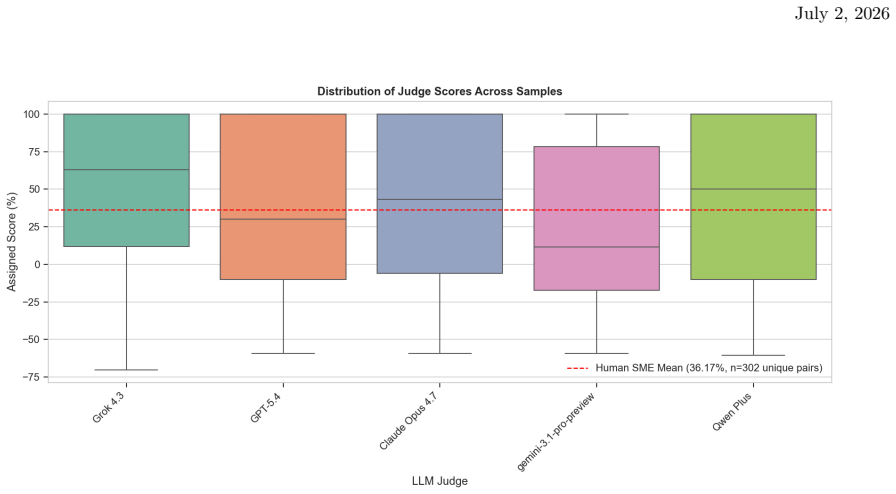
The central claim is that across all 1,307 judge evaluations, implicit cultural reasoning—which requires models to simulate native-speaker judgment rather than rely on lexical verification—emerges as the primary failure mode for automated grading across every judge model, with cultural tasks showing consistently higher Mean Absolute Deviation than linguistic tasks and four of five judges displaying systematic leniency.
What carries the argument
The cross-evaluation framework with penalty-weighted rubrics authored by native SMEs, paired with a dual-metric scheme of Mean Absolute Deviation and Signed Mean Error that isolates grading bias from symmetric noise.
If this is right
- Cultural tasks produce 1.83 to 4.78 percentage points higher MAD than linguistic tasks for all five judges.
- GPT-5.4 records the lowest MAD at 10.21 pp and near-zero signed error, making it the most reliable judge among those tested.
- Four of the five automated judges exhibit positive leniency ranging from +2.01% to +6.56%.
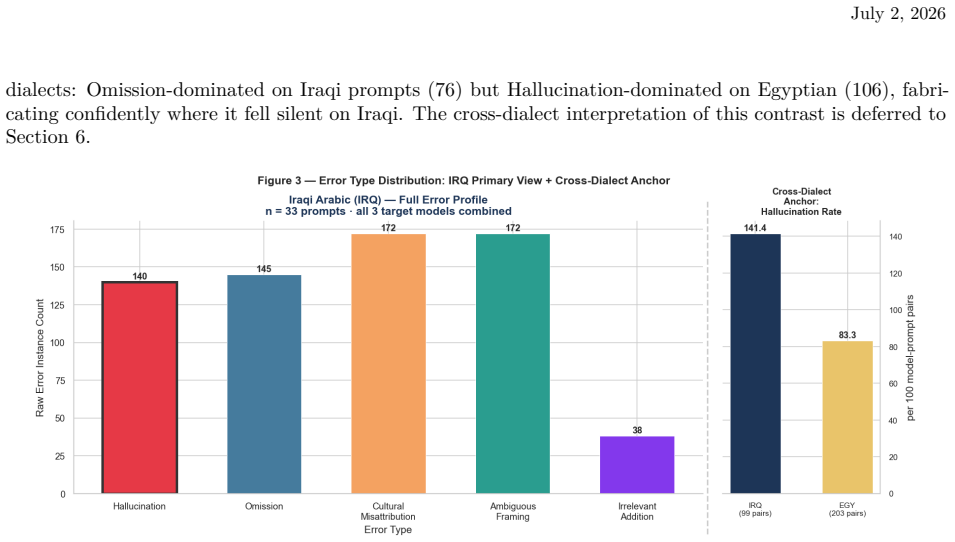
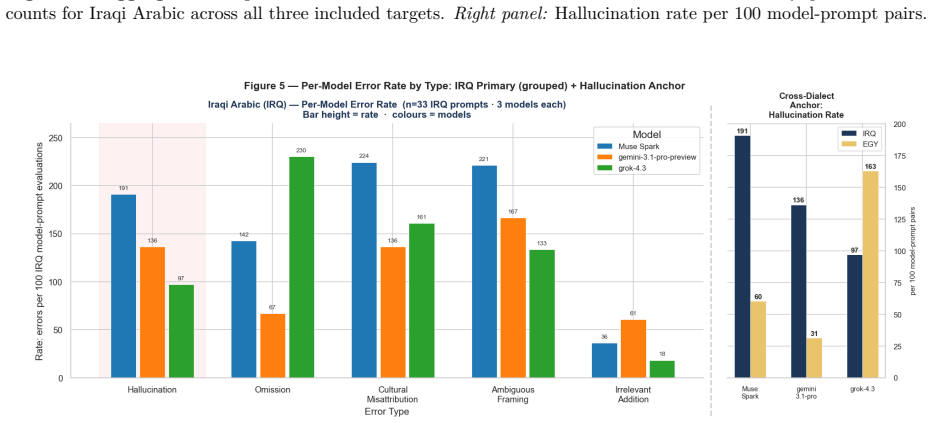
- Target models achieve substantially higher scores on Egyptian prompts than on Iraqi prompts, though SME leniency differences prevent direct attribution to knowledge gaps.
Where Pith is reading between the lines
- The same cultural-simulation gap may appear in LLM grading for other low-resource languages or dialects where native judgment cannot be reduced to surface patterns.
- Rubrics that explicitly probe for cultural inference rather than factual recall could reduce the observed failure mode in future automated judges.
- Extending the dual-metric scheme to track how grading bias changes when judges receive dialect-specific cultural priming would test whether the leniency pattern is removable.
- The framework highlights that lexical verification alone is insufficient for high-stakes cultural evaluation, implying that models need deeper internal representations of speaker perspective to serve as reliable graders.
Load-bearing premise
Human SME graders supply a stable, dialect-specific ground truth that can serve as a fixed reference, even though the paper records leniency differences between Iraqi and Egyptian experts.
What would settle it
A replication in which an independent set of native SMEs from the same dialects re-grades the same 302 prompt-response pairs and the failure pattern on implicit cultural reasoning either disappears or persists at the same rate.
Figures


read the original abstract
The cost of human expert evaluation is a principal bottleneck to deploying language models in specialized, high-stakes domains. This is particularly acute for Arabic sociolinguistic knowledge: credible grading requires not only linguistic fluency but deep cultural familiarity that cannot be approximated by surface-level metrics. We address this with a cross-evaluation framework instantiated on two underrepresented Arabic dialect communities: Egyptian and Iraqi Arabic. We contribute 103 validated prompt-rubric pairs (70 Egyptian, 33 Iraqi; 53 Cultural, 50 Linguistic), authored and graded by native-speaker SMEs using penalty-weighted rubrics distinguishing positive content requirements from answer-specific negative error criteria. Three frontier LLMs serve as target models (graded by human SMEs across 302 unique prompt-response pairs), while five frontier LLMs serve as automated judges enforcing a provider-level self-evaluation guard. A dual-metric scheme combining Mean Absolute Deviation (MAD) with Signed Mean Error separates directional grading bias from symmetric noise. Across 1,307 judge evaluations: GPT-5.4 is the most reliable judge (MADj = 10.21 pp, Signed Error = -1.12%); four of five judges show systematic leniency (+2.01% to +6.56%); Cultural tasks are harder to grade than Linguistic tasks for all judges (MAD gap 1.83-4.78 pp); and models substantially outperform on Egyptian prompts compared to Iraqi prompts. However, given leniency differences between Iraqi and Egyptian SMEs, we cannot solely attribute this gap to model knowledge. We therefore emphasize findings that do not assume identical leniency across human graders. Across all samples, implicit cultural reasoning -- requiring models to simulate native-speaker judgment rather than rely on lexical verification -- emerges as the primary failure mode for automated grading across all judge models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a cross-evaluation framework for benchmarking frontier LLMs on Arabic cultural and sociolinguistic knowledge using native-speaker SME ground truth for Egyptian and Iraqi dialects. It contributes 103 validated prompt-rubric pairs (distinguishing cultural and linguistic tasks), evaluates three target models on 302 prompt-response pairs, and deploys five LLMs as automated judges across 1,307 evaluations. A dual-metric approach (MAD and Signed Mean Error) is used to separate bias from noise. Findings include GPT-5.4 as the most reliable judge, systematic leniency in four of five judges, greater difficulty grading cultural tasks, dialect performance gaps (with caveats on SME leniency), and the identification of implicit cultural reasoning as the primary failure mode for automated grading.
Significance. If the human ground truth proves stable, the work provides a concrete, penalty-weighted rubric methodology and dual-metric scheme that could improve evaluation practices for culturally nuanced, high-stakes domains in underrepresented languages. The explicit separation of cultural vs. linguistic tasks and the provider-level self-evaluation guard are useful contributions; the empirical scale (1,307 evaluations) and restriction of some claims due to noted SME differences add credibility to the benchmarking approach.
major comments (2)
- [Abstract] Abstract (final paragraph): the central claim that 'implicit cultural reasoning ... emerges as the primary failure mode for automated grading across all judge models' is load-bearing yet rests on treating SME grades as a fixed reference that cleanly isolates cultural simulation failures from lexical ones. The same abstract notes leniency differences between Iraqi and Egyptian SMEs and states that performance gaps 'cannot be solely attributed to model knowledge,' but provides no inter-rater reliability statistics, dialect-stratified agreement figures, or rubric examples to bound reference noise. This directly risks confounding the diagnosed failure mode with grader variation.
- [Abstract] Abstract (methods description): the 103 validated pairs, 302 prompt-response pairs, and 1,307 judge evaluations are presented without raw data, error bars on MAD/Signed Error values, or full rubric examples. This makes it impossible to verify the dual-metric separation of directional bias from symmetric noise or to reproduce the cultural-vs-linguistic task distinction that underpins the failure-mode attribution.
minor comments (2)
- [Abstract] Notation such as 'MADj = 10.21 pp' and 'Signed Error = -1.12%' is introduced without an explicit definition of the 'j' subscript or the precise formula for Signed Mean Error in the abstract; a short methods subsection would clarify this.
- [Abstract] The split (70 Egyptian, 33 Iraqi; 53 Cultural, 50 Linguistic) is given but the validation process for the prompt-rubric pairs is not summarized, which would help readers assess the stability of the human reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major point below and outline revisions to improve clarity and verifiability while preserving the integrity of our reported findings.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the central claim that 'implicit cultural reasoning ... emerges as the primary failure mode for automated grading across all judge models' is load-bearing yet rests on treating SME grades as a fixed reference that cleanly isolates cultural simulation failures from lexical ones. The same abstract notes leniency differences between Iraqi and Egyptian SMEs and states that performance gaps 'cannot be solely attributed to model knowledge,' but provides no inter-rater reliability statistics, dialect-stratified agreement figures, or rubric examples to bound reference noise. This directly risks confounding the diagnosed failure mode with grader variation.
Authors: The manuscript explicitly caveats the dialect performance gap by noting SME leniency differences and restricts claims accordingly. The primary failure mode conclusion is drawn from qualitative review of disagreement cases where lexical cues were insufficient and cultural simulation was required, observed consistently across judges. We agree the abstract would benefit from tighter qualification of reference stability. In revision we will add a sentence bounding the claim, include one or two rubric examples, and report any available dialect-stratified agreement metrics from the SME validation process. revision: partial
-
Referee: [Abstract] Abstract (methods description): the 103 validated pairs, 302 prompt-response pairs, and 1,307 judge evaluations are presented without raw data, error bars on MAD/Signed Error values, or full rubric examples. This makes it impossible to verify the dual-metric separation of directional bias from symmetric noise or to reproduce the cultural-vs-linguistic task distinction that underpins the failure-mode attribution.
Authors: The full manuscript details the dual-metric computation (MAD for absolute deviation, Signed Mean Error for directional bias) and the cultural/linguistic task split in the methods and results sections. To improve verifiability we will insert error bars on the reported MAD and Signed Error statistics and add representative rubric examples (with the cultural vs. linguistic distinction illustrated) to the revised manuscript or an expanded appendix. Raw evaluation data will be offered via a data availability statement. revision: yes
Circularity Check
No circularity; empirical benchmarking against external human ground truth
full rationale
The paper describes a standard empirical benchmarking setup: 103 prompt-rubric pairs authored and graded by native-speaker SMEs, 302 prompt-response pairs evaluated by three target LLMs, and 1,307 automated judge evaluations compared via MAD and Signed Mean Error. All metrics are computed directly from the external human grades; no equations, fitted parameters, or predictions are defined in terms of the target results. The abstract explicitly notes leniency differences between Iraqi and Egyptian SMEs and restricts attribution accordingly, without invoking self-citations, uniqueness theorems, or ansatzes. The central observation on implicit cultural reasoning as a failure mode is an observational summary of the judge-human discrepancies, not a derivation that reduces to the inputs by construction. The work is self-contained against independent human benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Native-speaker SMEs provide reliable, low-bias ground truth for cultural and sociolinguistic tasks
Reference graph
Works this paper leans on
-
[1]
Towards measuring and modeling “culture” in LLMs: A survey
Muhammad Farid Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Singh, Alham Fikri Aji, Jacki O’Neill, Ashutosh Modi, and Monojit Choudhury. Towards measuring and modeling “culture” in LLMs: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15763–15784, 2024
2024
-
[2]
Fluent but foreign: Even regional LLMs lack cultural alignment
Dhruv Agarwal et al. Fluent but foreign: Even regional LLMs lack cultural alignment. arXiv preprint arXiv:2505.21548, 2026
-
[3]
PalmX 2025: The first shared task on benchmarking LLMs on arabic and islamic culture
Marwah Alwajih et al. PalmX 2025: The first shared task on benchmarking LLMs on arabic and islamic culture. In Proceedings of the Third Arabic Natural Language Processing Conference (ArabicNLP 2025) , 2025
2025
-
[4]
How reliable is multilingual LLM-as-a-judge? In Findings of the Association for Computational Linguistics: EMNLP 2025 , pages 11040–11053, Suzhou, China, 2025
Xiyan Fu and Wei Liu. How reliable is multilingual LLM-as-a-judge? In Findings of the Association for Computational Linguistics: EMNLP 2025 , pages 11040–11053, Suzhou, China, 2025. Association for Computational Linguistics
2025
-
[5]
Cultivating pluralism in algorithmic monoculture: The com- munity alignment dataset
Lester Hayes Zhang, Smitha Milli, et al. Cultivating pluralism in algorithmic monoculture: The com- munity alignment dataset. arXiv preprint arXiv:2507.09650 , 2025
-
[6]
Challenges and strategies in cross-cultural NLP
Daniel Hershcovich, Stella Frank, Heather Lent, Miryam de Lhoneux, Mostafa Abdou, Stephanie Brandl, Emanuele Bugliarello, Laura Cabello Piqueras, Ilias Chalkidis, Ruixiang Cui, Constanza Fierro, Katerina Margatina, Phillip Rust, and Anders Søgaard. Challenges and strategies in cross-cultural NLP. In Proceedings of the 60th Annual Meeting of the Associatio...
2022
-
[7]
Culturally aware natural language inference
Jing Huang and Diyi Yang. Culturally aware natural language inference. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 7591–7609, 2023
2023
-
[8]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models. In The Twelfth International Conference on Learning Representations , 2024
2024
-
[9]
Prometheus 2: An open source language model specialized in evaluating other language models
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , 2024
2024
-
[10]
Sunzhu Li, Jiale Zhao, Miteto Wei, Huimin Ren, Yang Zhou, Jingwen Yang, Shunyu Liu, Kaike Zhang, and Wei Chen. RubricHub: A comprehensive and highly discriminative rubric dataset via automated coarse-to-fine generation. arXiv preprint arXiv:2601.08430 , 2026. Benchmarking Frontier LLMs on Arabic Cultural and Sociolinguistic Knowledge: A Cross-Evaluation F...
-
[11]
BLEnD: A benchmark for LLMs on everyday knowledge in diverse cultures and languages
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki Afina Putri, Alice Oh, et al. BLEnD: A benchmark for LLMs on everyday knowledge in diverse cultures and languages. In Advances in Neural Information Processing Systems, 2024
2024
-
[12]
Culture is every- where: A call for intentionally cultural evaluation
Juhyun Oh, Inha Cha, Michael Saxon, Hyunseung Lim, Shaily Bhatt, and Alice Oh. Culture is every- where: A call for intentionally cultural evaluation. In Findings of the Association for Computational Linguistics: EMNLP 2025 , pages 19156–19168, 2025
2025
-
[13]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel R. Bowman. BBQ: A hand-built bias benchmark for question answering. In Findings of the Association for Computational Linguistics: ACL 2022 , pages 2086–2105, 2022
2022
-
[14]
CamelEval: Advancing culturally aligned arabic language models and benchmarks
Zhaozhi Qian, Faroq Altam, Muhammad Alqurishi, and Riad Souissi. CamelEval: Advancing culturally aligned arabic language models and benchmarks. arXiv preprint arXiv:2409.12623 , 2024
-
[15]
NormAd: A framework for measuring the cultural adaptability of large language models
Abhinav Rao, Akhila Yerukola, Vishwa Shah, Katharina Reinecke, and Maarten Sap. NormAd: A framework for measuring the cultural adaptability of large language models. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages 2373–2403, 2025
2025
-
[16]
Multilingual ̸= multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs
Jonathan Rystrøm, Hannah Rose Kirk, and Scott Hale. Multilingual ̸= multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs. In Proceedings of the OMMM Work- shop 2025 , pages 74–85, 2025
2025
-
[17]
The culture funnel: You can’t align what isn’t in the data
Ananya Sahu, Mehrnaz Mofakhami, Daniel D’Souza, Thomas Euyang, Julia Kreutzer, and Marzieh Fadaee. The culture funnel: You can’t align what isn’t in the data. arXiv preprint arXiv:2606.13808 , 2026
-
[18]
CultureBank: An online community-driven knowledge base towards culturally aware language technologies
Weiyan Shi, Ryan Li, Yutong Zhang, Caleb Ziems, Chunhua Yu, Raya Horesh, Rogério Abreu de Paula, and Diyi Yang. CultureBank: An online community-driven knowledge base towards culturally aware language technologies. In Findings of the Association for Computational Linguistics: EMNLP 2024 , 2024
2024
-
[19]
arXiv preprint arXiv:2503.23829 (2025) 5 20 J
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. Cross- ing the reward bridge: Expanding RL with verifiable rewards across diverse domains. arXiv preprint arXiv:2503.23829, 2025
-
[20]
Mind the gap in cultural alignment: Task-aware culture management for large language models
Binchi Zhang et al. Mind the gap in cultural alignment: Task-aware culture management for large language models. arXiv preprint arXiv:2602.22475 , 2026
-
[21]
CultureScope: A dimensional lens for probing cultural understanding in LLMs
Jinghao Zhang et al. CultureScope: A dimensional lens for probing cultural understanding in LLMs. arXiv preprint arXiv:2509.16188 , 2025
-
[22]
Chasing the tail: Effective rubric-based reward modeling for large language model post-training
Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric-based reward modeling for large language model post-training. In The Thirteenth International Conference on Learning Representations, 2026
2026
-
[23]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM- as-a-judge with MT-Bench and chatbot arena. In Advances in Neural Information Processing Systems , volume 36, 2023
2023
-
[24]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. MT-Bench: A multi-turn benchmark for evaluating chat LLMs. In Advances in Neural Information Processing Systems , volume 36, 2023. Benchmarking Frontier LLMs on Arabic Cultural ...
2023
-
[25]
Temperature is set to 0 for all calls; no other sampling parameters are varied
Judge Prompt All judge calls use the following fixed system prompt and user message template. Temperature is set to 0 for all calls; no other sampling parameters are varied. System Prompt You are an expert Subject Matter Expert (SME) in Arabic Sociolinguistics and Dialects. You will be provided with a PROMPT, an ANSWER generated by an AI model, and a grad...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.