Query-Centric Optimization of AI Workflows via Approximate Query Processing and Proxy Models
Pith reviewed 2026-07-02 16:35 UTC · model grok-4.3
The pith
AI workflows can be reframed as database queries so that sampling and lightweight filters cut expensive model calls by 50-90 percent with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
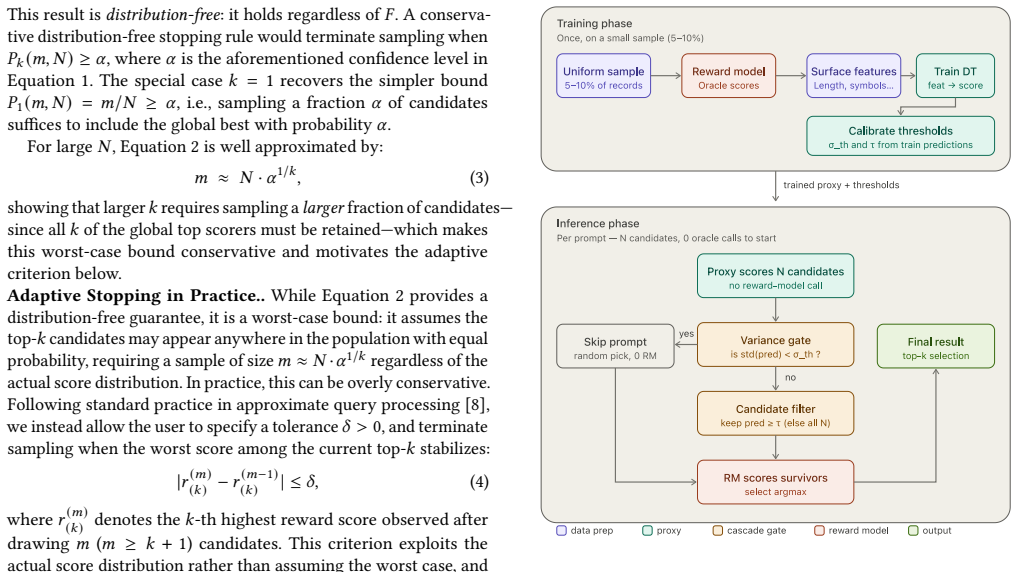
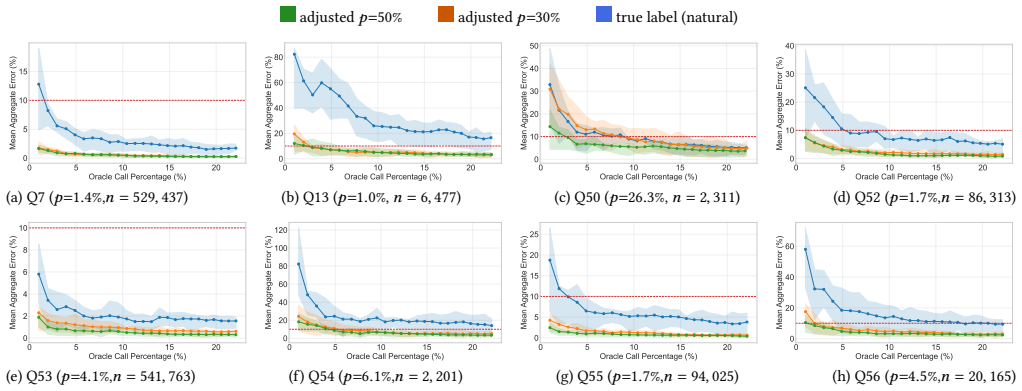
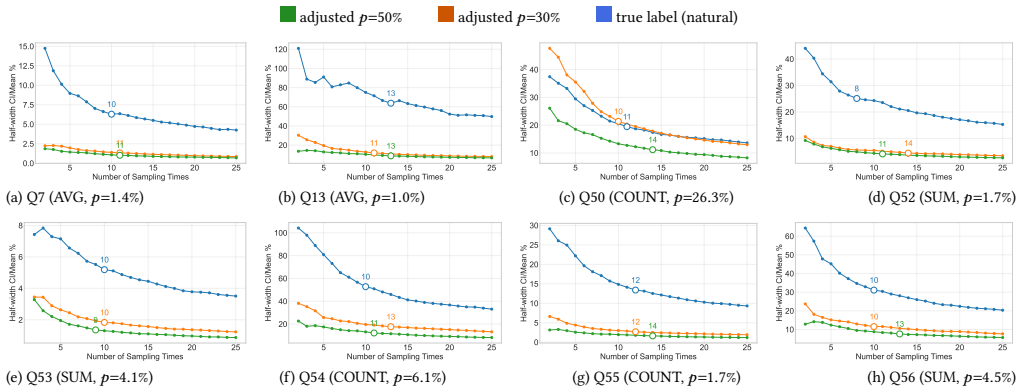
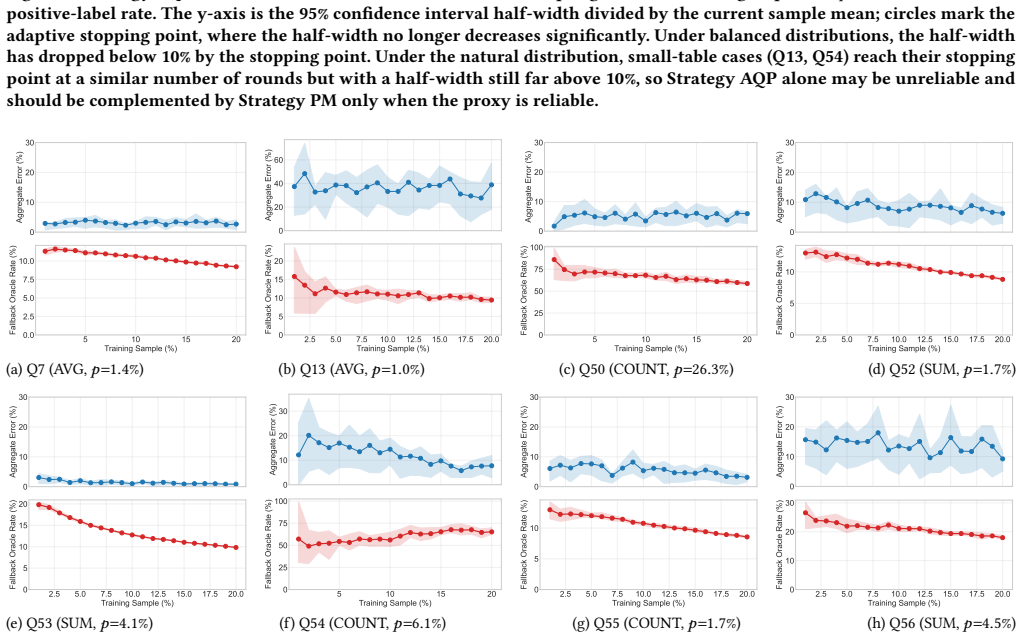
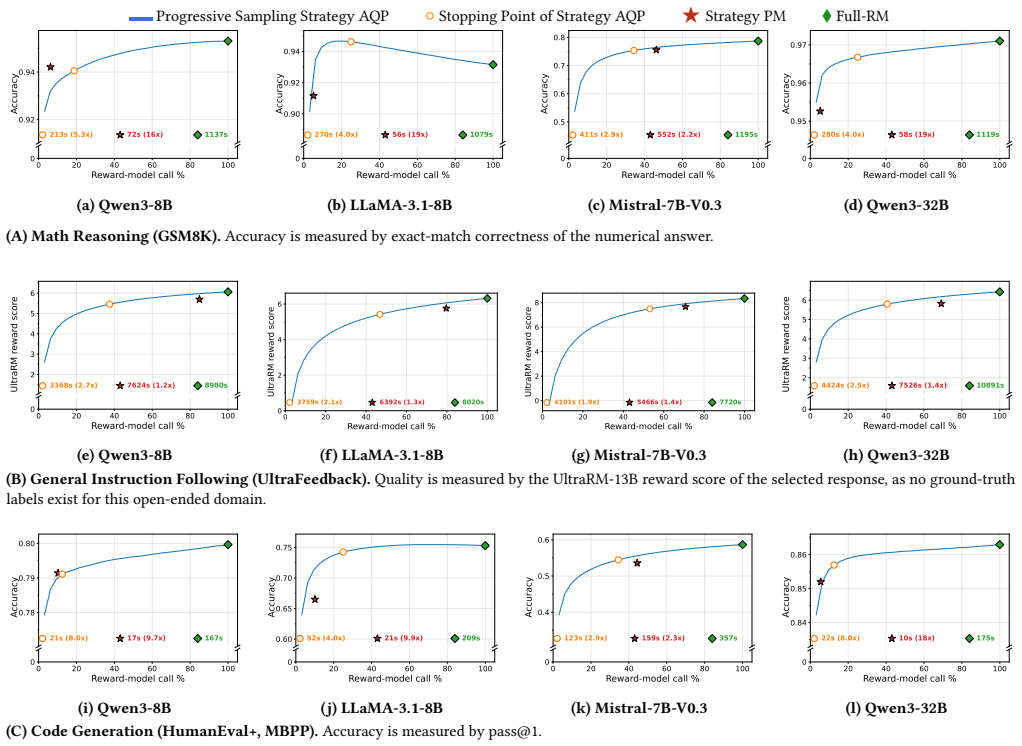
Treating AI workflows as declarative queries whose expensive predicate is a large model lets approximate query processing maintain a running aggregate with confidence intervals and stop once the interval lies inside a user-specified error bound; a second technique trains a CPU-resident decision tree on a modest set of oracle-labeled examples and routes only uncertain records to the model. On TPC-DS the AQP strategy reaches its stopping point at 10-15 percent of oracle calls under balanced distributions while keeping aggregate error below 10 percent, while the proxy-model strategy reduces calls by 60-70 percent. On LLM pipelines the AQP strategy stops at 20-50 percent of calls with less than
What carries the argument
The query-centric formulation that casts the workflow as an online aggregation problem or a pre-filtering problem solvable by a lightweight decision tree.
If this is right
- Aggregate queries over LLM outputs can terminate after a small fraction of evaluations once the confidence interval stabilizes.
- Lightweight decision trees can pre-filter records whose outcome is predictable, routing only uncertain cases to the expensive model.
- The same reductions apply across both structured tasks such as math and code generation and open-ended scoring by reward models.
- No modification to the underlying models or pipelines is required to obtain the reported savings.
Where Pith is reading between the lines
- The same sampling and proxy-filter logic could be applied to other expensive black-box functions such as physics simulators or chemical property predictors.
- Adaptive stopping points may allow agentic systems to allocate compute dynamically across many parallel reasoning branches.
- The approach suggests that database-style query optimizers could be extended to treat model calls as first-class expensive operators.
Load-bearing premise
AI workflows can be expressed as declarative queries with expensive predicates evaluated by large models or reward functions.
What would settle it
An experiment that re-expresses a real LLM pipeline as a query yet finds that early stopping or proxy filtering changes final accuracy or behavior in ways that cannot be restored by adjusting the error bound.
Figures


read the original abstract
Many modern AI workflows, ranging from LLM post-training pipelines to agentic reasoning tasks, can be expressed as declarative queries whose expensive predicate is evaluated by a large model or reward function. We propose a query-centric formulation of these workflows and show that classical database techniques, namely approximate query processing (AQP) and proxy-model (PM) based filtering, can substantially reduce the number of expensive model invocations without requiring changes to the underlying models or pipelines. Our first strategy treats the workflow as an online aggregation problem: it progressively samples records, maintains a running aggregate estimate with a confidence interval, and terminates early once the interval stabilizes, accepting the estimate when it falls within a user-specified error bound. Our second strategy trains a lightweight, CPU-resident decision tree on a small set of oracle-labeled examples and uses it to pre-filter records whose outcome can be predicted with high confidence, routing only uncertain records to the expensive model. We evaluate both strategies on TPC-DS aggregate queries and on real LLM post-training pipelines including math reasoning, general instruction following, and code generation. On TPC-DS, Strategy AQP keeps aggregate error under 10% while reaching its adaptive stopping point at 10-15% of oracle calls under balanced distributions, an 85-90% reduction, and Strategy PM reduces oracle calls by 60-70%. On LLM pipelines, Strategy AQP reaches its adaptive stopping point at 20-50% of oracle calls with less than 5% accuracy loss on the structured math and code tasks; open-ended instruction following, scored by a reward model, shows a larger but bounded reduction. Strategy PM reduces reward-model scoring time by up to 19x on structured tasks with less than 10% accuracy loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that many AI workflows (LLM post-training, agentic reasoning) can be expressed as declarative queries whose expensive predicates are evaluated by large models or reward functions. It applies two classical database techniques without pipeline changes: (1) approximate query processing (AQP) via online aggregation that samples records, maintains a running estimate with confidence interval, and stops early once the interval meets a user-specified error bound; (2) proxy-model (PM) filtering that trains a lightweight decision tree on a small oracle-labeled set and routes only uncertain records to the expensive model. On TPC-DS, AQP reaches stopping at 10-15% of oracle calls (85-90% reduction) with aggregate error <10% under balanced distributions while PM reduces calls by 60-70%; on LLM pipelines, AQP reaches stopping at 20-50% of calls with <5% accuracy loss on structured math/code tasks and PM yields up to 19x reduction on structured tasks with <10% loss.
Significance. If the central claims hold, the work demonstrates a practical transfer of AQP and proxy-model techniques from databases to AI workflow optimization, yielding concrete, large reductions in expensive model invocations on both TPC-DS and real LLM post-training pipelines. The empirical reporting of bounded error together with the adaptive, user-specified error control in AQP and the CPU-resident PM are strengths that would make the results actionable for practitioners.
major comments (1)
- [Abstract] Abstract: the claim that the techniques apply 'without requiring changes to the underlying models or pipelines' is load-bearing for the contribution. The abstract states that agentic reasoning tasks can be expressed as declarative queries over records, yet provides no concrete mapping or section showing how stateful, sequential control flow is cast as a static batch query over independent records; if the wrapper alters the original pipeline, the 'no changes' guarantee does not hold for the full scope of claimed workflows.
minor comments (2)
- [Abstract] Abstract: the phrase 'balanced distributions' for the TPC-DS 85-90% reduction is used without defining the data distribution or how balance was ensured.
- [Abstract] Abstract: the LLM accuracy-loss figures (<5%, <10%) are reported without stating the precise metric (e.g., exact-match, reward-model score) or the baseline used for comparison.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of the 'no pipeline changes' claim. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the techniques apply 'without requiring changes to the underlying models or pipelines' is load-bearing for the contribution. The abstract states that agentic reasoning tasks can be expressed as declarative queries over records, yet provides no concrete mapping or section showing how stateful, sequential control flow is cast as a static batch query over independent records; if the wrapper alters the original pipeline, the 'no changes' guarantee does not hold for the full scope of claimed workflows.
Authors: We agree that a concrete mapping for agentic workflows would strengthen the presentation. The manuscript's core contribution and all reported experiments concern batch-style workflows (TPC-DS aggregates and LLM post-training pipelines) that are already expressible as declarative queries over independent records. For agentic reasoning, the intended formulation treats individual decision steps as record-level predicates that can be batched; the wrapper is a thin query interface that leaves the underlying models and pipeline execution unchanged. We will add a short illustrative subsection (new Section 3.3) showing a minimal agentic loop reformulated as a static query, together with a brief discussion of the scope of workflows to which the 'no changes' guarantee applies. revision: yes
Circularity Check
No significant circularity; empirical application of known AQP/PM techniques
full rationale
The paper applies classical database techniques (online aggregation with CI early stopping; decision-tree proxy filtering) to AI workflows cast as declarative queries. All reported savings (e.g., 85-90% oracle reduction on TPC-DS, 20-50% on LLM tasks) are presented as direct experimental outcomes on TPC-DS and specific LLM pipelines rather than as predictions derived from fitted parameters or self-citations. No equations, self-definitional reductions, or load-bearing self-citations appear in the provided text; the central mapping assumption is stated explicitly but does not reduce any quantitative claim to a tautology or prior author result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mistral AI. 2024. Mistral-7B-v0.3. https://huggingface.co/mistralai/Mistral-7B- v0.3. Apache 2.0 License
2024
-
[2]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Gonzalez, Carlos Guestrin, and Matei Zaharia
Asim Biswal, Liana Patel, Siddarth Jha, Amog Kamsetty, Shu Liu, Joseph E. Gonzalez, Carlos Guestrin, and Matei Zaharia. 2024. Text2SQL is Not Enough: Unifying AI and Databases with TAG. arXiv:2408.14717 [cs.DB] https://arxiv. org/abs/2408.14717
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.Transactions on Machine Learning Research(2024)
2024
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2023. UltraFeedback: Boosting Language Models with High-quality Feedback. arXiv:2310.01377 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Joseph M. Hellerstein, Peter J. Haas, and Helen J. Wang. 1997. Online aggregation. SIGMOD Rec.26, 2 (June 1997), 171–182. https://doi.org/10.1145/253262.253291
-
[9]
Gaurav Tarlok Kakkar, Jiashen Cao, Aubhro Sengupta, Joy Arulraj, and Hyesoon Kim. 2025. Aero: Adaptive Query Processing of ML Queries.Proc. ACM Manag. Data3, 3, Article 174 (June 2025), 27 pages. https://doi.org/10.1145/3725408
- [10]
-
[11]
Daniel Kang, Peter Bailis, and Matei Zaharia. 2019. BlazeIt: optimizing declar- ative aggregation and limit queries for neural network-based video analytics. Proc. VLDB Endow.13, 4 (Dec. 2019), 533–546. https://doi.org/10.14778/3372716. 3372725
-
[12]
Daniel Kang, John Emmons, Firas Abuzaid, Peter Bailis, and Matei Zaharia. 2017. NoScope: optimizing neural network queries over video at scale.Proc. VLDB Endow.10, 11 (Aug. 2017), 1586–1597. https://doi.org/10.14778/3137628.3137664
- [13]
-
[14]
Bailis, Tatsunori Hashimoto, and Matei Zaharia
Daniel Kang, John Guibas, Peter D. Bailis, Tatsunori Hashimoto, and Matei Zaharia. 2022. TASTI: Semantic Indexes for Machine Learning-Based Queries over Unstructured Data. InProceedings of the 2022 International Conference on Management of Data(Philadelphia, PA, USA)(SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 1934–1947. https://d...
-
[15]
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. 2025. Rewardbench: Evaluating reward models for language modeling. InFindings of the Association for Computational Linguistics: NAACL 2025. 1755–1797
2025
-
[16]
Feifei Li, Bin Wu, Ke Yi, and Zhuoyue Zhao. 2016. Wander join: Online aggre- gation via random walks. InProceedings of the 2016 International Conference on Management of Data. 615–629
2016
-
[17]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, 74–81
2004
-
[18]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. InThirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=1qvx610Cu7
2023
-
[19]
Yao Lu, Aakanksha Chowdhery, Srikanth Kandula, and Surajit Chaudhuri. 2018. Accelerating Machine Learning Inference with Probabilistic Predicates. InPro- ceedings of the 2018 International Conference on Management of Data(Houston, TX, USA)(SIGMOD ’18). Association for Computing Machinery, New York, NY, USA, 1493–1508. https://doi.org/10.1145/3183713.3183751
-
[20]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS.Proc. VLDB Endow.18, 11 (July 2025), 4171–4184. https://doi.org/10.14778/3749646. 3749685
- [21]
-
[22]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (May 2025), 3035–3048. https: //doi.org/10.14778/3746405.3746426
-
[23]
Shreya Shankar, Sepanta Zeighami, and Aditya Parameswaran. 2026. Task Cascades for Efficient Unstructured Data Processing.Proc. ACM Manag. Data4, 1, Article 88 (April 2026), 26 pages. https://doi.org/10.1145/3786702
-
[24]
Bartlett, and Andrea Zanette
Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter L. Bartlett, and Andrea Zanette. 2024. Fast best-of-N decod- ing via speculative rejection. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Art...
2024
-
[25]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288 [cs.CL] https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Sean Wang
Zhihui Yang, Zuozhi Wang, Yicong Huang, Yao Lu, Chen Li, and X. Sean Wang
-
[28]
VLDB Endow.15, 10 (June 2022), 2032–2044
Optimizing machine learning inference queries with correlative proxy models.Proc. VLDB Endow.15, 10 (June 2022), 2032–2044. https://doi.org/10. 14778/3547305.3547310 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.