Validating Causal Abstraction Metrics on Simulated Complex Systems
Pith reviewed 2026-07-02 19:21 UTC · model grok-4.3
The pith
Only causal metrics that include faithfulness testing over unmapped variables reliably discriminate valid from invalid abstractions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within a unified causal abstraction framework, systematic evaluation on ten benchmark systems shows that only causal metrics incorporating faithfulness testing over unmapped variables reliably discriminate valid from invalid abstractions; the introduced Causal Abstraction Error passes all discrimination tests across every system and converges with as few as 30 sampled interventions.
What carries the argument
The Causal Abstraction Error (CAE), a continuous validity metric that includes an explicit faithfulness test over unmapped variables.
If this is right
- Causal metrics without the faithfulness component fail to discriminate valid and invalid abstractions.
- Observational, functional, and information-theoretic metrics do not reliably separate the two across the tested systems.
- The CAE works for both discrete and continuous state spaces as well as static and dynamical regimes.
- Validating a high-level explanation with CAE requires only a small number of interventions.
Where Pith is reading between the lines
- The benchmark could serve as a standard testbed for developing new abstraction discovery methods that aim for faithfulness.
- Metrics validated here might be adapted to evaluate explanations in domains where ground-truth causal structure is partially known.
- If the faithfulness test is key, then abstraction methods should explicitly optimize or verify coverage of all lower-level variables.
Load-bearing premise
The ten simulated systems have ground-truth causal explanations that are verifiably valid while the contrastive conditions are verifiably invalid.
What would settle it
Finding that a metric without faithfulness testing over unmapped variables successfully discriminates valid from invalid abstractions on all ten systems would falsify the main result.
Figures



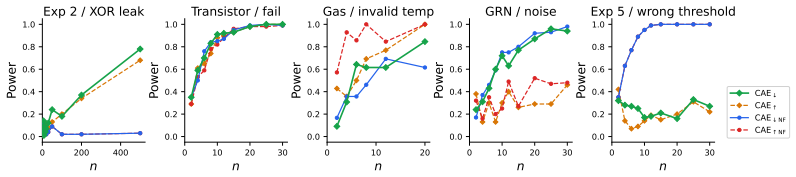

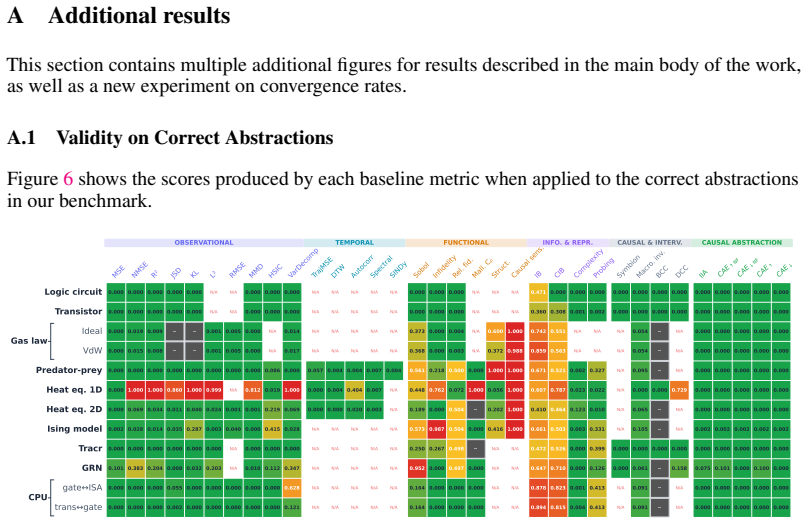
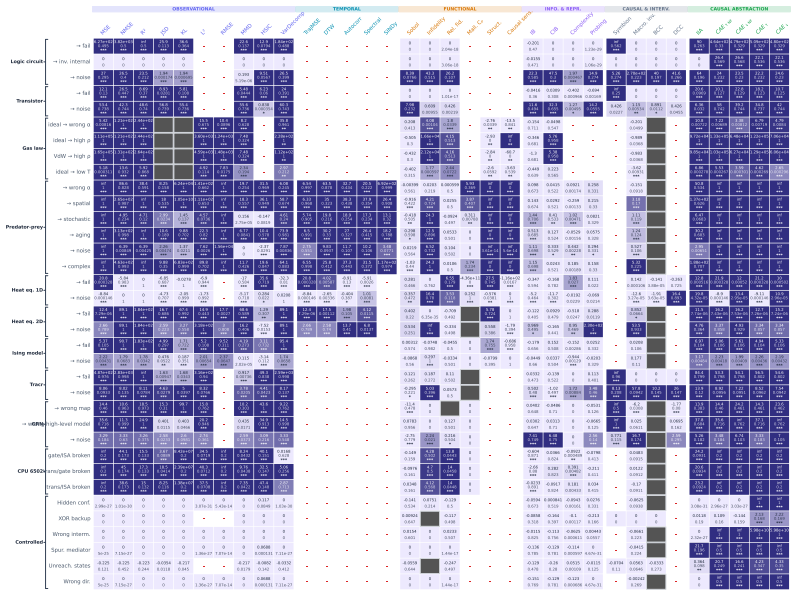


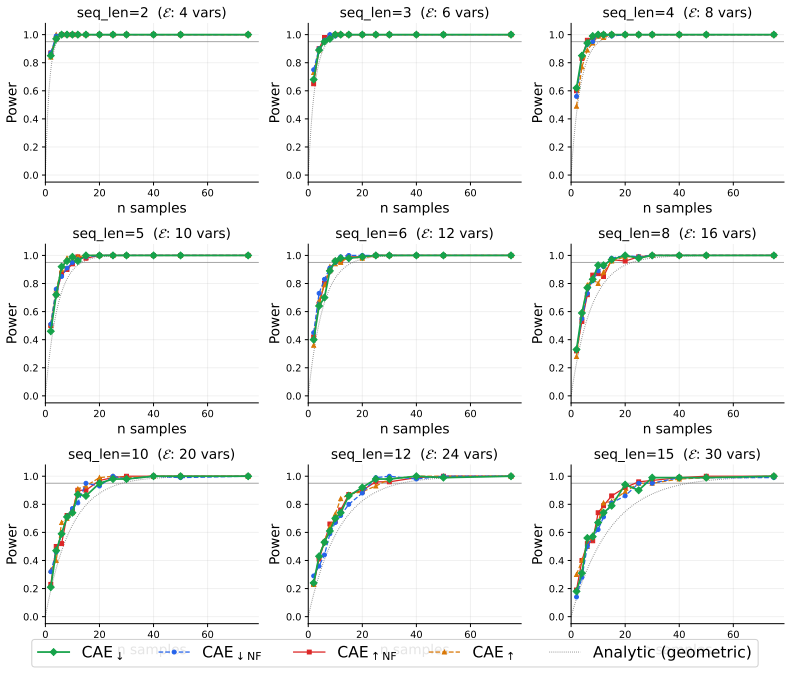
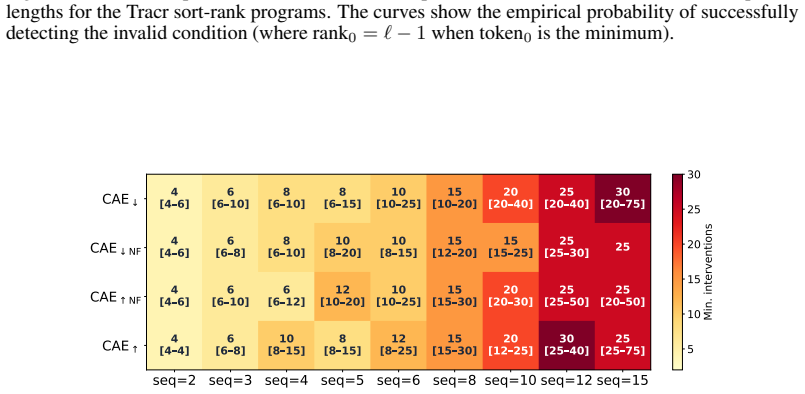

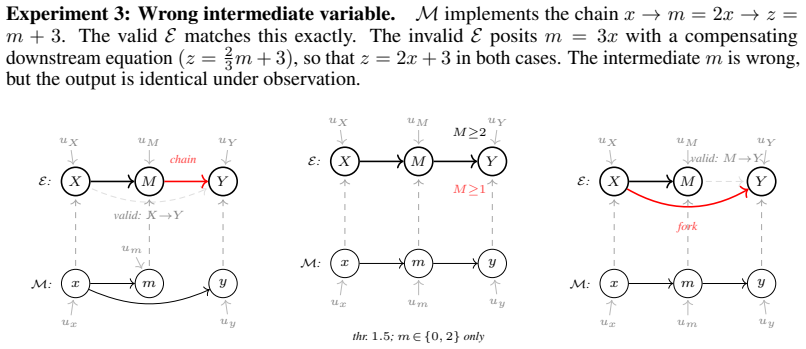
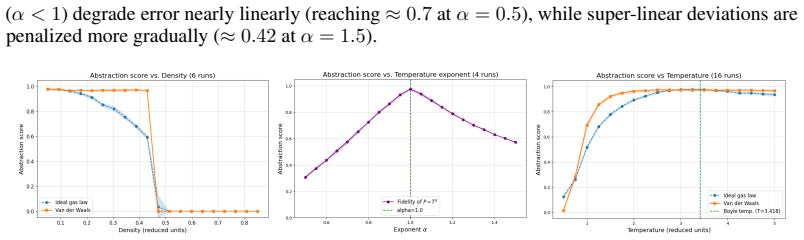
read the original abstract
A central goal of science is to produce valid explanations of complex systems: high-level causal accounts that faithfully reflect the behavior of lower-level mechanisms. Yet no consensus exists on how to measure whether a proposed high-level explanation is actually valid. We introduce a benchmark of ten complex systems spanning both discrete and continuous state spaces, as well as static and dynamical regimes, each equipped with consensual ground-truth causal explanations and invalid contrastive conditions. Within a unified causal abstraction framework, we systematically evaluate over thirty candidate metrics drawn from observational, functional, information-theoretic, and causal families. Our results show that only the latter reliably discriminates valid from invalid abstractions, and only when incorporating faithfulness testing over unmapped variables. Building on these findings, we introduce the Causal Abstraction Error (CAE), a continuous validity metric with an explicit faithfulness test, which passes all discrimination tests across every system and can converge with as few as 30 sampled interventions. We offer it as a general-purpose metric for the discovery and validation of high-level explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark of ten simulated complex systems (discrete/continuous, static/dynamical) each equipped with consensual ground-truth causal explanations and invalid contrastive conditions. Within a unified causal abstraction framework it evaluates over thirty metrics from observational, functional, information-theoretic, and causal families, reports that only causal metrics incorporating faithfulness testing over unmapped variables reliably discriminate valid from invalid abstractions, and introduces the Causal Abstraction Error (CAE) as a continuous validity metric with explicit faithfulness testing that passes all discrimination tests and converges with as few as 30 sampled interventions.
Significance. If the discrimination results are supported by the data and the ground-truth labels are verifiably objective, the work would supply a concrete, empirically validated metric for high-level causal explanations together with a reusable benchmark spanning multiple regimes; this would be a useful contribution to causal abstraction research in machine learning and scientific modeling. The systematic comparison across thirty metrics and the emphasis on faithfulness testing are positive elements.
major comments (3)
- [Benchmark construction] Benchmark construction section: the manuscript repeatedly invokes 'consensual ground-truth causal explanations' and 'verifiably invalid contrastive conditions' as the basis for all discrimination tests, yet supplies no construction protocol, expert validation procedure, or sensitivity analysis for these labels. Because the central claim (that only faithfulness-testing causal metrics discriminate) rests entirely on the correctness of these externally supplied labels, the absence of this protocol is load-bearing.
- [Results and evaluation] Results and evaluation sections: the abstract asserts that CAE 'passes all discrimination tests across every system' and that only causal metrics with faithfulness testing succeed, but the manuscript provides neither quantitative tables of discrimination performance, statistical significance tests, nor implementation details for the thirty metrics or the ten system generators. Without these, the comparative claims cannot be assessed.
- [CAE definition] CAE definition (presumably §4 or Eq. defining the metric): the paper states that CAE includes an explicit faithfulness test over unmapped variables and converges with 30 interventions, but does not report the precise functional form, the sampling procedure for interventions, or any ablation showing that the faithfulness component is necessary for the reported discrimination performance.
minor comments (2)
- [Metric taxonomy] Notation for the thirty metrics is introduced without a consolidated table mapping each metric to its family and whether it includes a faithfulness test; this makes the 'only causal metrics...' claim harder to trace.
- [Reproducibility statement] The manuscript does not state whether code or system generators will be released; given the emphasis on a reusable benchmark, this should be clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important areas where additional clarity and documentation are needed to support the central claims. We address each major comment below and commit to revisions that will make the supporting evidence fully accessible and verifiable.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the manuscript repeatedly invokes 'consensual ground-truth causal explanations' and 'verifiably invalid contrastive conditions' as the basis for all discrimination tests, yet supplies no construction protocol, expert validation procedure, or sensitivity analysis for these labels. Because the central claim (that only faithfulness-testing causal metrics discriminate) rests entirely on the correctness of these externally supplied labels, the absence of this protocol is load-bearing.
Authors: We agree that explicit documentation of the ground-truth label construction is essential. The original manuscript relied on an implicit protocol described only at a high level. In the revision we will add a dedicated subsection (and supplementary material) that details the exact construction protocol, the criteria used to obtain consensual labels, any expert validation steps performed, and sensitivity analyses that test robustness of the discrimination results to plausible perturbations of the ground-truth assignments. revision: yes
-
Referee: [Results and evaluation] Results and evaluation sections: the abstract asserts that CAE 'passes all discrimination tests across every system' and that only causal metrics with faithfulness testing succeed, but the manuscript provides neither quantitative tables of discrimination performance, statistical significance tests, nor implementation details for the thirty metrics or the ten system generators. Without these, the comparative claims cannot be assessed.
Authors: We accept that the current presentation does not allow independent assessment of the comparative claims. The revision will include (i) full quantitative tables reporting discrimination performance (accuracy, AUC, or equivalent) for all thirty metrics across the ten systems, (ii) statistical significance tests (with correction for multiple comparisons) comparing causal versus non-causal families, and (iii) a new appendix containing complete implementation details, hyper-parameters, and code references for every metric and every system generator so that the experiments are fully reproducible. revision: yes
-
Referee: [CAE definition] CAE definition (presumably §4 or Eq. defining the metric): the paper states that CAE includes an explicit faithfulness test over unmapped variables and converges with 30 interventions, but does not report the precise functional form, the sampling procedure for interventions, or any ablation showing that the faithfulness component is necessary for the reported discrimination performance.
Authors: We agree that the precise definition, sampling procedure, and necessity of the faithfulness component must be documented. The revised manuscript will (a) state the exact functional form of CAE (including the faithfulness penalty term), (b) specify the intervention sampling procedure and convergence diagnostics, and (c) add an ablation study that isolates the contribution of the faithfulness test by comparing CAE with and without that component on the same benchmark. These additions will appear in the main text and an expanded methods section. revision: yes
Circularity Check
No significant circularity; evaluation uses external ground-truth labels from simulations
full rationale
The paper supplies a benchmark of ten simulated systems, each equipped with pre-existing consensual ground-truth causal explanations and invalid contrasts. All metric evaluations, discrimination tests, and the endorsement of CAE are performed by measuring agreement with these externally supplied labels rather than by any equation or definition internal to the metrics themselves. No step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or redefinition of the input ground truths. The derivation therefore remains self-contained against the benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A unified causal abstraction framework applies uniformly to all ten simulated systems
invented entities (1)
-
Causal Abstraction Error (CAE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Causal Proxy Models For Concept-Based Model Explanations , author=. 2022 , eprint=
2022
-
[2]
arXiv preprint arXiv:2207.08603 , year=
Abstraction between structural causal models: A review of definitions and properties , author=. arXiv preprint arXiv:2207.08603 , year=
-
[3]
Srinivas, Niranjan and Krause, Andreas and Kakade, Sham M. and Seeger, Matthias W. , year=. Information-Theoretic Regret Bounds for Gaussian Process Optimization in the Bandit Setting , volume=. IEEE Transactions on Information Theory , publisher=. doi:10.1109/tit.2011.2182033 , number=
-
[4]
Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals
Elazar, Yanai and Ravfogel, Shauli and Jacovi, Alon and Goldberg, Yoav. Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00359
-
[5]
Probing for the Usage of Grammatical Number
Lasri, Karim and Pimentel, Tiago and Lenci, Alessandro and Poibeau, Thierry and Cotterell, Ryan. Probing for the Usage of Grammatical Number. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.603
-
[6]
Zennaro, Fabio Massimo and Turrini, Paolo and Damoulas, Theodoros , month = aug, year =. Quantifying. doi:10.24963/ijcai.2023/638 , booktitle =
-
[7]
J. Karl Johnson and John A. Zollweg and Keith E. Gubbins , title =. Molecular Physics , volume =. 1993 , publisher =. doi:10.1080/00268979300100411 , URL =
-
[8]
Gomes, André F. C. and Figueiredo, Mário A. T. , TITLE =. Entropy , VOLUME =. 2024 , NUMBER =
2024
-
[9]
I.M Sobol' , keywords =. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates , journal =. 2001 , note =. doi:https://doi.org/10.1016/S0378-4754(00)00270-6 , url =
-
[10]
S. Segmenting the fly embryo: logical analysis of the role of the Segment Polarity cross-regulatory module , journal=. 2008 , volume=. doi:10.1387/ijdb.072439ls , url=
-
[11]
2024 , eprint=
TracrBench: Generating Interpretability Testbeds with Large Language Models , author=. 2024 , eprint=
2024
-
[12]
ICML 2024 Workshop on Mechanistic Interpretability , year=
InterpBench: Semi-Synthetic Transformers for Evaluating Mechanistic Interpretability Techniques , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
2024
-
[13]
2025 , eprint=
MIB: A Mechanistic Interpretability Benchmark , author=. 2025 , eprint=
2025
-
[14]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[15]
Science , volume=
Distributed and overlapping representations of faces and objects in ventral temporal cortex , author=. Science , volume=. 2001 , publisher=
2001
-
[16]
Nucleic Acids Research , volume =
Roy, Amitava and Ward, Ethan and Choi, Illyoung and Cosi, Michele and Edgin, Tony and Hughes, Travis S and Islam, Md Shafayet and Khan, Asif M and Kolekar, Aakash and Rayl, Mariah and Robinson, Isaac and Sarando, Paul and Skidmore, Edwin and Swetnam, Tyson L and Wall, Mariah and Xu, Zhuoyun and Yung, Michelle L and Merchant, Nirav and Wheeler, Travis J , ...
-
[17]
Proceedings of the National Academy of Sciences , volume=
Sparsification of neuronal activity in the visual cortex at eye-opening , author=. Proceedings of the National Academy of Sciences , volume=. 2009 , publisher=
2009
-
[18]
Frontiers in neuroscience , volume=
Modular and hierarchically modular organization of brain networks , author=. Frontiers in neuroscience , volume=. 2010 , publisher=
2010
-
[19]
2023 , eprint=
The Hydra Effect: Emergent Self-repair in Language Model Computations , author=. 2023 , eprint=
2023
-
[20]
Neuron , volume=
Representation, pattern information, and brain signatures: from neurons to neuroimaging , author=. Neuron , volume=. 2018 , publisher=
2018
-
[21]
New England Journal of Medicine , volume=
An fMRI-based neurologic signature of physical pain , author=. New England Journal of Medicine , volume=. 2013 , publisher=
2013
-
[22]
Trends in cognitive sciences , volume=
Beyond mind-reading: multi-voxel pattern analysis of fMRI data , author=. Trends in cognitive sciences , volume=. 2006 , publisher=
2006
-
[23]
Karen Sachs and Omar Perez and Dana Pe'er and Douglas A. Lauffenburger and Garry P. Nolan , title =. Science , volume =. 2005 , doi =. https://www.science.org/doi/pdf/10.1126/science.1105809 , abstract =
-
[24]
2024 , eprint=
Instruction-tuning Aligns LLMs to the Human Brain , author=. 2024 , eprint=
2024
-
[25]
C. L. Mallows , journal =. Some Comments on CP , urldate =
-
[26]
Measuring Statistical Dependence with Hilbert-Schmidt Norms
Gretton, Arthur and Bousquet, Olivier and Smola, Alex and Sch \"o lkopf, Bernhard. Measuring Statistical Dependence with Hilbert-Schmidt Norms. Algorithmic Learning Theory. 2005
2005
-
[27]
1993 , publisher=
Spectral analysis for physical applications , author=. 1993 , publisher=
1993
-
[28]
IEEE transactions on acoustics, speech, and signal processing , volume=
Dynamic programming algorithm optimization for spoken word recognition , author=. IEEE transactions on acoustics, speech, and signal processing , volume=. 1978 , publisher=
1978
-
[29]
Borgwardt and Malte J
Arthur Gretton and Karsten M. Borgwardt and Malte J. Rasch and Bernhard Sch. A Kernel Two-Sample Test , journal =. 2012 , volume =
2012
-
[30]
2026 , eprint=
RealPDEBench: A Benchmark for Complex Physical Systems with Real-World Data , author=. 2026 , eprint=
2026
-
[31]
2024 , eprint=
PDEBENCH: An Extensive Benchmark for Scientific Machine Learning , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
CausalARC: Abstract Reasoning with Causal World Models , author=. 2025 , eprint=
2025
-
[33]
2014 , eprint=
Structural Intervention Distance (SID) for Evaluating Causal Graphs , author=. 2014 , eprint=
2014
-
[34]
International Conference on Learning Representations , year=
A framework for the quantitative evaluation of disentangled representations , author=. International Conference on Learning Representations , year=
-
[35]
2019 , eprint=
Isolating Sources of Disentanglement in Variational Autoencoders , author=. 2019 , eprint=
2019
-
[36]
2019 , eprint=
Disentangling by Factorising , author=. 2019 , eprint=
2019
-
[37]
2025 , eprint=
WorldVLA: Towards Autoregressive Action World Model , author=. 2025 , eprint=
2025
-
[38]
2024 , eprint=
Assessing Sample Quality via the Latent Space of Generative Models , author=. 2024 , eprint=
2024
-
[39]
2026 , eprint=
Beyond Accuracy and Complexity: The Effective Information Criterion for Structurally Stable Symbolic Regression , author=. 2026 , eprint=
2026
-
[40]
Journal of Simulation , volume =
R Gore and P F Reynolds Jr , title =. Journal of Simulation , volume =. 2010 , publisher =. doi:10.1057/jos.2009.26 , URL =
-
[41]
and Kamensky, David and Diallo, Saikou and Padilla, Jose , title =
Gore, Ross and Reynolds Jr., Paul F. and Kamensky, David and Diallo, Saikou and Padilla, Jose , title =. ACM Trans. Model. Comput. Simul. , month = apr, articleno =. 2015 , issue_date =. doi:10.1145/2699722 , abstract =
-
[42]
M.L. Glasser , keywords =. Second virial coefficient for a Lennard-Jones (2n-n) system in d dimensions and confined to a nanotube surface , journal =. 2002 , issn =. doi:https://doi.org/10.1016/S0375-9601(02)00814-9 , url =
-
[43]
RAVEL : Evaluating Interpretability Methods on Disentangling Language Model Representations
Huang, Jing and Wu, Zhengxuan and Potts, Christopher and Geva, Mor and Geiger, Atticus. RAVEL : Evaluating Interpretability Methods on Disentangling Language Model Representations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.470
-
[44]
and Pereira, Eduardo M
Carvalho, Diogo V. and Pereira, Eduardo M. and Cardoso, Jaime S. , TITLE =. Electronics , VOLUME =. 2019 , NUMBER =
2019
-
[45]
2022 , subtitle =
Interpretable Machine Learning , author =. 2022 , subtitle =
2022
-
[46]
2024 , eprint=
AtP*: An efficient and scalable method for localizing LLM behaviour to components , author=. 2024 , eprint=
2024
-
[47]
2025 , eprint=
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability , author=. 2025 , eprint=
2025
-
[48]
Inducing Causal Structure for Interpretable Neural Networks , url =
Geiger, Atticus and Wu, Zhengxuan and Lu, Hanson and Rozner, Josh and Kreiss, Elisa and Icard, Thomas and Goodman, Noah and Potts, Christopher , booktitle =. Inducing Causal Structure for Interpretable Neural Networks , url =
-
[49]
CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior , url =
Abraham, Eldar David and D'Oosterlinck, Karel and Feder, Amir and Gat, Yair and Geiger, Atticus and Potts, Christopher and Reichart, Roi and Wu, Zhengxuan , booktitle =. CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior , url =
-
[50]
arXiv preprint arXiv:2403.17806 , year=
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms , author=. arXiv preprint arXiv:2403.17806 , year=
-
[51]
, note =
Wu, Zhengxuan and Geiger, Atticus and Potts, Christopher and Goodman, Noah D. , note =. Interpretability at Scale: Identifying Causal Mechanisms in Alpaca , url =
-
[52]
Rigorously Assessing Natural Language Explanations of Neurons , url =
Huang, Jing and Geiger, Atticus and D'Oosterlinck, Karel and Wu, Zhengxuan and Potts, Christopher , note =. Rigorously Assessing Natural Language Explanations of Neurons , url =
-
[53]
, note =
Geiger, Atticus and Wu, Zhengxuan and Potts, Christopher and Icard, Thomas and Goodman, Noah D. , note =. Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , url =
-
[54]
and Icard, Thomas and Potts, Christopher , note =
Geiger, Atticus and Wu, Zhengxuan and D'Oosterlinck, Karel and Kreiss, Elisa and Goodman, Noah D. and Icard, Thomas and Potts, Christopher , note =. Faithful, Interpretable Model Explanations via Causal Abstraction , url =
-
[55]
Causal Proxy Models for Concept-based Model Explanations , url =
Wu, Zhengxuan and D'Oosterlinck, Karel and Geiger, Atticus and Zur, Amir and Potts, Christopher , booktitle =. Causal Proxy Models for Concept-based Model Explanations , url =
-
[56]
Wu, Zhengxuan and Geiger, Atticus and Rozner, Josh and Kreiss, Elisa and Lu, Hanson and Icard, Thomas and Potts, Christopher and Goodman, Noah D. , booktitle =. Causal Distillation for Language Models , url =. doi:10.18653/v1/2022.naacl-main.318 , month = jul, pages =
-
[57]
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =
Multi-Level Cause-Effect Systems , author =. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =. 2016 , editor =
2016
-
[58]
International conference on machine learning , pages=
Interventional causal representation learning , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[59]
Nonparametric Identifiability of Causal Representations from Unknown Interventions , url =
von K\". Nonparametric Identifiability of Causal Representations from Unknown Interventions , url =. Advances in Neural Information Processing Systems , editor =
-
[60]
Conference on Causal Learning and Reasoning , pages=
Jointly learning consistent causal abstractions over multiple interventional distributions , author=. Conference on Causal Learning and Reasoning , pages=. 2023 , organization=
2023
-
[61]
arXiv preprint arXiv:2503.10834 , year=
On the Identifiability of Causal Abstractions , author=. arXiv preprint arXiv:2503.10834 , year=
-
[62]
2025 , eprint=
The Non-Linear Representation Dilemma: Is Causal Abstraction Enough for Mechanistic Interpretability? , author=. 2025 , eprint=
2025
-
[63]
Advances in Neural Information Processing Systems , volume=
Weakly supervised causal representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
NeurIPS 2024 Causal Representation Learning Workshop , year=
Unsupervised Causal Abstraction , author=. NeurIPS 2024 Causal Representation Learning Workshop , year=
2024
-
[65]
arXiv preprint arXiv:2311.18639 , year=
Targeted reduction of causal models , author=. arXiv preprint arXiv:2311.18639 , year=
-
[66]
Conference on Causal Learning and Reasoning , pages=
On the equivalence of causal models: A category-theoretic approach , author=. Conference on Causal Learning and Reasoning , pages=. 2022 , organization=
2022
-
[67]
Uncertainty in Artificial Intelligence , pages=
Compositional abstraction error and a category of causal models , author=. Uncertainty in Artificial Intelligence , pages=. 2021 , organization=
2021
-
[68]
Master's thesis, University of Copenhagen , year=
The category theory of causal models , author=. Master's thesis, University of Copenhagen , year=
-
[69]
Proceedings of the 33rd Conference on Uncertainty in Artificial Intelligence (UAI) , pages =
Causal Consistency of Structural Equation Models , author =. Proceedings of the 33rd Conference on Uncertainty in Artificial Intelligence (UAI) , pages =. 2017 , note =
2017
-
[70]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Abstracting Causal Models , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2019 , month=. doi:10.1609/aaai.v33i01.33012678 , number=
-
[71]
Proceedings of The 35th Uncertainty in Artificial Intelligence Conference , pages =
Approximate Causal Abstractions , author =. Proceedings of The 35th Uncertainty in Artificial Intelligence Conference , pages =. 2020 , editor =
2020
-
[72]
2023 , eprint=
Attribution Patching Outperforms Automated Circuit Discovery , author=. 2023 , eprint=
2023
-
[73]
Distill , year =
Carter, Shan and Armstrong, Zan and Schubert, Ludwig and Johnson, Ian and Olah, Chris , title =. Distill , year =
-
[74]
2024 , eprint=
PURE: Turning Polysemantic Neurons Into Pure Features by Identifying Relevant Circuits , author=. 2024 , eprint=
2024
-
[75]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[76]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[77]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[78]
2022 , eprint=
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small , author=. 2022 , eprint=
2022
-
[79]
Distill , year =
Olah, Chris and Satyanarayan, Arvind and Johnson, Ian and Carter, Shan and Schubert, Ludwig and Ye, Katherine and Mordvintsev, Alexander , title =. Distill , year =
-
[80]
Distill , year =
Olah, Chris and Mordvintsev, Alexander and Schubert, Ludwig , title =. Distill , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.