AEGIS: A Multi-Task Joint-Embedding Predictive Architecture for Mammography
Pith reviewed 2026-07-02 19:02 UTC · model grok-4.3
The pith
A joint-embedding predictive model reaches 0.949 AUC for breast cancer triage after pre-training on 71,103 studies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
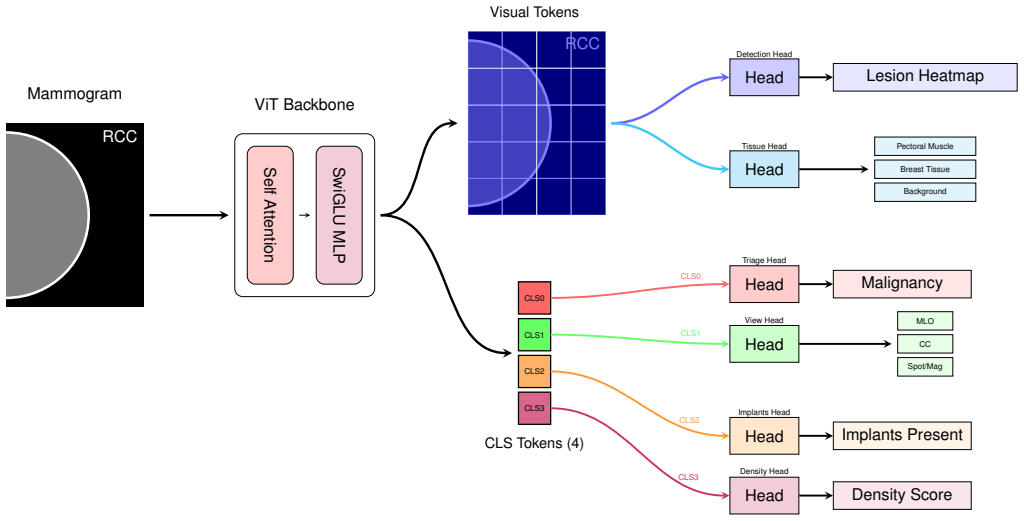
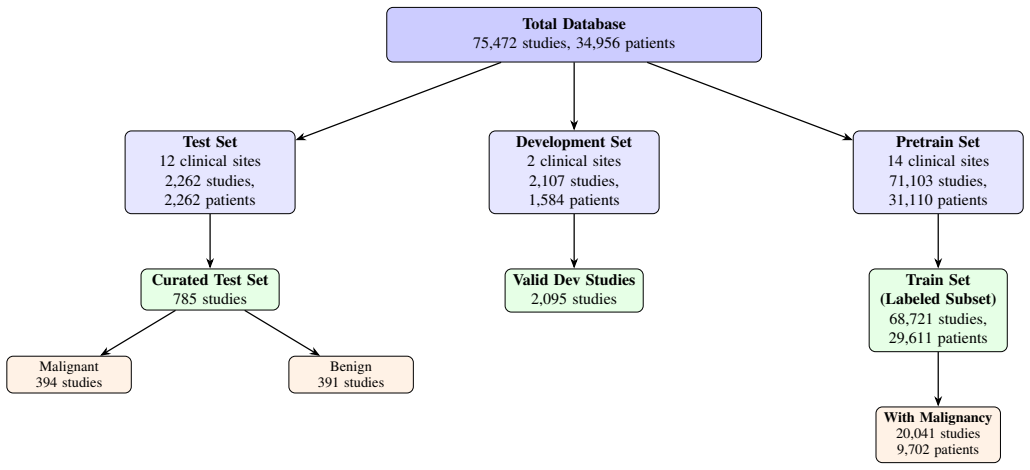
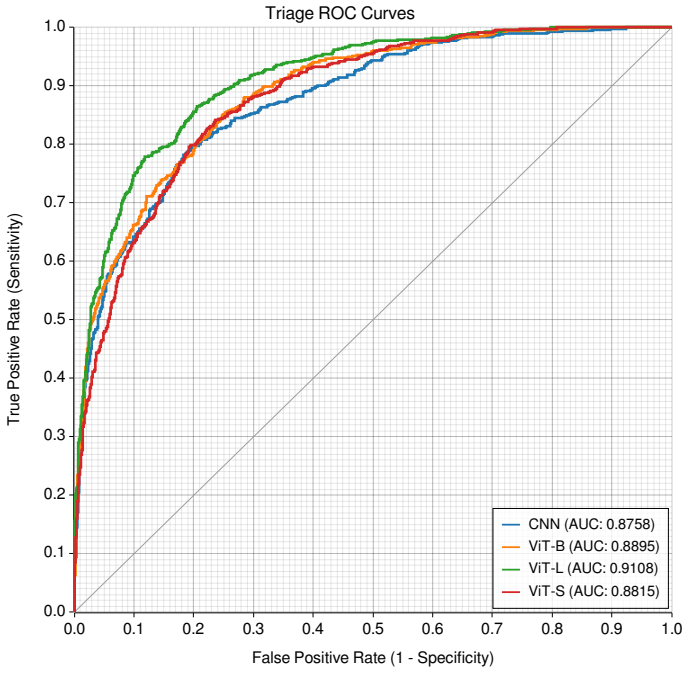
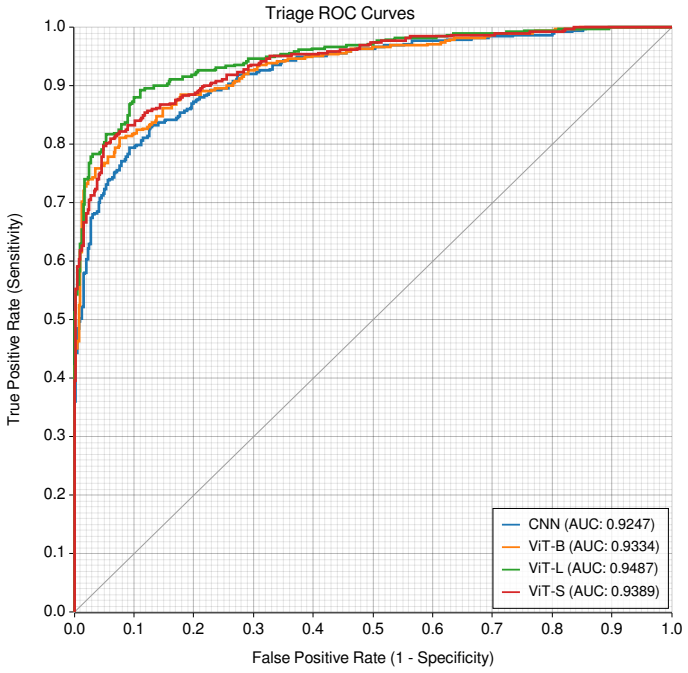
Aegis is a joint-embedding predictive architecture built on Vision Transformer variants that first learns representations via self-supervised JEPA pre-training across 71,103 studies from 14 sites, then fine-tunes with progressive resolution scaling to perform simultaneous breast cancer triage and BI-RADS density classification; the largest model records 0.949 AUC on triage, 0.953 AUC on binary density, 62.6 percent exact four-class density accuracy, and 0.871 AUC zero-shot on an external public dataset.
What carries the argument
Joint-embedding predictive architecture (JEPA) pre-training of Vision Transformer Small/Base/Large variants, followed by supervised multi-task fine-tuning for cancer detection and density assessment.
If this is right
- The largest model alone can operate at 93 percent sensitivity with 75 percent specificity for cancer triage.
- An ensemble with an FDA-cleared baseline raises discrimination to 0.952 AUC.
- Density classification reaches 98.8 percent adjacent accuracy, matching reported human inter-reader levels.
- Zero-shot transfer to VinDr-Mammo yields 0.871 AUC under a different reference standard.
Where Pith is reading between the lines
- The same pre-training recipe could be applied to other high-volume imaging modalities where labeled outcomes are expensive to obtain.
- Progressive resolution scaling during fine-tuning may be reusable for any medical imaging task that benefits from both global context and fine local detail.
- If the test-set curation process inadvertently favored easier cases, real-world sensitivity at the reported operating point would be lower than claimed.
- Multi-task training that jointly optimizes cancer detection and density may reduce the total annotation burden compared with training separate models.
Load-bearing premise
The curated 785-study test set is representative of real-world clinical distributions and free of selection bias relative to the 71,103-study pre-training corpus.
What would settle it
A statistically significant drop below 0.90 AUC when the same model is evaluated on an unselected consecutive series of screening mammograms collected after the study period from a site not represented in the original 14.
Figures

read the original abstract
We present Aegis, a joint-embedding predictive architecture for breast cancer detection and density assessment in mammography. We train three Vision Transformer variants (Small/Base/Large) using self-supervised joint-embedding predictive architecture (JEPA) pre-training on 71,103 studies from 14 clinical sites, followed by supervised fine-tuning with progressive resolution scaling up to 2048x1536. On a curated 785-study test set, our largest model achieves area under the receiver operating characteristic curve (AUC) 0.949 for breast cancer triage with 93% sensitivity and 75% specificity at the optimal operating point. An ensemble combining our model with a U.S. Food and Drug Administration-cleared baseline further improves discrimination to 0.952 AUC. For breast density classification, the model achieves 0.953 AUC for binary (dense vs. non-dense) classification and 62.6% exact accuracy across four Breast Imaging Reporting and Data System (BI-RADS) categories, with 98.8% adjacent accuracy comparable to reported human inter-reader agreement. External validation on the public VinDr-Mammo dataset provides evidence of cross-population transfer under a different reference standard, with the largest model achieving 0.871 AUC for triage in a zero-shot setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AEGIS, a multi-task joint-embedding predictive architecture (JEPA) using Vision Transformer variants (Small/Base/Large) for breast cancer triage and BI-RADS density assessment in mammography. It reports self-supervised pre-training on 71,103 studies from 14 sites, followed by supervised fine-tuning with progressive resolution scaling. On a curated 785-study test set the largest model reaches AUC 0.949 for triage (93% sensitivity, 75% specificity at optimal point), an ensemble with an FDA-cleared system reaches 0.952 AUC, binary density AUC 0.953, 62.6% exact 4-class accuracy (98.8% adjacent), and zero-shot AUC 0.871 on VinDr-Mammo.
Significance. If the test-set results generalize, the work provides evidence that large-scale multi-site JEPA pre-training can support competitive multi-task performance in mammography, including cross-population transfer on an external public dataset. The scale of pre-training data and the inclusion of external validation are positive features. The significance is limited by the absence of any characterization of the test-set curation process or statistical analysis of the reported metrics.
major comments (2)
- [Abstract] Abstract: the triage performance (AUC 0.949, 93%/75% operating point) and ensemble improvement (to 0.952) are reported exclusively on a 'curated 785-study test set' with no description of selection criteria, stratification by site/prevalence/density/acquisition parameters, or any demographic/prevalence tables comparing the test set to the 71,103-study pre-training corpus. Because the central clinical-utility claim rests on this held-out evaluation, the lack of curation protocol makes it impossible to determine whether the result is representative or affected by selection bias.
- [Abstract] Abstract / Results: no confidence intervals, statistical tests, or p-values are supplied for any AUC value, sensitivity/specificity point, or comparison against the FDA-cleared baseline. This information is required to support claims of improvement and clinical relevance.
minor comments (3)
- [Abstract] Abstract: the construction of the ensemble (score averaging, weighting, etc.) is not described.
- [Abstract] Abstract: no information is given on how class imbalance was handled during fine-tuning or evaluation.
- [Abstract] Abstract: the exact number of parameters and training hyperparameters for the three ViT variants are not stated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the importance of test-set transparency and statistical rigor. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the triage performance (AUC 0.949, 93%/75% operating point) and ensemble improvement (to 0.952) are reported exclusively on a 'curated 785-study test set' with no description of selection criteria, stratification by site/prevalence/density/acquisition parameters, or any demographic/prevalence tables comparing the test set to the 71,103-study pre-training corpus. Because the central clinical-utility claim rests on this held-out evaluation, the lack of curation protocol makes it impossible to determine whether the result is representative or affected by selection bias.
Authors: We agree that the current manuscript lacks sufficient detail on test-set curation, which limits assessment of representativeness and potential bias. In the revised version we will add a dedicated Methods subsection describing the curation protocol for the 785-study test set, including explicit selection criteria, any stratification by site/prevalence/density/acquisition parameters, and comparative tables or statistics on demographics and prevalence versus the 71,103-study pre-training corpus. revision: yes
-
Referee: [Abstract] Abstract / Results: no confidence intervals, statistical tests, or p-values are supplied for any AUC value, sensitivity/specificity point, or comparison against the FDA-cleared baseline. This information is required to support claims of improvement and clinical relevance.
Authors: We acknowledge the absence of confidence intervals and formal statistical testing. In the revision we will report 95% bootstrap confidence intervals for all AUC, sensitivity, and specificity values and will include statistical comparisons (e.g., DeLong test) with p-values for the ensemble versus the FDA-cleared baseline to substantiate claims of improvement. revision: yes
Circularity Check
No significant circularity; empirical evaluation on held-out data with no derivations or self-referential fits
full rationale
The paper reports standard self-supervised pre-training (JEPA on 71,103 studies) followed by supervised fine-tuning and evaluation on a separate 785-study curated test set plus external validation on VinDr-Mammo. No equations, derivations, fitted parameters re-labeled as predictions, or load-bearing self-citations appear in the provided text. Performance metrics (AUC 0.949, etc.) are direct empirical measurements on held-out data rather than quantities forced by construction from the inputs. This matches the default expectation for non-circular empirical ML papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Global cancer statistics 2022: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries,
F. Bray, M. Laversanne, H. Sung, J. Ferlay, R. L. Siegel, I. Soer- jomataram, and A. Jemal, “Global cancer statistics 2022: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries,”CA: A Cancer Journal for Clinicians, vol. 74, no. 3, pp. 229–263, 2024
2022
-
[2]
Breast cancer,
W. H. Organization, “Breast cancer,” Fact sheet, April 2026, available from: https://www.who.int/news-room/fact-sheets/detail/breast-cancer
2026
-
[3]
Global patterns and trends in breast cancer incidence and mortality across 185 countries,
J. Kim, A. Harper, V . McCormack, H. Sung, N. Houssami, E. Morgan, M. M. Fidler-Benaoudia, I. Soerjomataram, and F. Bray, “Global patterns and trends in breast cancer incidence and mortality across 185 countries,”Nature Medicine, February 2025. [Online]. Available: https://www.nature.com/articles/s41591-025-03502-3
2025
-
[4]
Self-supervised learning from images with a joint-embedding predictive architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” 2023
2023
-
[5]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” 2020
2020
-
[6]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” 2019
2019
-
[7]
Bootstrap your own latent: A new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, “Bootstrap your own latent: A new approach to self-supervised learning,” 2020
2020
-
[8]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” 2021
2021
-
[9]
Beit: Bert pre-training of image transformers,
H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” 2021
2021
-
[10]
ibot: Image bert pre-training with online tokenizer,
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “ibot: Image bert pre-training with online tokenizer,” 2021
2021
-
[11]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” 2021
2021
-
[12]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features without supe...
2023
-
[13]
Revisiting feature prediction for learning visual representations from video,
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas, “Revisiting feature prediction for learning visual representations from video,” 2024
2024
-
[14]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
R. Balestriero and Y . LeCun, “Lejepa: Provable and scalable self- supervised learning without the heuristics,” 2025. [Online]. Available: https://arxiv.org/abs/2511.08544
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” 2021. [Online]. Available: https://arxiv.org/abs/2012. 12877
2021
-
[17]
Escaping the big data paradigm with compact transformers,
A. Hassani, S. Walton, N. Shah, A. Abuduweili, J. Li, and H. Shi, “Escaping the big data paradigm with compact transformers,” 2022. [Online]. Available: https://arxiv.org/abs/2104.05704
-
[18]
Transformers in medical imaging: A survey,
F. Shamshad, S. Khan, S. W. Zamir, M. H. Khan, M. Hayat, F. S. Khan, and H. Fu, “Transformers in medical imaging: A survey,”Medical Image Analysis, vol. 88, p. 102802, 2023
2023
-
[19]
Vision transformers need registers,
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski, “Vision transformers need registers,” 2024. [Online]. Available: https://arxiv.org/abs/2309. 16588
2024
-
[20]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski, “DINOv3,” 2025. [Online]. Available: h...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,”
-
[22]
Root Mean Square Layer Normalization
[Online]. Available: https://arxiv.org/abs/1910.07467
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[23]
Vision-transformer-based transfer learning for mammogram classification,
G. Ayana, K. Dese, and S.-w. Choe, “Vision-transformer-based transfer learning for mammogram classification,”Diagnostics, vol. 13, no. 2, p. 178, 2023
2023
-
[24]
Detection of breast cancer in digital breast tomosynthesis with vision transformers,
I. Kassis, D. Lederman, G. Ben-Arie, M. Giladi Rosenthal, I. Shelef, and Y . Zigel, “Detection of breast cancer in digital breast tomosynthesis with vision transformers,”Scientific Reports, vol. 14, p. 22149, 2024
2024
-
[25]
Kashiwada, E
Y . Kashiwada, E. Takaya, M. Hiroya, N. Matsuda, T. Yashima, T. Kobayashi, G. Tamiya, and T. Ueda, “Applying vision transformer to assess multi-scale morphological features in mammography for breast cancer detection: multiscale image morphological extraction vision transformer (MIME-ViT),”PeerJ Computer Science, vol. 11, p. e3252, 2025
2025
-
[26]
International evaluation of an AI system for breast cancer screening,
S. M. McKinney, M. Sieniek, V . Godbole, J. Godwin, N. Antropova, H. Ashrafian, T. Back, M. Chesus, G. S. Corrado, A. Darziet al., “International evaluation of an AI system for breast cancer screening,” Nature, vol. 577, no. 7788, pp. 89–94, 2020
2020
-
[27]
Nation- wide real-world implementation of AI for cancer detection in population- based mammography screening,
N. Eisemann, S. Bunk, T. Mukama, H. Baltus, S. A. Elsner, T. Gomille, G. Hecht, S. Heywang-K”obrunner, R. Rathmann, K. Siegmann-Luz, T. T”ollner, T. Werner V omweg, C. Leibig, and A. Katalinic, “Nation- wide real-world implementation of AI for cancer detection in population- based mammography screening,”Nature Medicine, vol. 31, pp. 917–924, 2025
2025
-
[28]
A. Arieno, A. Chan, and S. V . Destounis, “A review of the role of augmented intelligence in breast imaging: From automated breast density assessment to risk stratification,”American Journal of Roentgenology, vol. 212, no. 2, pp. 259–270, 2019, pMID: 30422711. [Online]. Available: https://doi.org/10.2214/AJR.18.20391
-
[29]
Variation in mammographic breast density assessments among radiologists in clinical practice: a multicenter observational study,
B. L. Sprague, E. F. Conant, T. Onega, M. P. Garcia, E. F. Beaber, S. D. Herschorn, C. D. Lehman, A. N. A. Tosteson, R. Lacson, M. D. Schnall, D. Kontos, J. S. Haas, D. L. Weaver, W. E. Barlow, and PROSPR Consortium, “Variation in mammographic breast density assessments among radiologists in clinical practice: a multicenter observational study,”Annals of ...
2016
-
[30]
Breast cancer risk assessment in the ai era: The importance of model validation in ethnically diverse cohorts,
D. Kontos and J. Kalpathy-Cramer, “Breast cancer risk assessment in the ai era: The importance of model validation in ethnically diverse cohorts,”Radiology: Artificial Intelligence, vol. 5, no. 6, p. e230462,
-
[31]
Available: https://doi.org/10.1148/ryai.230462
[Online]. Available: https://doi.org/10.1148/ryai.230462
-
[32]
Vindr-mammo: A large-scale benchmark dataset for computer- aided diagnosis in full-field digital mammography,
H. T. Nguyen, H. Q. Nguyen, H. H. Pham, K. Lam, L. T. Le, M. Dao, and V . Vu, “Vindr-mammo: A large-scale benchmark dataset for computer- aided diagnosis in full-field digital mammography,”Scientific Data, vol. 10, p. 277, 2023
2023
-
[33]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,” Neurocomputing, vol. 568, p. 127063, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0925231223011864
2024
-
[34]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,” 2020. [Online]. Available: https://arxiv.org/abs/2002.05202
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[35]
Cluster and predict latent patches for improved masked image mod- eling,
T. Darcet, F. Baldassarre, M. Oquab, J. Mairal, and P. Bojanowski, “Cluster and predict latent patches for improved masked image mod- eling,” 2025
2025
-
[36]
X. Zhou, D. Wang, and P. Kr ¨ahenb¨uhl, “Objects as points,” inarXiv preprint arXiv:1904.07850, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[37]
Index for rating diagnostic tests,
W. J. Youden, “Index for rating diagnostic tests,”Cancer, vol. 3, no. 1, pp. 32–35, 1950
1950
-
[38]
ROC curves in clinical chemistry: uses, misuses, and possible solutions,
N. A. Obuchowski, M. L. Lieber, and F. H. Wians, “ROC curves in clinical chemistry: uses, misuses, and possible solutions,”Clinical Chemistry, vol. 50, no. 7, pp. 1118–1125, 2004
2004
-
[39]
United states cancer statistics: Data visualizations,
U.S. Centers for Disease Control and Prevention, “United states cancer statistics: Data visualizations,” https://gis.cdc.gov/Cancer/USCS/, 2023, accessed: August 2023
2023
-
[40]
Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach,
E. R. DeLong, D. M. DeLong, and D. L. Clarke-Pearson, “Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach,”Biometrics, vol. 44, no. 3, pp. 837– 845, 1988
1988
-
[41]
Optimizing breast cancer detection in mammograms: A comprehensive study of transfer learning, resolution reduction, and multi-view classification,
D. G. P. Petrini and H. Y . Kim, “Optimizing breast cancer detection in mammograms: A comprehensive study of transfer learning, resolution reduction, and multi-view classification,” 2025
2025
-
[42]
MamT4: Multi-view attention networks for mammog- raphy cancer classification,
A. Ibragimov, S. Senotrusova, A. Litvinov, E. Ushakov, E. Karpulevich, and Y . Markin, “MamT4: Multi-view attention networks for mammog- raphy cancer classification,” in2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2024, pp. 1965–1970
2024
-
[43]
Dual view deep learning for en- hanced breast cancer screening using mammography,
S. R. Kebede, F. G. Waldamichael, T. G. Debelee, M. Aleme, W. Bedane, B. Mezgebu, and Z. C. Merga, “Dual view deep learning for en- hanced breast cancer screening using mammography,”Scientific Reports, vol. 14, p. 3839, 2024
2024
-
[44]
AUCReshaping: improved sensitivity at high-specificity,
S. Bhat, A. Mansoor, B. Georgescuet al., “AUCReshaping: improved sensitivity at high-specificity,”Scientific Reports, vol. 13, p. 21097, 2023
2023
-
[45]
T-synth: A knowledge-based dataset of synthetic breast images,
C. Wiedeman, A. Sarmakeeva, E. Sizikova, D. Filienko, M. Lago, J. G. Delfino, and A. Badano, “T-synth: A knowledge-based dataset of synthetic breast images,”arXiv preprint arXiv:2507.04038, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.