HyFL-CLIP: Hyperbolic Fine-Tuning of CLIP for Robust Long-Context Understanding
Pith reviewed 2026-07-02 15:13 UTC · model grok-4.3
The pith
HyFL-CLIP distills CLIP's image-text alignment into hyperbolic space to model hierarchical semantics for robust long-context understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
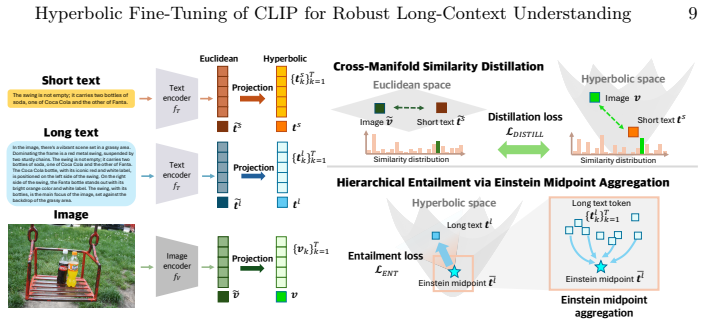
HyFL-CLIP models hierarchical semantics by linking summarized token-wise features, long-context descriptions, constituent short textual components, and images, capturing part-whole relationships via hyperbolic entailment with Einstein midpoint aggregation, and achieves up to 19.5% improvement in long-text cross-modal retrieval under textual perturbations over the best prior method.
What carries the argument
Hyperbolic entailment with Einstein midpoint aggregation, which links global long-context features to their constituent elements in a hierarchical manner.
If this is right
- HyFL-CLIP shows improved performance on long-context cross-modal retrieval, cross-modal retrieval with caption perturbations, intra-modality retrieval, and short-text cross-modal retrieval.
- The method can be integrated into other frameworks such as Stable Diffusion XL.
- Distilling Euclidean CLIP alignments into hyperbolic space preserves the original alignment while adding robustness to textual perturbations.
- Modeling hierarchical relationships addresses the limitation of strict one-to-one matching in Euclidean contrastive objectives.
Where Pith is reading between the lines
- Similar hyperbolic distillation could be applied to other vision-language models beyond CLIP to handle long contexts.
- Testing on contexts much longer than 77 tokens might reveal further gains or limits of the approach.
- The Einstein midpoint aggregation might generalize to other hierarchical data structures in multimodal tasks.
Load-bearing premise
The Euclidean contrastive objective fundamentally lacks mechanisms for hierarchical relationships between global context and its parts, and cross-manifold distillation will add this capability without harming alignment.
What would settle it
If replacing the hyperbolic space with Euclidean space while keeping the distillation and aggregation yields the same 19.5% improvement, the benefit would not stem from hyperbolic geometry.
Figures




read the original abstract
CLIP (Contrastive Language-Image Pre-training) has become a de facto paradigm for image-text alignment, but it struggles with long-context descriptions (>77 tokens) due to absolute positional encoding and pretraining on short captions. In long contexts, sentences are often reordered, summarized, or partially omitted. Although prior works extend CLIP with longer positional encodings, they often suffer from degraded image-text alignment under such text perturbations. We attribute this limitation to the Euclidean contrastive objective, which enforces strict one-to-one matching and lacks explicit mechanisms for modeling hierarchical relationships between global context and its constituent elements. To address this issue, we propose HyFL-CLIP, a hyperbolic fine-tuning framework that distills the well-established text-image alignment learned in Euclidean CLIP into hyperbolic space via cross-manifold similarity distillation, leveraging its geometry to capture hierarchical and entailment relations. Our method models hierarchical semantics by linking summarized token-wise features, long-context descriptions, constituent short textual components, and images, capturing part-whole relationships via hyperbolic entailment with Einstein midpoint aggregation. Experiments on diverse benchmarks, including long-context cross-modal retrieval, cross-modal retrieval with caption perturbations, intra-modality retrieval, and short-text cross-modal retrieval, show that HyFL-CLIP achieves more robust long-context understanding. In particular, it yields up to 19.5% improvement in long-text cross-modal retrieval under textual perturbations over the best prior method. We also show HyFL-CLIP can be seamlessly integrated into other model frameworks by applying it to Stable Diffusion XL (SDXL).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyFL-CLIP, a hyperbolic fine-tuning approach for CLIP that distills Euclidean image-text alignment into hyperbolic space using cross-manifold similarity. It models part-whole hierarchies between summarized tokens, long contexts, short components, and images via hyperbolic entailment and Einstein midpoint aggregation, claiming this yields more robust long-context understanding under text perturbations (reordering, summarization, omission) than prior Euclidean extensions. Experiments across long-context retrieval, perturbed retrieval, intra-modality, and short-text tasks report up to 19.5% gains over the best baseline, with integration shown on SDXL.
Significance. If the performance gains are shown to require hyperbolic geometry rather than the distillation/aggregation structure alone, the work would offer a concrete mechanism for injecting hierarchical entailment into vision-language models, potentially improving robustness in retrieval and generative settings where long or perturbed text is common.
major comments (3)
- [Abstract, §3] Abstract and §3 (method motivation): The central claim that the Euclidean contrastive objective 'lacks explicit mechanisms for modeling hierarchical relationships' is not isolated from the new distillation and aggregation components. Without an ablation that applies the same cross-manifold linking, summarized/long/short feature aggregation, and Einstein midpoint (but in Euclidean space), the 19.5% gain under perturbations cannot be attributed to curvature rather than the structural changes.
- [Experiments] Experiments section (quantitative results): The reported improvements lack any ablation or control that replaces hyperbolic entailment with a Euclidean hierarchical pooling or attention mechanism while keeping the distillation and feature linking identical; this directly tests the weakest assumption and is required to substantiate that hyperbolic geometry is load-bearing for the robustness claim.
- [§4] §4 (implementation details): The cross-manifold similarity distillation is described at a high level; the precise loss formulation, temperature schedules, and how Einstein midpoints are computed across manifolds must be given explicitly (with equations) so that the method can be reproduced and the geometry contribution measured.
minor comments (2)
- [Abstract] Abstract: Dataset names, number of perturbation types, and whether error bars are reported should be stated even in the abstract for immediate assessment of the 19.5% figure.
- [Figures/Tables] Figure captions and tables: Ensure all baselines are named consistently with the text and that perturbation protocols (e.g., reordering ratio, summarization length) are defined in the caption or a dedicated table.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment point-by-point below and will revise the manuscript accordingly to improve clarity and substantiate our claims.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method motivation): The central claim that the Euclidean contrastive objective 'lacks explicit mechanisms for modeling hierarchical relationships' is not isolated from the new distillation and aggregation components. Without an ablation that applies the same cross-manifold linking, summarized/long/short feature aggregation, and Einstein midpoint (but in Euclidean space), the 19.5% gain under perturbations cannot be attributed to curvature rather than the structural changes.
Authors: We appreciate this observation. Our approach is designed around hyperbolic geometry to naturally capture hierarchical entailment, which Euclidean space does not support in the same way. However, to better isolate the contribution of curvature, we will include an additional ablation study in the revised manuscript that applies analogous aggregation mechanisms in Euclidean space while keeping other components fixed. This will help clarify the role of hyperbolic geometry. revision: yes
-
Referee: [Experiments] Experiments section (quantitative results): The reported improvements lack any ablation or control that replaces hyperbolic entailment with a Euclidean hierarchical pooling or attention mechanism while keeping the distillation and feature linking identical; this directly tests the weakest assumption and is required to substantiate that hyperbolic geometry is load-bearing for the robustness claim.
Authors: We agree that such a control experiment would strengthen the paper. We will add this ablation to the experiments section, comparing the hyperbolic version against a Euclidean counterpart with similar hierarchical pooling, to demonstrate that the performance gains are indeed attributable to the hyperbolic geometry rather than the distillation structure alone. revision: yes
-
Referee: [§4] §4 (implementation details): The cross-manifold similarity distillation is described at a high level; the precise loss formulation, temperature schedules, and how Einstein midpoints are computed across manifolds must be given explicitly (with equations) so that the method can be reproduced and the geometry contribution measured.
Authors: We acknowledge that the implementation details were presented at a high level. In the revised manuscript, we will expand §4 to include the explicit mathematical formulations of the cross-manifold similarity loss, the temperature scheduling used during distillation, and the step-by-step computation of Einstein midpoints for cross-manifold aggregation, complete with equations. revision: yes
Circularity Check
No significant circularity; derivation relies on external pretrained CLIP alignment and empirical validation
full rationale
The paper's core derivation attributes robustness gains to hyperbolic entailment and Einstein midpoint aggregation for hierarchical modeling, motivated by a stated limitation of Euclidean contrastive loss. No equations, fitted parameters, or self-citations are shown reducing the reported improvements (e.g., 19.5% under perturbations) to quantities defined by the method itself. The cross-manifold distillation transfers an independent pretrained alignment, and results are presented as experimental outcomes on benchmarks rather than predictions forced by construction. The assumption about Euclidean limitations is an explicit premise, not a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hyperbolic geometry can capture hierarchical and entailment relations between global context and constituent elements better than Euclidean space for image-text alignment.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: CVPR (2019)
Agrawal, H., Desai, K., Wang, Y., Chen, X., Jain, R., Johnson, M., Batra, D., Parikh, D., Lee, S., Anderson, P.: Nocaps: Novel object captioning at scale. In: CVPR (2019)
2019
-
[3]
NeurIPS (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. NeurIPS (2022)
2022
-
[4]
In: CVPR (2025)
Asokan, M., Wu, K., Albreiki, F.: Finelip: Extending clip’s reach via fine-grained alignment with longer text inputs. In: CVPR (2025)
2025
-
[5]
In: CVPR (2022)
Atigh, M.G., Schoep, J., Acar, E., van Noord, N., Mettes, P.: Hyperbolic image segmentation. In: CVPR (2022)
2022
-
[6]
In: CVPR (2024)
Bianchi, L., Carrara, F., Messina, N., Gennaro, C., Falchi, F.: The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding. In: CVPR (2024)
2024
-
[7]
In: CVPR (2024)
Byun, J., Kim, D., Moon, T.: Mafa: Managing false negatives for vision-language pre-training. In: CVPR (2024)
2024
-
[8]
In: ICML (2021)
Chami, I., Gu, A., Nguyen, D.P., Ré, C.: Horopca: Hyperbolic dimensionality re- duction via horospherical projections. In: ICML (2021)
2021
-
[9]
NeurIPS32(2019)
Chami, I., Ying, Z., Ré, C., Leskovec, J.: Hyperbolic graph convolutional neural networks. NeurIPS32(2019)
2019
-
[10]
In: ECCV (2024)
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. In: ECCV (2024)
2024
-
[11]
ICLR (2022)
Chen, T.S., Hung, W.C., Tseng, H.Y., Chien, S.Y., Yang, M.H.: Incremental false negative detection for contrastive learning. ICLR (2022)
2022
-
[12]
In: CVPR (2023)
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J.: Reproducible scaling laws for contrastive language-image learning. In: CVPR (2023)
2023
-
[13]
In: ICML (2023)
Desai, K., Nickel, M., Rajpurohit, T., Johnson, J., Vedantam, S.R.: Hyperbolic image-text representations. In: ICML (2023)
2023
-
[14]
In: TextGraphs-12 (2018)
Dhingra, B., Shallue, C., Norouzi, M., Dai, A., Dahl, G.: Embedding text in hy- perbolic spaces. In: TextGraphs-12 (2018)
2018
-
[15]
ICLR (2021)
Dosovitskiy, A.: An image is worth 16x16 words: Transformers for image recogni- tion at scale. ICLR (2021)
2021
-
[16]
In: CVPR (2025)
Feng, Y., Wen, C., Peng, Z., Zhu, S., et al.: Retaining knowledge and enhancing long-text representations in clip through dual-teacher distillation. In: CVPR (2025)
2025
-
[17]
In: ICML
Ganea, O., Bécigneul, G., Hofmann, T.: Hyperbolic entailment cones for learning hierarchical embeddings. In: ICML. PMLR (2018)
2018
-
[18]
In: CVPR (2023)
Ge, Y., Ren, J., Gallagher, A., Wang, Y., Yang, M.H., Adam, H., Itti, L., Laksh- minarayanan, B., Zhao, J.: Improving zero-shot generalization and robustness of multi-modal models. In: CVPR (2023)
2023
-
[19]
ICLR (2023)
Geng, S., Yuan, J., Tian, Y., Chen, Y., Zhang, Y.: Hiclip: Contrastive language- image pretraining with hierarchy-aware attention. ICLR (2023)
2023
-
[20]
NeurIPS (2004) Hyperbolic Fine-Tuning of CLIP for Robust Long-Context Understanding 45
Grandvalet, Y., Bengio, Y.: Semi-supervised learning by entropy minimization. NeurIPS (2004) Hyperbolic Fine-Tuning of CLIP for Robust Long-Context Understanding 45
2004
-
[21]
NeurIPS (2025)
He,N.,Anand,R.,Madhu,H.,Maatouk,A.,Krishnaswamy,S.,Tassiulas,L.,Yang, M., Ying, R.: Helm: Hyperbolic large language models via mixture-of-curvature experts. NeurIPS (2025)
2025
-
[22]
arXiv preprint arXiv:2504.08912 (2025)
He, N., Yang, M., Ying, R.: Hypercore: The core framework for building hyperbolic foundation models with comprehensive modules. arXiv preprint arXiv:2504.08912 (2025)
-
[23]
In: CVPR (2017)
He, X., Peng, Y.: Fine-grained image classification via combining vision and lan- guage. In: CVPR (2017)
2017
-
[24]
NeurIPS (2023)
Hsieh, C.Y., Zhang, J., Ma, Z., Kembhavi, A., Krishna, R.: Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. NeurIPS (2023)
2023
-
[25]
TPAMI47(5), 3563–3579 (2025)
Huang, K., Duan, C., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench++: An en- hanced and comprehensive benchmark for compositional text-to-image generation. TPAMI47(5), 3563–3579 (2025)
2025
-
[26]
arXiv preprint arXiv:2004.00849 (2020)
Huang, Z., Zeng, Z., Liu, B., Fu, D., Fu, J.: Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv preprint arXiv:2004.00849 (2020)
-
[27]
In: CVPR (2022)
Huynh, T., Kornblith, S., Walter, M.R., Maire, M., Khademi, M.: Boosting con- trastive self-supervised learning with false negative cancellation. In: CVPR (2022)
2022
-
[28]
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021).https://doi.org/10.5281/zenodo.5143773,https://doi. org/10.5281/zenodo.5143773
-
[29]
In: ICML (2021)
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: ICML (2021)
2021
-
[30]
Jin, L., Luo, G., Zhou, Y., Sun, X., Jiang, G., Shu, A., Ji, R.: Refclip: A universal teacherforweaklysupervisedreferringexpressioncomprehension.In:CVPR(2023)
2023
-
[31]
In: The Thirteenth International Conference on Learning Representations (ICLR) (2025), iCLR
Kang, D.U., Kim, H., Chun, S.Y.: Cdam: Class distribution-induced attention map for open-vocabulary semantic segmentations. In: The Thirteenth International Conference on Learning Representations (ICLR) (2025), iCLR
2025
-
[32]
In: CVPR (2015)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In: CVPR (2015)
2015
-
[33]
In: CVPR (2020)
Khrulkov, V., Mirvakhabova, L., Ustinova, E., Oseledets, I., Lempitsky, V.: Hy- perbolic image embeddings. In: CVPR (2020)
2020
-
[34]
In: CVPR (2026)
Kim, H., Jang, J.H., Kim, J.J., Chun, S.Y.: Uncertainty-guided compositional alignment with part-to-whole semantic representativeness in hyperbolic vision- language models. In: CVPR (2026)
2026
-
[35]
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
Kiros, R., Salakhutdinov, R., Zemel, R.S.: Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
IJCV (2017)
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV (2017)
2017
-
[37]
Lang,K.:Newsweeder:Learningtofilternetnews.In:Machinelearningproceedings 1995 (1995)
1995
-
[38]
In: ACL (2019)
Le, M., Roller, S., Papaxanthos, L., Kiela, D., Nickel, M.: Inferring concept hier- archies from text corpora via hyperbolic embeddings. In: ACL (2019)
2019
-
[39]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[40]
arXiv preprint arXiv:2512.20029 (2025) 46 JH Jang, H Kimet al
Li, L., Li, J., Lei, J., Xiao, J., Shao, F., Chen, L.: Learning hierarchical hyperbolic embeddings for compositional zero-shot learning. arXiv preprint arXiv:2512.20029 (2025) 46 JH Jang, H Kimet al
-
[41]
In: CVPR
Li, Y., Liu, X., Kag, A., Hu, J., Idelbayev, Y., Sagar, D., Wang, Y., Tulyakov, S., Ren, J.: Textcraftor: Your text encoder can be image quality controller. In: CVPR. pp. 7985–7995 (2024)
2024
-
[42]
In: ECCV (2014)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
2014
-
[43]
NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. NeurIPS (2023)
2023
-
[44]
NeurIPS32 (2019)
Liu, Q., Nickel, M., Kiela, D.: Hyperbolic graph neural networks. NeurIPS32 (2019)
2019
-
[45]
ICLR (2017)
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. ICLR (2017)
2017
-
[46]
ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. ICLR (2019)
2019
-
[47]
NeurIPS32(2019)
Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolin- guistic representations for vision-and-language tasks. NeurIPS32(2019)
2019
-
[48]
Pattern Recognition
Lv, X., Zhao, Y., Yin, H., Chen, Y., Liu, J.: Msg-clip: Enhancing clip’s ability to learn fine-grained structural associations through multi-modal scene graph align- ment. Pattern Recognition
-
[49]
In: Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies (2011)
Maas, A., Daly, R.E., Pham, P.T., Huang, D., Ng, A.Y., Potts, C.: Learning word vectors for sentiment analysis. In: Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies (2011)
2011
-
[50]
Journal of machine learning research (2008)
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research (2008)
2008
-
[51]
ICLR (2025)
Mistretta, M., Baldrati, A., Agnolucci, L., Bertini, M., Bagdanov, A.D.: Cross the gap: Exposing the intra-modal misalignment in clip via modality inversion. ICLR (2025)
2025
-
[52]
ICLR (2025)
Najdenkoska, I., Derakhshani, M.M., Asano, Y.M., Van Noord, N., Worring, M., Snoek, C.G.: Tulip: Token-length upgraded clip. ICLR (2025)
2025
-
[53]
In: ECCV (2024)
Onoe, Y., Rane, S., Berger, Z., Bitton, Y., Cho, J., Garg, R., Ku, A., Parekh, Z., Pont-Tuset, J., Tanzer, G., et al.: Docci: Descriptions of connected and contrasting images. In: ECCV (2024)
2024
-
[54]
ICLR (2024)
Pal, A., van Spengler, M., di Melendugno, G.M.D., Flaborea, A., Galasso, F., Mettes, P.: Compositional entailment learning for hyperbolic vision-language mod- els. ICLR (2024)
2024
-
[55]
In: CVPR (2025)
Peng, Z., Xu, Z., Zeng, Z., Wen, C., Huang, Y., Yang, M., Tang, F., Shen, W.: Understanding fine-tuning clip for open-vocabulary semantic segmentation in hy- perbolic space. In: CVPR (2025)
2025
-
[56]
In: CVPR (2015)
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazeb- nik, S.: Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: CVPR (2015)
2015
-
[57]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
In: CVPR (2023)
Pratt, S., Covert, I., Liu, R., Farhadi, A.: What does a platypus look like? gener- ating customized prompts for zero-shot image classification. In: CVPR (2023)
2023
-
[59]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[60]
In: CVPR (2024)
Ramasinghe, S., Shevchenko, V., Avraham, G., Thalaiyasingam, A.: Accept the modality gap: An exploration in the hyperbolic space. In: CVPR (2024)
2024
-
[61]
In: CVPR (2022) Hyperbolic Fine-Tuning of CLIP for Robust Long-Context Understanding 47
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022) Hyperbolic Fine-Tuning of CLIP for Robust Long-Context Understanding 47
2022
-
[62]
NeuriPS (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. NeuriPS (2022)
2022
-
[63]
In: CVPR (2023)
Sain, A., Bhunia, A.K., Chowdhury, P.N., Koley, S., Xiang, T., Song, Y.Z.: Clip for all things zero-shot sketch-based image retrieval, fine-grained or not. In: CVPR (2023)
2023
-
[64]
In: ICML (2018)
Sala, F., De Sa, C., Gu, A., Ré, C.: Representation tradeoffs for hyperbolic em- beddings. In: ICML (2018)
2018
-
[65]
In: CVPR (2025)
Sarkar, S.D., Miksik, O., Pollefeys, M., Barath, D., Armeni, I.: Crossover: 3d scene cross-modal alignment. In: CVPR (2025)
2025
-
[66]
NeurIPS (2024)
Sinha, A., Zeng, S., Yamada, M., Zhao, H.: Learning structured representations with hyperbolic embeddings. NeurIPS (2024)
2024
-
[67]
In: ICCV (2025)
Srivastava, S., Wu, K.: Hypervlm: Hyperbolic space guided vision language mod- eling for hierarchical multi-modal understanding. In: ICCV (2025)
2025
-
[68]
Poincar\'e GloVe: Hyperbolic Word Embeddings
Tifrea, A., Bécigneul, G., Ganea, O.E.: Poincar\’e glove: Hyperbolic word embed- dings. arXiv preprint arXiv:1810.06546 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[69]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
In: ICCV (2019)
Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In: ICCV (2019)
2019
-
[71]
In: CVPR (2024)
Urbanek, J., Bordes, F., Astolfi, P., Williamson, M., Sharma, V., Romero-Soriano, A.: A picture is worth more than 77 text tokens: Evaluating clip-style models on dense captions. In: CVPR (2024)
2024
-
[72]
In: CVPR (2025)
Wang, B., Ning, Z., Ding, J., Gao, X., Li, Y., Jiang, D., Yang, J., Liu, W.: Fix- clip: Dual-branch hierarchical contrastive learning via synthetic captions for better understanding of long text. In: CVPR (2025)
2025
-
[73]
In: CVPR (2025)
Wang, Z., Ramasinghe, S., Xu, C., Monteil, J., Bazzani, L., Ajanthan, T.: Learning visual hierarchies in hyperbolic space for image retrieval. In: CVPR (2025)
2025
-
[74]
In: ICCV (2023)
Wu, K., Peng, H., Zhou, Z., Xiao, B., Liu, M., Yuan, L., Xuan, H., Valenzuela, M., Chen, X.S., Wang, X., et al.: Tinyclip: Clip distillation via affinity mimicking and weight inheritance. In: ICCV (2023)
2023
-
[75]
AAAI (2025)
Wu, R., Chen, P., Shen, F., Zhao, S., Hui, Q., Gao, H., Lu, T., Liu, Z., Zhao, F., Wang, K., et al.: Himo-clip: Modeling semantic hierarchy and monotonicity in vision-language alignment. AAAI (2025)
2025
-
[76]
In: CVPR (2025)
Xie, S., Lingjing, L., Zheng, Y., Yao, Y., Tang, Z., Xing, E.P., Chen, G., Zhang, K.: Smartclip: Modular vision-language alignment with identification guarantees. In: CVPR (2025)
2025
-
[77]
arXiv preprint arXiv:2310.08390 (2023)
Yan, S., Liu, Z., Xu, L.: Hyp-uml: Hyperbolic image retrieval with uncertainty- aware metric learning. arXiv preprint arXiv:2310.08390 (2023)
-
[78]
NeurIPS (2025)
Yang, M., Feng, A., Xiong, B., Liu, J., King, I., Ying, R.: Hyperbolic fine-tuning for large language models. NeurIPS (2025)
2025
-
[79]
In: ECCV (2024)
Zhang, B., Zhang, P., Dong, X., Zang, Y., Wang, J.: Long-clip: Unlocking the long-text capability of clip. In: ECCV (2024)
2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.