Know When to Stop: Segment-Level Credit Assignment for Reducing Overthinking
Pith reviewed 2026-07-02 13:29 UTC · model grok-4.3
The pith
DASH assigns segment-level credit using drift from intermediate answers to reduce overthinking in reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
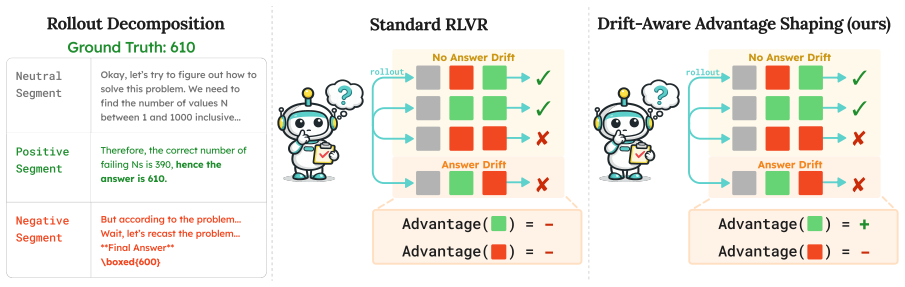
By comparing each intermediate answer candidate in the reasoning trace to the ground truth, one can label whether subsequent reflection is productive; DASH uses these labels to assign segment-level advantages that favor segments drifting toward correctness and disfavor those drifting away, producing models that overthink less and solve more problems correctly.
What carries the argument
Drift-aware advantage shaping at the segment level, where drift is measured by whether an intermediate answer commitment matches the final correct answer.
If this is right
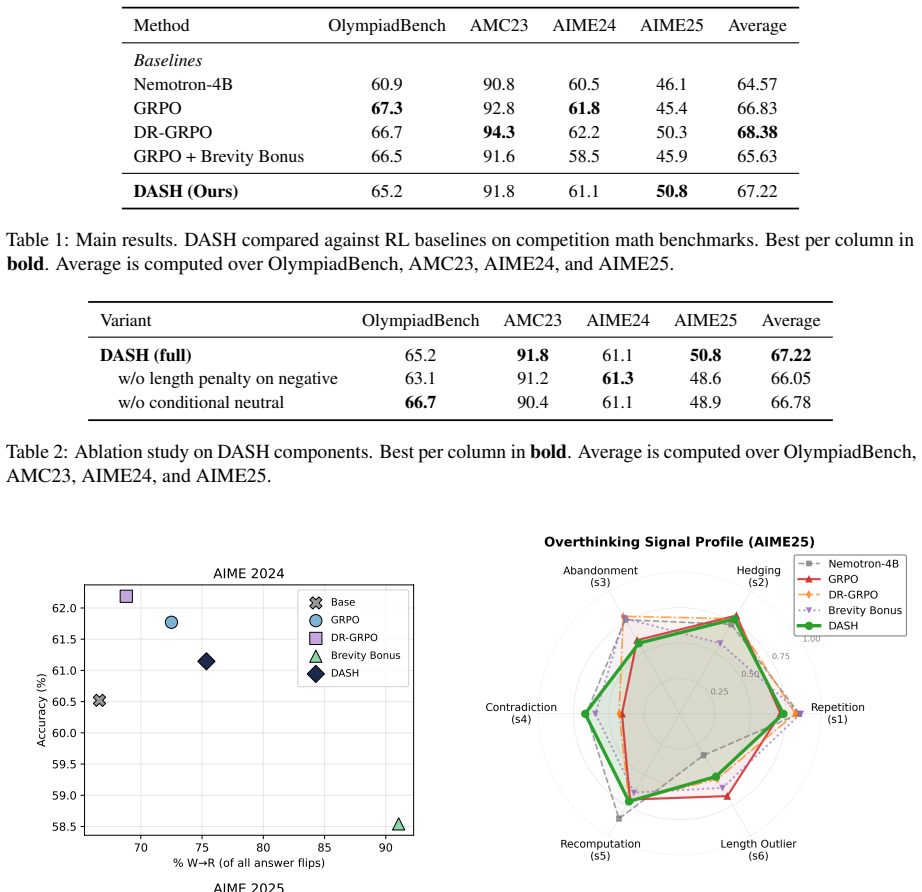
- Achieves 50.8% accuracy on AIME25 versus 45.4% for GRPO
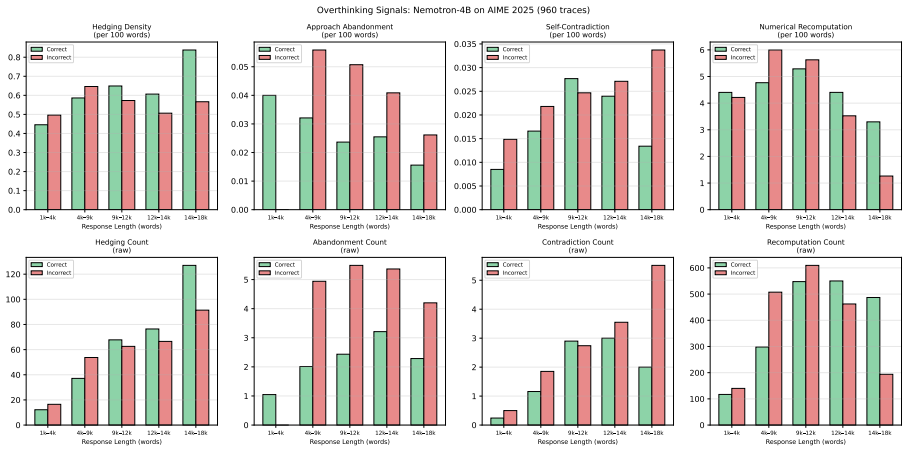
- Reduces rates of overthinking behaviors such as hedging and self-contradiction
- Produces more productive self-correction than length-controlled or standard RL baselines
Where Pith is reading between the lines
- The same intermediate-commitment signal could be used to train models that internalize early stopping without needing ground truth at inference time
- Segment-level drift shaping may transfer to non-math domains where partial answers can be checked against an external verifier
- Finer credit assignment of this form could complement existing length penalties in reasoning RL
Load-bearing premise
Intermediate answer commitments within reasoning traces can provide a cheap proxy for whether subsequent reflection is productive without any additional supervision.
What would settle it
Training a model with DASH and then measuring whether the rate of unproductive self-reflection on held-out AIME problems remains as high as in GRPO-trained models would falsify the claim that the segment credit signal improves reflection productivity.
Figures


read the original abstract
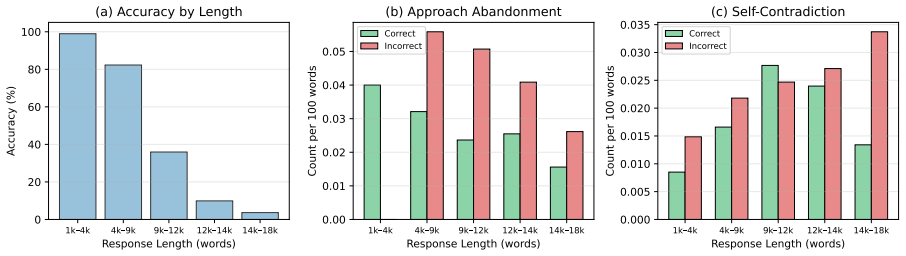
Reasoning language models frequently overthink: generating extended chains of behaviors such as hedging, approach abandonment, and self contradiction that consume tokens without improving answers. We show that these behaviors are not merely a consequence of length; even when controlling for response length, incorrect traces exhibit higher rates of unproductive self-reflection than correct ones. Addressing this requires identifying where self-reflection helps vs hurts, but obtaining these step-level annotations is costly. We observe that intermediate answer commitments within reasoning traces can provide a cheap proxy: by comparing each final answer candidate in the trace to the ground truth, we can determine whether subsequent reflection is productive without any additional supervision. Building on this insight, we propose DASH (Drift Aware advantage SHaping), which assigns segment-level credit based on whether each reasoning segment leads toward or away from correctness. On competition-level math benchmarks, DASH achieves the highest accuracy where overthinking is prevalent (AIME25: 50.8% vs. 45.4% GRPO) while reducing overthinking behaviors and achieving more productive self-correction than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reasoning LMs exhibit overthinking (hedging, approach abandonment, self-contradiction) even after length controls, and that intermediate answer commitments compared to ground truth provide a cheap proxy for labeling whether subsequent reflection segments are productive. It introduces DASH (Drift Aware advantage SHaping) to perform segment-level credit assignment based on this proxy, yielding 50.8% accuracy on AIME25 (vs. 45.4% GRPO) while reducing overthinking and improving self-correction.
Significance. If the proxy is reliable and the length-controlled comparisons hold, the work supplies a supervision-light mechanism for shaping advantages at the segment level, directly targeting unproductive reflection in long-chain reasoning. The reported gains on competition math benchmarks where overthinking is prevalent would be a concrete advance for efficiency in models that already use RL-style training.
major comments (2)
- [Abstract / method description] The central proxy assumption—that an intermediate answer's match or mismatch to ground truth reliably labels whether the following reflection segment is productive—is load-bearing for the entire credit-assignment scheme, yet the abstract provides no quantitative validation of this proxy against any independent measure of productivity (e.g., human annotation or downstream answer improvement). A correct intermediate does not guarantee that further reflection is useless, and an incorrect one does not guarantee that reflection will be recoverable.
- [Abstract] The length-controlled comparison showing higher unproductive self-reflection in incorrect traces is stated as a key motivation, but without the full experimental details it is impossible to assess whether the controls (token budget, prompt, decoding) are sufficient to isolate the effect from other confounders.
minor comments (2)
- [Results] The abstract reports point estimates (50.8% vs 45.4%) but does not mention variance, number of runs, or statistical significance; these should be added to the results section.
- [Method] Notation for DASH components (drift detection, advantage shaping) should be defined explicitly with equations rather than left descriptive.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / method description] The central proxy assumption—that an intermediate answer's match or mismatch to ground truth reliably labels whether the following reflection segment is productive—is load-bearing for the entire credit-assignment scheme, yet the abstract provides no quantitative validation of this proxy against any independent measure of productivity (e.g., human annotation or downstream answer improvement). A correct intermediate does not guarantee that further reflection is useless, and an incorrect one does not guarantee that reflection will be recoverable.
Authors: We agree the proxy is central to DASH and that the abstract lacks explicit quantitative validation against independent measures. The manuscript demonstrates the proxy's utility via end-to-end gains (AIME25 accuracy and reduced overthinking), but to directly address the concern we will add a new analysis (e.g., correlation between proxy labels and observed answer improvement after reflection segments) and explicitly note the proxy's limitations in the revised abstract and discussion. revision: yes
-
Referee: [Abstract] The length-controlled comparison showing higher unproductive self-reflection in incorrect traces is stated as a key motivation, but without the full experimental details it is impossible to assess whether the controls (token budget, prompt, decoding) are sufficient to isolate the effect from other confounders.
Authors: The length-controlled experiments, including specific token budgets, prompt templates, and decoding parameters, are detailed in Section 3.2 and Appendix A. We will revise the abstract to include a concise reference to these controls and ensure the main-text motivation section cross-references the appendix for full reproducibility. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines its segment-level advantage signal via direct comparison of each intermediate answer candidate to external ground truth. This is an independent, externally supplied label rather than a quantity fitted from or defined in terms of the model's own predictions or prior outputs. Reported accuracy gains are measured on standard held-out competition benchmarks (AIME25 etc.) against baselines. No equations, self-citations, or uniqueness theorems appear in the supplied text that would reduce the central claim to a renaming or self-referential fit. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DASH (Drift Aware advantage SHaping)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[2]
2025 , url =
Yi, Jingyang and Wang, Justin and Li, Sida , booktitle =. 2025 , url =
2025
-
[3]
Dai, Muzhi and Yang, Chenxu and Si, Qingyi , booktitle =
-
[4]
2024 , publisher =
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , publisher =
2024
-
[5]
2024 , publisher =
Groeneveld, Dirk and others , booktitle =. 2024 , publisher =
2024
-
[6]
The Twelfth International Conference on Learning Representations , year =
Large Language Models Cannot Self-Correct Reasoning Yet , author =. The Twelfth International Conference on Learning Representations , year =
-
[7]
2023 , organization =
American Mathematics Competitions (AMC) 8, 10A, 10B, 12A, 12B , author =. 2023 , organization =
2023
-
[8]
The Twelfth International Conference on Learning Representations , year =
Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation , author =. The Twelfth International Conference on Learning Representations , year =
-
[9]
Hugging Face Datasets , howpublished =
Math-AI , title =. Hugging Face Datasets , howpublished =. 2025 , publisher =
2025
-
[10]
Hugging Face Datasets , howpublished =
Math-AI , title =. Hugging Face Datasets , howpublished =. 2026 , publisher =
2026
-
[11]
Advances in Neural Information Processing Systems , volume =
Solving Quantitative Reasoning Problems with Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the
-
[14]
2024 , url =
Learning to Reason with. 2024 , url =
2024
-
[15]
2024 , month = nov, url =
2024
-
[19]
Efficiently Scaling
Yichao Fu and Junda Chen and Siqi Zhu and Zheyu Fu and Zhongdongming Dai and Yonghao Zhuang and Yian Ma and Aurick Qiao and Tajana Rosing and Ion Stoica and Hao Zhang , booktitle=. Efficiently Scaling. 2026 , url=
2026
-
[21]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[22]
2025 , eprint =
Llama-Nemotron: Efficient Reasoning Models , author =. 2025 , eprint =
2025
-
[23]
2026 , eprint =
Circular Reasoning: Understanding Self-Reinforcing Loops in Large Reasoning Models , author =. 2026 , eprint =
2026
-
[25]
2026 , eprint =
Batched Contextual Reinforcement: A Task-Scaling Law for Efficient Reasoning , author =. 2026 , eprint =
2026
-
[30]
2025 , eprint =
Revisiting Overthinking in Long Chain-of-Thought from the Perspective of Self-Doubt , author =. 2025 , eprint =
2025
-
[31]
Understanding
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , booktitle =. Understanding. 2025 , url =
2025
-
[32]
2025 , url =
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and others , booktitle =. 2025 , url =
2025
-
[33]
2025 , howpublished=
2025
-
[34]
2024 , howpublished=
2024
-
[36]
2025 , url =
Aggarwal, Pranjal and Welleck, Sean , booktitle =. 2025 , url =
2025
-
[41]
2025 , editor =
Kazemnejad, Amirhossein and Aghajohari, Milad and Portelance, Eva and Sordoni, Alessandro and Reddy, Siva and Courville, Aaron and Le Roux, Nicolas , booktitle =. 2025 , editor =
2025
-
[42]
Segment Policy Optimization: Effective Segment-Level Credit Assignment in
Guo, Yiran and Xu, Lijie and Liu, Jie and Dan, Ye and Qiu, Shuang , booktitle =. Segment Policy Optimization: Effective Segment-Level Credit Assignment in. 2025 , url =
2025
-
[44]
2025 , eprint =
Dynamic Early Exit in Reasoning Models , author =. 2025 , eprint =
2025
-
[46]
Thinkless:
Fang, Gongfan and Ma, Xinyin and Wang, Xinchao , booktitle =. Thinkless:. 2025 , url =
2025
-
[50]
Pranjal Aggarwal and Sean Welleck. 2025. https://openreview.net/forum?id=4jdIxXBNve L1 : Controlling how long a reasoning model thinks with reinforcement learning . In Proceedings of the Second Conference on Language Modeling
2025
-
[51]
AI-MO Team . 2024. NuminaMath 1.5 . https://huggingface.co/datasets/AI-MO/NuminaMath-1.5
2024
-
[52]
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2024. https://arxiv.org/abs/2412.21187 Do NOT think that much for 2+3=? on the overthinking of o1-like LLM s . Preprint, arXiv:2412.21187
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
DeepSeek-AI . 2025. https://arxiv.org/abs/2501.12948 DeepSeek-R1 : Incentivizing reasoning capability in LLM s via reinforcement learning . Preprint, arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [54]
-
[55]
Gongfan Fang, Xinyin Ma, and Xinchao Wang. 2025. https://openreview.net/forum?id=ariVQf0KZx Thinkless: LLM learns when to think . In Advances in Neural Information Processing Systems
2025
-
[56]
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Yonghao Zhuang, Yian Ma, Aurick Qiao, Tajana Rosing, Ion Stoica, and Hao Zhang. 2026. https://openreview.net/forum?id=nn51ewu5k2 Efficiently scaling LLM reasoning programs with certaindex . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
-
[57]
Yiran Guo, Lijie Xu, Jie Liu, Ye Dan, and Shuang Qiu. 2025. https://openreview.net/forum?id=9osvTOYbT4 Segment policy optimization: Effective segment-level credit assignment in RL for large language models . In Advances in Neural Information Processing Systems
2025
-
[58]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. https://aclanthology.org/2024.acl-long.211/ O lympiad B ench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems . In Proceedings of...
2024
-
[59]
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. 2025. https://arxiv.org/abs/2504.01296 Thinkprune: Pruning long chain-of-thought of LLM s via reinforcement learning . Preprint, arXiv:2504.01296
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Jian Hu. 2025. https://arxiv.org/abs/2501.03262 REINFORCE++ : A simple and efficient approach for aligning large language models . Preprint, arXiv:2501.03262
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. 2025. https://proceedings.mlr.press/v267/kazemnejad25a.html VinePPO : Refining credit assignment in RL training of LLM s . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Mach...
2025
- [62]
-
[63]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let's verify step by step. In International Conference on Learning Representations, volume 2024, pages 39578--39601
2024
- [64]
-
[65]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. https://openreview.net/forum?id=5PAF7PAY2Y Understanding R1-Zero-Like training: A critical perspective . In Proceedings of the Second Conference on Language Modeling
2025
- [66]
-
[67]
Math-AI. 2025. Aime24: Math reasoning benchmark. https://huggingface.co/datasets/math-ai/aime24
2025
-
[68]
Math-AI. 2026. Aime25: American invitational mathematics examination 2025. https://huggingface.co/datasets/math-ai/aime25
2026
-
[69]
Mathematical Association of America . 2023. https://maa.org/student-programs/amc/ American Mathematics Competitions (AMC) 8, 10A, 10B, 12A, 12B . Mathematical Association of America, Washington, DC. Competitions aimed at middle and high school students
2023
-
[70]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori Hashimoto. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1025 s1: Simple test-time scaling . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2027...
-
[71]
Niels M \"u ndler, Jingxuan He, Slobodan Jenko, and Martin Vechev. 2024. Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. In The Twelfth International Conference on Learning Representations
2024
- [72]
-
[73]
Open R1 Team . 2025. OpenR1-Math-220k . https://huggingface.co/datasets/open-r1/OpenR1-Math-220k. Apache 2.0 License
2025
- [74]
- [75]
-
[76]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279--1297
2025
- [78]
- [79]
- [80]
-
[81]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.acl-long.510 Math-shepherd: Verify and reinforce LLM s step-by-step without human annotations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
-
[82]
Xinyan Wang, Xiaogeng Liu, and Chaowei Xiao. 2026. https://arxiv.org/abs/2603.22016 ROM : Real-time overthinking mitigation via streaming detection and intervention . Preprint, arXiv:2603.22016
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [83]
-
[84]
Yue Wang, Qiuzhi Liu, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Linfeng Song, Dian Yu, Juntao Li, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025 b . https://arxiv.org/abs/2501.18585 Thoughts are all over the place: On the underthinking of o1-like LLM s . Preprint, arXiv:2501.18585
-
[85]
Zihao Wei, Liang Pang, Jiahao Liu, Jingcheng Deng, Shicheng Xu, Zenghao Duan, Jingang Wang, Fei Sun, Xunliang Cai, Huawei Shen, and Xueqi Cheng. 2025. https://arxiv.org/abs/2508.17627 Stop spinning wheels: Mitigating LLM overthinking via mining patterns for early reasoning exit . Preprint, arXiv:2508.17627
- [86]
- [87]
- [88]
-
[89]
Jingyang Yi, Justin Wang, and Sida Li. 2025. https://openreview.net/forum?id=MJvwM5dBZM ShorterBetter : Guiding reasoning models to find optimal inference length for efficient reasoning . In Advances in Neural Information Processing Systems
2025
-
[90]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, and 1 others. 2025. https://openreview.net/forum?id=2a36EMSSTp DAPO : An open-source LLM reinforcement learning system at scale . In Advances in Neural Information Processing Systems
2025
-
[91]
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, Tiantian Fan, Zhengyin Du, Xiangpeng Wei, Xiangyu Yu, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, and 8 others. 2025. https://arxiv.org/abs/2504.05118 VAPO : Efficient and reliable reinforcement learning for advanced reasoni...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[92]
Shu Zhou, Rui Ling, Junan Chen, Xin Wang, Tao Fan, and Hao Wang. 2026. https://arxiv.org/abs/2604.10739 When more thinking hurts: Overthinking in LLM test-time compute scaling . Preprint, arXiv:2604.10739
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.