Large Language Models for Multi-Lingual Equivalent Mutant Detection: An Extended Empirical Study
Pith reviewed 2026-07-02 09:04 UTC · model grok-4.3
The pith
Fine-tuned large language models detect equivalent mutants more accurately than traditional methods across Java and C
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-based approaches achieve higher F1-scores than the evaluated traditional methods, with fine-tuned code embedding yielding the highest detection accuracy among the tested strategies. Moreover, fine-tuned LLMs demonstrate measurable generalization across programming languages.
What carries the argument
Fine-tuned large language models that embed code to classify pairs of mutants as equivalent or non-equivalent
If this is right
- LLM approaches reach higher F1-scores than the compared traditional detection methods.
- Fine-tuned code embedding gives the highest accuracy among the LLM strategies tested.
- LLM methods maintain inference times comparable to existing machine-learning models.
- Fine-tuned LLMs show measurable cross-language generalization between Java and C.
Where Pith is reading between the lines
- If the accuracy gains hold on broader data, mutation testing could become less expensive to apply in practice.
- The same embedding-based classification approach might transfer to other code-semantics tasks that require distinguishing behavioral equivalence.
Load-bearing premise
The 3,302 Java and 1,088 C mutant pairs used for benchmarking are representative of real-world equivalent mutants and the state-of-the-art baseline methods were implemented without bias or implementation differences that favor the LLM approaches.
What would settle it
A new benchmark set of mutant pairs drawn from additional languages or larger real-world projects on which the LLM strategies no longer produce higher F1-scores than the traditional baselines would falsify the central claim.
Figures

read the original abstract
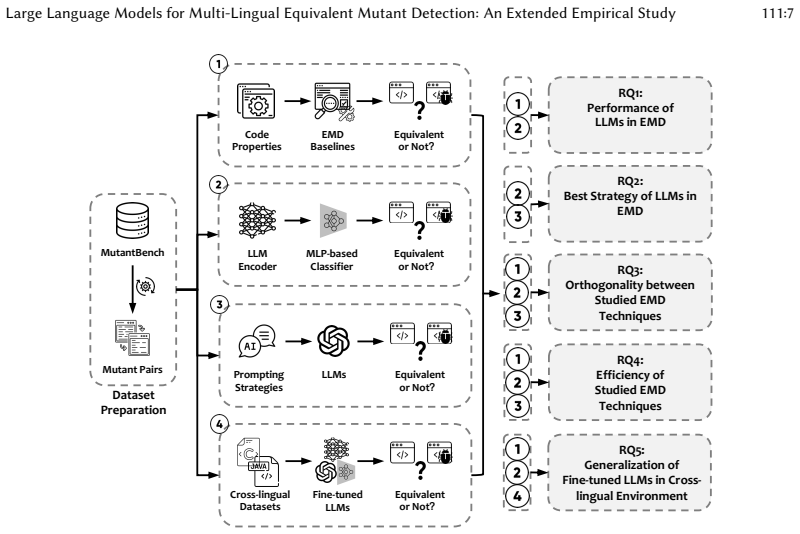
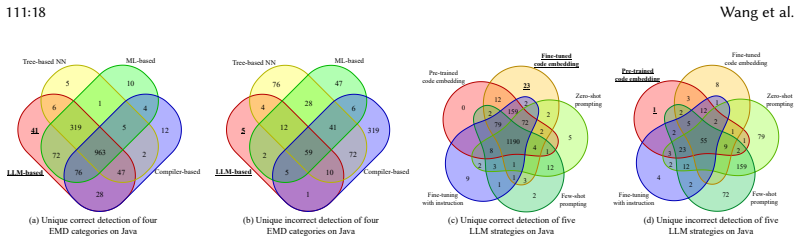
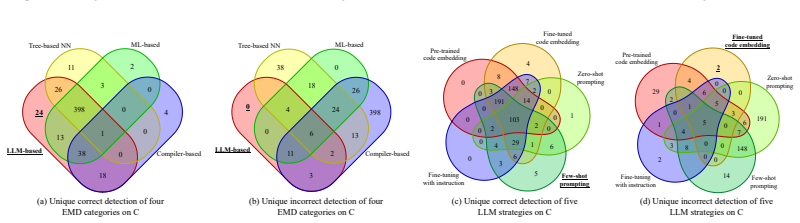
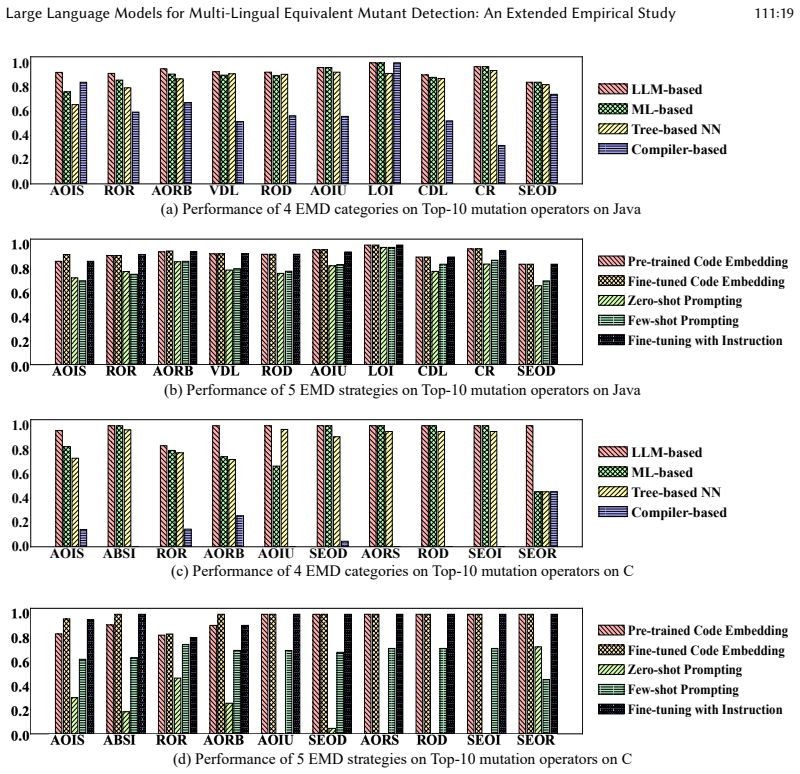
Mutation testing is a powerful technique for ensuring software quality. However, the presence of equivalent mutants introduces unnecessary costs and biases, limiting its practical effectiveness. Although numerous equivalent mutant detection (EMD) methods have been proposed, they often face distinct challenges: pure-code analysis methods can be limited by their reliance on specific compiler infrastructures, while existing machine-learning approaches remain constrained by scarce training data and limited generalization to unseen mutants. Large language models (LLMs) have recently demonstrated remarkable performance across diverse code-related tasks by better capturing program semantics. Yet their potential for EMD remains largely unexplored, particularly in the multi-lingual context. This paper presents the first comprehensive empirical study on LLMs for EMD, using 3,302 Java and 1,088 C mutant pairs to benchmark against state-of-the-art methods, explore strategy variations, assess efficiency, and evaluate cross-lingual generalization. Experimental results show that LLM-based approaches achieve higher F1-scores than the evaluated traditional methods, with fine-tuned code embedding yielding the highest detection accuracy among the tested strategies. Moreover, LLM-based approaches strike a practical balance between effectiveness and efficiency with inference times comparable to existing machine-learning models. Importantly, fine-tuned LLMs demonstrate measurable generalization across programming languages. These findings establish LLMs as a viable and efficient approach for tackling the longstanding challenge of equivalent mutant detection, offering new directions for advancing mutation testing in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first comprehensive empirical study on large language models (LLMs) for equivalent mutant detection (EMD) in mutation testing. It benchmarks LLM strategies (including fine-tuned code embeddings) against traditional methods on a dataset of 3,302 Java and 1,088 C mutant pairs, reporting higher F1 scores for LLMs, best performance from fine-tuned embeddings, practical efficiency (inference times comparable to prior ML models), and measurable cross-lingual generalization.
Significance. If the results hold under rigorous validation, the work would advance mutation testing practice by offering a more effective and efficient solution to the equivalent-mutant problem, a longstanding barrier to adoption. The multi-lingual scope and explicit efficiency measurements are strengths; the study also supplies a sizable new benchmark that future EMD research can build upon.
major comments (3)
- [§4] §4 (Dataset and labeling): The construction and validation of the 4,390 ground-truth labels receive insufficient detail; no inter-rater agreement statistics, coverage thresholds, or external validation against test suites are reported. Because every F1 comparison rests on these labels, the absence is load-bearing for the central superiority claim.
- [§5] §5 (Baseline reproduction): The paper provides no source code, exact reproduction instructions, or compiler-configuration details for the state-of-the-art traditional and prior ML baselines. Systematic implementation differences could therefore artifactually inflate the reported LLM advantage.
- [§6.3] §6.3 (Cross-lingual evaluation): The cross-lingual generalization experiments do not state whether any mutant or code overlap exists between the Java and C collections, nor do they describe the precise train/test partitioning used to enforce language separation. This information is required to substantiate the generalization result.
minor comments (3)
- [Abstract] Abstract and §6: Include error bars, number of runs, or statistical significance tests alongside the F1 scores to allow readers to assess the stability of the reported improvements.
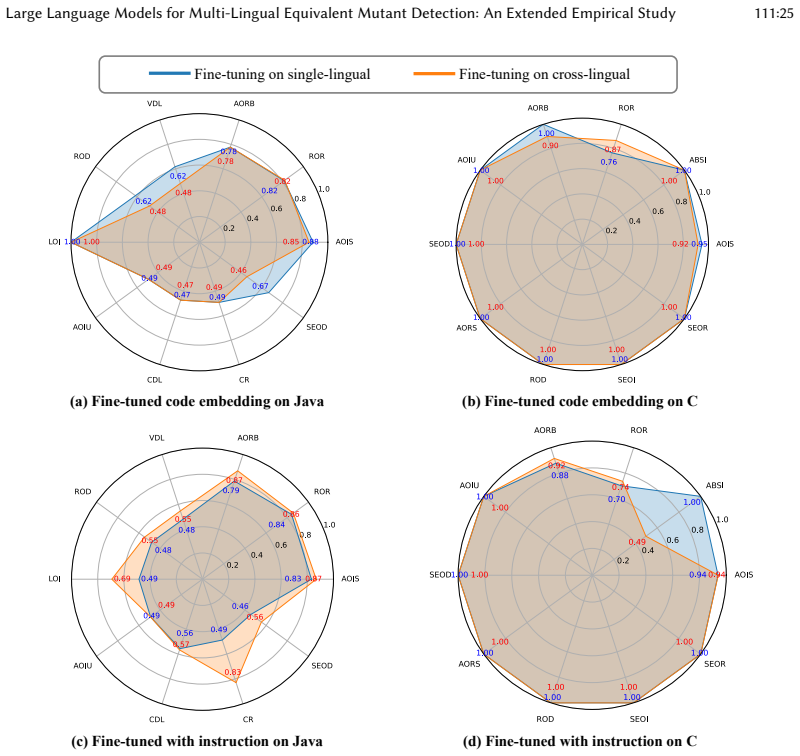
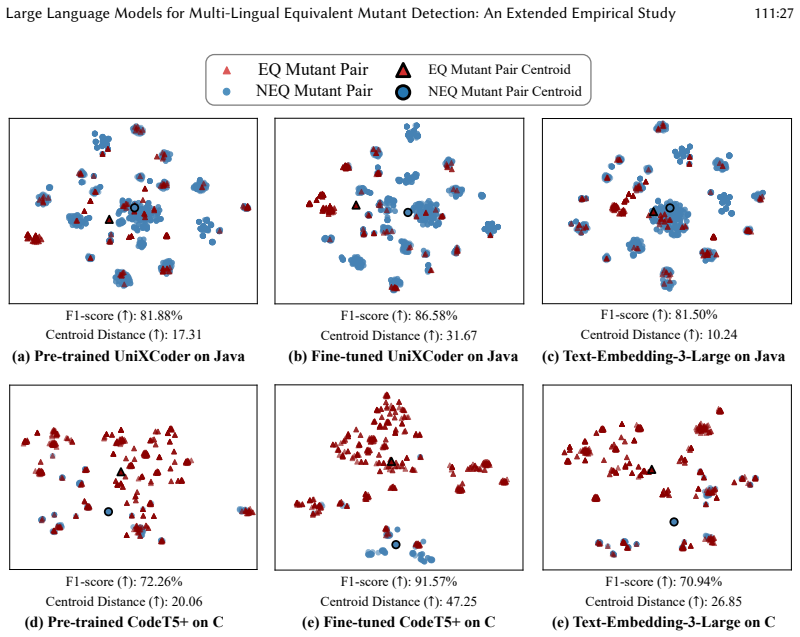
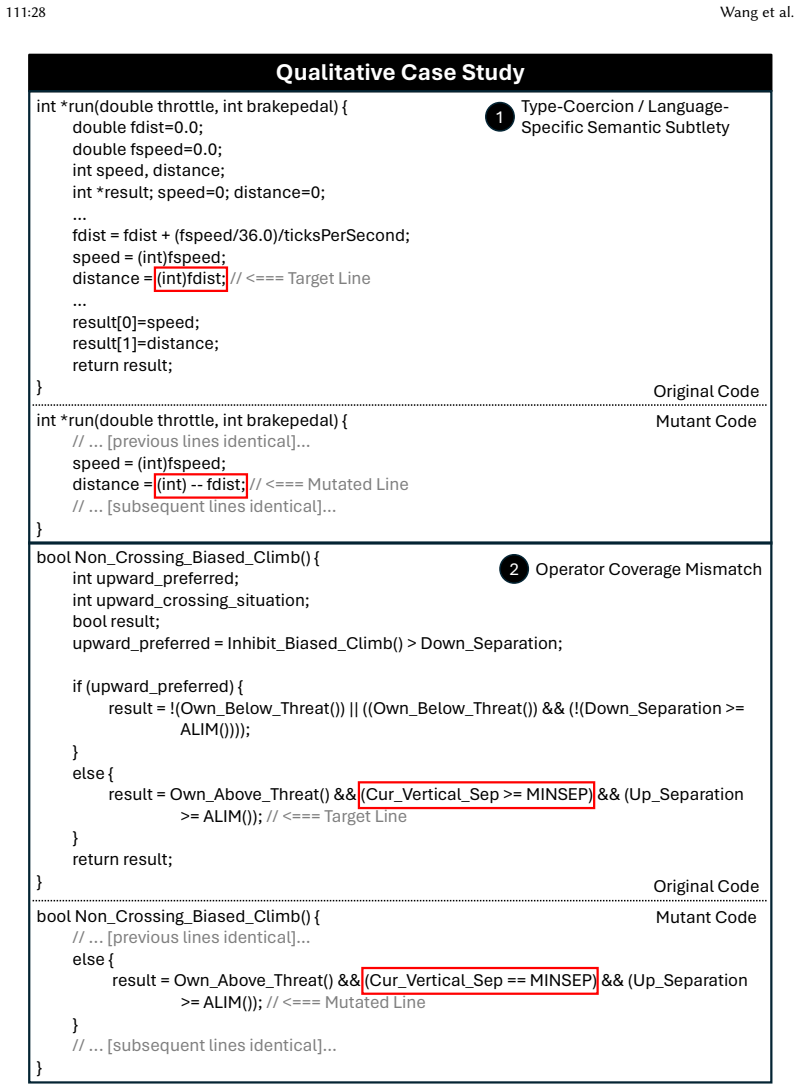
- [Table 1] Table 1 and Figure 3: Ensure axis labels, legend entries, and caption text are fully self-contained so that efficiency and accuracy trade-offs can be interpreted without reference to the main text.
- [§2] Related-work section: Add explicit citations to the most recent LLM-based code-analysis papers that post-date the baselines used, to clarify the novelty boundary.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications where possible and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4] §4 (Dataset and labeling): The construction and validation of the 4,390 ground-truth labels receive insufficient detail; no inter-rater agreement statistics, coverage thresholds, or external validation against test suites are reported. Because every F1 comparison rests on these labels, the absence is load-bearing for the central superiority claim.
Authors: We agree that §4 would benefit from expanded description of the labeling process. The ground-truth labels were produced via a hybrid approach combining static analysis heuristics with author-led manual review on the collected mutant pairs; however, formal inter-rater agreement metrics were not computed because labeling was performed by a single primary researcher with internal consistency checks rather than multiple independent raters. In the revised manuscript we will add a dedicated subsection detailing the exact heuristics, any coverage or confidence thresholds applied, the manual review protocol, and any post-hoc validation steps performed against available test suites. This addition will directly address the concern that the F1 results rest on insufficiently documented labels. revision: yes
-
Referee: [§5] §5 (Baseline reproduction): The paper provides no source code, exact reproduction instructions, or compiler-configuration details for the state-of-the-art traditional and prior ML baselines. Systematic implementation differences could therefore artifactually inflate the reported LLM advantage.
Authors: We concur that reproducibility details for the baselines are essential. The traditional and prior ML baselines were re-implemented following the descriptions in their respective source papers, using the same datasets and evaluation protocol; however, the submission did not include the re-implementation code, compiler flags, or step-by-step reproduction scripts. In the revision we will add a reproducibility appendix (or supplementary repository link) that supplies the exact source code used, compiler configurations, and any deviations from the original baseline implementations, thereby allowing independent verification that the reported LLM advantage is not an artifact of implementation differences. revision: yes
-
Referee: [§6.3] §6.3 (Cross-lingual evaluation): The cross-lingual generalization experiments do not state whether any mutant or code overlap exists between the Java and C collections, nor do they describe the precise train/test partitioning used to enforce language separation. This information is required to substantiate the generalization result.
Authors: We confirm that the Java and C mutant-pair collections were assembled from entirely disjoint codebases with no shared mutants, functions, or files, ensuring zero overlap. For the cross-lingual experiments, models were trained exclusively on one language and evaluated on the other using a strict language-separated split (i.e., no intra-language mixing in the test sets). We will revise §6.3 to state these facts explicitly, including the precise train/test partitioning ratios and confirmation of zero overlap, thereby substantiating the reported cross-lingual generalization. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with external baselines
full rationale
This is an empirical study that benchmarks LLM variants against independently described state-of-the-art methods on fixed mutant-pair datasets. No equations, fitted parameters, uniqueness theorems, or ansatzes are introduced whose outputs reduce by construction to the paper's own inputs or self-citations. All reported F1 scores and cross-lingual results are direct measurements against external baselines; the central claims therefore remain falsifiable by re-running the same experiments on the released data rather than being definitionally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 3,302 Java and 1,088 C mutant pairs constitute a valid benchmark for evaluating equivalent mutant detection methods.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Konstantinos Adamopoulos, Mark Harman, and Robert M Hierons. 2004. How to overcome the equivalent mutant problem and achieve tailored selective mutation using co-evolution. InGenetic and Evolutionary Computation–GECCO 2004: Genetic and Evolutionary Computation Conference, Seattle, W A, USA, June 26-30, 2004. Proceedings, Part II. Springer, 1338–1349
2004
- [3]
- [4]
-
[5]
James H Andrews, Lionel C Briand, and Yvan Labiche. 2005. Is mutation an appropriate tool for testing experiments?. InProceedings of the 27th international conference on Software engineering. 402–411
2005
-
[6]
James H Andrews, Lionel C Briand, Yvan Labiche, and Akbar Siami Namin. 2006. Using mutation analysis for assessing and comparing testing coverage criteria.IEEE Transactions on Software Engineering32, 8 (2006), 608–624
2006
-
[7]
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report.arXiv preprint arXiv:2305.10403 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Paolo Arcaini, Angelo Gargantini, Elvinia Riccobene, and Paolo Vavassori. 2017. A novel use of equivalent mutants for static anomaly detection in software artifacts.Information and Software Technology81 (2017), 52–64
2017
-
[9]
Michael Baer, Norbert Oster, and Michael Philippsen. 2020. Mutantdistiller: Using symbolic execution for automatic detection of equivalent mutants and generation of mutant killing tests. In2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 294–303
2020
-
[10]
Ezio Bartocci, Leonardo Mariani, Dejan Ničković, and Drishti Yadav. 2023. Property-based mutation testing. In2023 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 222–233
2023
-
[11]
Moritz Beller, Chu-Pan Wong, Johannes Bader, Andrew Scott, Mateusz Machalica, Satish Chandra, and Erik Meijer
-
[12]
In2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP)
What it would take to use mutation testing in industry—a study at facebook. In2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 268–277
-
[13]
Claudinei Brito, Vinicius HS Durelli, Rafael S Durelli, Simone RS de Souza, Auri MR Vincenzi, and Márcio Eduardo Delamaro. 2020. A preliminary investigation into using machine learning algorithms to identify minimal and equivalent mutants. In2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 304–313
2020
-
[14]
Nadia Burkart and Marco F Huber. 2021. A survey on the explainability of supervised machine learning.Journal of Artificial Intelligence Research70 (2021), 245–317
2021
-
[15]
Cristiano Cervellera and Danilo Macciò. 2017. Distribution-preserving stratified sampling for learning problems. IEEE Transactions on Neural Networks and Learning Systems29, 7 (2017), 2886–2895
2017
-
[16]
Thierry Titcheu Chekam, Mike Papadakis, Maxime Cordy, and Yves Le Traon. 2021. Killing stubborn mutants with symbolic execution.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 2 (2021), 1–23
2021
-
[17]
Seungjoon Chung and Shin Yoo. 2022. Augmenting Equivalent Mutant Dataset Using Symbolic Execution. In2022 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 150–159
2022
-
[18]
Xavier Devroey, Gilles Perrouin, Mike Papadakis, Axel Legay, Pierre-Yves Schobbens, and Patrick Heymans. 2018. Model-based mutant equivalence detection using automata language equivalence and simulations.Journal of Systems and Software141 (2018), 1–15. J. ACM, Vol. 1, No. 1, Article 111. Publication date: July 2026. Large Language Models for Multi-Lingual...
2018
- [19]
-
[20]
Yali Du and Zhongxing Yu. 2023. Pre-training code representation with semantic flow graph for effective bug localization. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 579–591
2023
-
[21]
Sidong Feng and Chunyang Chen. 2024. Prompting Is All You Need: Automated Android Bug Replay with Large Language Models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
2024
-
[22]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[23]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Rohit Gheyi, Márcio Ribeiro, Beatriz Souza, Marcio Guimarães, Leo Fernandes, Marcelo d’Amorim, Vander Alves, Leopoldo Teixeira, and Baldoino Fonseca. 2021. Identifying method-level mutation subsumption relations using Z3. Information and Software Technology132 (2021), 106496
2021
-
[25]
Dan Gong, Tiantian Wang, Xiaohong Su, and Yanhang Zhang. 2022. Equivalent mutants detection based on weighted software behavior graph.International Journal of Software Engineering and Knowledge Engineering32, 06 (2022), 819–843
2022
-
[26]
Rahul Gopinath, Carlos Jensen, and Alex Groce. 2014. Mutations: How close are they to real faults?. In2014 IEEE 25th International Symposium on Software Reliability Engineering. IEEE, 189–200
2014
-
[27]
Rahul Gopinath, Björn Mathis, and Andreas Zeller. 2018. If You Can’t Kill a Supermutant, You Have a Problem. In 2018 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 18–24
2018
-
[28]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Marcio Augusto Guimarães, Leo Fernandes, Márcio Ribeiro, Marcelo d’Amorim, and Rohit Gheyi. 2020. Optimizing mutation testing by discovering dynamic mutant subsumption relations. In2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST). IEEE, 198–208
2020
-
[30]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. Unixcoder: Unified cross-modal pre-training for code representation.arXiv preprint arXiv:2203.03850(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svy- atkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Mark Harman, Rob Hierons, and Sebastian Danicic. 2001. The relationship between program dependence and mutation analysis.Mutation testing for the new century(2001), 5–13
2001
-
[35]
Mark Harman, Jillian Ritchey, Inna Harper, Shubho Sengupta, Ke Mao, Abhishek Gulati, Christopher Foster, and Hervé Robert. 2025. Mutation-Guided LLM-based Test Generation at Meta. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 180–191
2025
-
[36]
Dominik Holling, Sebastian Banescu, Marco Probst, Ana Petrovska, and Alexander Pretschner. 2016. Nequivack: Assessing mutation score confidence. In2016 IEEE Ninth International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 152–161
2016
-
[37]
Homepage. 2025. https://github.com/SpanShu96/Large-Language-Models-for-Multi-Lingual-Equivalent-Mutant- Detection-An-Extended-Empirical-Study
2025
-
[38]
Mahdi Houshmand and Samad Paydar. 2017. TCE+: An extension of the tce method for detecting equivalent mutants in java programs. InFundamentals of Software Engineering: 7th International Conference, FSEN 2017, Tehran, Iran, April 26–28, 2017, Revised Selected Papers 7. Springer, 164–179
2017
-
[39]
Kai Huang, Xiangxin Meng, Jian Zhang, Yang Liu, Wenjie Wang, Shuhao Li, and Yuqing Zhang. 2023. An empirical study on fine-tuning large language models of code for automated program repair. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 1162–1174
2023
-
[40]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024). J. ACM, Vol. 1, No. 1, Article 111. Publication date: July 2026. 111:34 Wang et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Yue Jia and Mark Harman. 2009. Higher order mutation testing.Information and Software Technology51, 10 (2009), 1379–1393
2009
-
[42]
Yue Jia and Mark Harman. 2010. An analysis and survey of the development of mutation testing.IEEE transactions on software engineering37, 5 (2010), 649–678
2010
- [43]
-
[44]
Ernst, Reid Holmes, and Gordon Fraser
René Just, Darioush Jalali, Laura Inozemtseva, Michael D. Ernst, Reid Holmes, and Gordon Fraser. 2014. Are mutants a valid substitute for real faults in software testing?. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering(Hong Kong, China)(FSE 2014). Association for Computing Machinery, New York, NY, USA,...
- [45]
-
[46]
Jinhan Kim, Juyoung Jeon, Shin Hong, and Shin Yoo. 2022. Predictive mutation analysis via the natural language channel in source code.ACM Transactions on Software Engineering and Methodology (TOSEM)31, 4 (2022), 1–27
2022
-
[47]
Marinos Kintis, Mike Papadakis, Yue Jia, Nicos Malevris, Yves Le Traon, and Mark Harman. 2017. Detecting trivial mutant equivalences via compiler optimisations.IEEE Transactions on Software Engineering44, 4 (2017), 308–333
2017
-
[48]
Marinos Kintis, Mike Papadakis, Andreas Papadopoulos, Evangelos Valvis, and Nicos Malevris. 2016. Analysing and comparing the effectiveness of mutation testing tools: A manual study. In2016 IEEE 16th International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 147–156
2016
-
[49]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[50]
Kruskal and W
William H. Kruskal and W. Allen Wallis. 1952. Use of Ranks in One-Criterion Variance Analysis.J. Amer. Statist. Assoc.47, 260 (1952), 583–621
1952
-
[51]
Kaufman, Ryan Featherman, Hannah Potter, Ardi Madadi, and René Just
Benjamin Kushigian, Samuel J. Kaufman, Ryan Featherman, Hannah Potter, Ardi Madadi, and René Just. 2024. Equivalent Mutants in the Wild: Identifying and Efficiently Suppressing Equivalent Mutants for Java Programs. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for ...
-
[52]
Benjamin Kushigian, Amit Rawat, and René Just. 2019. Medusa: Mutant equivalence detection using satisfiability analysis. In2019 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 77–82
2019
-
[53]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al . 2023. StarCoder: may the source be with you!arXiv preprint arXiv:2305.06161(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Tsz-On Li, Wenxi Zong, Yibo Wang, Haoye Tian, Ying Wang, Shing-Chi Cheung, and Jeff Kramer. 2023. Nuances are the key: Unlocking chatgpt to find failure-inducing tests with differential prompting. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 14–26
2023
-
[55]
Wen Li, Li Li, and Haipeng Cai. 2022. On the vulnerability proneness of multilingual code. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Singapore, Singapore)(ESEC/FSE 2022). Association for Computing Machinery, New York, NY, USA, 847–859. https: //doi.org/10.1145/354...
-
[56]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. 2022. Diffusion-lm improves controllable text generation.Advances in Neural Information Processing Systems35 (2022), 4328–4343
2022
-
[57]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2024. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in Neural Information Processing Systems36 (2024)
2024
-
[58]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.Comput. Surveys55, 9 (2023), 1–35
2023
-
[59]
Yiling Lou, Dan Hao, and Lu Zhang. 2015. Mutation-based test-case prioritization in software evolution. In2015 IEEE 26th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 46–57
2015
-
[60]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation.arXiv preprint arXiv:2102.04664(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[61]
Yucheng Lu, Youngsuk Park, Lifan Chen, Yuyang Wang, Christopher De Sa, and Dean Foster. 2021. Variance reduced training with stratified sampling for forecasting models. InInternational Conference on Machine Learning. PMLR, 7145–7155. J. ACM, Vol. 1, No. 1, Article 111. Publication date: July 2026. Large Language Models for Multi-Lingual Equivalent Mutant ...
2021
-
[62]
Wei Ma, Shangqing Liu, Wenhan Wang, Qiang Hu, Ye Liu, Cen Zhang, Liming Nie, and Yang Liu. 2023. The scope of chatgpt in software engineering: A thorough investigation.arXiv preprint arXiv:2305.12138(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Lech Madeyski, Wojciech Orzeszyna, Richard Torkar, and Mariusz Jozala. 2013. Overcoming the equivalent mutant problem: A systematic literature review and a comparative experiment of second order mutation.IEEE Transactions on Software Engineering40, 1 (2013), 23–42
2013
-
[64]
Mohsen Moradi Moghadam, Mehdi Bagherzadeh, Raffi Khatchadourian, and Hamid Bagheri. 2023. muAkka: Mutation Testing for Actor Concurrency in Akka using Real-World Bugs. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 262–274
2023
-
[65]
Muhammad Rashid Naeem, Tao Lin, Hamad Naeem, and Hailu Liu. 2020. A machine learning approach for classification of equivalent mutants.Journal of Software: Evolution and Process32, 5 (2020), e2238
2020
- [66]
-
[67]
A Jefferson Offutt and Jie Pan. 1997. Automatically detecting equivalent mutants and infeasible paths.Software testing, verification and reliability7, 3 (1997), 165–192
1997
-
[68]
Saeyoon Oh, Seongmin Lee, and Shin Yoo. 2021. Effectively sampling higher order mutants using causal effect. In 2021 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 19–24
2021
-
[69]
Milos Ojdanic, Ezekiel Soremekun, Renzo Degiovanni, Mike Papadakis, and Yves Le Traon. 2023. Mutation testing in evolving systems: Studying the relevance of mutants to code evolution.ACM Transactions on Software Engineering and Methodology32, 1 (2023), 1–39
2023
-
[70]
OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue. https://openai.com/blog/chatgpt
2022
-
[71]
OpenAI. 2024. https://openai.com/
2024
-
[72]
OpenAI. 2024. New Generation of Embedding Model. https://openai.com/blog/new-embedding-models-and-api- updates
2024
-
[73]
OpenAI. 2025. Introducing OpenAI o3 and o4-mini. https://openai.com/index/introducing-o3-and-o4-mini/
2025
-
[74]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[75]
Mike Papadakis, Marcio Delamaro, and Yves Le Traon. 2014. Mitigating the effects of equivalent mutants with mutant classification strategies.Science of Computer Programming95 (2014), 298–319
2014
-
[76]
Mike Papadakis, Yue Jia, Mark Harman, and Yves Le Traon. 2015. Trivial compiler equivalence: A large scale empirical study of a simple, fast and effective equivalent mutant detection technique. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE, 936–946
2015
-
[77]
Mike Papadakis, Marinos Kintis, Jie Zhang, Yue Jia, Yves Le Traon, and Mark Harman. 2019. Mutation testing advances: an analysis and survey. InAdvances in computers. Vol. 112. Elsevier, 275–378
2019
-
[78]
Mike Papadakis and Yves Le Traon. 2013. Mutation testing strategies using mutant classification. InProceedings of the 28th Annual ACM Symposium on Applied Computing. 1223–1229
2013
-
[79]
Mike Papadakis and Yves Le Traon. 2015. Metallaxis-FL: mutation-based fault localization.Software Testing, Verification and Reliability25, 5-7 (2015), 605–628
2015
-
[80]
Samuel Peacock, Lin Deng, Josh Dehlinger, and Suranjan Chakraborty. 2021. Automatic equivalent mutants classifica- tion using abstract syntax tree neural networks. In2021 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 13–18
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.