AmbiDrop: Ambisonics-Based Array-Agnostic Neural Speech Enhancement
Pith reviewed 2026-07-02 05:26 UTC · model grok-4.3
The pith
AmbiDrop achieves array-agnostic neural speech enhancement by feeding Ambisonics signals to the network after Ambisonics Signal Matching and training with channel-wise dropout to simulate real-array errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
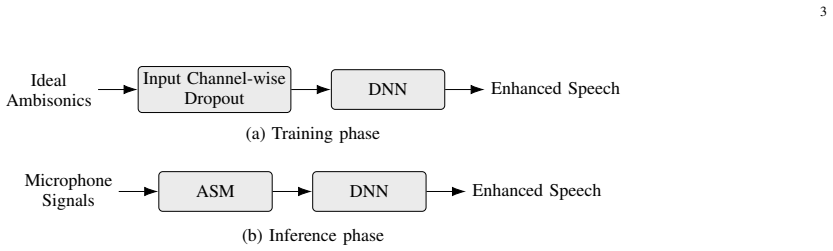
AmbiDrop decouples the DNN from physical sensor arrangements by using ideal Ambisonics as its input representation; a channel-wise dropout layer applied during training simulates the encoding errors that arise when real arrays are mapped to Ambisonics via Ambisonics Signal Matching, allowing the same trained network to process signals from arbitrary geometries at inference time.
What carries the argument
Ambisonics representation combined with a channel-wise dropout layer that simulates Ambisonics encoding errors from non-ideal arrays.
If this is right
- A single trained model handles diverse unseen array layouts without retraining.
- The network continues to function when individual sensors fail.
- Smaller network scales remain effective, supporting edge-device deployment.
- The same framework processes both simulated and real-world recordings with maintained quality.
Where Pith is reading between the lines
- The method could standardize input representations across different wearable or distributed audio devices.
- Similar dropout-based domain randomization might apply to other array-dependent audio tasks such as source localization.
- If Ambisonics order is increased, the approach might trade higher spatial fidelity for greater robustness to array mismatch.
Load-bearing premise
Ambisonics Signal Matching can produce signals close enough to ideal Ambisonics that the dropout-trained network generalizes without large performance loss.
What would settle it
Performance measurements on real arrays where Ambisonics Signal Matching produces large deviations from ideal Ambisonics, showing a sharp drop relative to fixed-geometry baselines.
Figures

read the original abstract
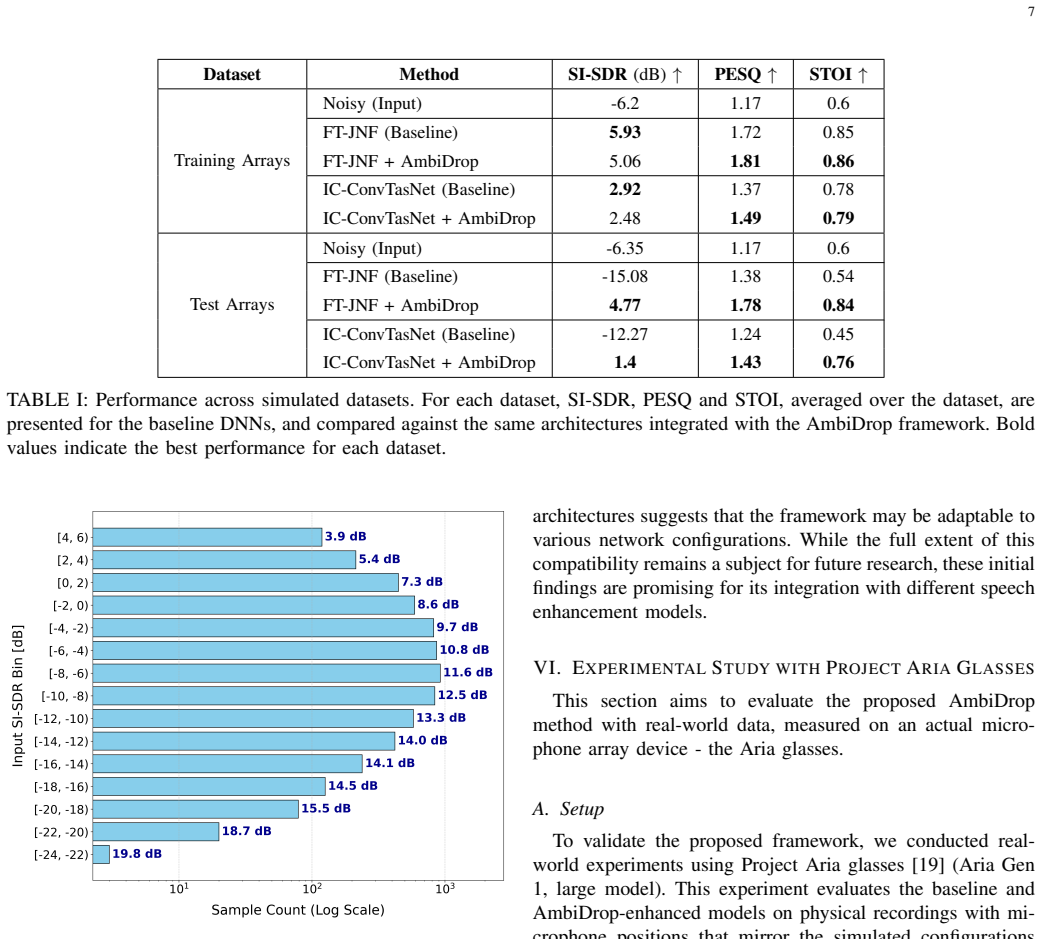
Multichannel Deep Neural Networks (DNNs) have significantly improved speech enhancement performance; however, they typically remain constrained by reliance on fixed microphone array geometries, leading to poor generalization on unseen or irregular configurations. Current array-agnostic approaches often rely on high-complexity architectures or massive, diverse datasets, yet they still struggle to generalize to out-of-distribution layouts. In this paper, we present an in-depth analysis of AmbiDrop, a recently proposed framework that achieves geometry independence by leveraging ideal Ambisonics as the DNN input. By employing a channel-wise dropout layer during training to simulate Ambisonics encoding errors, AmbiDrop decouples the learning process from the physical sensor arrangement. During inference, microphone signals from arbitrary array configurations are transformed into the Ambisonics domain via Ambisonics Signal Matching (ASM) before processing. Extensive experiments demonstrate that AmbiDrop maintains high robustness across a diverse suite of unseen simulated arrays and real-world recordings. Furthermore, our results show that the framework is resilient to sensor failures and remains effective even with reduced network scales, making it highly suitable for deployment on resource-constrained edge devices and versatile wearable hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AmbiDrop, a DNN-based speech enhancement framework that achieves array-agnostic operation by taking ideal Ambisonics signals as input. Channel-wise dropout is applied during training to simulate Ambisonics encoding errors, while Ambisonics Signal Matching (ASM) converts signals from arbitrary microphone arrays into the Ambisonics domain at inference time. The central claim is that this yields high robustness on unseen simulated arrays, real-world recordings, sensor failures, and reduced network scales.
Significance. If the robustness claims hold after verification of the error modeling assumption, the work would provide a practical route to geometry-independent multichannel enhancement without requiring massive datasets or high-complexity architectures, with direct applicability to wearable and edge devices.
major comments (2)
- [Abstract] Abstract: the claim that channel-wise dropout during training adequately simulates Ambisonics encoding errors for generalization is load-bearing for the robustness results on real recordings, yet the manuscript provides no analysis or evidence that the structured, geometry-dependent residuals produced by ASM (least-squares mapping) lie within the distribution of independent per-channel dropout.
- [Abstract] Abstract: the statement that 'extensive experiments demonstrate' robustness across unseen arrays and real recordings is unsupported by any reported datasets, baselines, metrics, or statistical tests, preventing evaluation of whether the central array-agnostic claim is substantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our claims regarding error modeling and experimental substantiation. We address each point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that channel-wise dropout during training adequately simulates Ambisonics encoding errors for generalization is load-bearing for the robustness results on real recordings, yet the manuscript provides no analysis or evidence that the structured, geometry-dependent residuals produced by ASM (least-squares mapping) lie within the distribution of independent per-channel dropout.
Authors: We acknowledge this is a valid observation: the manuscript does not provide an explicit distributional comparison between ASM residuals and the independent per-channel dropout. While the dropout was motivated by the goal of simulating encoding mismatches, a direct analysis (e.g., via residual statistics or divergence measures) is absent. In the revision we will add a dedicated analysis subsection with quantitative comparison of error distributions to support the modeling assumption. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments demonstrate' robustness across unseen arrays and real recordings is unsupported by any reported datasets, baselines, metrics, or statistical tests, preventing evaluation of whether the central array-agnostic claim is substantiated.
Authors: The body of the manuscript details the experimental protocol, including specific simulated array geometries, real-world recording conditions, comparison baselines, objective metrics, and significance testing. The abstract condenses these results. To address the concern directly, we will revise the abstract to include concise references to the number of array configurations, real datasets, and primary metrics used. revision: partial
Circularity Check
No significant circularity; relies on external Ambisonics encoding
full rationale
The paper presents AmbiDrop as using ideal Ambisonics input with channel-wise dropout during training to simulate encoding errors, followed by ASM transformation at inference. No equations, derivations, or fitted parameters are shown that reduce claimed robustness to a quantity defined by the method itself. Robustness is asserted via experiments on unseen arrays and real recordings. The phrase 'a recently proposed framework' indicates possible self-citation to prior work, but this is not load-bearing for the central empirical claims, which rest on external Ambisonics concepts rather than self-referential definitions or predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. L. Van Trees,Optimum array processing: Part IV of detection, estimation, and modulation theory. New York, NY , USA: Wiley- Interscience, 2002
2002
-
[2]
Design of multichannel wiener filter for speech enhancement in hearing aids and noise reduction tech- nique,
N. Modhave, Y . Karuna, and S. Tonde, “Design of multichannel wiener filter for speech enhancement in hearing aids and noise reduction tech- nique,” in2016 Online International Conference on Green Engineering and Technologies (IC-GET). IEEE, 2016, pp. 1–4
2016
-
[3]
Review of ideal binary and ratio mask estimation techniques for monaural speech separation,
T. Minipriya and R. Rajavel, “Review of ideal binary and ratio mask estimation techniques for monaural speech separation,” in2018 F ourth International Conference on Advances in Electrical, Electronics, Infor- mation, Communication and Bio-Informatics (AEEICB). IEEE, 2018, pp. 1–5
2018
-
[4]
Microphone array signal processing and deep learning for speech enhancement: Combining model-based and data-driven ap- proaches to parameter estimation and filtering,
R. Haeb-Umbach, T. Nakatani, M. Delcroix, C. Boeddeker, and T. Ochiai, “Microphone array signal processing and deep learning for speech enhancement: Combining model-based and data-driven ap- proaches to parameter estimation and filtering,”IEEE Signal Process. Mag., vol. 41, no. 6, pp. 12–23, 2024
2024
-
[5]
Advances in microphone array processing and multichannel speech enhancement,
G. Huang, J. R. Jensen, J. Chen, J. Benesty, M. G. Christensen, A. Sugiyama, G. Elko, and T. Gaensler, “Advances in microphone array processing and multichannel speech enhancement,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2025, pp. 1–5
2025
-
[6]
End-to-end mi- crophone permutation and number invariant multi-channel speech sep- aration,
Y . Luo, Z. Chen, N. Mesgarani, and T. Yoshioka, “End-to-end mi- crophone permutation and number invariant multi-channel speech sep- aration,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2020, pp. 6394–6398
2020
-
[7]
VarArray: Array-geometry-agnostic continuous speech sep- aration,
T. Yoshioka, X. Wang, D. Wang, M. Tang, Z. Zhu, Z. Chen, and N. Kanda, “VarArray: Array-geometry-agnostic continuous speech sep- aration,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2022, pp. 6027–6031
2022
-
[8]
Flexible multichannel speech enhancement for noise-robust frontend,
A. Juki ´c, J. Balam, and B. Ginsburg, “Flexible multichannel speech enhancement for noise-robust frontend,” inProc. IEEE Workshop Appl. Signal Process. Audio Acoust. (WASPAA), 2023, pp. 1–5
2023
-
[9]
One model to enhance them all: Array geometry agnostic multi-channel personalized speech enhancement,
H. Taherian, S. E. Eskimez, T. Yoshioka, H. Wang, Z. Chen, and X. Huang, “One model to enhance them all: Array geometry agnostic multi-channel personalized speech enhancement,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2022, pp. 271–275
2022
-
[10]
Microphone Array Generalization for Multichannel Narrowband Deep Speech Enhancement,
S. Zhang and X. Li, “Microphone Array Generalization for Multichannel Narrowband Deep Speech Enhancement,” inProc. Interspeech 2021, 2021, pp. 666–670
2021
-
[11]
DeFTAN-AA: Array Geometry Agnostic Multichannel Speech Enhancement,
D. Lee and J.-W. Choi, “DeFTAN-AA: Array Geometry Agnostic Multichannel Speech Enhancement,” inInterspeech 2024, 2024, pp. 3360–3364
2024
-
[12]
Neural Speech Separation Using Spatially Distributed Microphones,
D. Wang, Z. Chen, and T. Yoshioka, “Neural Speech Separation Using Spatially Distributed Microphones,” inInterspeech 2020, 2020, pp. 339– 343
2020
-
[13]
Meta- learning for variable array configurations in end-to-end few-shot multi- channel speech enhancement,
A. Mannanova, K. Tesch, J.-M. Lemercier, and T. Gerkmann, “Meta- learning for variable array configurations in end-to-end few-shot multi- channel speech enhancement,” inProc. Int. Workshop Acoustic Signal Enhancement (IWAENC), 2024, pp. 200–204
2024
-
[14]
Eigenbeam-feature-based multi-order encoder for geometry-agnostic speech enhancement,
D. Zhang, A. I. Mezza, F. Miotello, J. Chen, M. Wang, F. Antonacci, and A. Bernardini, “Eigenbeam-feature-based multi-order encoder for geometry-agnostic speech enhancement,” in2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 22192–22196
2026
-
[15]
AmbiDrop: Array-Agnostic Speech En- hancement Using Ambisonics Encoding and Dropout-Based Learning,
M. Tatarjitzky and B. Rafaely, “AmbiDrop: Array-Agnostic Speech En- hancement Using Ambisonics Encoding and Dropout-Based Learning,” in2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 14732–14736
2026
-
[16]
Zotter and M
F. Zotter and M. Frank,Ambisonics: A practical 3D audio theory for recording, studio production, sound reinforcement, and virtual reality. Cham, Switzerland: Springer Nature, 2019
2019
-
[17]
Rafaely,Fundamentals of Spherical Array Processing
B. Rafaely,Fundamentals of Spherical Array Processing. Springer, 2015, vol. 8
2015
-
[18]
Am- bisonics encoding for arbitrary microphone arrays incorporating residual channels for binaural reproduction,
Y . Gayer, V . Tourbabin, Z. Ben-Hur, J. Donley, and B. Rafaely, “Am- bisonics encoding for arbitrary microphone arrays incorporating residual channels for binaural reproduction,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. Workshops (ICASSP), 2024, pp. 244–248
2024
-
[19]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredithet al., “Project aria: A new tool for egocentric multi-modal ai research,”arXiv preprint arXiv:2308.13561, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Unified description of ambisonics using real and complex spherical harmonics,
M. Poletti, “Unified description of ambisonics using real and complex spherical harmonics,” inAmbisonics Symp, 2009
2009
-
[21]
Insights into deep nonlinear filters for improved multi-channel speech enhancement,
K. Tesch and T. Gerkmann, “Insights into deep nonlinear filters for improved multi-channel speech enhancement,”IEEE/ACM Trans. Audio, Speech, and Language Process., vol. 31, pp. 563–575, 2023
2023
-
[22]
Inter-channel Conv-TasNet for multi- channel speech enhancement (2021),
D. Lee, S. Kim, and J. Choi, “Inter-channel Conv-TasNet for multi- channel speech enhancement (2021),”arXiv preprint ArXiv:2111.04312, 2021
-
[23]
Image method for efficiently simulating small-room acoustics,
J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,”J. Acoust. Soc. Am., vol. 65, no. 4, pp. 943–950, 1979
1979
-
[24]
CSR-I (WSJ0) complete LDC93S6A,
J. S. Garofolo, D. Graff, D. Paul, and D. Pallett, “CSR-I (WSJ0) complete LDC93S6A,” Linguistic Data Consortium, Philadelphia, May 2007
2007
-
[25]
SDR—half- baked or well done?
J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR—half- baked or well done?” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Brighton, UK, 2019, pp. 626–630
2019
-
[26]
Anthropometric manikin for acoustic research,
M. Burkhard and R. Sachs, “Anthropometric manikin for acoustic research,”The Journal of the Acoustical Society of America, vol. 58, no. 1, pp. 214–222, 1975
1975
-
[27]
The CHiME-8 MMCSG Challenge: Multi-modal conversations in smart glasses,
K. ˇZmol´ıkov´a, S. Merello, K. Kalgaonkar, J. Lin, N. Moritz, P. Ma, M. Sun, H. Chen, A. Saliou, S. Petridiset al., “The CHiME-8 MMCSG Challenge: Multi-modal conversations in smart glasses,” inProc. CHiME 2024, 2024, pp. 7–12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.