Retrieved Images as Visual Thought: Training-Free Multimodal In-Context Learning for the Open-vs-Closed Gap
Pith reviewed 2026-07-02 14:42 UTC · model grok-4.3
The pith
Retrieving labeled images as visual thought lets smaller models match larger ones on in-context tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
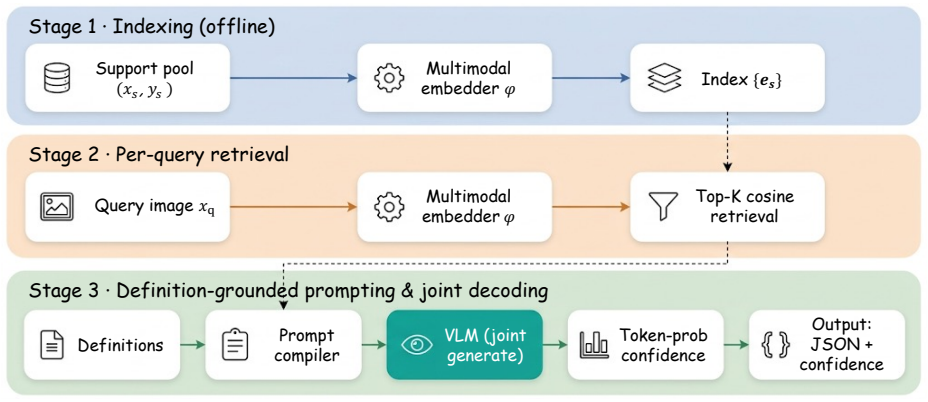
ReVisIT shows that per-query multimodal retrieval of labeled images, combined with structured definitions and alternating turns before joint multi-attribute decoding, allows vision-language models to use retrieved images as visual thought units for effective in-context learning without any training or generation.
What carries the argument
ReVisIT framework using retrieved image-label pairs as visual thought units via alternating injection and joint decoding.
If this is right
- Retrieval quality drives 83% of the performance improvement.
- Alternating turns add substantial gains on free-form tasks like Bongard-OpenWorld.
- The full method yields 4-6 point gains across multiple backbones on MAAC-Bench.
- Structured class definitions provide adaptive benefits depending on the task.
- The approach degrades gracefully when only some components are applicable.
Where Pith is reading between the lines
- This retrieval route could serve as a simpler alternative to generation-based visual reasoning methods.
- Future work might explore integrating this with better retrieval systems for broader tasks.
- The release of MAAC-Bench with verification protocol could standardize evaluation of attribute-based reasoning.
Load-bearing premise
That the retrieved labeled exemplars provide useful visual information that the model can meaningfully integrate, rather than benefits arising mainly from changes in prompt formatting.
What would settle it
Testing whether performance drops to chance levels when retrieved images are replaced with unrelated or randomly selected ones on the same benchmarks.
Figures



read the original abstract
Recent work on Thinking with Images makes vision a dynamic part of reasoning, but does so through generation: the model invokes external tools, synthesizes code, or imagines new imagery, each at the cost of a tool protocol, brittle code, or an expensive training pipeline. A fourth route makes vision dynamic without generating anything, by retrieving labeled exemplar images and reasoning over them, yet it remains underexplored despite being train-free. We present ReVisIT, a train-free framework that realizes this retrieval-based route by treating each retrieved image-label pair as a unit of visual thought. ReVisIT combines structured class definitions, per-query multimodal retrieval of exemplars, and alternating user/assistant injection of those exemplars before joint multi-attribute decoding, and degrades gracefully to whichever components a task admits. On VL-ICL Bench Fast Open MiniImageNet, Qwen3-VL-30B-A3B with ReVisIT reaches 98.5% at 4-shot, statistically indistinguishable from the 72B LLaVA-OneVision SOTA (98.7%) on this near-saturated task at about 1/2.4 the parameters, while the same backbone without the scaffold sits at chance. The turns layer alone adds 26.1 points to GPT-4.1 on free-form concept induction (Bongard-OpenWorld), and the full stack yields a 4-6 point macro gain across three backbones on MAAC-Bench, a new license-clean 27-class, 5-attribute benchmark, significant by paired bootstrap on the curator-derived attributes. Component analysis shows that retrieval-plus-turns is the universal lever while structured definitions are need-adaptive, and that 83% of the retrieval gain comes from retrieval quality rather than from the presence of exemplars. MAAC-Bench is released with a rubric-grounded LLM verification protocol that replaces author spot-check on subjective attributes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReVisIT, a training-free multimodal in-context learning framework that treats per-query retrieved labeled exemplar images as units of 'visual thought.' It combines structured class definitions, multimodal retrieval, alternating user/assistant injection of exemplars, and joint multi-attribute decoding. Empirical claims include reaching 98.5% on VL-ICL Bench Fast Open MiniImageNet (4-shot) with Qwen3-VL-30B-A3B (statistically indistinguishable from a 72B SOTA), 26.1-point gain from the turns layer on Bongard-OpenWorld, 4-6 point macro gains on the new MAAC-Bench across backbones, and component analysis attributing 83% of retrieval gains to retrieval quality (with retrieval-plus-turns as the universal lever).
Significance. If the results and attributions hold after controls, the work demonstrates a simple, training-free route to close performance gaps between smaller and larger VLMs on visual reasoning tasks by leveraging retrieval rather than generation. The release of MAAC-Bench with a rubric-grounded LLM verification protocol is a concrete positive contribution to the field.
major comments (2)
- [Abstract / Component Analysis] The central attribution that 'retrieval-plus-turns is the universal lever' and that alternating injection plus joint decoding integrates visual thought units (rather than gains arising from prompt formatting) requires a matched-format control experiment. The component analysis (83% from retrieval quality) does not appear to compare the alternating user/assistant turns structure against a standard concatenated few-shot prompt using identical retrieved image-label pairs; without this, the specific contribution of the injection/decoding mechanism to the near-SOTA MiniImageNet result remains unsecured.
- [Abstract / Experimental Results] The abstract reports precise accuracy figures, paired bootstrap significance, statistical indistinguishability, and component contributions, yet supplies no experimental details on dataset splits, full controls, error bars, or verification that the same retrieved exemplars were used across injection styles. This information is load-bearing for evaluating whether the reported gains on the near-saturated MiniImageNet task are robust or benchmark-specific.
minor comments (2)
- [Abstract] Clarify the precise definition of 'joint multi-attribute decoding' and how it differs from standard next-token prediction over the full prompt; the current description leaves the decoding procedure underspecified.
- [Abstract] The claim of 'graceful degradation to whichever components a task admits' would benefit from an explicit table or section enumerating which components are ablated per benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger controls and fuller experimental transparency. We address each major comment below and will revise the manuscript to incorporate the requested elements.
read point-by-point responses
-
Referee: [Abstract / Component Analysis] The central attribution that 'retrieval-plus-turns is the universal lever' and that alternating injection plus joint decoding integrates visual thought units (rather than gains arising from prompt formatting) requires a matched-format control experiment. The component analysis (83% from retrieval quality) does not appear to compare the alternating user/assistant turns structure against a standard concatenated few-shot prompt using identical retrieved image-label pairs; without this, the specific contribution of the injection/decoding mechanism to the near-SOTA MiniImageNet result remains unsecured.
Authors: We agree that a matched-format control is required to isolate the alternating injection and joint multi-attribute decoding from simple concatenation of the same image-label pairs. The current component analysis attributes 83% of retrieval gains to quality and identifies retrieval-plus-turns as the universal lever, but does not include the direct concatenated baseline requested. We will add this control experiment (identical exemplars, standard few-shot concatenation vs. ReVisIT turns structure) and report its results to secure the attribution for the MiniImageNet performance. revision: yes
-
Referee: [Abstract / Experimental Results] The abstract reports precise accuracy figures, paired bootstrap significance, statistical indistinguishability, and component contributions, yet supplies no experimental details on dataset splits, full controls, error bars, or verification that the same retrieved exemplars were used across injection styles. This information is load-bearing for evaluating whether the reported gains on the near-saturated MiniImageNet task are robust or benchmark-specific.
Authors: We will add the requested experimental details to the revised manuscript, including dataset splits, full list of controls, error bars from the paired bootstrap, and explicit confirmation that identical retrieved exemplars were held fixed across injection styles. While abstracts are space-constrained, the main text and appendix will contain all load-bearing information so that the near-SOTA claim on MiniImageNet can be fully evaluated for robustness. revision: yes
Circularity Check
No significant circularity; empirical claims on external benchmarks with no derivations or self-referential reductions
full rationale
The paper introduces the ReVisIT framework as a train-free method using retrieved image-label pairs for multimodal in-context learning, with all central claims consisting of empirical accuracy numbers (e.g., 98.5% on VL-ICL Bench Fast Open MiniImageNet) and component ablations on external benchmarks. No equations, mathematical derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. Self-citations, if any, are not load-bearing for any derivation chain, and the work is self-contained against independent benchmarks without reducing results to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark accuracy on VL-ICL Bench, Bongard-OpenWorld, and MAAC-Bench measures the intended open-vs-closed visual reasoning capability.
Reference graph
Works this paper leans on
-
[1]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Flamingo: a visual language model for few- shot learning. InNeurIPS. Awadalla,A.;Gao,I.;Gardner,J.;Hessel,J.;Hanafy,Y.;Zhu, W.;Marathe,K.;Bitton,Y.;Gadre,S.;Sagawa,S.;etal.2023. OpenFlamingo:Anopen-sourceframeworkfortraininglarge autoregressive vision-language models.arXiv:2308.01390. Hu,W.;Gu,J.-C.;Dou,Z.-Y.;Fayyaz,M.;Lu,P.;Chang,K.- W.;andPeng,N.2024a.M...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Scaling up visual and vision-language representation learning with noisy text supervision. InICML. Khattak, M. U.; Wasim, S. T.; Naseer, M.; Khan, S.; Yang, M.-H.;andKhan,F.S.2023. Self-regulatingprompts:Foun- dational model adaptation without forgetting. InICCV. Kong,S.;Shen,X.;Lin,Z.;Mech,R.;andFowlkes,C.2016. Photoaestheticsrankingnetworkwithattributes...
2023
-
[3]
Introducing IDEFICS-2. arXiv:2405.02246. Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal,N.;Küttler,H.;Lewis,M.;Yih,W.-t.;Rocktäschel,T.; et al
-
[4]
LLaVA-OneVision: Easy Visual Task Transfer
LLaVA- OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326. Li, C.; Liu, H.; Li, L. H.; Zhang, P.; Aneja, J.; Yang, J.; Jin, P.;Hu,H.;Liu,Z.;Lee,Y.J.;andGao,J.2022. ELEVATER: Abenchmarkandtoolkitforevaluatinglanguage-augmented visual models. InNeurIPS Datasets and Benchmarks. Liu,J.;Shen,D.; Zhang,Y.;Dolan,B.;Carin,L.;andChen, W
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Murray,N.;Marchesotti,L.;andPerronnin,F.2012
What Makes Good In-Context Examples for GPT- 3? InProceedings of Deep Learning Inside Out (DeeLIO): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. Murray,N.;Marchesotti,L.;andPerronnin,F.2012. AVA:a large-scale database for aesthetic visual analysis. InCVPR. Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, ...
2012
-
[6]
Large Language Models: A Survey
A survey on retrieval-augmented generation in healthcare.arXiv:2402.06196. Saleh,B.;andElgammal,A.2016. Large-scaleclassification of fine-art paintings: Learning the right metric on the right feature. InInternational Journal for Digital Art History. Strezoski,G.;andWorring,M.2018.OmniArt:Alarge-scale artistic benchmark. InACM TOMM. Surís,D.;Menon,S.;andVo...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv:2409.12191. Wu, R.; Ma, X.; Ci, Z.; Fan, Q.; Wu, Y. N.; and Zhu, Y
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Bongard-OpenWorld: Few-shot reasoning for free- form visual concepts in the real world. InICLR. Yang, J.; Zhang, H.; Li, F.; Zou, X.; Li, C.; and Gao, J. 2023a. Set-of-Mark prompting unleashes extraordinary vi- sual grounding in GPT-4V. InarXiv:2310.11441. Yang,Z.;Ping,W.;Liu,Z.;Korthikanti,V.;Nie,W.;Huang, D.-A.; Fan, L.; Yu, Z.; Lan, S.; Li, B.; et al. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Tip-Adapter: Training-free adaption of CLIP for few-shot classification. InECCV. Zhang, X.; Gao, Z.; Zhang, B.; Li, P.; Zhang, X.; Liu, Y.; Yuan,T.;Wu,Y.;Jia,Y.;Zhu,S.-C.;andLi,Q.2025. Chain- of-Focus: Adaptive visual search and zooming for multi- modal reasoning via RL. arXiv:2505.15436. Zhao, C.; et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Thinking with Images for Multi- modal Reasoning: Foundations, Methods, and Future Fron- tiers. arXiv:2506.23918. Zheng, Z.; Yang, M.; Hong, J.; Zhao, C.; Xu, G.; Yang, L.; Shen, C.; and Yu, X
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
DeepEyes: Incentiviz- ing “Thinking with Images” via reinforcement learning. arXiv:2505.14362. Zhou,K.;Yang,J.;Loy,C.C.;andLiu,Z.2022a.Conditional prompt learning for vision-language models. InCVPR. Zhou, K.; Yang, J.; Loy, C. C.; and Liu, Z. 2022b. Learning topromptforvision-languagemodels.International Journal of Computer Vision (IJCV), 130(9): 2337–234...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
H Inference pipeline pseudocode Algorithm 1The ReVisIT inference pipeline (§3) Require:Queryx q;taxonomyT;supportpoolS;embedder ϕ; VLMπ; shot countK 1:[Offline]∀(x s, ys)∈ S:e s ←ϕ(x s, ys) 2:E K ←topK s∈S cos(ϕ(xq), e s){retrieval} 3:M←[Compile(T)]{three-block sys prompt} 4:for(x e, ye)∈ E K: append⟨user:xe⟩,⟨asst:y e⟩toM 5:Append⟨user:x q⟩toM 6:J←greedy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.