Learning to Watch: Active Video Anomaly Understanding via Interleaved Policy Optimization
Pith reviewed 2026-07-02 14:36 UTC · model grok-4.3
The pith
Anom-π turns video anomaly understanding into active sequential decisions so a 2B-parameter model can outperform larger passive systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
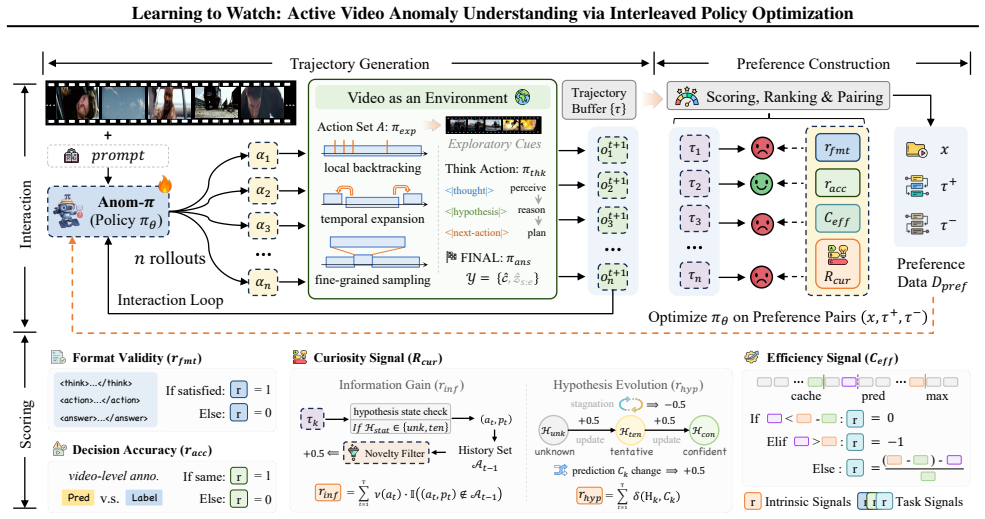
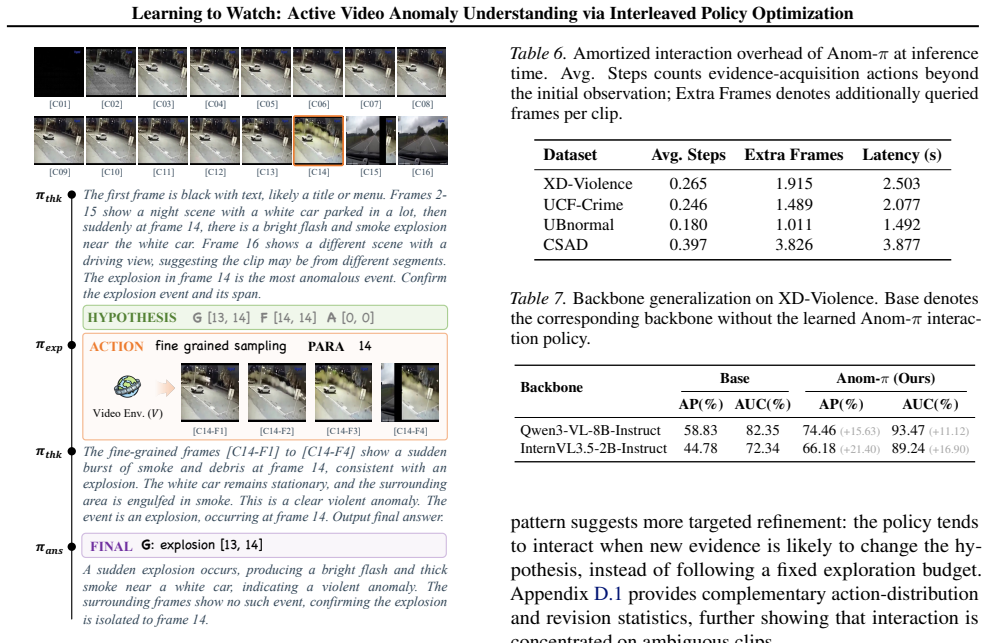
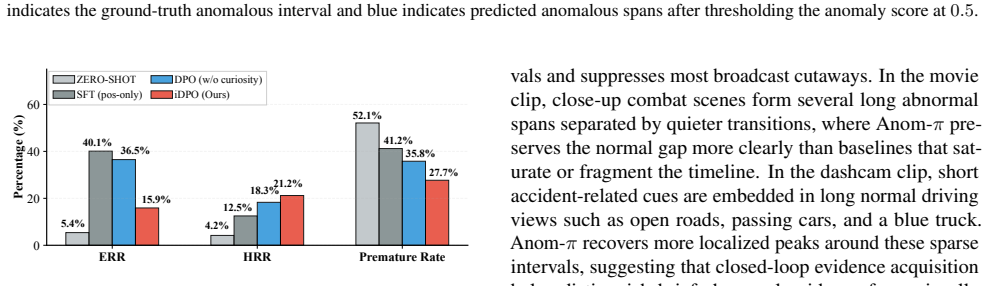
Anom-π unifies internal cognitive reasoning and strategic evidence acquisition into an interleaved policy that employs temporal atomic operators such as local backtracking, temporal expansion, and fine-grained sampling. These interaction strategies are learned under video-level weak supervision by Interactive Direct Preference Optimization (iDPO) guided by an Active Evidence Inquiry (AEI) utility that balances task success, informative evidence acquisition, and interaction cost, enabling the agent to actively disambiguate hypotheses while suppressing redundant exploration.
What carries the argument
The interleaved policy whose actions are temporal atomic operators and whose learning signal is iDPO alignment under the AEI utility.
If this is right
- The agent acquires evidence selectively rather than exhaustively, reducing interaction cost while raising task success.
- Trajectory-level preference optimization succeeds even when only video-level labels are available.
- Smaller models become competitive in complex VAU scenarios once perceptual proactivity is enabled.
- Redundant exploration is suppressed because the AEI utility penalizes uninformative actions.
Where Pith is reading between the lines
- The same active-policy structure could be applied to other sparse-cue video tasks such as action anticipation or long-form summarization.
- Distilling the learned operators into a passive model might improve conventional VAU baselines without runtime interaction.
- If interaction cost is further weighted, the framework could support real-time deployment on edge devices where full video review is expensive.
Load-bearing premise
Video-level weak supervision plus the AEI utility is sufficient to produce non-trivial, non-collapsing interaction policies.
What would settle it
A controlled test in which the iDPO-trained policy produces the same accuracy as a fixed passive sampler on a set of deliberately ambiguous anomaly videos would show the active strategy adds no value.
Figures





read the original abstract
Video anomaly understanding (VAU) relies on sparse, context-dependent cues. However, existing passive paradigms suffer from observational aliasing, where static sampling fails to disambiguate semantically distinct events. To overcome this, we propose $Anom\text{-}\pi$, a closed-loop framework that reconceptualizes video understanding as an active sequential decision-making process within a dynamic environment. Inspired by human video-reviewing behavior, this framework unifies internal cognitive reasoning and strategic evidence acquisition into an interleaved policy, utilizing temporal atomic operators such as local backtracking, temporal expansion, and fine-grained sampling to endow the model with perceptual proactivity. To learn such complex interaction strategies under video-level weak supervision, we design Interactive Direct Preference Optimization (iDPO) to achieve trajectory-level policy alignment, guided by an Active Evidence Inquiry (AEI) utility that balances task success, informative evidence acquisition, and interaction cost. This approach enables the agent to learn to actively disambiguate hypotheses while suppressing redundant exploration. Extensive experiments demonstrate that our framework, with only 2B parameters, achieves highly competitive performance, significantly outperforming state-of-the-art large-scale VAU models in complex scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Anom-π, a closed-loop active framework for video anomaly understanding that models the task as sequential decision-making. It introduces temporal atomic operators (local backtracking, temporal expansion, fine-grained sampling) within an interleaved policy, trained via Interactive Direct Preference Optimization (iDPO) under an Active Evidence Inquiry (AEI) utility that balances task success, evidence informativeness, and interaction cost, all using only video-level weak supervision. The central claim is that this 2B-parameter model achieves highly competitive performance and significantly outperforms state-of-the-art large-scale passive VAU models in complex scenarios.
Significance. If the empirical claims hold and the active policy demonstrably avoids collapse, the work would be significant for shifting VAU from passive sampling to human-inspired active evidence acquisition, potentially enabling smaller models to resolve observational aliasing in context-dependent anomalies. The trajectory-level alignment via iDPO and the multi-objective AEI utility represent a substantive technical contribution over standard supervised or reinforcement baselines.
major comments (1)
- [iDPO and AEI utility description (abstract and method)] The headline performance claim (2B-param model significantly outperforming large VAU models via active strategies) is load-bearing on the assumption that iDPO under AEI produces non-redundant use of the temporal atomic operators. With only video-level weak supervision and no mention of an explicit diversity term, entropy bonus, or trajectory-level contrastive loss, it is unclear what mechanism prevents policy collapse to a single operator or constant querying behavior; this must be addressed with either a formal argument or ablation evidence showing distinct operator usage distributions.
minor comments (1)
- [Abstract] The abstract asserts 'extensive experiments' and 'superior performance' without naming baselines, metrics, datasets, or result tables; while the full manuscript presumably supplies these, the abstract should at minimum indicate the evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concern regarding mechanisms preventing policy collapse in iDPO under AEI below and will revise the manuscript to strengthen this section.
read point-by-point responses
-
Referee: [iDPO and AEI utility description (abstract and method)] The headline performance claim (2B-param model significantly outperforming large VAU models via active strategies) is load-bearing on the assumption that iDPO under AEI produces non-redundant use of the temporal atomic operators. With only video-level weak supervision and no mention of an explicit diversity term, entropy bonus, or trajectory-level contrastive loss, it is unclear what mechanism prevents policy collapse to a single operator or constant querying behavior; this must be addressed with either a formal argument or ablation evidence showing distinct operator usage distributions.
Authors: The AEI utility is explicitly formulated as a multi-objective function balancing task success, evidence informativeness, and interaction cost. The interaction-cost term directly penalizes redundant or constant querying, while the informativeness objective requires context-dependent selection among the temporal atomic operators (local backtracking, temporal expansion, fine-grained sampling) to resolve aliasing. iDPO performs trajectory-level preference alignment on trajectories that achieve high AEI utility, thereby favoring policies that employ varied operators over collapsed ones. Although an explicit entropy bonus or diversity regularizer is not present, the composite AEI objective supplies the necessary regularization. In the revised manuscript we will add a formal derivation of how AEI discourages collapse together with ablation results on operator-usage distributions across scenarios. revision: yes
Circularity Check
No circularity: framework claims rest on empirical performance, not self-referential definitions or fitted predictions.
full rationale
The provided abstract and description contain no equations, derivations, or parameter-fitting steps that reduce claimed outputs (e.g., performance gains from iDPO under AEI) to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core components. The method is presented as a novel combination of policy optimization and utility design whose validity is asserted via experiments rather than algebraic identity. This matches the default expectation of non-circularity for papers without explicit mathematical reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing passive paradigms suffer from observational aliasing where static sampling fails to disambiguate events
- ad hoc to paper Video-level weak supervision suffices to learn complex interaction strategies via iDPO
invented entities (4)
-
Anom-π framework
no independent evidence
-
iDPO
no independent evidence
-
AEI utility
no independent evidence
-
temporal atomic operators
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the computer vision and pattern recognition conference , pages=
Holmes-vau: Towards long-term video anomaly understanding at any granularity , author=. Proceedings of the computer vision and pattern recognition conference , pages=
-
[2]
arXiv preprint arXiv:2505.23504 , year=
Vau-r1: Advancing video anomaly understanding via reinforcement fine-tuning , author=. arXiv preprint arXiv:2505.23504 , year=
-
[3]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in neural information processing systems , volume=
Vad-r1: Towards video anomaly reasoning via perception-to-cognition chain-of-thought , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
A2seek: Towards reasoning-centric benchmark for aerial anomaly understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Cuebench: Advancing unified understanding of context-aware video anomalies in real-world , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Proceedings of the Fourteenth International Conference on Learning Representations , year =
JUDO: A Juxtaposed Domain-Oriented Multimodal Reasoner for Industrial Anomaly QA , author =. Proceedings of the Fourteenth International Conference on Learning Representations , year =
-
[9]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Hiprobe-vad: Video anomaly detection via hidden states probing in tuning-free multimodal llms , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Panda: Towards generalist video anomaly detection via agentic ai engineer , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Harnessing large language models for training-free video anomaly detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
VADTree: Explainable training-free video anomaly detection via hierarchical granularity-aware tree , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
A unified reasoning framework for holistic zero-shot video anomaly analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Eventvad: Training-free event-aware video anomaly detection , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[16]
Follow the rules: Reasoning for video anomaly detection with large language models , author=. Proc. Eur. Conf. Comput. Vis. (ECCV) , pages=
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[19]
Huang, Chao and Shi, Yushu and Wen, Jie and Wang, Wei and Xu, Yong and Cao, Xiaochun , booktitle=. Ex-. 2025 , volume=
2025
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dual memory units with uncertainty regulation for weakly supervised video anomaly detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Weakly-supervised video anomaly detection with robust temporal feature magnitude learning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation: A Unified Approach , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Self-distilled masked auto-encoders are efficient video anomaly detectors , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
European conference on computer vision , pages=
Not only look, but also listen: Learning multimodal violence detection under weak supervision , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Real-world anomaly detection in surveillance videos , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ubnormal: New benchmark for supervised open-set video anomaly detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[29]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
HeadHunt-VAD: Hunting Robust Anomaly-Sensitive Heads in MLLM for Tuning-Free Video Anomaly Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[31]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Learning Event Completeness for Weakly Supervised Video Anomaly Detection , author=. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , volume=
2025
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Just Dance with pi! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Prompt-enhanced multiple instance learning for weakly supervised video anomaly detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Hawk: Learning to understand open-world video anomalies , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aligning Effective Tokens with Video Anomaly in Large Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Qwen2.5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Uncovering what why and how: A comprehensive benchmark for causation understanding of video anomaly , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[41]
IEEE Transactions on Information Forensics and Security , year=
Video-Level Language-Driven Video-Based Visible-Infrared Person Re-Identification , author=. IEEE Transactions on Information Forensics and Security , year=
-
[42]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Logical relation inference and multiview information interaction for domain adaptation person re-identification , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , publisher=
2023
-
[43]
Pattern Recognition , pages=
Shape-centered representation learning for visible-infrared person re-identification , author=. Pattern Recognition , pages=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.