Loss Smoothing for Stable Adaptation Under Distribution Shift
Pith reviewed 2026-07-02 15:50 UTC · model grok-4.3
The pith
Loss smoothing by interpolating source and target objectives improves adaptation under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
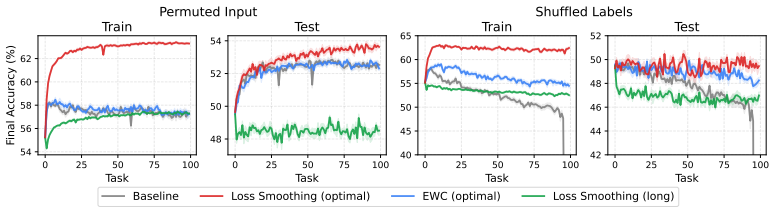
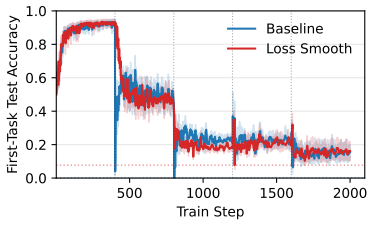
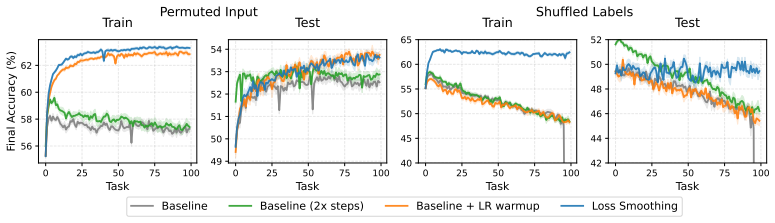
Loss smoothing interpolates between the source and target training objectives at the start of adaptation, preserving useful source features that would otherwise be distorted by an abrupt objective switch and thereby improving final performance on the target task.
What carries the argument
Loss smoothing, a schedule that applies a time-varying linear combination of source loss and target loss for an initial number of adaptation steps before switching fully to the target loss.
If this is right
- Higher target accuracy in supervised classification under controlled covariate and label shifts.
- Improved transfer metrics when adapting pretrained vision models to new domains.
- More stable learning curves and higher returns when moving from offline to online reinforcement learning.
- Better downstream task performance after language-model fine-tuning without loss of pretraining utility.
Where Pith is reading between the lines
- The same interpolation idea could be applied to continual learning sequences with multiple successive shifts rather than a single source-target pair.
- Non-linear or learned interpolation schedules might outperform the fixed linear ramp used here.
- If the benefit stems from feature preservation, the approach might combine naturally with explicit feature-regularization terms already common in adaptation literature.
Load-bearing premise
An abrupt switch from source to target objective distorts useful source features and a linear interpolation between the two will preserve those features without introducing new optimization problems.
What would settle it
A replication experiment on one of the paper's controlled supervised shift benchmarks in which loss smoothing produces no accuracy gain or a clear accuracy drop relative to direct target-objective adaptation.
Figures





read the original abstract
In settings such as fine-tuning and reinforcement learning, neural networks are often adapted under distribution shift. Standard adaptation methods typically optimize the target objective directly, inducing an abrupt change from the source training objective. This abrupt transition can distort learned representations, including features that may still be useful for the new task. We investigate whether a more gradual transition can improve adaptation. We propose loss smoothing, a simple approach that interpolates between the source and target training objectives at the start of adaptation. This smooth transition helps to preserve useful features from the source distribution while still enabling the model to specialize to the target distribution. Across controlled supervised shifts, pretrained vision adaptation, offline-to-online and online reinforcement learning, and language model fine-tuning, we find that loss smoothing consistently improves performance, suggesting that smoother objective transitions are a broadly useful tool for model adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes loss smoothing, a method that linearly interpolates between source and target training objectives during the initial phase of adaptation under distribution shift. It claims this gradual transition preserves useful source features better than abrupt optimization of the target loss alone, and reports consistent performance gains across controlled supervised shifts, pretrained vision adaptation, offline-to-online and online RL, and language model fine-tuning.
Significance. If the empirical results hold under rigorous controls, the method is a low-overhead, broadly applicable heuristic for adaptation tasks that could improve stability in transfer and fine-tuning pipelines without requiring architectural changes or extra compute.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of 'consistent improvements' is stated without any reported quantitative results, effect sizes, baseline comparisons, statistical tests, or ablation details in the provided text, preventing assessment of whether gains are reliable or merely incidental.
- [§3 and §5] §3 (Method) and §5 (Discussion): no analysis (gradient alignment, Hessian trace, loss-surface visualization, or variance measurements) is supplied for the interpolated objective λ·L_source + (1-λ)·L_target, so the asserted mechanism of a 'smoother trajectory' that preserves features remains unverified and could be confounded by regularization or schedule effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of 'consistent improvements' is stated without any reported quantitative results, effect sizes, baseline comparisons, statistical tests, or ablation details in the provided text, preventing assessment of whether gains are reliable or merely incidental.
Authors: The abstract is intentionally concise, but we agree it should better convey the scale of results. Section 4 already contains the full quantitative details: tables report per-task accuracies or returns with standard deviations, direct comparisons against abrupt target optimization and other baselines, and ablations on the interpolation schedule. Statistical significance is assessed via paired t-tests or bootstrap intervals in the reported experiments. To address the concern, we will revise the abstract to include representative effect sizes (e.g., average relative improvement and key baseline names) while remaining within length limits. revision: yes
-
Referee: [§3 and §5] §3 (Method) and §5 (Discussion): no analysis (gradient alignment, Hessian trace, loss-surface visualization, or variance measurements) is supplied for the interpolated objective λ·L_source + (1-λ)·L_target, so the asserted mechanism of a 'smoother trajectory' that preserves features remains unverified and could be confounded by regularization or schedule effects.
Authors: We acknowledge that the current manuscript provides only empirical evidence rather than direct mechanistic verification. The consistent gains across controlled shifts, vision fine-tuning, RL, and LM tasks make confounding by generic regularization less likely, as the benefit appears specifically tied to the source-to-target interpolation phase. We will expand §5 to discuss alternative explanations (regularization vs. trajectory smoothing) and add a short gradient-norm analysis during early adaptation steps. Full Hessian traces or loss-surface visualizations would require new experiments and are left for future work. revision: partial
Circularity Check
No circularity: purely empirical proposal with no derivation chain
full rationale
The paper introduces loss smoothing as a simple linear interpolation between source and target objectives and evaluates it experimentally across supervised shifts, vision adaptation, RL, and LM fine-tuning. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the manuscript. All performance claims rest on direct experimental comparisons rather than any reduction to inputs by construction, so the work is self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/s41586-024-07711-7
ISSN 1476-4687. doi: 10.1038/s41586-024-07711-7. 12 C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax - a differentiable physics engine for large scale rigid body simulation,
-
[2]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data-driven reinforcement learning.CoRR, abs/2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.acl-long.841. Caglar Gulcehre, Marcin Moczulski, Francesco Visin, and Yoshua Bengio. Mollifying Networks. In International Conference on Learning Representations, February
-
[4]
doi: 10.1073/pnas.1611835114. Suhas Kotha and Percy Liang. Replaying pre-training data improves fine-tuning, March
-
[5]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Association for Computing Machinery. ISBN 979-8-4007-0229-7. doi: 10.1145/3600006.3613165. Matthias De Lange, Gido M van de Ven, and Tinne Tuytelaars. Continual evaluation for lifelong learning: Identifying the stability gap. InThe Eleventh International Conference on Learning Representations,
-
[6]
doi: 10.1109/ tpami.2017.2773081
ISSN 1939-3539. doi: 10.1109/ tpami.2017.2773081. Jarek Liesen, Chris Lu, and Robert Lange. Rejax,
-
[7]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
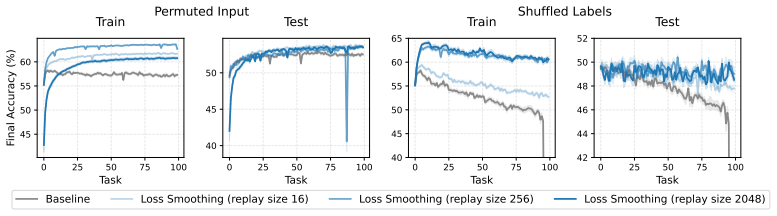
by overemphasizing older data
Figure 11: Ablation in supervised settings: effect of the amount of replay data on model performance. by overemphasizing older data. For the amount of replay data, a batch of 256 examples is generally sufficient. Using fewer examples can hurt performance, while using more does not provide additional benefits. B DomainNet Experimental Details We run the fu...
2021
-
[9]
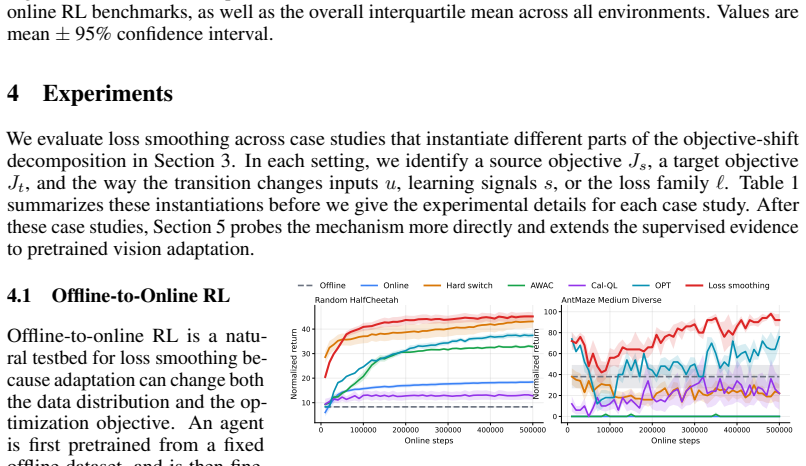
The hard-switch and online TD3 controls do not use the offline loss branch
For smoothed TD3+BC-to-TD3 runs, each update draws one batch from the online replay buffer and one independent batch from the fixed D4RL dataset; the offline actor/critic losses are computed on the offline batch, the online actor/critic losses are computed on the online batch, and the losses are interpolated after they are computed. The hard-switch and on...
2021
-
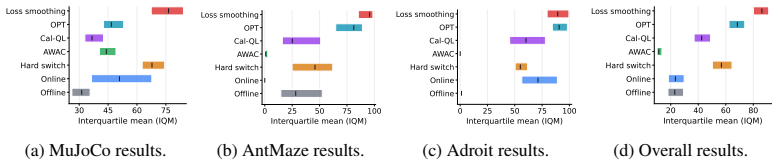
[10]
In dense MuJoCo tasks, loss smoothing typically retains the fast improvement of offline initialization while allowing the policy to move beyond the constraints of the offline objective. In the support-constrained AntMaze and Adroit tasks, the curves show the complementary role of the offline objective: early smoothing stabilizes fine-tuning in regimes whe...
2025
-
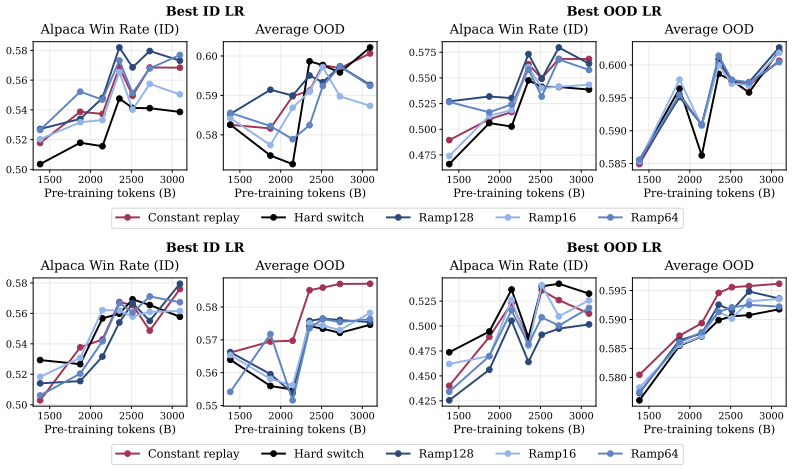
[11]
Instruction-tuning data.We use two target distributions
We use the token counts in the checkpoint names as the pretraining budget. Instruction-tuning data.We use two target distributions. For Anthropic-HH, we use the Anthropic/hh-rlhf training split [Bai et al., 2022] and keep the chosen transcript from each 22 0 20 40Normalized return Medium HalfCheetah 20 40 60 80 100Normalized return Medium Hopper 0 20 40 6...
2022
-
[12]
23 Table 5: OLMo-1B checkpoints used in the fine-tuning experiments
We do not use a validation split or early stopping during fine-tuning. 23 Table 5: OLMo-1B checkpoints used in the fine-tuning experiments. Checkpoint Short name Pretraining tokens step330000-tokens1383B1383B 1.383T step447000-tokens1874B1874B 1.874T step512000-tokens2146B2146B 2.146T step561250-tokens2353B2353B 2.353T step600000-tokens2515B2515B 2.515T s...
2019
-
[13]
The learning-rate sweep is η∈ {10 −5,5·10 −5,10 −4}
The resulting training lengths are 141 update steps for Anthropic-HH and 483 update steps for Tulu-v1, corresponding to 36.96M and 126.62M target tokens respectively. The learning-rate sweep is η∈ {10 −5,5·10 −5,10 −4}. For each checkpoint, target, method configuration, and learning rate, we run data-order seeds{0,1,2} . This gives 7 checkpoints ×2 target...
2023
-
[14]
Judging uses Meta-Llama-3-70B-Instruct [Grattafiori et al., 2024] in vLLM with tensor parallel size 4, temperature 0, maximum 8 judge tokens, and a response character cap of 12,000
We judge each candidate against a target- matched hard-switch reference trained from the 1874B checkpoint with learning rate 10−5 and seed 0; the same reference responses are reused for all pretraining budgets within a target family. Judging uses Meta-Llama-3-70B-Instruct [Grattafiori et al., 2024] in vLLM with tensor parallel size 4, temperature 0, maxim...
2024
-
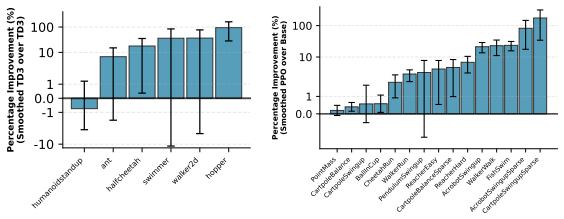
[15]
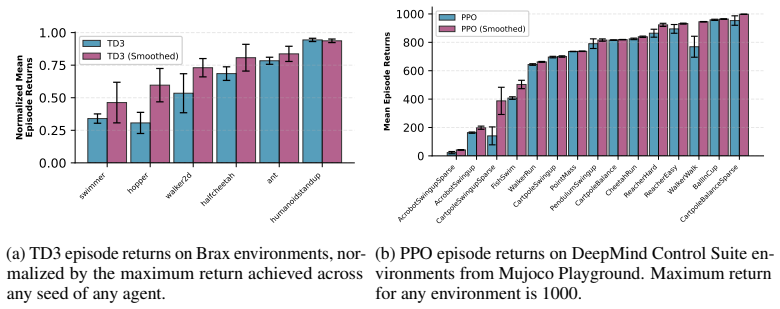
E Online Reinforcement Learning E.1 Additional Results We show the raw returns for the TD3 and PPO experiments in Figure 14a and Figure 14b, respectively
Figure 14: TD3 and PPO final performance on each task. E Online Reinforcement Learning E.1 Additional Results We show the raw returns for the TD3 and PPO experiments in Figure 14a and Figure 14b, respectively. E.2 Experimental Details Our code is based on the rejax codebase [Liesen et al., 2024]. TD3For the base algorithm, we take the hyperparameters pres...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.