EFlow: Learning Evidence Flow for Long-Video Reasoning with Adaptive Reflection
Pith reviewed 2026-07-02 14:17 UTC · model grok-4.3
The pith
EFlow separates temporal grounding from reasoning via distinct CoT steps to avoid biased evidence retrieval in long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
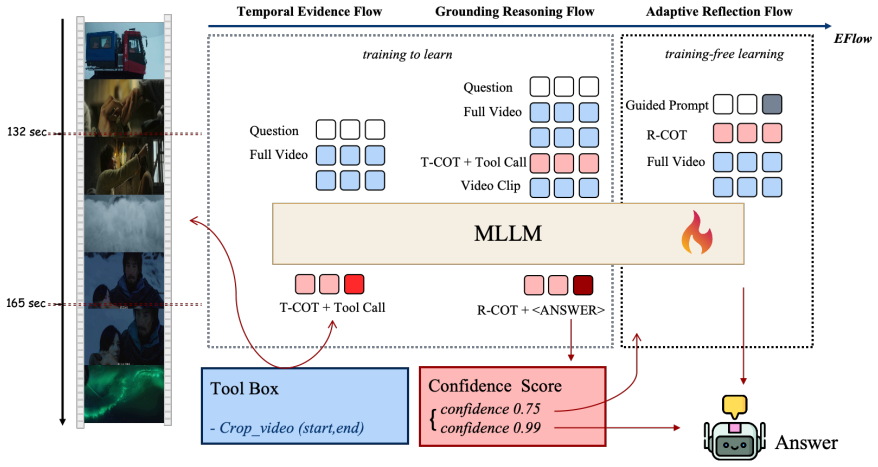
EFlow is an evidence-first video reasoning framework built upon Qwen3-VL that explicitly separates temporal grounding and logical reasoning through CoT for Temporal Grounding and CoT for Reasoning, enabling the model to retrieve relevant evidence before answer inference. In addition, EFlow introduces a confidence-aware reflection mechanism that re-evaluates the full video when retrieved evidence is potentially insufficient. Dedicated trajectory datasets are constructed and the model is trained through supervised fine-tuning, reinforcement learning, and reinforcement fine-tuning, yielding consistent improvements across five video understanding benchmarks.
What carries the argument
Dual-chain-of-thought structure that performs temporal grounding before reasoning, together with a confidence-aware reflection mechanism that triggers full-video re-evaluation.
If this is right
- Relevant evidence segments are located without distortion from early answer hypotheses.
- Low-confidence cases trigger a second full-video pass that can recover missing information.
- Staged training on trajectory data teaches the model to maintain the evidence-first order.
- Performance gains appear consistently on multiple long-video understanding benchmarks.
Where Pith is reading between the lines
- The separation pattern may transfer to other multimodal settings where perception and inference can mutually bias each other.
- Reflection could be extended to multiple iterative rounds rather than a single re-evaluation pass.
- The emphasis on curated trajectory data implies that standard video-caption pairs alone may be insufficient for learning proper evidence flow.
Load-bearing premise
Interleaving temporal grounding and answer reasoning inside one trajectory creates premature semantic commitment that biases evidence localization, and separating the two stages reliably prevents this bias.
What would settle it
Train the base model on identical data once with interleaved trajectories and once with separated grounding-then-reasoning trajectories, then compare both the completeness of retrieved evidence segments and final answer accuracy on the same long-video test sets.
Figures


read the original abstract
Long-video reasoning is fundamentally constrained by how models acquire and utilize visual evidence. Existing tool-augmented video frameworks often interleave temporal grounding and answer reasoning within a single trajectory, causing early semantic hypotheses to bias evidence localization. We term this failure mode premature semantic commitment, where biased grounding retrieves incomplete evidence and incomplete evidence further reinforces incorrect reasoning. To address this issue, we propose EFlow, an evidence-first video reasoning framework built upon Qwen3-VL. EFlow explicitly separates temporal grounding and logical reasoning through CoT for Temporal Grounding and CoT for Reasoning, enabling the model to retrieve relevant evidence before answer inference. In addition, EFlow introduces a confidence-aware reflection mechanism that re-evaluates the full video when retrieved evidence is potentially insufficient. We further construct dedicated trajectory datasets and train EFlow through supervised fine-tuning, reinforcement learning, and reinforcement fine-tuning. Extensive experiments across five video understanding benchmarks demonstrate that EFlow consistently improves long-video reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EFlow, an evidence-first framework for long-video reasoning built on Qwen3-VL. It separates CoT for Temporal Grounding from CoT for Reasoning to avoid premature semantic commitment, adds a confidence-aware reflection mechanism that re-evaluates the full video when evidence is insufficient, constructs dedicated trajectory datasets, and trains via supervised fine-tuning, reinforcement learning, and reinforcement fine-tuning. The central claim is that this yields consistent improvements on five video understanding benchmarks.
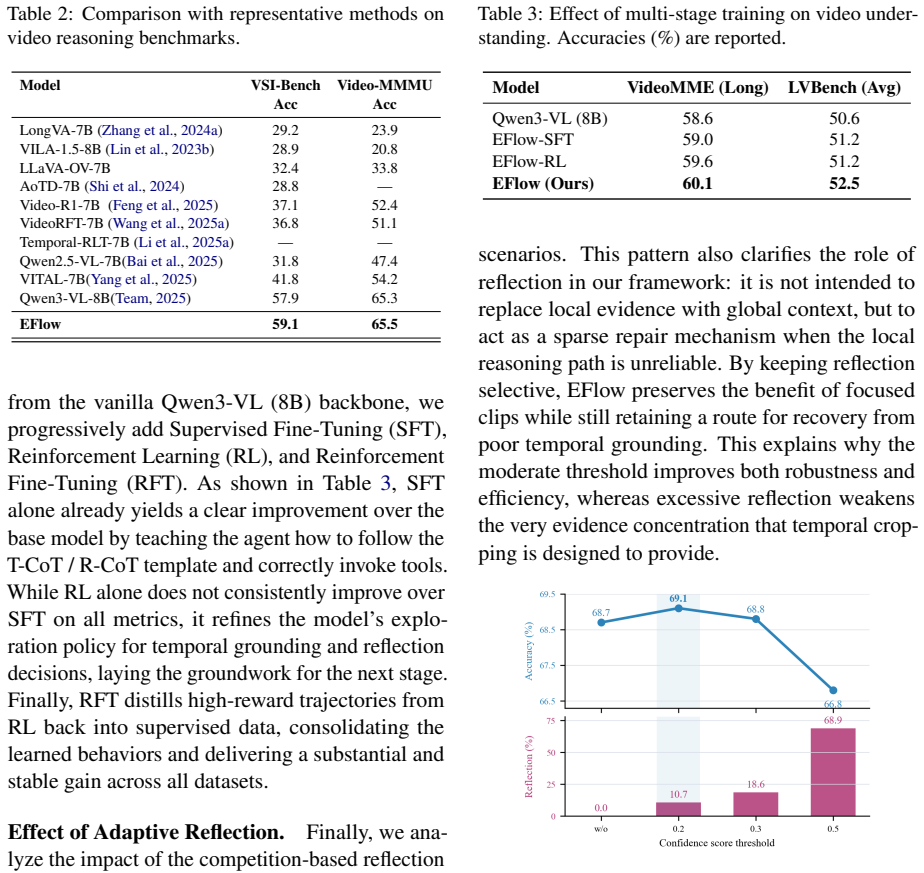
Significance. If the empirical gains hold and the separation of grounding and reasoning stages demonstrably reduces biased evidence retrieval, the work could supply a reusable pattern for structured long-video reasoning. The explicit construction of trajectory datasets and the multi-stage training pipeline (SFT + RL + RFT) are concrete strengths that could be adopted by other video-reasoning efforts.
major comments (3)
- [Abstract] Abstract: the assertion of 'consistent improvements across five video understanding benchmarks' is unsupported by any quantitative results, baselines, error bars, or dataset-construction details, so the central empirical claim cannot be evaluated from the supplied text.
- [§3] §3 (Trajectory Dataset Construction): the process for building the dedicated trajectory datasets is described at too high a level to verify that the CoT stages are truly separated or to reproduce the training data used for the reported gains.
- [§4] §4 (Experiments): no ablation isolating the effect of the separated CoT stages versus an interleaved baseline is referenced, leaving the motivating hypothesis about premature semantic commitment untested within the manuscript.
minor comments (2)
- The term 'premature semantic commitment' is introduced without citation to related concepts in chain-of-thought or tool-use literature.
- Notation for the confidence score used in the reflection mechanism is not defined in the main text or equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'consistent improvements across five video understanding benchmarks' is unsupported by any quantitative results, baselines, error bars, or dataset-construction details, so the central empirical claim cannot be evaluated from the supplied text.
Authors: We acknowledge that the abstract lacks specific metrics. The full manuscript reports results in §4 with baselines and comparisons, but to make the claim evaluable from the abstract alone we will revise it to include key quantitative gains, baseline references, and error-bar information. revision: yes
-
Referee: [§3] §3 (Trajectory Dataset Construction): the process for building the dedicated trajectory datasets is described at too high a level to verify that the CoT stages are truly separated or to reproduce the training data used for the reported gains.
Authors: We agree the description is high-level. In revision we will expand §3 with concrete examples of separated CoT trajectories, the exact annotation protocol used to enforce separation between temporal grounding and reasoning, and additional reproducibility details on dataset construction. revision: yes
-
Referee: [§4] §4 (Experiments): no ablation isolating the effect of the separated CoT stages versus an interleaved baseline is referenced, leaving the motivating hypothesis about premature semantic commitment untested within the manuscript.
Authors: The current experiments demonstrate overall gains but do not contain a dedicated ablation of separated versus interleaved CoT. We will add this ablation study in the revised §4 to directly evaluate the premature semantic commitment hypothesis. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents EFlow as an engineering framework that separates CoT for Temporal Grounding from CoT for Reasoning and adds a confidence-aware reflection step to mitigate premature semantic commitment. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citation chains appear in the provided abstract or reader summary. The central claims rest on a descriptive motivation and standard training procedures (SFT, RL, RFT) on constructed datasets rather than any derivation that reduces to its own inputs by construction. This is a methodological proposal whose validity is to be assessed empirically, not a self-referential derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923. Yifan Chen and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Video-zoomer: Zoom in for reasoning about long videos with multi- granularity.arXiv preprint arXiv:2505.02420. DeepSeek-AI
-
[3]
Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. Kaituo Feng, Kaixiong Shao, Zihan Liu, Dongxu Xu, Yue Zhu, Bin Xie, and Feng Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Video-R1: Reinforcing Video Reasoning in MLLMs
Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776. Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuan- han Zhang, Xiang Yue, Bo Li, and Ziwei Liu
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos.arXiv preprint arXiv:2501.13826. Hongbo Jin, Qingyuan Wang, Wenhao Zhang, Yang Liu, and Sijie Cheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Peng Jin, Jinfa Ryu, Yuan Huang, Bin Lin, and 1 others
Videomem: Enhancing ultra-long video understanding via adaptive memory management.arXiv preprint arXiv:2512.04540. Peng Jin, Jinfa Ryu, Yuan Huang, Bin Lin, and 1 others
-
[7]
arXiv preprint arXiv:2311.08046 , year=
Chat-univi: Unified visual representation em- powers large language models with image and video understanding.arXiv preprint arXiv:2311.08046. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li
-
[8]
LLaVA-OneVision: Easy Visual Task Transfer
Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326. Hongyu Li, Songhao Han, Yue Liao, Junfeng Luo, Jialin Gao, Shuicheng Yan, and Si Liu. 2025a. Reinforcement learning tuning for videollms: Re- ward design and data efficiency.arXiv preprint arXiv:2506.01908. Xinhao Li and 1 others. 2025b. Videochat-r1: Enhanc- ing spatio-temporal ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424. Shuhuai Ren, Bin Lin, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Timechat: A time- sensitive multimodal large language model for long video un- derstanding,
Timechat: A time-sensitive multimodal large language model for long video understanding.arXiv preprint arXiv:2312.02051. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models.arXiv preprint arXiv:2402.03300. Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
Enhancing video-llm reasoning via agent-of-thoughts distillation.arXiv preprint arXiv:2412.01694. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
- [13]
-
[14]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. 2025a. Videorft: Incentivizing video reason- ing capability in mllms via reinforced fine-tuning. arXiv preprint arXiv:2505.12434. Shihao Wang, Guo Chen, De-an Huang, Zhiqi Li, Ming- han Li, Guilin Li, Jose M Alvarez, Lei Zhang, and Zhiding Yu. 2...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Longvideobench: A benchmark for long-context interleaved video-language understanding.arXiv preprint arXiv:2407.15754. Hang Yan and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Jihan Yang, Shusheng Yang, Anjali W
Rewatch: Watch again to reason better with llms.arXiv preprint arXiv:2505.05515. Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
-
[17]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Thinking in space: How multimodal large language models see, remember, and recall spaces.arXiv preprint arXiv:2412.14171. Shuwei Yang and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Vital: A tool- augmented video agent with reinforcement learn- ing for long video understanding.arXiv preprint arXiv:2505.03458. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Long Context Transfer from Language to Vision
React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations. Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Hao- ran Tan, Chunyuan Li, and Ziwei Liu. 2024a. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852. Yuanhan Zhang, Bo L...
work page internal anchor Pith review Pith/arXiv arXiv
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.