Dynamic Bidirectional Pattern Memory: A Production-Scale Empirical Characterisation of Inference-Time Gating in Clinical NLP
Pith reviewed 2026-07-02 13:17 UTC · model grok-4.3
The pith
In clinical NLP generator-verifier pipelines, learned memory filters fail at scale unless they test the same evidence the verifier weighs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Together these give a transferable result for any generator-verifier pipeline: the most natural memory design can fail silently at scale, and whether a pre-generation gate is selective is decided before any engineering effort, by whether its signal probes the question the verifier itself answers. Throughout, the system flags suspect extractions rather than deleting them, so every decision stays visible for clinical review.
What carries the argument
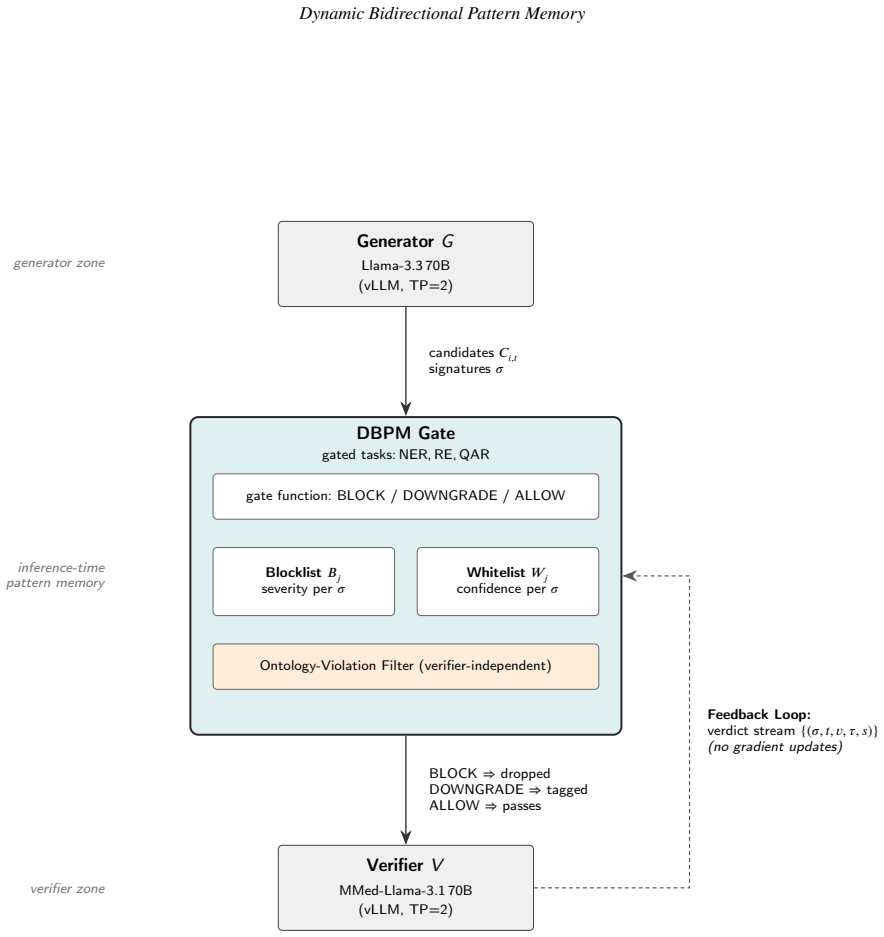
Inference-time pattern-memory gating that learns at deployment which extractions to filter so the verifier need not re-examine candidates already seen to fail.
If this is right
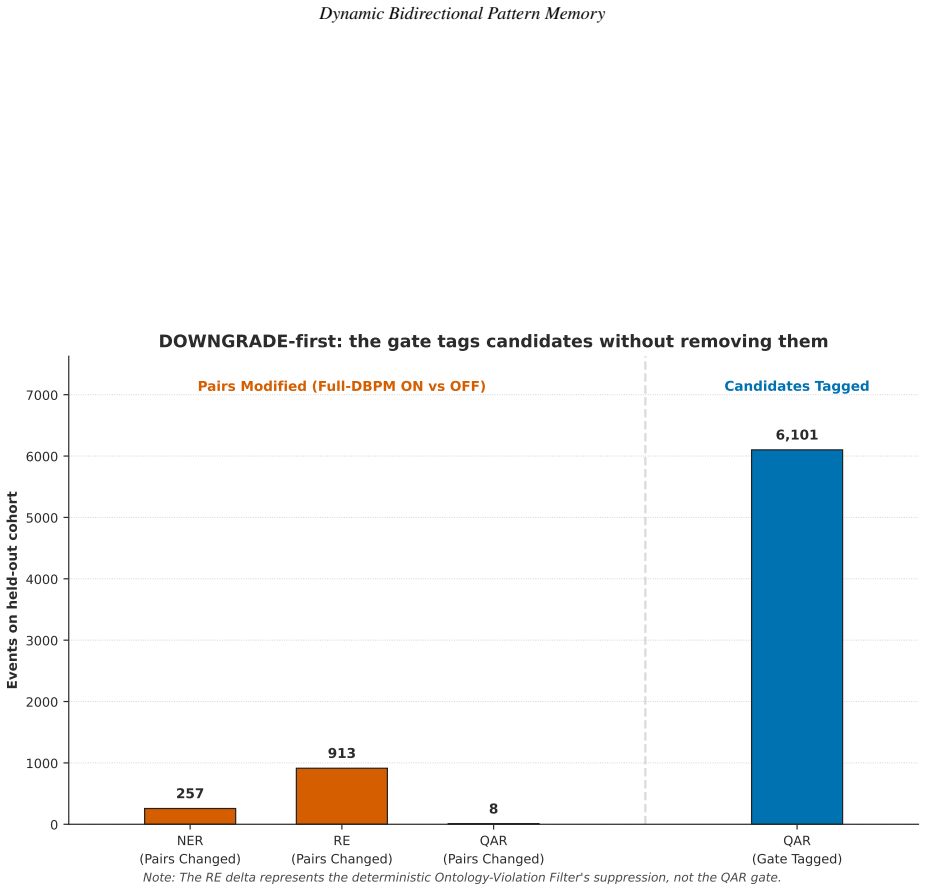
- A relation-extraction filter learned from verifier rejections remains empty at full scale.
- A fixed clinical ontology produces the same filtering effect without calling the verifier.
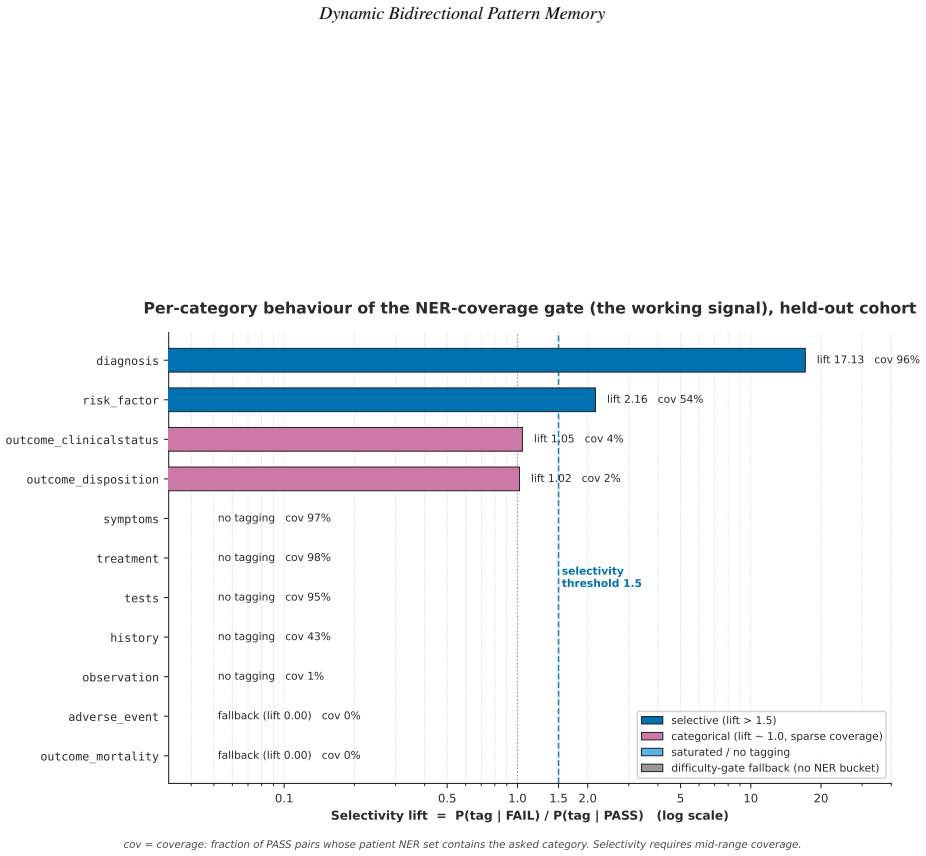
- A question-answering filter succeeds only when it checks whether extracted entities support the question asked.
- A filter is selective only when it tests the same evidence the verifier weighs, not when it imitates the verifier's output.
Where Pith is reading between the lines
- The selectivity principle may apply to generator-verifier pipelines in non-clinical domains where rejection patterns are similarly sparse.
- Pre-designing gates around the verifier's core evidence type could reduce compute before any deployment data is collected.
- Experiments on tasks engineered to produce clustered rejections would directly test whether the observed failure mode is dataset-specific.
Load-bearing premise
The sparsity of rejections across many distinct forms is a general property of clinical NLP pipelines rather than an artifact of this dataset, models, and extraction task.
What would settle it
Running the identical generator-verifier pipeline on a different clinical dataset where the verifier's rejections cluster on a small number of repeated forms, allowing a learned filter to accumulate rejections and become non-empty.
Figures
read the original abstract
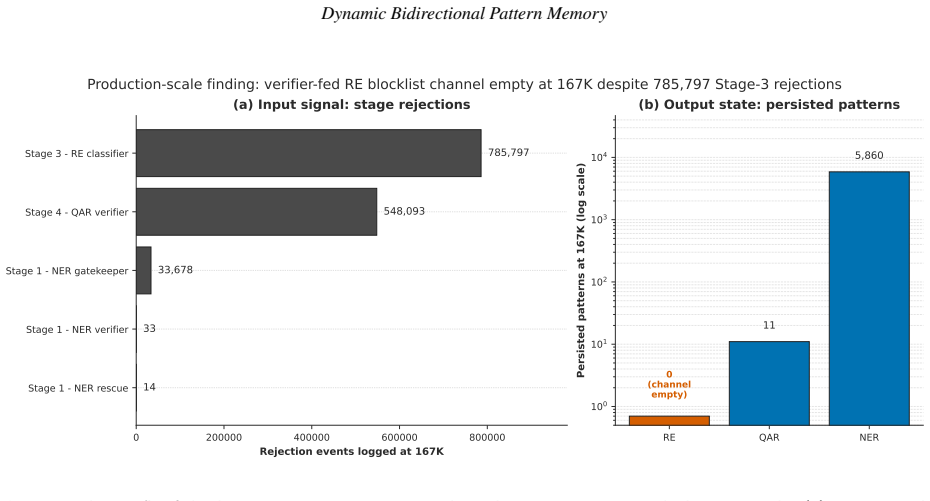
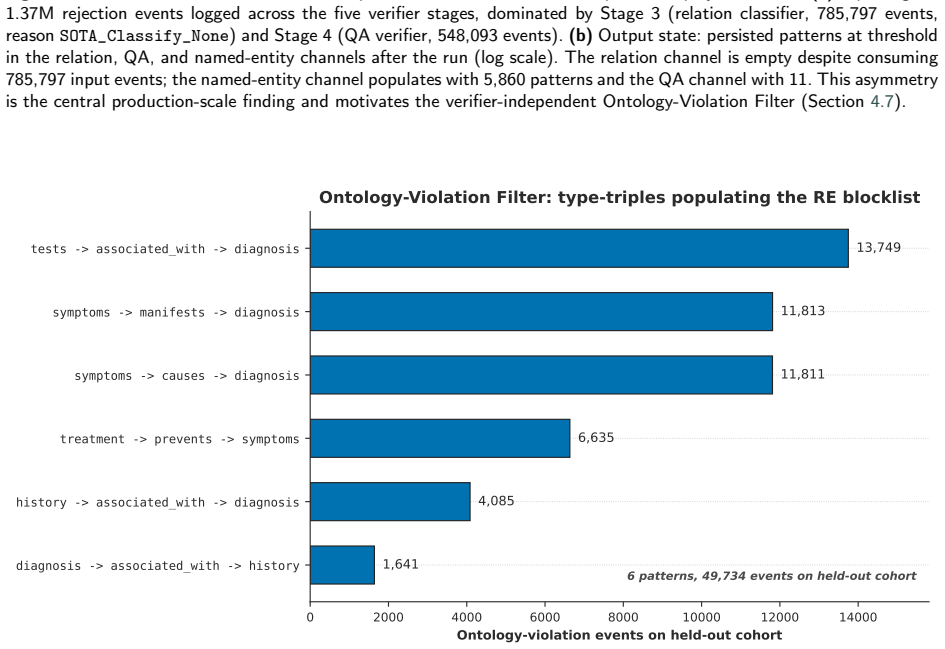
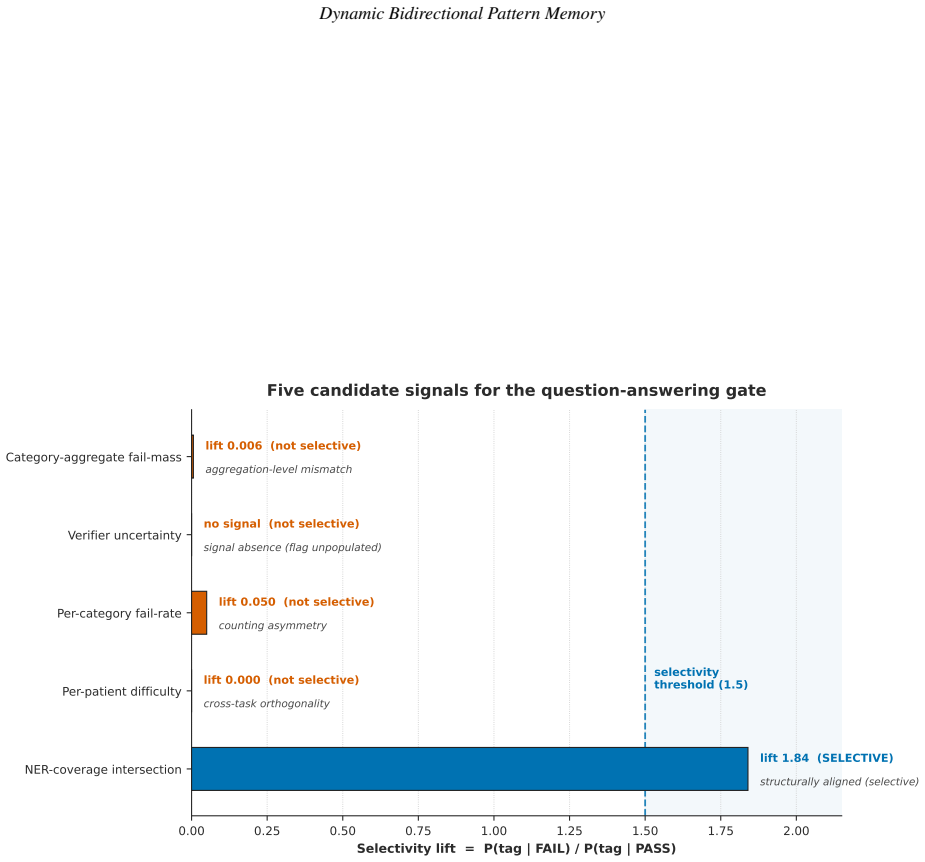
We study inference-time pattern-memory gating in a production-scale clinical natural language processing (NLP) pipeline. The pipeline pairs a generator (Llama-3.3 70B) proposing extractions with a verifier (MMed-Llama-3.1 70B) accepting or rejecting them, over 167,034 PMC-Patients narratives, and adds a lightweight memory that learns at deployment which extractions to filter, so the verifier need not re-examine candidates already seen to fail. We report four findings. First, learning filtering rules directly from the verifier's rejections failed at full scale: the relation-extraction filter stayed empty despite 785,797 logged rejections, because they were spread too thinly across too many distinct forms to accumulate. Second, a simpler rule using a fixed clinical ontology produced the same filtering without the verifier, capturing 49,734 ontology-violating relations on a held-out 5,000-patient set. Third, of five versions of the question-answering filter, four failed for distinct, instructive reasons; the fifth succeeded by checking whether a patient's extracted entities support the question asked, and where it applies was 1.84 times likelier to flag an answer the verifier would reject than one it would accept. Fourth, one pattern held across all five: a filter is selective only when it tests the same evidence the verifier weighs, not when it imitates the verifier's output. Together these give a transferable result for any generator-verifier pipeline: the most natural memory design can fail silently at scale, and whether a pre-generation gate is selective is decided before any engineering effort, by whether its signal probes the question the verifier itself answers. Throughout, the system flags suspect extractions rather than deleting them, so every decision stays visible for clinical review. All code and test artefacts are released openly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies inference-time pattern-memory gating in a production-scale clinical NLP pipeline pairing Llama-3.3 70B (generator) with MMed-Llama-3.1 70B (verifier) over 167,034 PMC-Patients narratives. It reports four findings from direct observation of 785,797 rejections and held-out tests: (1) learning filters from verifier rejections fails at scale due to sparsity across distinct forms, yielding an empty filter; (2) a fixed clinical ontology rule captures 49,734 violating relations without the verifier; (3) of five QA filter variants, only the entity-support check succeeds and is 1.84 times likelier to flag verifier-rejected answers; (4) selectivity occurs only when the filter probes the same evidence as the verifier. The paper concludes with a transferable design principle for generator-verifier systems and releases all code and artefacts.
Significance. If the empirical observations hold, the work provides concrete, actionable guidance on why natural memory designs fail silently at scale in clinical extraction pipelines and why filter selectivity is determined by evidence alignment rather than output imitation. The open release of code and test artefacts is a clear strength supporting reproducibility. The findings are directly relevant to production deployment of LLM-based clinical NLP systems.
major comments (2)
- [Abstract] Abstract (transferable result paragraph): the claim that the four findings yield a transferable result for any generator-verifier pipeline is load-bearing for the paper's broader contribution, yet the evidence consists of a single corpus (PMC-Patients), task (relation extraction), and model pair; no cross-dataset, cross-task, or cross-model replication is described to establish the conditions under which sparsity-induced filter failure must occur.
- [Abstract] Abstract (third finding): the reported 1.84 times likelihood for the successful QA filter is presented without accompanying details on the underlying statistical test, sample sizes per condition, confidence intervals, or exact computation from the held-out 5,000-patient set, which limits verification of this quantitative claim central to finding (3).
minor comments (1)
- [Abstract] Abstract: the five QA filter variants are referenced but not briefly distinguished, which would improve clarity for readers evaluating why four failed for distinct reasons.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where the presentation of our empirical findings can be strengthened. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (transferable result paragraph): the claim that the four findings yield a transferable result for any generator-verifier pipeline is load-bearing for the paper's broader contribution, yet the evidence consists of a single corpus (PMC-Patients), task (relation extraction), and model pair; no cross-dataset, cross-task, or cross-model replication is described to establish the conditions under which sparsity-induced filter failure must occur.
Authors: We agree that the evidence base is a single empirical setting and that the absence of cross-replication limits the strength of any general claim. The transferable result is framed as a design principle inferred from the observed mechanisms (sparsity across distinct forms and the requirement for evidence alignment), which arise from properties of high-cardinality clinical relation spaces rather than from the specific corpus or models. Nevertheless, we will revise the abstract to qualify the language as yielding 'a candidate transferable design principle' and will expand the discussion to state the single-setting limitation explicitly along with the conditions under which the principle is expected to apply. revision: yes
-
Referee: [Abstract] Abstract (third finding): the reported 1.84 times likelihood for the successful QA filter is presented without accompanying details on the underlying statistical test, sample sizes per condition, confidence intervals, or exact computation from the held-out 5,000-patient set, which limits verification of this quantitative claim central to finding (3).
Authors: We will incorporate the requested details into the revised manuscript. The 1.84 ratio was obtained on the held-out 5,000-patient set by dividing the proportion of verifier-rejected answers flagged by the entity-support QA filter by the proportion of accepted answers flagged by the same filter. The revision will report the contingency-table counts for each condition, the exact computational procedure, the statistical test applied, the associated p-value, and 95% confidence intervals around the ratio. revision: yes
Circularity Check
No circularity: empirical counts and filter outcomes on external data
full rationale
The manuscript reports direct experimental outcomes from executing a generator-verifier pipeline on the PMC-Patients corpus (167k narratives, 785k rejections). All four findings are observational tallies (empty learned filter, ontology capture rate, QA filter success/failure rates, 1.84x selectivity ratio) with no equations, fitted parameters renamed as predictions, or self-citations that bear the central claim. The transferable statement follows from the observed pattern that only filters probing the verifier's own evidence succeed; this is a post-hoc summary of the runs, not a reduction to inputs by construction. No self-definitional loops, ansatzes, or uniqueness theorems appear.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The fixed clinical ontology is sufficiently complete and accurate to capture ontology-violating relations without false positives that would invalidate the no-verifier filtering result.
Reference graph
Works this paper leans on
-
[1]
1877–1901
Language models are few-shot learners, in: Advances in Neural Information Processing Systems, pp. 1877–1901. Chiang,W.L.,Li,Z.,Lin,Z.,Sheng,Y.,Wu,Z.,Zhang,H.,Zheng,L.,Zhuang,S.,Zhuang,Y.,Gonzalez,J.E.,Stoica,I.,Xing,E.P.,2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. URL:https://vicuna.lmsys.org. A.H. Lazem et al.:Preprin...
1901
-
[2]
Journal of the American Medical Informatics Association 27, 3–12
2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records. Journal of the American Medical Informatics Association 27, 3–12. doi:10.1093/jamia/ocz166. Hinton, G., Vinyals, O., Dean, J.,
-
[3]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 . Hong,S.,Zhuge,M.,Chen,J.,Zheng,X.,Cheng,Y.,Wang,J.,Zhang,C.,Wang,Z.,Yau,S.K.S.,Lin,Z.,etal.,2024. Metagpt:Metaprogramming for a multi-agent collaborative framework, in: International Conference on Learning Representations. Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences 114, 3521–3526. doi:10.1073/pnas.1611835114. Lee, D.H.,
-
[5]
Self-Refine: Iterative Refinement with Self-Feedback
Self-refine: Iterative refinement with self-feedback, in: Advances in Neural Information Processing Systems. URL:https://arxiv.org/abs/2303.17651. Parisi, G.I., Kemker, R., Part, J.L., Kanan, C., Wermter, S.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Trainingcomplexmodelswithmulti-taskweaksupervision,in:Proceedings of the AAAI Conference on Artificial Intelligence, pp
Ratner,A.,Hancock,B.,Dunnmon,J.,Sala,F.,Pandey,S.,Ré,C.,2019. Trainingcomplexmodelswithmulti-taskweaksupervision,in:Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4763–4771. Santoro,A.,Bartunov,S.,Botvinick,M.,Wierstra,D.,Lillicrap,T.,2016. Meta-learningwithmemory-augmentedneuralnetworks,in:International Conference on Machine Learning,...
2019
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal reinforcement learning, in: Advances in Neural Information Processing Systems. URL:https://arxiv.org/abs/2303.11366. Sukhbaatar, S., Szlam, A., Weston, J., Fergus, R.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Journal of Artificial Intelligence Research 7, 83–124
Towards flexible teamwork. Journal of Artificial Intelligence Research 7, 83–124. doi:10.1613/jair.433. Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., Hashimoto, T.B.,
-
[9]
Wei,J.,Wang,X.,Schuurmans,D.,Bosma,M.,Ichter,B.,Xia,F.,Chi,E.H.,Le,Q.V.,Zhou,D.,2022
Self-consistency improves chain-of-thought reasoning in language models, in: International Conference on Learning Representations. Wei,J.,Wang,X.,Schuurmans,D.,Bosma,M.,Ichter,B.,Xia,F.,Chi,E.H.,Le,Q.V.,Zhou,D.,2022. Chain-of-thoughtpromptingelicitsreasoning in large language models, in: Advances in Neural Information Processing Systems, pp. 24824–24837. ...
2022
-
[10]
Xie,Q.,Luong,M.T.,Hovy,E.,Le,Q.V.,2020
Autogen: Enabling next-gen llm applications via multi-agent conversation, in: First Conference on Language Modeling. Xie,Q.,Luong,M.T.,Hovy,E.,Le,Q.V.,2020. Self-trainingwithnoisystudentimprovesimagenetclassification,in:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698. Yao, S., Zhao, J., Yu, D., Du, N., Shafr...
2020
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models, in: International Conference on Learning Representations. URL:https://arxiv.org/abs/2210.03629. Zhang,Q.,Hu,C.,Upasani,S.,Ma,B.,Hong,F.,Kamanuru,V.,Rainton,J.,Wu,C.,Ji,M.,Li,H.,Thakker,U.,Zou,J.,Olukotun,K.,2026. Agentic context engineering: Evolving contexts for self-improving language models, i...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
This asymmetry is the central production-scale finding and motivates the verifier-independent Ontology-Violation Filter (Section 4.7). 0 2000 4000 6000 8000 10000 12000 14000 Ontology-violation events on held-out cohort tests -> associated_with -> diagnosis symptoms -> manifests -> diagnosis symptoms -> causes -> diagnosis treatment -> prevents -> symptom...
2000
-
[13]
A.H. Lazem et al.:Preprint submitted to ElsevierPage 36 of 39 Dynamic Bidirectional Pattern Memory 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Selectivity lift = P(tag | FAIL) / P(tag | PASS) Category-aggregate fail-mass Verifier uncertainty Per-category fail-rate Per-patient difficulty NER-coverage intersection lift 0.006 (not selective) aggregation-lev...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.