AVSR-Diff: Scale-Agnostic Diffusion Priors for Temporally Consistent Arbitrary-Scale Video Super-Resolution
Pith reviewed 2026-07-02 14:04 UTC · model grok-4.3
The pith
Separating latent denoising from coordinate rendering yields temporally stable arbitrary-scale video super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
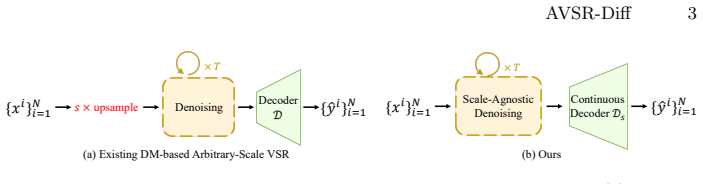
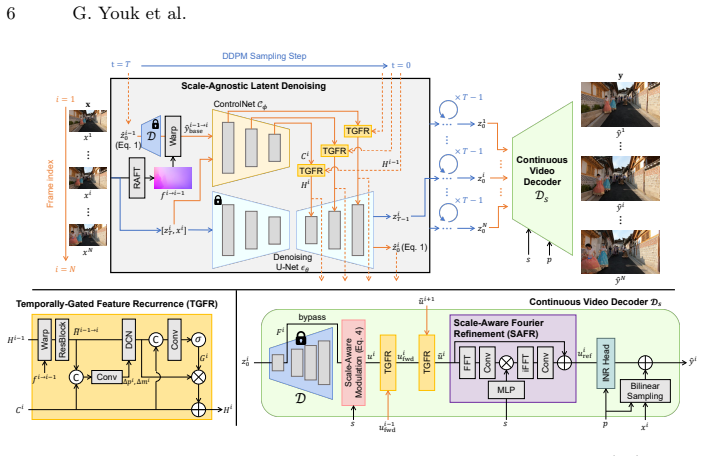
AVSR-Diff separates scale-agnostic latent denoising from continuous coordinate rendering, avoiding resolution-specific diffusion sampling, and introduces the Temporally-Gated Feature Recurrence module to produce strictly aligned temporal priors together with a Scale-Aware Fourier Refinement module inside a continuous video VAE decoder that adapts frequency components to any target scale.
What carries the argument
The decoupled framework that isolates scale-agnostic latent denoising from continuous coordinate rendering, carried by the Temporally-Gated Feature Recurrence module for frame-aligned priors and the Scale-Aware Fourier Refinement module for scale-adaptive frequency adjustment.
If this is right
- Arbitrary-scale video super-resolution becomes feasible without trading away temporal stability.
- High-frequency detail preservation holds across a continuous range of upsampling factors rather than only at discrete fixed scales.
- The same latent priors can be reused for multiple output resolutions without repeated full diffusion runs.
- Performance at native resolution can exceed that of recent fixed-scale generative models.
Where Pith is reading between the lines
- The same separation of denoising and rendering stages could be tested on other video generation tasks that need both scale flexibility and motion coherence.
- Extending the continuous decoder to handle downscaling or mixed-resolution inputs would be a direct next step.
- Real-world deployment would benefit from checking whether the method remains stable on camera footage with complex motion or compression artifacts.
Load-bearing premise
Separating the denoising stage from scale-specific rendering and adding the gated recurrence module will remove the temporal flickering that diffusion stochasticity normally produces.
What would settle it
Side-by-side video sequences at scaling factors of 4x and 8x that show whether AVSR-Diff exhibits visibly less frame-to-frame flickering than prior arbitrary-scale and fixed-scale diffusion baselines.
Figures



read the original abstract
Diffusion models have significantly advanced video super-resolution (VSR) but remain largely constrained to fixed upsampling scales. Conversely, while coordinate-based arbitrary-scale VSR methods offer scale flexibility, they inherently suffer from severe over-smoothing at large scaling factors. Integrating generative priors with continuous decoding is promising but currently hindered by severe temporal flickering caused by the stochasticity of diffusion sampling. To address this, we propose AVSR-Diff (Arbitrary-scale Video Super-Resolution with Diffusion), a novel decoupled framework that separates scale-agnostic latent denoising from continuous coordinate rendering, effectively avoiding computationally heavy resolution-specific sampling. Our approach introduces a Temporally-Gated Feature Recurrence (TGFR) module to extract strictly aligned, temporally consistent latent priors. Furthermore, we design a continuous video VAE decoder incorporating a Scale-Aware Fourier Refinement (SAFR) module to dynamically adapt frequency components to any target scale. Extensive experiments demonstrate that AVSR-Diff consistently preserves high-frequency details and strong temporal stability across various scales, surpassing state-of-the-art arbitrary-scale baselines. Remarkably, our framework outperforms recent fixed-scale generative models even on their native resolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AVSR-Diff, a decoupled framework for arbitrary-scale video super-resolution that integrates diffusion priors. It separates scale-agnostic latent denoising from continuous coordinate rendering to mitigate temporal flickering induced by diffusion stochasticity, introduces the Temporally-Gated Feature Recurrence (TGFR) module to produce aligned latent priors, and incorporates a Scale-Aware Fourier Refinement (SAFR) module in a continuous video VAE decoder. The central claim is that this architecture preserves high-frequency details and temporal stability across scales, outperforming state-of-the-art arbitrary-scale baselines and even fixed-scale generative models at native resolutions, as supported by extensive experiments.
Significance. If the experimental claims hold, the work addresses a practical barrier in combining generative diffusion models with coordinate-based arbitrary-scale VSR. The decoupling strategy and TGFR/SAFR modules offer a coherent architectural solution to temporal consistency, which could influence future video enhancement pipelines. The absence of parameter-free derivations or machine-checked proofs is noted, but the approach is grounded in standard architectural choices rather than circular fitting.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts that 'extensive experiments demonstrate' superiority in high-frequency detail preservation and temporal stability, yet the provided text contains no quantitative metrics, error bars, dataset specifications, or statistical comparisons. This leaves the central empirical claim without verifiable support.
- [§3.2] §3.2 (TGFR module): The claim that recurrent gating produces 'strictly aligned, temporally consistent latent priors' that eliminate diffusion-induced flickering rests on an unverified assumption about alignment properties across scales; no ablation isolating TGFR's contribution to temporal metrics (e.g., temporal consistency scores) is referenced to substantiate this load-bearing component.
- [§4] §4 (Experiments): The surprising claim that the method outperforms recent fixed-scale generative models 'even on their native resolution' requires explicit side-by-side quantitative results and controls for implementation differences; without these, the cross-paradigm comparison cannot be evaluated.
minor comments (2)
- [§3] Clarify the exact interface between the scale-agnostic latent space and the continuous coordinate renderer to avoid ambiguity in how scale information is injected.
- [Figures] Ensure all figures include scale-specific captions and that any temporal stability visualizations are accompanied by quantitative metrics rather than qualitative examples alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that will strengthen the empirical support and clarity of the claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts that 'extensive experiments demonstrate' superiority in high-frequency detail preservation and temporal stability, yet the provided text contains no quantitative metrics, error bars, dataset specifications, or statistical comparisons. This leaves the central empirical claim without verifiable support.
Authors: We agree that the abstract as presented lacks specific numerical support. The full §4 contains quantitative tables reporting PSNR, SSIM, LPIPS, and temporal metrics (tOF, warping error) on Vimeo-90K and REDS with comparisons to baselines. To resolve the concern, we will revise the abstract to incorporate key representative metrics, dataset names, and a brief mention of statistical comparisons, while adding error bars to relevant figures in §4. revision: yes
-
Referee: [§3.2] §3.2 (TGFR module): The claim that recurrent gating produces 'strictly aligned, temporally consistent latent priors' that eliminate diffusion-induced flickering rests on an unverified assumption about alignment properties across scales; no ablation isolating TGFR's contribution to temporal metrics (e.g., temporal consistency scores) is referenced to substantiate this load-bearing component.
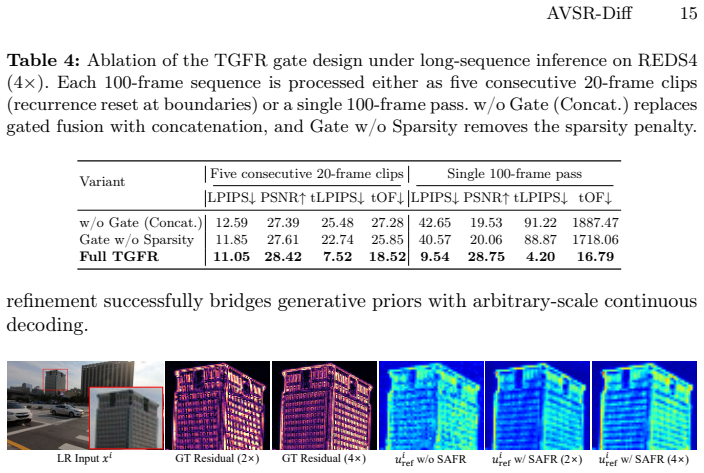
Authors: The referee correctly identifies that an isolated ablation of TGFR on temporal metrics is not explicitly referenced. While §4.3 presents component ablations for the overall framework, we will add a dedicated table in the revision that isolates TGFR's effect on temporal consistency scores (tOF and warping error) across scales to directly substantiate the module's contribution. revision: yes
-
Referee: [§4] §4 (Experiments): The surprising claim that the method outperforms recent fixed-scale generative models 'even on their native resolution' requires explicit side-by-side quantitative results and controls for implementation differences; without these, the cross-paradigm comparison cannot be evaluated.
Authors: We concur that direct side-by-side results with controls are necessary for the cross-paradigm claim. In the revised manuscript we will insert a new table in §4 that reports quantitative comparisons against recent fixed-scale generative models at their native resolutions, using official implementations and identical evaluation protocols to control for implementation differences. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an architectural framework (decoupled latent denoising + TGFR module + SAFR decoder) whose central claims rest on design choices and empirical validation rather than any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain is exhibited in the provided text that reduces outputs to inputs by construction; the approach is self-contained against external benchmarks with no visible reduction to prior author work or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-Cascaded Diffusion Models for Arbitrary-Scale Image Super-Resolution
Bang, J., Lee, J., Lee, K., Lee, H., Kang, D.U., Chun, S.Y.: Self-cascaded diffusion models for arbitrary-scale image super-resolution. arXiv preprint arXiv:2506.07813 (2025) 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2509.26325 (2025) 11, 12, 25
Becker, A., Erbach, J., Narnhofer, D., Schindler, K.: Continuous space-time video super-resolution with 3d fourier fields. arXiv preprint arXiv:2509.26325 (2025) 11, 12, 25
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bernasconi, M., Djelouah, A., Zhang, Y., Gross, M., Schroers, C.: Ldip: Long distance information propagation for video super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11558–11567 (2025) 2, 4
2025
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, K.C., Wang, X., Yu, K., Dong, C., Loy, C.C.: Basicvsr: The search for essential components in video super-resolution and beyond. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4947–4956 (2021) 2, 4
2021
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, K.C., Zhou, S., Xu, X., Loy, C.C.: Basicvsr++: Improving video super- resolution with enhanced propagation and alignment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5972–5981 (2022) 2, 4, 7, 10, 11
2022
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, K.C., Zhou, S., Xu, X., Loy, C.C.: Investigating tradeoffs in real-world video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5962–5971 (2022) 4, 11, 12, 25
2022
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, Y.H., Chen, S.C., Lin, Y.Y., Peng, W.H.: Motif: Learning motion trajec- tories with local implicit neural functions for continuous space-time video super- resolution. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 23131–23141 (2023) 2, 4, 11, 12, 25
2023
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Y., Liu, S., Wang, X.: Learning continuous image representation with local implicit image function. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8628–8638 (2021) 2, 3, 4, 6, 9
2021
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen,Z.,Chen,Y.,Liu,J.,Xu,X.,Goel,V.,Wang,Z.,Shi,H.,Wang,X.:Videoinr: Learning video implicit neural representation for continuous space-time super- resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2047–2057 (2022) 2, 4, 11, 12, 25
2047
-
[10]
arXiv preprint arXiv:2505.16239 (2025) 2
Chen, Z., Zou, Z., Zhang, K., Su, X., Yuan, X., Guo, Y., Zhang, Y.: Dove: Effi- cient one-step diffusion model for real-world video super-resolution. arXiv preprint arXiv:2505.16239 (2025) 2
-
[11]
ACM Transactions on Graphics (TOG)39(4), 75–1 (2020) 10
Chu, M., Xie, Y., Mayer, J., Leal-Taixé, L., Thuerey, N.: Learning temporal co- herence via self-supervision for gan-based video generation. ACM Transactions on Graphics (TOG)39(4), 75–1 (2020) 10
2020
-
[12]
In: Proceedings of the IEEE international conference on computer vision
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolu- tional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 764–773 (2017) 3, 7
2017
-
[13]
Advances in neural information processing systems34, 8780–8794 (2021) 4
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021) 4
2021
-
[14]
IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020) 10
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unify- ing structure and texture similarity. IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020) 10
2020
-
[15]
In: Proceedings of the AVSR-Diff 17 IEEE/CVF conference on computer vision and pattern recognition
Gao, S., Liu, X., Zeng, B., Xu, S., Li, Y., Luo, X., Liu, J., Zhen, X., Zhang, B.: Implicit diffusion models for continuous super-resolution. In: Proceedings of the AVSR-Diff 17 IEEE/CVF conference on computer vision and pattern recognition. pp. 10021– 10030 (2023) 2, 5
2023
-
[16]
arXiv preprint arXiv:2407.07667 (2024) 2, 3, 4, 5, 11, 12, 22, 23, 25
He, J., Xue, T., Liu, D., Lin, X., Gao, P., Lin, D., Qiao, Y., Ouyang, W., Liu, Z.: Venhancer: Generative space-time enhancement for video generation. arXiv preprint arXiv:2407.07667 (2024) 2, 3, 4, 5, 11, 12, 22, 23, 25
-
[17]
Advances in neural information processing systems33, 6840–6851 (2020) 10
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 10
2020
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017) 10
2017
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, E., Kim, H., Jin, K.H., Yoo, J.: Bf-stvsr: B-splines and fourier—best friends for high fidelity spatial-temporal video super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28009– 28018 (2025) 2, 4, 11, 12, 25
2025
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, J., Kim, T.K.: Arbitrary-scale image generation and upsampling using latent diffusion model and implicit neural decoder. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9202–9211 (2024) 2, 5
2024
-
[21]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014) 10
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Z., Liu, H., Shang, F., Liu, Y., Wan, L., Feng, W.: Savsr: Arbitrary-scale video super-resolution via a learned scale-adaptive network. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 3288–3296 (2024) 2, 4, 11, 12, 25
2024
-
[23]
IEEE Transactions on Image Processing 33, 2171–2182 (2024) 2, 4
Liang, J., Cao, J., Fan, Y., Zhang, K., Ranjan, R., Li, Y., Timofte, R., Van Gool, L.: Vrt: A video restoration transformer. IEEE Transactions on Image Processing 33, 2171–2182 (2024) 2, 4
2024
-
[24]
Advances in Neural Information Processing Systems35, 378– 393 (2022) 2, 4, 10, 11
Liang, J., Fan, Y., Xiang, X., Ranjan, R., Ilg, E., Green, S., Cao, J., Zhang, K., Timofte, R., Gool, L.V.: Recurrent video restoration transformer with guided de- formable attention. Advances in Neural Information Processing Systems35, 378– 393 (2022) 2, 4, 10, 11
2022
-
[25]
IEEE transactions on pattern analysis and machine intelligence36(2), 346–360 (2013) 10
Liu, C., Sun, D.: On bayesian adaptive video super resolution. IEEE transactions on pattern analysis and machine intelligence36(2), 346–360 (2013) 10
2013
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, C., Yang, H., Fu, J., Qian, X.: Learning trajectory-aware transformer for video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5687–5696 (2022) 2, 4
2022
-
[27]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016) 10
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition workshops
Nah, S., Baik, S., Hong, S., Moon, G., Son, S., Timofte, R., Mu Lee, K.: Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition workshops. pp. 0–0 (2019) 10, 13
2019
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 3, 4, 5, 10, 23
2022
-
[30]
In: European Conference on Computer Vision
Rota, C., Buzzelli, M., van de Weijer, J.: Enhancing perceptual quality in video super-resolution through temporally-consistent detail synthesis using diffusion models. In: European Conference on Computer Vision. pp. 36–53. Springer (2024) 2, 4, 7, 11, 12, 25
2024
-
[31]
IEEE trans- actions on Signal Processing45(11), 2673–2681 (1997) 8 18 G
Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE trans- actions on Signal Processing45(11), 2673–2681 (1997) 8 18 G. Youk et al
1997
-
[32]
In: European Conference on Computer Vision
Shang, W., Ren, D., Zhang, W., Fang, Y., Zuo, W., Ma, K.: Arbitrary-scale video super-resolution with structural and textural priors. In: European Conference on Computer Vision. pp. 73–90. Springer (2024) 2, 4, 11, 12, 25
2024
-
[33]
In: European conference on computer vision
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: European conference on computer vision. pp. 402–419. Springer (2020) 7, 10
2020
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tian, Y., Zhang, Y., Fu, Y., Xu, C.: Tdan: Temporally-deformable alignment net- work for video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3360–3369 (2020) 2, 4
2020
-
[35]
Advances in neural information pro- cessing systems30(2017) 8
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) 8
2017
-
[36]
IEEE transactions on image processing 13(4), 600–612 (2004) 10
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004) 10
2004
-
[37]
Wolberg, G.: Digital image warping, vol. 10662. IEEE computer society press Los Alamitos, CA (1990) 7
1990
-
[38]
In: Proceedings of the European conference on computer vision (ECCV)
Wu, Y., He, K.: Group normalization. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018) 8
2018
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xie, R., Liu, Y., Zhou, P., Zhao, C., Zhou, J., Zhang, K., Zhang, Z., Yang, J., Yang, Z., Tai, Y.: Star: Spatial-temporal augmentation with text-to-video models for real-world video super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17108–17118 (2025) 2, 4, 11, 12, 25
2025
-
[40]
arXiv preprint arXiv:2511.16928 (2025) 2, 4
Xu, J., Zheng, M., Chen, Y., Qiao, M., Deng, X., Xu, M.: Rethinking diffusion model-based video super-resolution: Leveraging dense guidance from aligned fea- tures. arXiv preprint arXiv:2511.16928 (2025) 2, 4
-
[41]
Xu, K., Yu, Z., Wang, X., Mi, M.B., Yao, A.: Enhancing video super-resolution via implicitresampling-basedalignment.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 2546–2555 (2024) 2, 4
2024
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, Y., Park, T., Zhang, R., Zhou, Y., Shechtman, E., Liu, F., Huang, J.B., Liu, D.: Videogigagan: Towards detail-rich video super-resolution. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2139–2149 (2025) 4
2025
-
[43]
In: European conference on computer vision
Yang, X., He, C., Ma, J., Zhang, L.: Motion-guided latent diffusion for temporally consistent real-world video super-resolution. In: European conference on computer vision. pp. 224–242. Springer (2024) 2, 4, 11, 12, 25
2024
-
[44]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, X., Xiang, W., Zeng, H., Zhang, L.: Real-world video super-resolution: A benchmark dataset and a decomposition based learning scheme. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4781–4790 (2021) 4
2021
-
[45]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) 3, 5
2023
-
[46]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 10
2018
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, S., Yang, P., Wang, J., Luo, Y., Loy, C.C.: Upscale-a-video: Temporal- consistent diffusion model for real-world video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2535–2545 (2024) 2, 4, 11, 12, 25 AVSR-Diff 19
2024
-
[48]
Advances in neural information processing systems35, 26565–26577 (2022) 23
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. Advances in neural information processing systems35, 26565–26577 (2022) 23
2022
-
[49]
arXiv preprint arXiv:2501.08316 (2025) 23
Lin, S., Xia, X., Ren, Y., Yang, C., Xiao, X., Jiang, L.: Diffusion adversarial post- training for one-step video generation. arXiv preprint arXiv:2501.08316 (2025) 23
-
[50]
Advances in neural information processing systems35, 5775–5787 (2022) 23
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems35, 5775–5787 (2022) 23
2022
-
[51]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023) 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Zhang, Z., Li, Y., Wu, Y., Kag, A., Skorokhodov, I., Menapace, W., Siarohin, A., Cao, J., Metaxas, D., Tulyakov, S., et al.: Sf-v: Single forward video generation model. Advances in Neural Information Processing Systems37, 103599–103618 (2024) 23 AVSR-Diff: Supplementary Material In thisSupplementary Material, we provide additional details and results to ...
2024
-
[53]
The best and second-best results are highlighted inredand blue, respectively. Method 2× 2.5× LPIPS↓DISTS↓PSNR↑SSIM↑tLPIPS↓tOF↓LPIPS↓DISTS↓PSNR↑SSIM↑tLPIPS↓tOF↓ Arbitrary-scale Regression-based VSR VideoINR [9] 12.26 5.49 24.87 0.7346 9.22 64.4114.42 6.67 26.42 0.7940 7.21 52.91 MoTIF [7] 8.39 4.08 32.36 0.9269 9.23 42.4612.43 5.29 31.85 0.9110 8.11 23.61 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.