Evidence-Supported Credit Risk Report Generation Using News-Centric Financial Knowledge Graphs
Pith reviewed 2026-07-02 12:46 UTC · model grok-4.3
The pith
News-centric financial knowledge graphs improve credit risk report generation quality by 19-34 percent over baselines while reducing hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
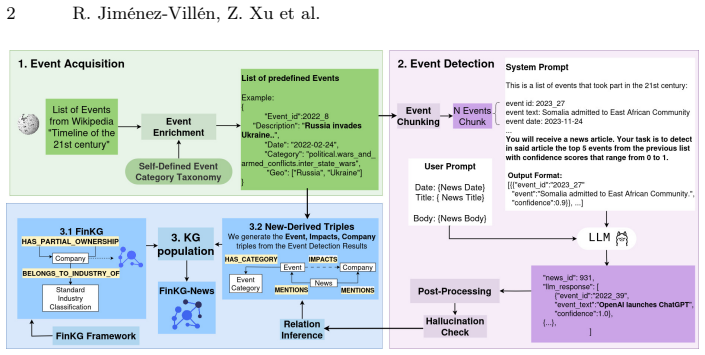
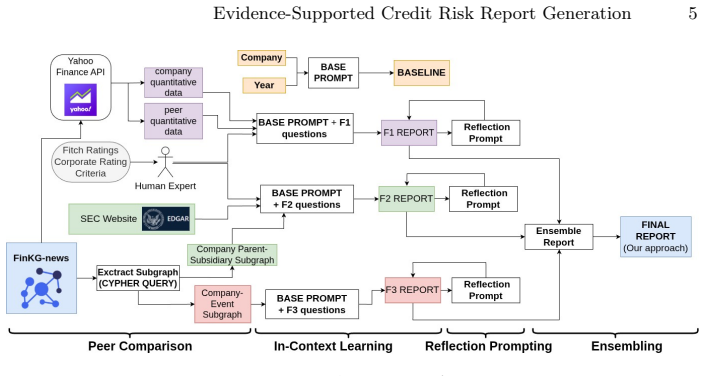
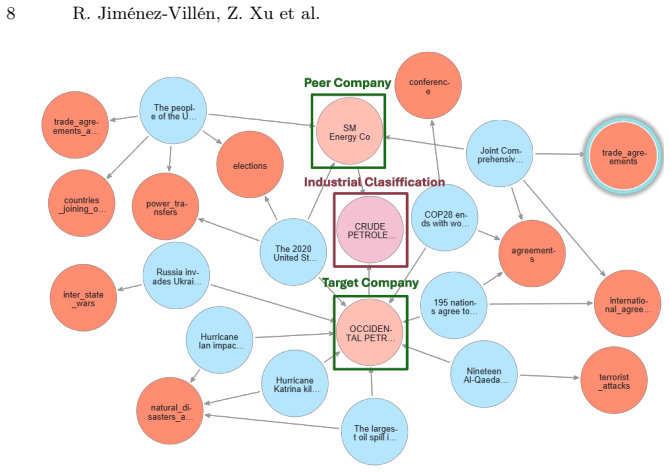
FinKG-News automatically constructs company-centric knowledge graphs by extracting news events as anchors linked to companies, and when these graphs are supplied as grounded evidence in an in-context learning architecture, the generated credit risk reports achieve higher quality across three financial dimensions and fewer hallucinations than baselines.
What carries the argument
FinKG-News, the framework that extracts news events as anchors and builds factual, company-centric, environment-aware knowledge graphs integrating events, news, and company data for use as evidence in report generation.
If this is right
- Reports better explain market dynamics because event-market relations are modeled explicitly rather than left implicit in text.
- Quality gains of 19 to 34 percent hold across the three core financial dimensions examined.
- Hallucination rates drop relative to baselines when the knowledge-graph evidence is supplied.
- Expert review cannot yet be replaced by automated hallucination detection because the latter remains unreliable.
Where Pith is reading between the lines
- The same event-anchored graph construction could be reused for adjacent tasks such as earnings-forecast generation or supply-chain risk assessment if the extraction pipeline is kept fixed.
- Performance may degrade on companies or events that receive little news coverage, since the graphs depend on reported events.
- Adding structured financial-statement data directly into the same graph structure might further constrain the generated reports without changing the in-context learning setup.
Load-bearing premise
The automatically extracted events and resulting knowledge graphs accurately capture the real drivers of credit risk without introducing errors that the in-context learning then propagates.
What would settle it
A controlled experiment in which the same set of credit risk reports is generated once with the FinKG-News evidence and once without it, followed by expert scoring of factual accuracy and quality that shows no consistent improvement when the graphs are included.
Figures


read the original abstract
Financial markets evolve in response to real-world events reported in news, yet these drivers often remain implicit in text. To better explain market dynamics, event-market relations must be explicitly modeled through factual, company-centric, and environment-aware knowledge graphs. We present FinKG-News, a framework that automatically constructs such graphs by extracting news events as anchors linked to companies. Using FinKG-News as grounded evidence that integrates events, news, and company data, we develop an in-context learning architecture for credit risk report generation across three core financial dimensions. Automatic and human evaluations show that automated hallucination detection and quality assessment remain unreliable, making expert judgment indispensable. Our approach consistently outperforms baselines, improving quality by 19%-34% while reducing hallucinations. The source code and project resources are publicly available at: https://github.com/ichise-laboratory/FINKG-news.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FinKG-News, a framework for automatically constructing company-centric financial knowledge graphs anchored on extracted news events. These graphs are then used as grounded evidence in an in-context learning architecture to generate credit risk reports across three core financial dimensions. The authors report that the approach outperforms baselines with 19-34% quality gains and reduced hallucinations, while explicitly noting that automatic hallucination detection and quality assessment remain unreliable and that expert judgment is indispensable. Code and resources are made publicly available.
Significance. If the evaluation gaps can be addressed, the work could contribute to grounded LLM applications in finance by linking news events to structured company data. The public code release supports reproducibility. However, the absence of validation for the core extraction step and the acknowledged unreliability of the reported metrics limit the immediate significance of the claimed improvements.
major comments (3)
- [Abstract] Abstract: The central claim of 19%-34% quality improvement and hallucination reduction is asserted without any description of the baselines, metrics (e.g., which quality scores), dataset size, number of reports evaluated, or evaluation protocol. This omission is load-bearing because the paper itself flags the unreliability of automatic assessment.
- [Abstract] Abstract: No precision, recall, F1, or human validation results are supplied for the automatic event extraction and KG construction that underpins FinKG-News. If extraction errors (missed events, incorrect links, or spurious relations) are present, they would be propagated by the in-context learning step rather than mitigated, directly weakening the 'grounded evidence' premise.
- [Abstract] Abstract: The manuscript states that 'automated hallucination detection and quality assessment remain unreliable' yet still reports hallucination reduction; the human evaluation protocol, annotator instructions, and agreement statistics are not described, leaving the evidence for the main result unsupported.
minor comments (1)
- [Abstract] The three core financial dimensions are referenced but not enumerated in the abstract; a short list would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the abstract and evaluation descriptions require expansion to better contextualize our claims, given the paper's own caveats on automatic metrics. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 19%-34% quality improvement and hallucination reduction is asserted without any description of the baselines, metrics (e.g., which quality scores), dataset size, number of reports evaluated, or evaluation protocol. This omission is load-bearing because the paper itself flags the unreliability of automatic assessment.
Authors: We agree that the abstract should include more context on the evaluation setup to support the reported improvements. In the revised manuscript, we will expand the abstract to briefly describe the baselines, specify that quality metrics and hallucination assessments are based on human evaluation, note the dataset size and number of reports evaluated, and outline the evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract: No precision, recall, F1, or human validation results are supplied for the automatic event extraction and KG construction that underpins FinKG-News. If extraction errors (missed events, incorrect links, or spurious relations) are present, they would be propagated by the in-context learning step rather than mitigated, directly weakening the 'grounded evidence' premise.
Authors: This comment correctly identifies a gap in the current manuscript, which does not report quantitative metrics or human validation for the extraction and KG construction steps. We will add a new subsection detailing human validation results for event and relation extraction accuracy on sampled data to address propagation concerns and strengthen the grounded evidence premise. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that 'automated hallucination detection and quality assessment remain unreliable' yet still reports hallucination reduction; the human evaluation protocol, annotator instructions, and agreement statistics are not described, leaving the evidence for the main result unsupported.
Authors: We agree that transparency on the human evaluation is essential, as the reported hallucination reductions and quality gains rely on human judgments rather than automatic methods. In the revision, we will add a detailed description of the human evaluation protocol, annotator instructions, number of annotators, and inter-annotator agreement statistics to fully support the main results. revision: yes
Circularity Check
No significant circularity; no derivations or self-referential fits present
full rationale
The paper describes a framework (FinKG-News) for automatic event extraction and KG construction from news, followed by in-context learning for credit risk reports. No equations, parameters, or derivations appear in the provided text. The central claims rest on external news data, public code, and empirical evaluations rather than any self-definitional mapping, fitted-input prediction, or load-bearing self-citation chain. Automatic assessment limitations are explicitly noted, but this does not create circularity in the derivation. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform effective in-context learning when supplied with structured knowledge graph evidence from news.
invented entities (1)
-
FinKG-News
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://en.wikipedia.org/wiki/Timeline_of_the_21st_century (2025)
Timeline of the 21st century — Wikipedia, the free encyclopedia. https://en.wikipedia.org/wiki/Timeline_of_the_21st_century (2025)
2025
-
[2]
In: Proceedings of the 6th ACM International Conference on AI in Finance
Arun, A., Dimino, F., Agarwal, T.P., Sarmah, B., Pasquali, S.: Finreflectkg: Agen- tic construction and evaluation of financial knowledge graphs. In: Proceedings of the 6th ACM International Conference on AI in Finance. p. 283–290. ICAIF ’25 (2025)
2025
-
[3]
Bachmann, M.: rapidfuzz/rapidfuzz: Release 3.13.0 (2025)
2025
-
[4]
The quarterly journal of economics131(4), 1593–1636 (2016)
Baker, S.R., Bloom, N., Davis, S.J.: Measuring economic policy uncertainty. The quarterly journal of economics131(4), 1593–1636 (2016)
2016
-
[5]
In: Der- noncourt, F., Preoţiuc-Pietro, D., Shimorina, A
Chen, Y., Wu, F., Wang, J., Qian, H., Liu, Z., Zhang, Z., Zhou, J., Wang, M.: Knowledge-augmented financial market analysis and report generation. In: Der- noncourt, F., Preoţiuc-Pietro, D., Shimorina, A. (eds.) Proceedings of the 2024 ConferenceonEmpiricalMethodsinNaturalLanguageProcessing:IndustryTrack. pp. 1207–1217 (2024) Evidence-Supported Credit Ris...
2024
-
[6]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Dong, Z., Fan, X., Peng, Z.: Fnspid: A comprehensive financial news dataset in time series. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. p. 4918–4927. KDD ’24 (2024)
2024
-
[7]
In: Proceedings of the 28th international conference on computational linguistics
Elhammadi, S., Lakshmanan, L.V., Ng, R., Simpson, M., Huai, B., Wang, Z., Wang, L.: A high precision pipeline for financial knowledge graph construction. In: Proceedings of the 28th international conference on computational linguistics. pp. 967–977 (2020)
2020
-
[8]
Report, Fitch Ratings (2025)
Fitch Ratings: Corporate rating criteria. Report, Fitch Ratings (2025)
2025
-
[9]
ACM Comput
Hogan, A., Blomqvist, E., Cochez, M., D’amato, C., Melo, G.D., Gutierrez, C., Kirrane, S., Gayo, J.E.L., Navigli, R., Neumaier, S., Ngomo, A.C.N., Polleres, A., Rashid, S.M., Rula, A., Schmelzeisen, L., Sequeda, J., Staab, S., Zimmermann, A.: Knowledge graphs. ACM Comput. Surv.54(4) (2021)
2021
-
[10]
In: 2023 IEEE 17th International Confer- ence on Semantic Computing (ICSC)
Kertkeidkachorn, N., Nararatwong, R., Xu, Z., Ichise, R.: Finkg: A core financial knowledge graph for financial analysis. In: 2023 IEEE 17th International Confer- ence on Semantic Computing (ICSC). pp. 90–93 (2023)
2023
-
[11]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[12]
In: Wang, M., Zitouni, I
Li, X., Chan, S., Zhu, X., Pei, Y., Ma, Z., Liu, X., Shah, S.: Are ChatGPT and GPT-4 general-purpose solvers for financial text analytics? a study on several typ- ical tasks. In: Wang, M., Zitouni, I. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 408–422 (2023)
2023
-
[13]
In: Proceedings of the 5th ACM International Conference on AI in Finance
Li, X.V., Sanna Passino, F.: Findkg: Dynamic knowledge graphs with large lan- guage models for detecting global trends in financial markets. In: Proceedings of the 5th ACM International Conference on AI in Finance. p. 573–581. ICAIF ’24 (2024)
2024
-
[14]
arXiv preprint arXiv:2406.15673 (2024)
Liu, D., Nassereldine, A., Yang, Z., Xu, C., Hu, Y., Li, J., Kumar, U., Lee, C., Qin, R., Shi, Y., et al.: Large language models have intrinsic self-correction ability. arXiv preprint arXiv:2406.15673 (2024)
-
[15]
Expert Systems with Applications252, 123999 (2024)
Liu, Z., Zhang, Z., Zeng, X.: Risk identification and management through knowl- edge association: A financial event evolution knowledge graph approach. Expert Systems with Applications252, 123999 (2024)
2024
-
[16]
In: Proceedings of the twenty-ninthinternationalconferenceoninternationaljointconferencesonartificial intelligence
Liu, Z., Huang, D., Huang, K., Li, Z., Zhao, J.: Finbert: A pre-trained financial language representation model for financial text mining. In: Proceedings of the twenty-ninthinternationalconferenceoninternationaljointconferencesonartificial intelligence. pp. 4513–4519 (2021)
2021
-
[17]
Scientific Reports14(1), 14156 (2024)
Maharjan, J., Garikipati, A., Singh, N.P., Cyrus, L., Sharma, M., Ciobanu, M., Barnes, G., Thapa, R., Mao, Q., Das, R.: Openmedlm: prompt engineering can out- perform fine-tuning in medical question-answering with open-source large language models. Scientific Reports14(1), 14156 (2024)
2024
-
[18]
Journal of Financial Economics123(1), 137–162 (2017)
Manela, A., Moreira, A.: News implied volatility and disaster concerns. Journal of Financial Economics123(1), 137–162 (2017)
2017
-
[19]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Schulhoff, S., Ilie, M., Balepur, N., Kahadze, K., Liu, A., Si, C., Li, Y., Gupta, A., Han, H., Schulhoff, S., et al.: The prompt report: a systematic survey of prompt engineering techniques. arXiv preprint arXiv:2406.06608 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
IEEE Transactions on Services Computing12(3), 356–369 (2019) 14 R
Song, D., Schilder, F., Hertz, S., Saltini, G., Smiley, C., Nivarthi, P., Hazai, O., Landau, D., Zaharkin, M., Zielund, T., Molina-Salgado, H., Brew, C., Bennett, D.: Building and querying an enterprise knowledge graph. IEEE Transactions on Services Computing12(3), 356–369 (2019) 14 R. Jiménez-Villén, Z. Xu et al
2019
-
[21]
Journal of King Saud University - Computer and Information Sciences 34(7), 4322–4334 (2022)
Tao, M., Gao, S., Mao, D., Huang, H.: Knowledge graph and deep learning com- bined with a stock price prediction network focusing on related stocks and muta- tion points. Journal of King Saud University - Computer and Information Sciences 34(7), 4322–4334 (2022)
2022
-
[22]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[23]
Procedia Computer Science199, 773–779 (2022)
Wen, S., Li, J., Zhu, X., Liu, M.: Analysis of financial fraud based on manager knowledge graph. Procedia Computer Science199, 773–779 (2022)
2022
-
[24]
BloombergGPT: A Large Language Model for Finance
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., Mann, G.: Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
International Journal of Semantic Computing pp
Xu, Z., Takamura, H., Ichise, R.: Fincakg: A framework to construct financial causality knowledge graph from text. International Journal of Semantic Computing pp. 1–20 (2025)
2025
-
[26]
FinLLM Symposium at IJCAI 2023 (2023)
Yang, H., Liu, X.Y., Wang, C.D.: Fingpt: Open-source financial large language models. FinLLM Symposium at IJCAI 2023 (2023)
2023
-
[27]
Şerban, O., Leidner, J., Helin, H., Horrell, G.: A unified link prediction architecture applied on a novel heterogeneous knowledge base. In: International Conference on Web Information Systems Engineering (WISE) (2021) A News Dataset Pre-Processing Details In this section, we provide a detailed description of the procedures carried out for cleaning and pr...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.