Decision-Aware Training for Sample-Based Generative Models
Pith reviewed 2026-07-02 15:18 UTC · model grok-4.3
The pith
Augmenting the energy score with a differentiable decision loss trains sample-based generative models to reduce downstream decision costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decision-aware training augments the energy score objective with a differentiable decision loss that directly penalizes the cost incurred by acting on the model's forecast; the combined loss remains a proper scoring rule, allowing sample-based generative models to produce forecasts that are both calibrated and decision-optimal.
What carries the argument
The differentiable decision loss, which measures expected cost of optimal actions taken under samples from the model and combines with the energy score while preserving proper scoring properties.
If this is right
- Training signal is reallocated toward forecast errors that carry high decision cost rather than uniform density matching.
- Full probabilistic forecasts are retained because the added term does not replace the energy score.
- Improvements concentrate in cost-sensitive regions of the forecast space.
- The method applies to any sample-based generative model whose original objective is the energy score.
Where Pith is reading between the lines
- The same decision-loss construction could be paired with other proper scoring rules if they admit differentiable decision terms.
- Domains with known asymmetric costs, such as inventory or medical triage, could adopt the method by substituting the appropriate cost function.
- Scaling behavior with decision-problem complexity remains open for empirical test on larger models.
Load-bearing premise
A decision loss reflecting the downstream cost structure can be expressed as a differentiable function of the generated samples.
What would settle it
A controlled experiment in which the decision-aware model produces strictly higher total decision costs than the standard energy-score model when both are evaluated on held-out data using the true cost function.
Figures

read the original abstract
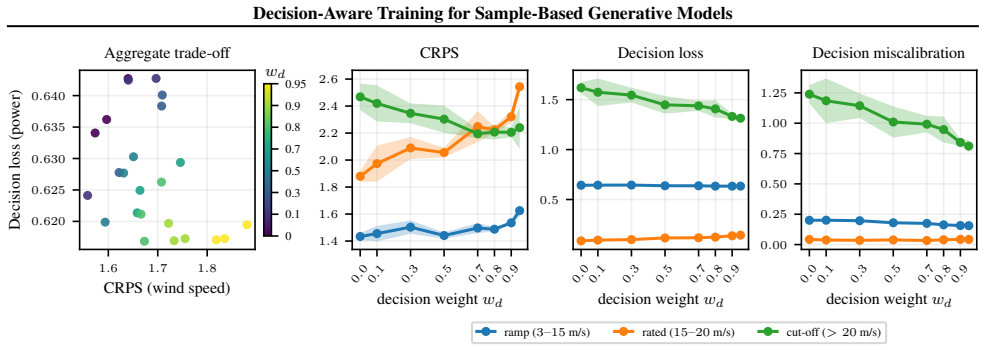
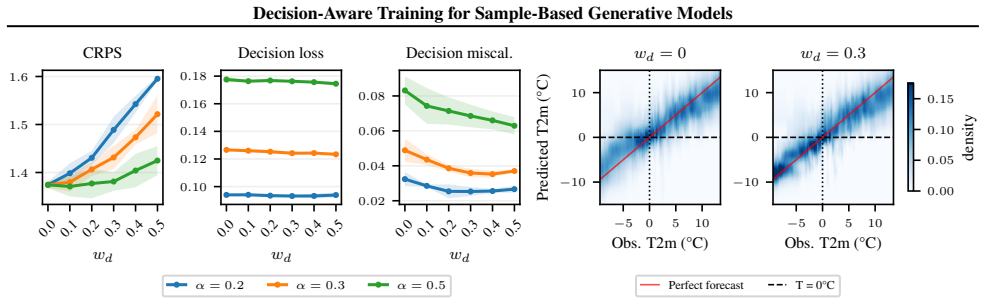
Sample-based generative models are increasingly used for probabilistic forecasting in high-stakes decision settings, yet their training objectives are blind to the decision maker's cost structure. These models are commonly trained with strictly proper scoring rules, such as the energy score, which allocate their training signal in proportion to data density, with no awareness of where forecast errors are most costly for downstream decisions. We therefore propose decision-aware training for sample-based generative models, augmenting the energy score objective with a differentiable decision loss that directly penalises the cost incurred by acting on the model's forecast. This combined loss is theoretically grounded, as the decision loss is itself a proper scoring rule. We validate our method on one synthetic and two real-world tasks, showing targeted improvements in cost-sensitive regions while retaining full probabilistic forecasts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes decision-aware training for sample-based generative models by augmenting the energy score objective with a differentiable decision loss that directly penalizes the cost of acting on the model's forecast. It claims the combined loss is theoretically grounded because the decision loss is itself a proper scoring rule, and reports targeted improvements on one synthetic and two real-world tasks while retaining full probabilistic forecasts.
Significance. If the differentiability construction and proper-scoring property can be established for general downstream costs, the approach would address a genuine limitation in applying generative models to high-stakes probabilistic forecasting by aligning training gradients with decision-relevant error regions.
major comments (3)
- [Abstract] Abstract, paragraph 3: the assertion that 'the decision loss is itself a proper scoring rule' is stated without derivation, reference, or explicit construction; because this property is invoked to ground the combined objective, its absence leaves the central theoretical claim unsupported.
- [Abstract] Abstract, paragraph 3: the claim that the decision loss is 'differentiable' with respect to generated samples is asserted without specifying the required smoothness assumptions on the downstream optimization (e.g., handling of argmax or integer programs); this assumption is load-bearing for end-to-end training and is not automatic for arbitrary cost structures.
- [Validation] Validation section (implied by 'one synthetic and two real-world tasks'): no error bars, statistical significance tests, or details on hyperparameter selection for the loss weighting are reported; without these, the claimed 'targeted improvements in cost-sensitive regions' cannot be assessed as robust.
minor comments (1)
- [Abstract] The abstract does not indicate whether the method preserves the strictly proper character of the energy score after augmentation or only claims propriety for the added term.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: the assertion that 'the decision loss is itself a proper scoring rule' is stated without derivation, reference, or explicit construction; because this property is invoked to ground the combined objective, its absence leaves the central theoretical claim unsupported.
Authors: We agree the abstract states the claim without supporting material. The manuscript body derives the proper scoring property of the decision loss; we will revise the abstract to reference the relevant theoretical section and add a concise justification of the property to better support the claim. revision: yes
-
Referee: [Abstract] Abstract, paragraph 3: the claim that the decision loss is 'differentiable' with respect to generated samples is asserted without specifying the required smoothness assumptions on the downstream optimization (e.g., handling of argmax or integer programs); this assumption is load-bearing for end-to-end training and is not automatic for arbitrary cost structures.
Authors: The referee correctly identifies that differentiability requires explicit assumptions. We will add a paragraph in the methods section specifying the smoothness conditions on the downstream problem and noting the use of differentiable relaxations (e.g., for argmax) where needed. revision: yes
-
Referee: [Validation] Validation section (implied by 'one synthetic and two real-world tasks'): no error bars, statistical significance tests, or details on hyperparameter selection for the loss weighting are reported; without these, the claimed 'targeted improvements in cost-sensitive regions' cannot be assessed as robust.
Authors: We agree that error bars, significance tests, and hyperparameter details are necessary for robustness assessment. We will revise the validation section to report these elements, including multiple-run statistics and the procedure used to select the loss weighting. revision: yes
Circularity Check
No load-bearing circularity; decision loss presented as external proper scoring rule property
full rationale
The paper augments the energy score with a differentiable decision loss and states that the combined loss is theoretically grounded because the decision loss is itself a proper scoring rule. This property is asserted as an independent fact rather than derived from or fitted to the same inputs within the paper. No equations or self-citations are shown that reduce the decision loss or the overall objective to a quantity defined by construction from the training data or prior fitted parameters. The central claim retains independent content from the energy score literature and the asserted properness of the added term.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting hyperparameter
axioms (1)
- domain assumption The decision loss is itself a proper scoring rule
Reference graph
Works this paper leans on
-
[1]
Bonev, B., Kurth, T., Mahesh, A., Bisson, M., Kossaifi, J., Kashinath, K., Anandkumar, A., Collins, W. D., Pritchard, M. S., and Keller, A. Fourcastnet 3: A geometric ap- proach to probabilistic machine-learning weather fore- casting at scale.arXiv preprint arXiv:2507.12144,
-
[2]
Ad- vanced strategies for wind power trading in short-term electricity markets
Bourry, F., Juban, J., Costa, L., and Kariniotakis, G. Ad- vanced strategies for wind power trading in short-term electricity markets. InEuropean Wind Energy Conference & Exhibition EWEC 2008, pp. 8–pages. EWEC,
2008
-
[3]
Couairon, G., Singh, R., Charantonis, A., Lessig, C., and Monteleoni, C. Archesweather & archesweathergen: a de- terministic and generative model for efficient ml weather forecasting.arXiv preprint arXiv:2412.12971,
-
[4]
S., Zhou, G., Murphy, K., Gretton, A., and Doucet, A
De Bortoli, V ., Galashov, A., Guntupatti, J. S., Zhou, G., Murphy, K., Gretton, A., and Doucet, A. Distributional diffusion models with scoring rules.arXiv preprint arXiv:2502.02483,
- [5]
-
[6]
Smooth calibration and decision making.arXiv preprint arXiv:2504.15582,
Hartline, J., Wu, Y ., and Yang, Y . Smooth calibration and decision making.arXiv preprint arXiv:2504.15582,
-
[7]
The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730): 1999–2049,
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Hor´anyi, A., Mu˜noz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., et al. The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730): 1999–2049,
1999
-
[8]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Improved probabilistic regression using diffusion models.arXiv preprint arXiv:2510.04583,
Kneissl, C., Bulte, C., Scholl, P., and Kutyniok, G. Improved probabilistic regression using diffusion models.arXiv preprint arXiv:2510.04583,
-
[10]
C., Roberts, C., Adewoyin, R., Bouall`egue, Z
Lang, S., Alexe, M., Clare, M. C., Roberts, C., Adewoyin, R., Bouall`egue, Z. B., Chantry, M., Dramsch, J., Dueben, P. D., Hahner, S., et al. Aifs-crps: ensemble forecast- ing using a model trained with a loss function based on the continuous ranked probability score.arXiv preprint arXiv:2412.15832,
-
[11]
Learning in Implicit Generative Models
Mohamed, S. and Lakshminarayanan, B. Learn- ing in implicit generative models.arXiv preprint arXiv:1610.03483,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2312.15796 , year=
Price, I., Sanchez-Gonzalez, A., Alet, F., Andersson, T. R., El-Kadi, A., Masters, D., Ewalds, T., Stott, J., Mohamed, S., Battaglia, P., et al. Gencast: Diffusion-based ensemble forecasting for medium-range weather.arXiv preprint arXiv:2312.15796,
-
[13]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[14]
with weightw d ≥0. A.3. Finite-Sample Analysis of the Training Objective A.4. Derivation of per-sample gradient (Eq. (7)) Problem setup.Define f(a;{ˆyj}M j=1) := 1 M PM j=1 c(a,ˆyj); we write f(a) for brevity, making the sample dependence explicit only where the argument requires it. The optimal action solves min a f(a)s.t.a≥a min, a≤a max.(11) Since the ...
2022
-
[15]
Applying this withx=a,θ={ˆy j}M j=1, andF(a;{ˆyj}M j=1) :=f ′(a;{ˆyj}M j=1), the IFT requires∂F/∂a̸= 0ata ∗: ∂F ∂a a∗ = 1 M MX j=1 ∂2c ∂a2 (a∗,ˆyj) =:H >0,(17) where H >0 follows from strict convexity of f at a∗; the IFT therefore guarantees that a∗ is locally a smooth function of {ˆyj}M j=1. In our setting, a∗ is already defined as a function of {ˆyj}; t...
2025
-
[16]
with learning rate 10−3 to train the models over 2000 epochs. Loss scales of CRPS and decision loss are estimated once before training and fixed throughout; optionally, a short CRPS pre-training phase precedes scale estimation to ensure realistic samples and cost values. We perform 200 epochs of CRPS pre-training for the wind power dispatch task, since we...
2000
-
[17]
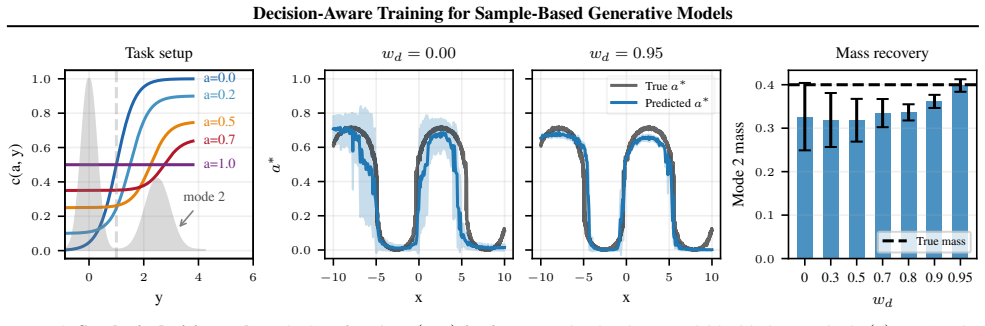
Some of the troughs (a∗ = 0, boundary case) that exist for wd = 0remain a blind spot throughout
fails to track the ground truth action at the transitions between the extremes; decision-aware training ( wd >0.0 ) improves the tracking of a∗ and gets closer to the ground truth for large wd. Some of the troughs (a∗ = 0, boundary case) that exist for wd = 0remain a blind spot throughout. 14 Decision-Aware Training for Sample-Based Generative Models −10 ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.