RepoRescue: An Empirical Study of LLM Agents on Whole-Repository Compatibility Rescue
Pith reviewed 2026-07-02 07:58 UTC · model grok-4.3
The pith
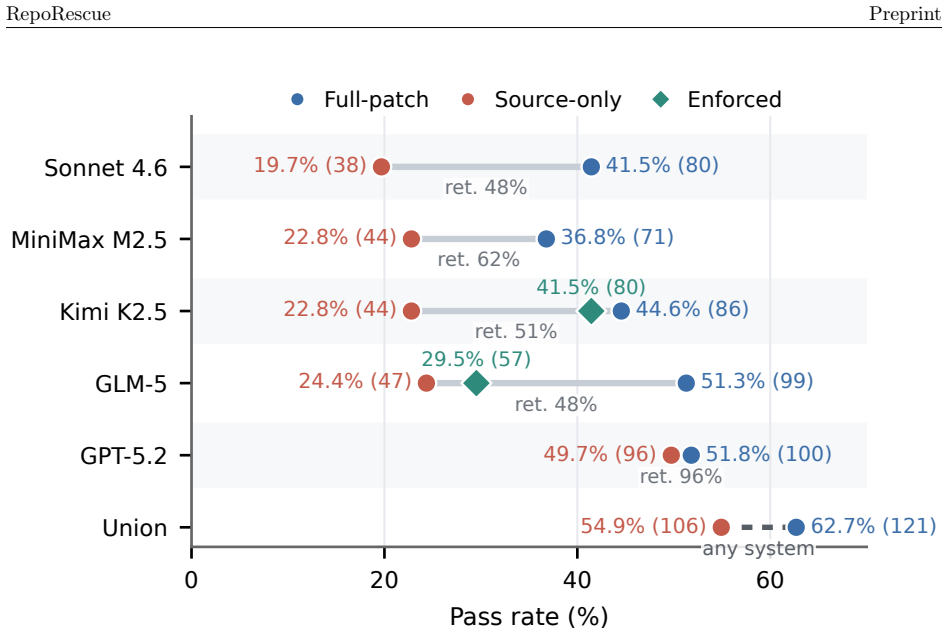
LLM agents can adapt old repositories to modern environments after ecosystem drift, rescuing up to 41.5 percent even when test edits are blocked at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
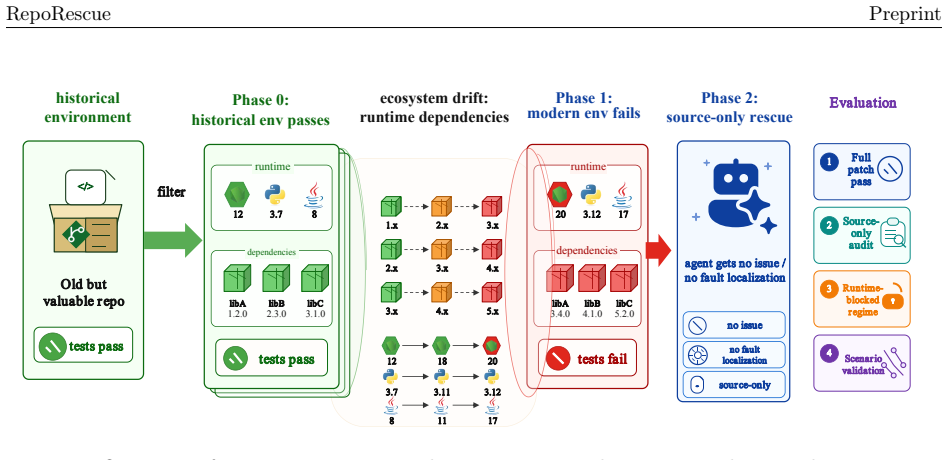
RepoRescue shows that LLM agents perform compatibility rescue on whole repositories, with Kimi achieving 41.5 percent success when runtime blocking prevents test-file edits. The union of evaluated systems reaches 62.7 percent, exceeding the best single system by 10.9 points. On 14 repositories that require coordinated whole-codebase changes, systems from GPT-5.2 through Codex succeed on all 14 while every Claude Code system succeeds on at most two. Among 34 unmaintained Python candidates whose suites pass after rescue, 22 function in realistic scenarios and 12 pass a bug-hunt check that confirms the patches address the compatibility failure.
What carries the argument
The RepoRescue benchmark and its evaluation regimes, which supply agents with only the repository and failing modern environment while enforcing source-only repair through runtime blocking and post-rescue practical validation.
If this is right
- Agent systems can be applied to maintain unmaintained open-source repositories by producing source changes that restore compatibility.
- Combining outputs from multiple distinct agent systems increases the fraction of repositories that can be rescued beyond any single system.
- Success concentrates on isolated fixes while coordinated changes across files remain a bottleneck for certain agent families.
- Runtime enforcement of source-only edits is required to ensure agents address root causes rather than altering test expectations.
Where Pith is reading between the lines
- Large-scale deployment of ensembles of these agents could reduce the maintenance burden on abandoned but still useful open-source projects.
- The observed difference in handling cross-file coordination suggests targeted improvements in agent architectures for multi-file reasoning.
- The gap between test-suite passage and real-world functionality after rescue points to the value of additional validation layers beyond automated tests.
Load-bearing premise
The 315 repositories were correctly verified to pass their test suites in historical environments and to fail after the modernization process, and that this modernization produces failures representative of real unmaintained repositories.
What would settle it
Evaluating the same agent systems on a new collection of repositories that have become genuinely unmaintained in the wild and finding success rates substantially lower than 41.5 percent under runtime blocking would indicate the reported rescue rates do not generalize.
Figures
read the original abstract
Open-source libraries and tools are widely reused, but compatibility maintenance is expensive. Once maintainers leave, useful repositories can stop working as runtimes and dependencies evolve. We study whether LLM agents can adapt old repositories to modern environments, a task we call compatibility rescue. Unlike bug repair, compatibility rescue starts from a repository that worked in its original environment but fails after ecosystem drift. RepoRescue gives agents only the repository and its failing modern environment; the agent must diagnose the failure, locate affected code, and produce a source-code rescue that restores the historical test suite. We build RepoRescue from 193 Python and 122 Java repositories, each verified to pass historically and fail after modernization. We evaluate five deployed agent systems on Python and three on Java. Beyond full-patch pass rate, we rerun patches after removing test-file edits to measure source-only repair, add a runtime-enforced regime that blocks test edits, and validate practical use for repositories whose suites pass after rescue. We find that Claude Code systems sometimes edit failing tests even when prompted not to; with runtime blocking, Kimi still rescues 41.5% of repositories. Systems are complementary: their union reaches 62.7%, exceeding the best single system by 10.9 points. Difficulty concentrates in cross-file coordination: on 14 repositories requiring coordinated whole-codebase changes, GPT-5.2 through Codex passes all 14, while every Claude Code system passes at most two. Finally, a passing suite is only an initial signal: among 34 unmaintained Python candidates whose suites pass after rescue, 22 work in realistic scenarios and 12 pass bug-hunt with patches that address the compatibility failure. RepoRescue benchmarks compatibility rescue with source-only auditing, runtime enforcement, practical validation, and reasoning labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RepoRescue, a benchmark and empirical study evaluating LLM agents on compatibility rescue for whole repositories that worked historically but fail after simulated ecosystem drift. It constructs a dataset of 315 repositories (193 Python, 122 Java), each verified to pass tests in their original environment and fail after modernization. Five agent systems are evaluated on Python and three on Java using metrics including full-patch pass rate, source-only repair (after removing test-file edits), runtime-enforced blocking of test edits, and practical validation on unmaintained candidates. Key results include Kimi rescuing 41.5% under runtime blocking, a union of systems reaching 62.7% (10.9 points above the best single system), strong performance differences on 14 repositories needing coordinated cross-file changes (GPT-5.2–Codex succeed on all 14; Claude systems on at most 2), and 22 of 34 rescued Python suites working in realistic scenarios.
Significance. If the benchmark construction holds, the work offers a rigorous empirical assessment of LLM agents on a realistic, multi-file maintenance task distinct from single-bug repair. Strengths include the use of runtime blocking to prevent test hacking, source-only auditing, explicit labeling of coordination difficulty, and follow-up practical validation beyond test-suite passage. The complementarity finding and concentration of failures in cross-file changes provide actionable guidance for agent design. The benchmark itself, with its historical-pass and modernization-failure construction, could serve as a reusable resource for the field.
major comments (2)
- [Benchmark construction (Methods/§3)] Benchmark construction (Methods/§3): The central empirical claims rest on the statement that all 315 repositories 'were verified to pass historically and fail after modernization.' No details are supplied on the historical environments, exact modernization procedure (dependency versions, runtime upgrades, etc.), pass/fail criteria, or any check that the induced failures are representative of real unmaintained repositories rather than artifacts of the procedure. This verification is load-bearing for the reported percentages (41.5%, 62.7%, 14/14 vs. ≤2/14) and must be described with concrete steps and examples.
- [Coordinated-change subset (Results/§5)] Coordinated-change subset (Results/§5): The claim that GPT-5.2 through Codex pass all 14 repositories requiring coordinated whole-codebase changes while every Claude Code system passes at most two is a key differentiator. The manuscript must specify how these 14 repositories were identified and labeled, the exact prompting and access conditions given to each system, and whether the classification was performed before or after seeing the agent outputs.
minor comments (3)
- [Abstract] Abstract: 'GPT-5.2 through Codex' is ambiguous; list the exact model/agent names evaluated for each language.
- [Throughout] All reported percentages should be accompanied by the denominator (e.g., '41.5% (n=193)') for immediate interpretability.
- [Practical validation (likely §6)] The practical-validation step (34 candidates, 22 realistic successes) would benefit from a brief description of the 'realistic scenarios' and 'bug-hunt' protocol used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Benchmark construction (Methods/§3)] Benchmark construction (Methods/§3): The central empirical claims rest on the statement that all 315 repositories 'were verified to pass historically and fail after modernization.' No details are supplied on the historical environments, exact modernization procedure (dependency versions, runtime upgrades, etc.), pass/fail criteria, or any check that the induced failures are representative of real unmaintained repositories rather than artifacts of the procedure. This verification is load-bearing for the reported percentages (41.5%, 62.7%, 14/14 vs. ≤2/14) and must be described with concrete steps and examples.
Authors: We agree that the current description in §3 is insufficient for reproducibility and for validating that the induced failures are representative. In the revised manuscript we will expand the Methods section with: (1) the precise historical environments (Python 3.6/3.7 and Java 8/11 with pinned dependency versions from the original commit), (2) the exact modernization steps (dependency version bumps to latest compatible releases plus runtime upgrades), (3) the pass/fail criteria (full test-suite exit code 0 with no warnings treated as failures), and (4) evidence of representativeness (comparison against a sample of real GitHub issues from unmaintained repositories). Concrete examples for both Python and Java will be added. revision: yes
-
Referee: [Coordinated-change subset (Results/§5)] Coordinated-change subset (Results/§5): The claim that GPT-5.2 through Codex pass all 14 repositories requiring coordinated whole-codebase changes while every Claude Code system passes at most two is a key differentiator. The manuscript must specify how these 14 repositories were identified and labeled, the exact prompting and access conditions given to each system, and whether the classification was performed before or after seeing the agent outputs.
Authors: We agree that the identification process for the 14-repository subset requires explicit documentation. In the revised §5 we will add: (1) the labeling criteria (repositories were flagged when the minimal rescue required coordinated edits to at least three interdependent source files, determined by manual inspection of the original failing state), (2) the exact prompting templates, model versions, temperature, and API access parameters used for each system, and (3) confirmation that the subset classification was performed on the benchmark before any agent runs were executed, thereby avoiding post-hoc selection bias. revision: yes
Circularity Check
No circularity: direct empirical counts on benchmark with no derivation or fitted predictions
full rationale
This paper performs an empirical study: it constructs a benchmark of 315 repositories, verifies historical pass/modern fail behavior, runs five agent systems, and reports measured success rates (e.g., 41.5% rescue under blocking, 62.7% union). No equations, first-principles derivations, parameter fitting, or predictions are claimed. The central numbers are direct counts from agent executions. The benchmark-construction verification is an experimental assumption whose soundness is external to any derivation chain; it does not reduce any result to itself by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the reported claims. The study is therefore self-contained against external benchmarks and receives score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Repositories were verified to pass historically and fail after modernization.
- domain assumption The historical test suite serves as a valid success metric for compatibility rescue.
Reference graph
Works this paper leans on
-
[1]
Why modern open source projects fail,
J. Coelho and M. T. Valente, “Why modern open source projects fail,” inProceedings of the 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE), 2017, pp. 186–196
2017
-
[2]
On the abandonment and survival of open source projects: An empirical investigation,
G. Avelino, E. Constantinou, M. T. Valente, and A. Serebrenik, “On the abandonment and survival of open source projects: An empirical investigation,” inProceedings of the ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2019
2019
-
[3]
pyupgrade: A tool to automatically upgrade syntax for newer versions of Python,
A. Sottile, “pyupgrade: A tool to automatically upgrade syntax for newer versions of Python,” https://github.com/asottile/pyupgrade, 2024
2024
-
[4]
OpenRewrite: Large-scale automated source code refactoring,
Moderne, Inc., “OpenRewrite: Large-scale automated source code refactoring,” https://docs. openrewrite.org/, 2024, accessed: 2025-12-01
2024
-
[5]
ModelContextProtocol: Specification,
ModelContextProtocol, “ModelContextProtocol: Specification,” https://modelcontextprotocol. io/specification/2025-11-25, 2025, accessed: 2026-06-17
2025
-
[6]
PyCG: Practical call graph generation in Python,
V. Salis, T. Sotiropoulos, P. Louridas, D. Spinellis, and D. Mitropoulos, “PyCG: Practical call graph generation in Python,” inProceedings of the IEEE/ACM 43rd International Conference on Software Engineering (ICSE), 2021, pp. 1646–1657
2021
-
[7]
FastMCP: The fast, Pythonic way to build MCP servers and clients,
PrefectHQ, “FastMCP: The fast, Pythonic way to build MCP servers and clients,” https: //github.com/PrefectHQ/fastmcp, 2024
2024
-
[8]
Stop Comparing LLM Agents Without Disclosing the Harness
Y. Zhang, J. Wang, Y. Ge, W. Xu, J. Hamm, and C. K. Reddy, “Stop comparing LLM agents without disclosing the harness,”arXiv preprint arXiv:2605.23950, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Claude Code: Overview,
Anthropic, “Claude Code: Overview,” https://docs.anthropic.com/en/docs/claude-code/ overview, 2026, accessed 2026-06-25
2026
-
[10]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Probable inference, the law of succession, and statistical inference,
E. B. Wilson, “Probable inference, the law of succession, and statistical inference,”Journal of the American Statistical Association, vol. 22, no. 158, pp. 209–212, 1927
1927
-
[12]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inProceedings of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[13]
On the use of agentic coding: An empirical study of pull requests on GitHub,
M. Watanabe, H. Li, Y. Kashiwa, B. Reid, H. Iida, and A. E. Hassan, “On the use of agentic coding: An empirical study of pull requests on GitHub,”arXiv preprint arXiv:2509.14745, 2025
-
[14]
Uncovering systematic failures of LLMs in verifying code against nat- ural language specifications,
H. Jin and H. Chen, “Uncovering systematic failures of LLMs in verifying code against nat- ural language specifications,” inProceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025. 17 RepoRescue Preprint
2025
-
[15]
Beyond Accuracy: Behavioral Dynamics of Agentic Multi-Hunk Repair
N. Nashid, D. Ding, K. Gallaba, A. E. Hassan, and A. Mesbah, “Beyond accuracy: Behavioral dynamics of agentic multi-hunk repair,”arXiv preprint arXiv:2511.11012, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Scalpel: The Python static analysis framework,
L. Li, J. Wang, and H. Quan, “Scalpel: The Python static analysis framework,” 2022, arXiv:2202.11840; presented at EuroPython 2022
-
[17]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE- agent: Agent-computer interfaces enable automated software engineering,”arXiv preprint arXiv:2405.15793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Agentless: Demystifying LLM-based Software Engineering Agents
C. S. Xia, Y. Deng, S. Dunn, and L. Zhang, “Agentless: Demystifying LLM-based software engineering agents,”arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
I. Bouzenia, P. Devanbu, and M. Pradel, “RepairAgent: An autonomous, LLM-based agent for program repair,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, arXiv:2403.17134
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
UniDebugger: Hierarchical multi-agent framework for unified software debugging,
C. Lee, C. S. Xia, L. Yang, J.-t. Huang, Z. Zhu, L. Zhang, and M. R. Lyu, “UniDebugger: Hierarchical multi-agent framework for unified software debugging,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025, pp. 18248–18277
2025
-
[21]
TSAPR: A tree search framework for automated program repair,
H. Hu, C. Shang, W. Sun, and H. Zhang, “TSAPR: A tree search framework for automated program repair,”arXiv preprint arXiv:2507.01827, 2025
-
[22]
CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin, “CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[23]
HAFixAgent: History-aware program repair agent,
Y. Shi, H. Li, B. Adams, and A. E. Hassan, “HAFixAgent: History-aware program repair agent,” arXiv preprint arXiv:2511.01047, 2025
-
[24]
DynaFix: Iterative Automated Program Repair Driven by Execution-Level Dynamic Information
Z. Huang, L. Xu, C. Liu, W. Sun, X. Zhang, Y. Lei, M. Yan, and H. Zhang, “DynaFix: Iterative automated program repair driven by execution-level dynamic information,”arXiv preprint arXiv:2512.24635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
RGFL: Reasoning guided fault localization for automated program repair using large language models,
M. Sepidband, H. Taherkhani, H. V. Pham, and H. Hemmati, “RGFL: Reasoning guided fault localization for automated program repair using large language models,”arXiv preprint arXiv:2601.18044, 2026
-
[26]
When large language models confront repository-level automatic program repair: How well they done?
Y. Chen, J. Wu, X. Ling, C. Li, Z. Rui, T. Luo, and Y. Wu, “When large language models confront repository-level automatic program repair: How well they done?” inProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 2024, arXiv:2403.00448
-
[27]
RepoRepair: Leveraging code docu- mentation for repository-level automated program repair,
Z. Pan, C. Li, W. Zhong, Y. Feng, B. Luo, and V. Ng, “RepoRepair: Leveraging code docu- mentation for repository-level automated program repair,”arXiv preprint arXiv:2603.01048, 2026
-
[28]
SGAgent: Suggestion-Guided LLM-Based Multi-Agent Framework for Repository-Level Software Repair
Q. Zhang, C. Gao, Y. Han, Y. Shang, C. Fang, Z. Chen, and L. Xiao, “SGAgent: Suggestion- guided LLM-based multi-agent framework for repository-level software repair,”arXiv preprint arXiv:2602.23647, 2026. 18 RepoRescue Preprint
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Enhancing repository-level software repair via repository-aware knowledge graphs,
B. Yang, J. Ren, S. Jin, Y. Liu, F. Liu, B. Le, and H. Tian, “Enhancing repository-level software repair via repository-aware knowledge graphs,”arXiv preprint arXiv:2503.21710, 2025
-
[30]
RepoAI: Automated code refactoring through multi-agent LLM orchestration and retrieval- augmented generation,
N. Chondamrongkul, M. P. P. Kyaw, S. M. Ko, P. P. Paing, M. K. T. Swe, and T. Hongthong, “RepoAI: Automated code refactoring through multi-agent LLM orchestration and retrieval- augmented generation,”Science of Computer Programming, vol. 253, p. 103477, 2026
2026
-
[31]
RepoAudit: An autonomous LLM-agent for repository-level code auditing,
J. Guo, C. Wang, X. Xu, Z. Su, and X. Zhang, “RepoAudit: An autonomous LLM-agent for repository-level code auditing,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[32]
Using Copilot agent mode to automate library migration: A quantitative assessment,
A. Almeida, L. Xavier, and M. T. Valente, “Using Copilot agent mode to automate library migration: A quantitative assessment,”arXiv preprint arXiv:2510.26699, 2025, accepted at AGENT 2026, co-located with ICSE
-
[33]
CODEMENV: Benchmarking large language models on code migration,
K. Cheng, X. Shen, Y. Yang, T. Wang, Y. Cao, M. A. Ali, H. Wang, L. Hu, and D. Wang, “CODEMENV: Benchmarking large language models on code migration,” inFindings of the Association for Computational Linguistics: ACL, 2025
2025
-
[34]
GitChameleon 2.0: Evaluating AI code generation against Python library version incompatibilities,
D. Misra, N. Islah, V. May, B. Rauby, Z. Wang, J. Gehring, A. Orvieto, M. Chaudhary, E. B. Muller, I. Rish, S. E. Kahou, and M. Caccia, “GitChameleon 2.0: Evaluating AI code generation against Python library version incompatibilities,”arXiv preprint arXiv:2507.12367, 2025
-
[35]
PCART: Automated repair of python API parameter compatibility issues,
S. Zhang, G. Xiao, J. Wang, H. Lei, G. He, Y. Liu, and Z. Zheng, “PCART: Automated repair of python API parameter compatibility issues,”arXiv preprint arXiv:2406.03839, 2024
-
[36]
MigrateLib: A tool for end-to-end python library migration,
M. Islam, A. K. Jha, M. Mahmoud, and S. Nadi, “MigrateLib: A tool for end-to-end python library migration,”arXiv preprint arXiv:2510.08810, 2025
-
[37]
PyMigBench: A benchmark for python library migration,
M. Islam, A. K. Jha, S. Nadi, and I. Akhmetov, “PyMigBench: A benchmark for python library migration,” inProceedings of the 20th IEEE/ACM International Conference on Mining Software Repositories (MSR), 2023, pp. 511–515
2023
-
[38]
FreshBrew: A benchmark for evaluating AI agents on Java code migration,
V. May, D. Misra, Y. Luo, A. Sridhar, J. Gehring, and S. S. Ribeiro Junior, “FreshBrew: A benchmark for evaluating AI agents on Java code migration,”arXiv preprint arXiv:2510.04852, 2025
-
[39]
You name it, I run it: An LLM agent to execute tests of arbitrary projects,
I. Bouzenia and M. Pradel, “You name it, I run it: An LLM agent to execute tests of arbitrary projects,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 1054–1076, 2025, arXiv:2412.10133
-
[40]
Ecosystem-level determinants of sustained activity in open-source projects: A case study of the PyPI ecosystem,
M. Valiev, B. Vasilescu, and J. Herbsleb, “Ecosystem-level determinants of sustained activity in open-source projects: A case study of the PyPI ecosystem,” inProceedings of the 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2018, pp. 644–655
2018
-
[41]
Measuring dependency freshness in software systems,
J. Cox, E. Bouwers, M. C. J. D. van Eekelen, and J. Visser, “Measuring dependency freshness in software systems,” inProceedings of the 37th International Conference on Software Engineering (ICSE), 2015, pp. 109–118. 19 RepoRescue Preprint
2015
-
[42]
On the evolution of technical lag in the npm package dependency network,
A. Decan, T. Mens, and E. Constantinou, “On the evolution of technical lag in the npm package dependency network,” inProceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2018, pp. 404–414
2018
-
[43]
Do developers update their library dependencies?
R. G. Kula, D. M. German, A. Ouni, T. Ishio, and K. Inoue, “Do developers update their library dependencies?” inEmpirical Software Engineering, vol. 23, 2018, pp. 384–417
2018
-
[44]
An empirical comparison of dependency network evolution in seven software packaging ecosystems,
A. Decan, T. Mens, and P. Grosjean, “An empirical comparison of dependency network evolution in seven software packaging ecosystems,” inEmpirical Software Engineering, vol. 24, 2019, pp. 381–416
2019
-
[45]
Demystifying the vulnerability propagation and its evolution via dependency trees in the NPM ecosystem,
C. Liu, S. Chen, L. Fan, B. Chen, Y. Liu, and X. Peng, “Demystifying the vulnerability propagation and its evolution via dependency trees in the NPM ecosystem,” inProceedings of the ACM/IEEE International Conference on Software Engineering (ICSE), 2022, pp. 672–684
2022
-
[46]
Fixing dependency errors for Python build reproducibility,
S. Mukherjee, A. Almanza, and C. Rubio-González, “Fixing dependency errors for Python build reproducibility,” inProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2021, pp. 439–451
2021
-
[47]
The last dependency crusade: Solving Python de- pendency conflicts with LLMs,
A. Bartlett, C. C. S. Liem, and A. Panichella, “The last dependency crusade: Solving Python de- pendency conflicts with LLMs,” inProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering Workshops (ASEW), 2025, pp. 169–178, arXiv:2501.16191
-
[48]
B. P. Vangala, A. Adibifar, A. Gehani, and T. Malik, “AI-generated code is not reproducible (yet): An empirical study of dependency gaps in LLM-based coding agents,”arXiv preprint arXiv:2512.22387, 2025
-
[49]
An empirical study of bugs in modern LLM agent frameworks,
X. Zhuet al., “An empirical study of bugs in modern LLM agent frameworks,”arXiv preprint arXiv:2602.21806, 2026
-
[50]
Guidelines for conducting and reporting case study research in software engineering,
P. Runeson and M. Höst, “Guidelines for conducting and reporting case study research in software engineering,”Empirical Software Engineering, vol. 14, pp. 131–164, 2009
2009
-
[51]
Preliminary guidelines for empirical research in software engineering,
B. A. Kitchenham, S. L. Pfleeger, L. M. Pickard, P. W. Jones, D. C. Hoaglin, K. El Emam, and J. Rosenberg, “Preliminary guidelines for empirical research in software engineering,” inIEEE Transactions on Software Engineering, vol. 28, no. 8, 2002, pp. 721–734
2002
-
[52]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and Psychological Measurement, vol. 20, no. 1, pp. 37–46, 1960
1960
-
[53]
Longitudinal data analysis using generalized linear models,
K.-Y. Liang and S. L. Zeger, “Longitudinal data analysis using generalized linear models,” Biometrika, vol. 73, no. 1, pp. 13–22, 1986. 20
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.