Auto-FL-Research: Agentic Search for Federated Learning Algorithms
Pith reviewed 2026-07-03 20:31 UTC · model grok-4.3
The pith
A constrained coding-agent workflow searches for federated learning algorithmic recipes and separates recipe changes from scalar tuning and seed variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
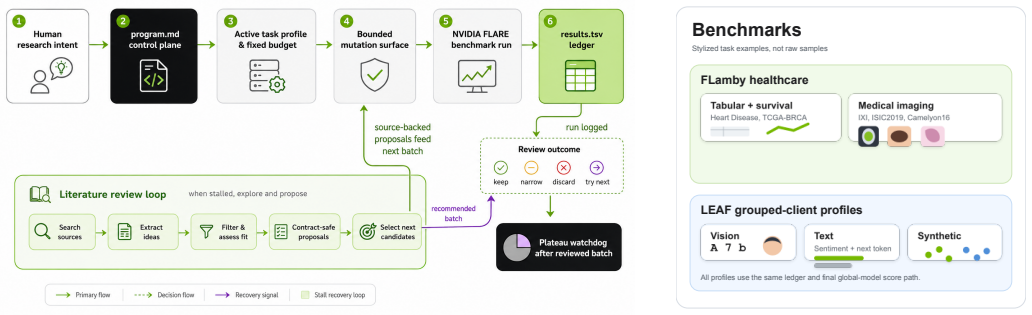
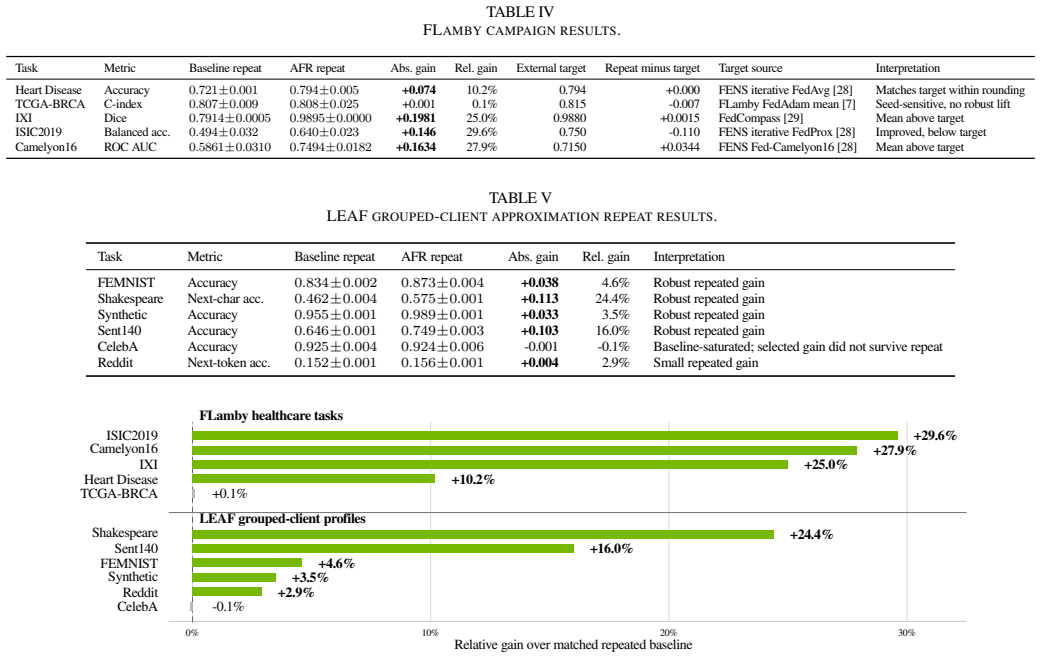
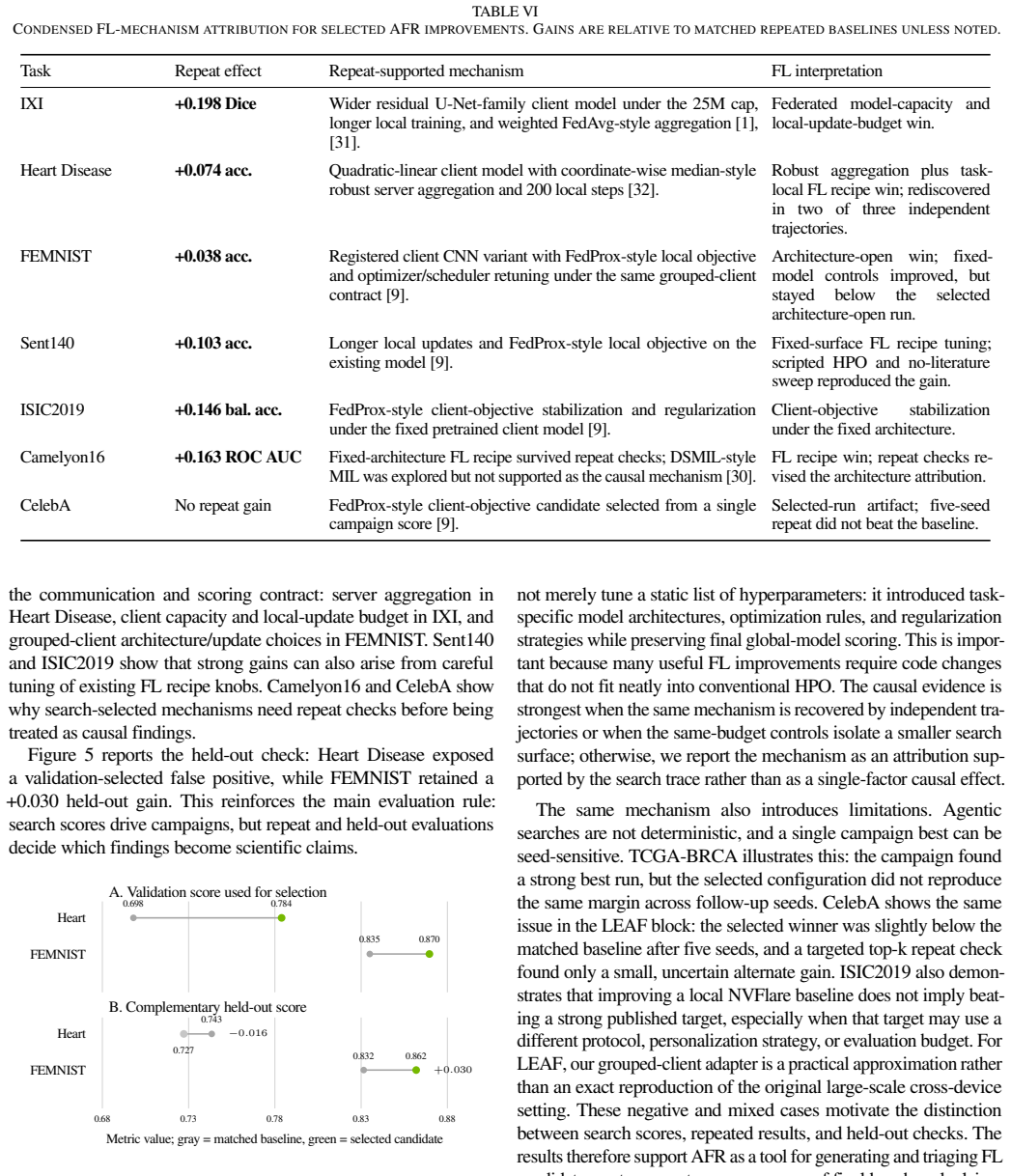
Auto-FL-Research deploys coding agents to generate and code candidate federated learning training algorithms inside profiles that fix the mutation surface, compute budget, communication contract, and model evaluation. Five-seed repeat testing supports gains on four FLamby tasks and five of six LEAF profiles. Same-budget baselines demonstrate that several gains arise from alterations to the federated learning recipe itself, whereas others are recovered by scalar controls on the original recipe or fail to replicate under repeated or held-out evaluation. These outcomes allow separation of repeated algorithmic mechanisms from tuning effects and selected artifacts.
What carries the argument
The constrained coding-agent workflow that proposes and edits code for server aggregation, client schedules, local objectives, and model variants while task profiles fix mutation surface, compute budget, communication contract, and final model evaluation.
If this is right
- Gains are recorded on four FLamby tasks and five of six LEAF profiles after five-seed repeat evaluations.
- Several gains correspond to changes in the federated learning recipe rather than scalar adjustments within a fixed recipe.
- Seed-sensitive candidates and search-selected failure cases appear during evaluation.
- Agent-generated candidates can be grouped into repeated mechanisms, fixed-surface tuning effects, and single-run artifacts.
Where Pith is reading between the lines
- The same workflow could be applied to other machine learning settings where many small algorithmic choices interact with training dynamics.
- Tighter integration of scalar control baselines inside the agent loop might further automate the separation of recipe novelty from tuning.
- Extending profiles to vary communication constraints could expose additional classes of non-robust agent proposals.
Load-bearing premise
Task profiles can be set so that they fix the mutation surface, compute budget, communication contract, and evaluation protocol in a way that cleanly isolates algorithmic recipe changes from scalar tuning effects and seed variance.
What would settle it
An experiment in which scalar hyperparameter search on the original fixed recipes matches or exceeds every agent-proposed gain across the same tasks and five-seed repeats, or in which no gains survive on a fresh set of held-out tasks.
Figures

read the original abstract
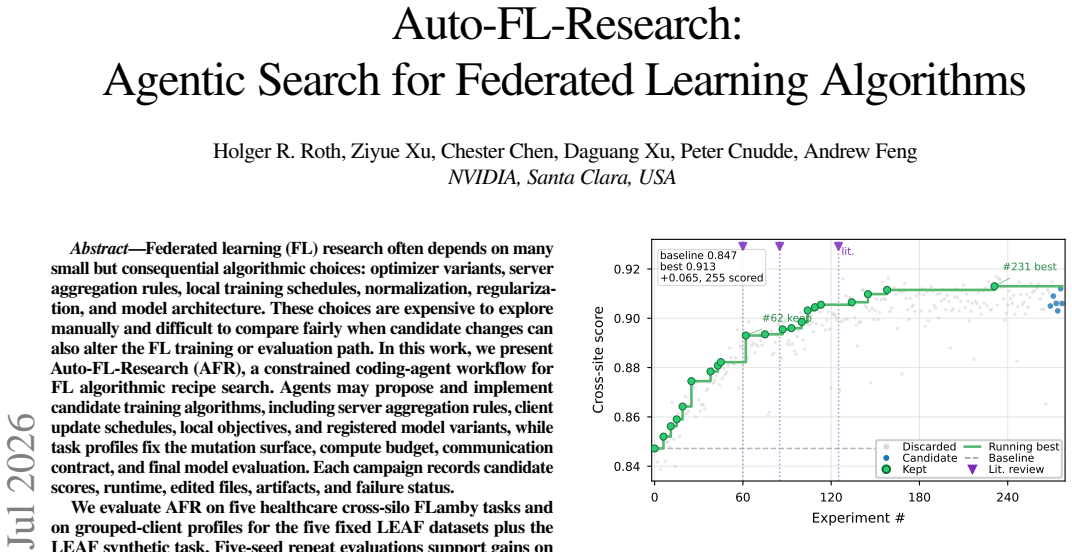
Federated learning (FL) research often depends on many small but consequential algorithmic choices: optimizer variants, server aggregation rules, local training schedules, normalization, regularization, and model architecture. These choices are expensive to explore manually and difficult to compare fairly when candidate changes can also alter the FL training or evaluation path. In this work, we present Auto-FL-Research (AFR), a constrained coding-agent workflow for FL algorithmic recipe search. Agents may propose and implement candidate training algorithms, including server aggregation rules, client update schedules, local objectives, and registered model variants, while task profiles fix the mutation surface, compute budget, communication contract, and final model evaluation. Each campaign records candidate scores, runtime, edited files, artifacts, and failure status. We evaluate AFR on five healthcare cross-silo FLamby tasks and on grouped-client profiles for the five fixed LEAF datasets plus the LEAF synthetic task. Five-seed repeat evaluations support gains on four FLamby tasks and five of six LEAF profiles, while also exposing seed-sensitive and search-selected failure cases. Same-budget controls show that several gains correspond to FL-recipe changes, whereas other improvements are recovered by fixed-surface scalar controls or fail under repeat or held-out evaluation. These mixed outcomes are part of the contribution: they show how agent-generated candidates can be separated into repeated FL mechanisms, fixed-surface tuning effects, and selected single-run artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Auto-FL-Research (AFR), a constrained coding-agent workflow for searching federated learning algorithmic recipes (server aggregation, client schedules, local objectives, model variants). Task profiles are asserted to fix the mutation surface, compute budget, communication contract, and evaluation; agents propose and implement candidates, with campaigns logging scores, runtimes, edits, and failures. Five-seed repeat evaluations on five FLamby healthcare tasks and six LEAF profiles (five fixed datasets plus synthetic) report gains on four FLamby tasks and five LEAF profiles, while same-budget scalar controls and held-out checks separate recipe-driven gains from tuning effects or single-run artifacts; mixed outcomes (seed sensitivity, search-selected failures) are presented as part of the contribution.
Significance. If the claimed separation between FL-recipe changes and scalar tuning holds under the stated controls, the work supplies a reproducible agentic search method plus transparent negative results that could reduce manual trial-and-error in FL algorithm design. The explicit reporting of seed-sensitive and control-recovered cases is a strength that supports falsifiability.
major comments (2)
- [Abstract] Abstract (evaluation protocol): the central attribution of gains to 'FL-recipe changes' rather than scalar tuning or seed variance rests on the claim that task profiles strictly fix the mutation surface, communication contract, and evaluation path. No mechanism, constraint list, or worked example is supplied showing how the surface is enforced or how the same-budget scalar baseline is constructed to match the agent's search space exactly; without this, the separation cannot be verified and the reported gains remain vulnerable to post-hoc selection.
- [Abstract] Abstract (five-seed repeats and controls): while five-seed repeats and same-budget controls are described, the abstract notes that 'several gains correspond to FL-recipe changes, whereas other improvements are recovered by fixed-surface scalar controls or fail under repeat.' This mixed outcome is load-bearing for the claim that AFR isolates algorithmic novelty; the manuscript must quantify how many of the reported gains survive both the scalar control and the held-out evaluation, with per-task breakdowns.
minor comments (2)
- [Abstract] The abstract refers to 'grouped-client profiles for the five fixed LEAF datasets plus the LEAF synthetic task' without defining the grouping criteria or how they differ from standard LEAF partitions.
- [Abstract] Terminology: 'fixed-surface scalar controls' and 'mutation surface' are used without an explicit definition or reference to the section that operationalizes them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing verifiability of the evaluation protocol and explicit quantification of results. We address each major comment below and note the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation protocol): the central attribution of gains to 'FL-recipe changes' rather than scalar tuning or seed variance rests on the claim that task profiles strictly fix the mutation surface, communication contract, and evaluation path. No mechanism, constraint list, or worked example is supplied showing how the surface is enforced or how the same-budget scalar baseline is constructed to match the agent's search space exactly; without this, the separation cannot be verified and the reported gains remain vulnerable to post-hoc selection.
Authors: We agree that the abstract does not supply these details. The manuscript body defines task profiles with explicit constraint lists (fixed vs. mutable components) and describes same-budget scalar baselines as restricting mutations to scalar hyperparameters only. To make the separation immediately verifiable from the abstract alone, we will add a short description of the enforcement mechanism together with a worked example of baseline construction. revision: partial
-
Referee: [Abstract] Abstract (five-seed repeats and controls): while five-seed repeats and same-budget controls are described, the abstract notes that 'several gains correspond to FL-recipe changes, whereas other improvements are recovered by fixed-surface scalar controls or fail under repeat.' This mixed outcome is load-bearing for the claim that AFR isolates algorithmic novelty; the manuscript must quantify how many of the reported gains survive both the scalar control and the held-out evaluation, with per-task breakdowns.
Authors: The referee correctly notes that the abstract uses the term 'several' without counts or per-task detail. The results section and supplements already contain the per-task data on which gains survive the scalar controls and held-out checks. We will revise the abstract to state the exact counts and include a concise per-task breakdown of surviving gains. revision: yes
Circularity Check
No significant circularity; evaluation uses external benchmarks and explicit controls
full rationale
The paper describes an empirical agent-based search workflow evaluated on FLamby and LEAF benchmarks. It reports five-seed repeats and same-budget scalar controls to separate recipe changes from tuning effects. No equations, fitted parameters, or self-citations are presented as load-bearing derivations that reduce the reported gains to quantities defined inside the search itself. The central claims rest on external task profiles and held-out evaluations rather than self-referential constructions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Ag¨uera y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inAISTATS, vol. 54. PMLR, 2017, pp. 1273–1282
2017
-
[2]
Advances and open problems in federated learning,
P . Kairouz and H. B. McMahan, “Advances and open problems in federated learning,”F oundations and trends in machine learning, vol. 14, no. 1-2, pp. 1–210, 2021
2021
-
[3]
Auto- fedavg: Learnable federated averaging for multi-institutional medical image segmentation,
Y . Xia, D. Y ang, W. Li, A. Myronenko, D. Xu, H. Obinataet al., “Auto- fedavg: Learnable federated averaging for multi-institutional medical image segmentation,” arXiv:2104.10195, 2021
-
[4]
From federated learning to federated neural architecture search: A survey,
H. Zhu, H. Zhang, and Y . Jin, “From federated learning to federated neural architecture search: A survey,”Complex and Intelligent Systems, vol. 7, pp. 639–657, 2021
2021
-
[5]
Auto-fedrl: Federated hyperparameter optimization for multi-institutional medical image segmentation,
P . Guo, D. Y ang, A. Hatamizadeh, A. Xu, Z. Xu, W. Liet al., “Auto-fedrl: Federated hyperparameter optimization for multi-institutional medical image segmentation,” ECCV , 2022
2022
-
[6]
Adaptive federated optimization,
S. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Kone ˇcn´yet al., “Adaptive federated optimization,” inICLR, 2021
2021
-
[7]
FLamby: Datasets and benchmarks for cross-silo federated learning in realistic healthcare settings,
J. O. du Terrail, S.-S. Ayed, E. Cyffers, F. Grimberg, C. He, R. Loebet al., “FLamby: Datasets and benchmarks for cross-silo federated learning in realistic healthcare settings,” inNeurIPS, vol. 35, 2022
2022
-
[8]
LEAF: A benchmark for federated settings,
S. Caldas, S. M. K. Duddu, P . Wu, T. Li, J. Koneˇcn´y, H. B. McMahanet al., “LEAF: A benchmark for federated settings,” inW orkshop on F ederated Learning for Data Privacy and Confidentiality, 2019
2019
-
[9]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProc., MLSys, vol. 2, 2020, pp. 429–450
2020
-
[10]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P . Karimireddy, S. Kale, M. Mohri, S. Reddi, S. U. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProc., 37th ICML, vol. 119. PMLR, 2020, pp. 5132–5143
2020
-
[11]
Hutter, L
F. Hutter, L. Kotthoff, and J. V anschoren, Eds.,Automated Machine Learning: Methods, Systems, Challenges. Springer, 2019
2019
-
[12]
Neural architecture search: A survey,
T. Elsken, J. H. Metzen, and F. Hutter, “Neural architecture search: A survey,” JMLR, vol. 20, no. 55, pp. 1–21, 2019
2019
-
[13]
Automl: A survey of the state-of-the-art,
X. He, K. Zhao, and X. Chu, “Automl: A survey of the state-of-the-art,” Knowledge-Based Systems, vol. 212, p. 106622, 2021
2021
-
[14]
AutoFL: Towards AutoML in a federated learning context,
D. Preuveneers, “AutoFL: Towards AutoML in a federated learning context,” Applied Sciences, vol. 13, no. 14, p. 8019, 2023
2023
-
[15]
AutoFL: Enabling heterogeneity-aware energy efficient federated learning,
Y . G. Kim and C.-J. Wu, “AutoFL: Enabling heterogeneity-aware energy efficient federated learning,” inProceedings of the 54th Annual IEEE/ACM International Symposium on Microarchitecture, 2021, pp. 183–198
2021
-
[16]
AutoFL: A bayesian game approach for autonomous client participation in federated edge learning,
M. Hu, W. Y ang, Z. Luo, X. Liu, Y . Zhou, X. Chenet al., “AutoFL: A bayesian game approach for autonomous client participation in federated edge learning,” IEEE Transactions on Mobile Computing, vol. 23, no. 1, pp. 194–208, 2024
2024
-
[17]
Automated federated learning in mobile-edge networks: Fast adaptation and convergence,
C. Y ou, K. Guo, G. Feng, P . Y ang, and T. Q. S. Quek, “Automated federated learning in mobile-edge networks: Fast adaptation and convergence,”IEEE Internet of Things Journal, vol. 10, no. 15, pp. 13 571–13 586, 2023
2023
-
[18]
Hyper-parameter optimization for federated learning with step-wise adaptive mechanism,
Y . Saadati and M. H. Amini, “Hyper-parameter optimization for federated learning with step-wise adaptive mechanism,” arXiv:2411.12244, 2024
-
[19]
C. He, M. Annavaram, and S. Avestimehr, “Towards non-I.I.D. and invisible data with FedNAS: Federated deep learning via neural architecture search,” arXiv:2004.08546, 2020
-
[20]
LEAF: A benchmark for federated settings project page,
LEAF Project, “LEAF: A benchmark for federated settings project page,” https://leaf.cmu.edu/, 2026, accessed 2026-06-03
2026
-
[21]
NVIDIA FLARE: Federated learning from simulation to real-world,
H. R. Roth, Y . Cheng, Y . Wen, I. Y ang, Z. Xu, Y .-T. Hsiehet al., “NVIDIA FLARE: Federated learning from simulation to real-world,”arXiv:2210.13291, 2022
-
[22]
EAIRA: Establishing a methodology for evaluating ai models as scientific research assistants,
F. Cappello, S. Madireddy, R. Underwood, N. L.-P . Chiaet al., “EAIRA: Establishing a methodology for evaluating ai models as scientific research assistants,” arXiv:2502.20309, 2025
-
[23]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha, “The AI scientist: Towards fully automated open-ended scientific discovery,” arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Y . Y amada, R. T. Lange, C. Lu, S. Hu, C. Lu, J. Foersteret al., “The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search,” arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Agent Laboratory: Using LLM Agents as Research Assistants
S. Schmidgall, Y . Su, Z. Wang, X. Sun, J. Wu, X. Y uet al., “Agent laboratory: Using LLM agents as research assistants,” arXiv:2501.04227, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
autoresearch: Ai agents running research on single-gpu nanochat training automatically,
A. Karpathy, “autoresearch: Ai agents running research on single-gpu nanochat training automatically,” https://github.com/karpathy/autoresearch, 2026, software repository; accessed 2026-06-08
2026
-
[27]
Camyla: Scaling Autonomous Research in Medical Image Segmentation
Y . Gao, H. Li, F. Y uan, X. Gao, W . Huang, and X. Wang, “Camyla: Scaling au- tonomous research in medical image segmentation,” arXiv:2604.10696, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Revisiting ensembling in one-shot federated learning,
Y . Allouah, A. Dhasade, R. Guerraoui, N. Gupta, A.-M. Kermarrec, R. Pinot et al., “Revisiting ensembling in one-shot federated learning,” inNeurIPS, vol. 37, 2024
2024
-
[29]
FedCompass: Efficient cross-silo federated learning on heterogeneous client devices using a computing power-aware scheduler,
Z. Li, P . Chaturvedi, S. He, H. Chen, G. Singh, V . Kindratenkoet al., “FedCompass: Efficient cross-silo federated learning on heterogeneous client devices using a computing power-aware scheduler,” inICLR, 2024
2024
-
[30]
Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning,
B. Li, Y . Li, and K. W. Eliceiri, “Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning,” inCVPR, 2021, pp. 14 318–14 328
2021
-
[31]
3D U-Net: Learning dense volumetric segmentation from sparse annotation,
O. Cicek, A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger, “3D U-Net: Learning dense volumetric segmentation from sparse annotation,” in MICCAI. Springer, 2016, pp. 424–432
2016
-
[32]
Byzantine-robust distributed learn- ing: Towards optimal statistical rates,
D. Yin, Y . Chen, R. Kannan, and P . Bartlett, “Byzantine-robust distributed learn- ing: Towards optimal statistical rates,” inProceedings of the 35th International Conference on Machine Learning, vol. 80. PMLR, 2018, pp. 5650–5659
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.