Agent4cs: A Multi-agent System for Code Summarization in Large Hierarchical Codebases
Pith reviewed 2026-07-03 20:26 UTC · model grok-4.3
The pith
A three-agent system summarizes large codebases bottom-up and raises semantic consistency 8 percent on average while lifting keyword coverage up to 38 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
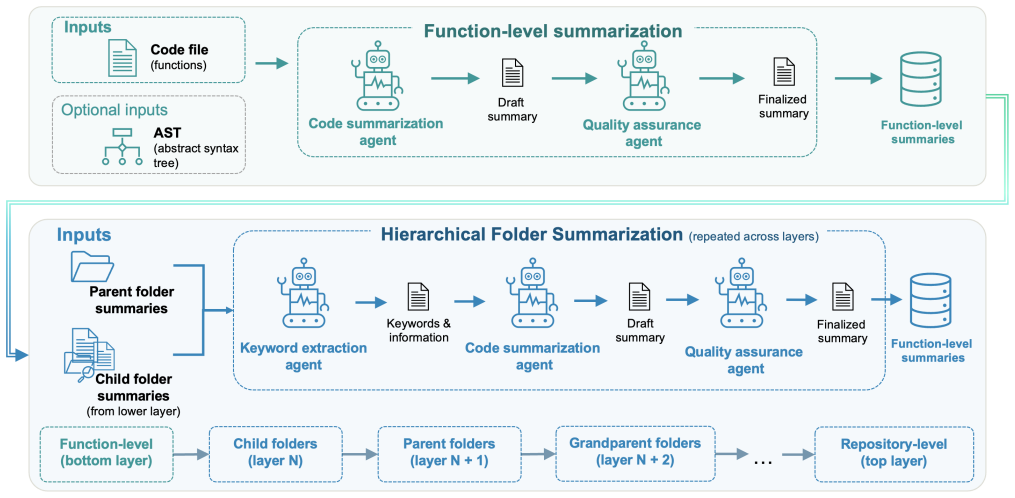
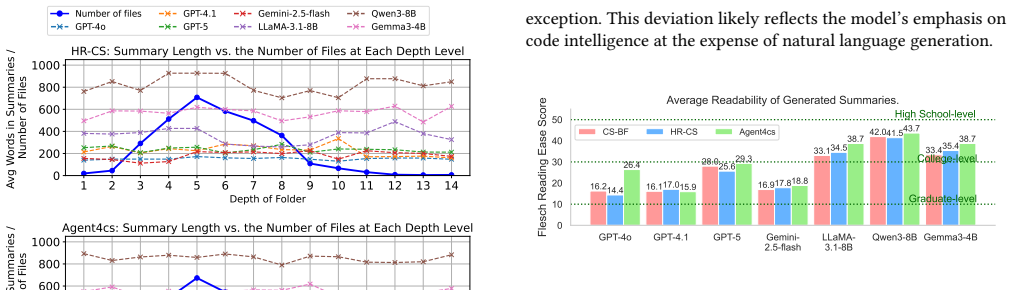
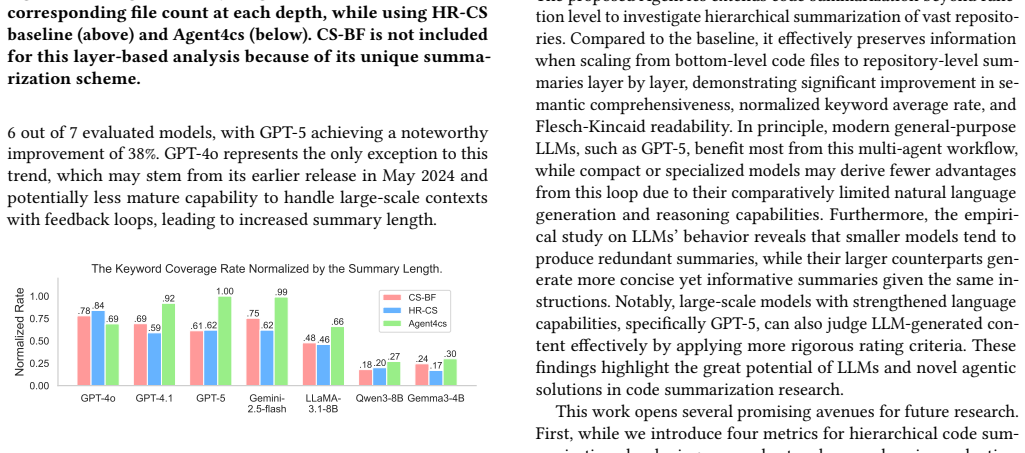
Agent4cs applies three specialized agents in a bottom-up hierarchy: a summarization agent creates folder-level descriptions, a keyword-extraction agent surfaces critical information from child folders, and a quality-assurance agent iterates on readability and completeness. This structure yields an average 8 percent rise in semantic consistency across all folder levels and up to 38 percent higher normalized keyword coverage compared with structured prompting baselines that also receive code segments.
What carries the argument
The three-agent分工 of summarization agent, keyword-extraction agent, and quality-assurance agent arranged in bottom-up order over the folder hierarchy.
If this is right
- Summaries maintain higher semantic consistency at every level of a repository's folder tree.
- Normalized keyword coverage improves by as much as 38 percent on real-world code collections.
- The same agent arrangement works across seven different frontier models without per-model changes.
- The method handles repositories that contain obfuscated structure or missing documentation.
Where Pith is reading between the lines
- The same bottom-up agent pattern could be applied to other hierarchical artifacts such as documentation trees or data catalogs.
- Teams maintaining large codebases might reduce manual review time if the generated summaries prove reliable enough to serve as first drafts.
- Further tests could check whether adding a fourth agent for cross-folder dependency detection produces additional gains.
Load-bearing premise
The measured gains arise from the specific division into three agents and the bottom-up folder traversal rather than from simply issuing more language-model calls or supplying longer contexts.
What would settle it
An experiment that keeps total language-model calls and context length constant but collapses the three agents into one prompt and shows no remaining improvement over the baselines.
Figures







read the original abstract
Understanding large, complex codebases, especially those with obfuscated structures and incomplete documentation, remains a significant challenge. Existing code summarization solutions often rely on a single language model or coding assistant like Claude Code, and treat source code as flat text, underutilizing the rich interdependencies and hierarchical information within a repository. To address these shortcomings, we propose Agent4cs - a multi-agent framework that summarizes large codebases in a bottom-up fashion, where a summarization agent focuses on producing robust summaries; a keyword-extraction agent proactively identifies critical information from subfolders; and a quality-assurance agent iteratively refines the outputs for readability, coherence, and completeness. Evaluated on 7 frontier models, Agent4cs improves semantic consistency across all folder levels by average 8% compared to two structured prompting baselines with code segments. Furthermore, extensive evaluation on real-world datasets demonstrates up to 38% gains in normalized keyword coverage rate over the same baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
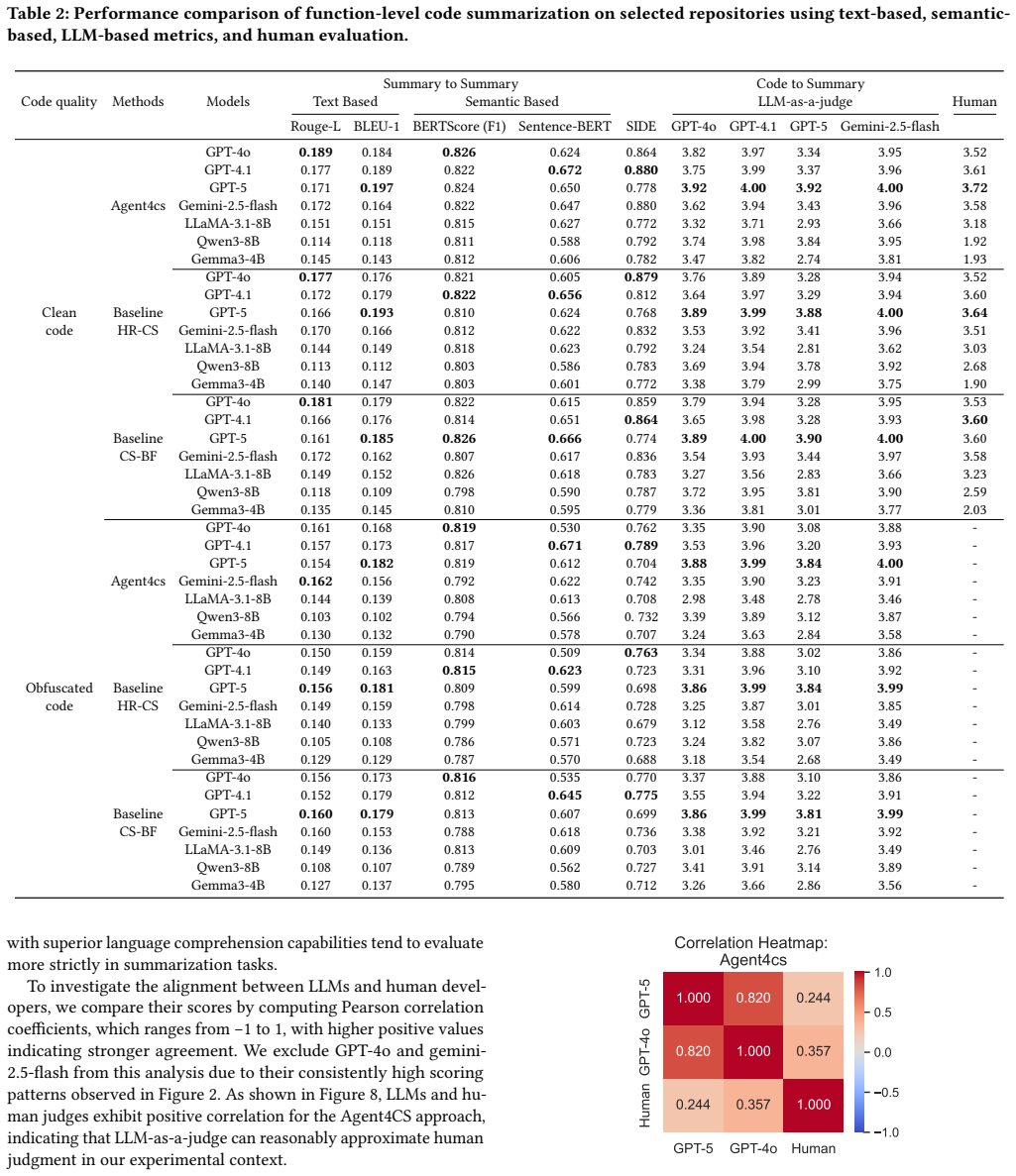
Summary. The manuscript proposes Agent4cs, a multi-agent framework for bottom-up summarization of large hierarchical codebases. It deploys three agents (summarization, keyword-extraction, and quality-assurance) that operate on folder structure to produce summaries, extract keywords, and iteratively refine outputs. The central empirical claim is that, across 7 frontier models and real-world datasets, Agent4cs yields an average 8% improvement in semantic consistency across folder levels and up to 38% gains in normalized keyword coverage rate relative to two structured prompting baselines that also receive code segments.
Significance. If the reported gains prove robust and causally attributable to the three-agent hierarchical design rather than increased inference budget, the work would offer a concrete demonstration that specialized multi-agent decomposition can improve LLM-based understanding of complex repositories. The evaluation on multiple models is a positive feature; however, the absence of controls that isolate the architectural contribution weakens the interpretability of the results.
major comments (1)
- [Evaluation section] Evaluation section: The central claim attributes the 8% semantic-consistency and 38% keyword-coverage improvements to the specific three-agent bottom-up design. The comparisons are made only against 'structured prompting baselines with code segments' and supply no data on total LLM calls, total tokens consumed, or number of refinement iterations used by Agent4cs versus the baselines. Without such controls, the observed deltas cannot be isolated from the possibility that Agent4cs simply expends more inference budget; this is load-bearing for the causal interpretation of the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The central claim attributes the 8% semantic-consistency and 38% keyword-coverage improvements to the specific three-agent bottom-up design. The comparisons are made only against 'structured prompting baselines with code segments' and supply no data on total LLM calls, total tokens consumed, or number of refinement iterations used by Agent4cs versus the baselines. Without such controls, the observed deltas cannot be isolated from the possibility that Agent4cs simply expends more inference budget; this is load-bearing for the causal interpretation of the architecture.
Authors: We agree that the absence of reported inference-budget metrics limits the strength of the causal claim. The manuscript currently provides no data on LLM calls, token consumption, or refinement iterations for Agent4cs versus the structured-prompting baselines, so the observed gains cannot be isolated from possible differences in total compute. In the revised manuscript we will add a new table and accompanying text in the Evaluation section that reports, for each of the seven models and both datasets: (i) average number of LLM calls per top-level summary, (ii) total tokens consumed, and (iii) number of quality-assurance refinement rounds. These figures will be collected under identical model and temperature settings for all methods, enabling readers to assess whether the reported improvements exceed what would be expected from increased inference budget alone. revision: yes
Circularity Check
No circularity; purely empirical multi-agent system evaluation
full rationale
The paper describes a multi-agent framework (summarization, keyword-extraction, and QA agents) for hierarchical code summarization and reports empirical gains (8% semantic consistency, 38% keyword coverage) against structured prompting baselines on 7 models and real-world datasets. No equations, parameters, or derivations are present. All claims rest on direct external comparisons rather than any self-referential fitting, self-citation chains, or renamings that reduce to inputs by construction. The work is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automatic metrics such as semantic consistency and keyword coverage correlate with human judgments of summary usefulness.
invented entities (1)
-
Summarization agent, keyword-extraction agent, quality-assurance agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2020. A Transformer-based Approach for Source Code Summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 4998– 5007
2020
-
[2]
Toufique Ahmed and Premkumar Devanbu. 2023. Few-shot training LLMs for project-specific code-summarization. InProceedings of the 37th IEEE/ACM In- ternational Conference on Automated Software Engineering(Rochester, MI, USA) (ASE ’22). Association for Computing Machinery, New York, NY, USA, Article 177, 5 pages. doi:10.1145/3551349.3559555
-
[3]
Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl Barr. 2024. Automatic semantic augmentation of language model prompts (for code summa- rization). InProceedings of the IEEE/ACM 46th international conference on software engineering. 1–13
2024
-
[4]
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate.International Conference on Learning Representations (ICLR)(2015), 1–15. arXiv:1409.0473 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio
-
[6]
On the Properties of Neural Machine Translation: Encoder–Decoder Ap- proaches. InProceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. Association for Computational Linguistics, Doha, Qatar, 103–111. doi:10.3115/v1/W14-4012
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Wikipedia contributors. n.d.. Flesch–Kincaid readability tests. https://en. wikipedia.org/wiki/Flesch%E2%80%93Kincaid_readability_tests Accessed: Octo- ber 7, 2025
2025
-
[9]
Giuseppe Crupi, Rosalia Tufano, Alejandro Velasco, Antonio Mastropaolo, Denys Poshyvanyk, and Gabriele Bavota. 2025. On the Effectiveness of LLM-as-a- judge for Code Generation and Summarization.IEEE Transactions on Software Engineering(2025)
2025
-
[10]
Nilesh Dhulshette, Sapan Shah, and Vinay Kulkarni. 2025. Hierarchical repository- level code summarization for business applications using local LLMs. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 145–152
2025
-
[11]
William H DuBay. 2004. The principles of readability. (2004)
2004
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The LLaMA 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[13]
Hanya Elhashemy, Youssef Lotfy, and Yongjian Tang. 2025. Bridging the Prototype-Production Gap: A Multi-Agent System for Notebooks Transforma- tion. In2025 40th IEEE/ACM International Conference on Automated Software Engineering Workshops (ASEW). 299–302. doi:10.1109/ASEW67777.2025.00061
-
[14]
Chunrong Fang, Weisong Sun, Yuchen Chen, Xiao Chen, Zhao Wei, Quanjun Zhang, Yudu You, Bin Luo, Yang Liu, and Zhenyu Chen. 2024. ESALE: Enhanc- ing code-summary alignment learning for source code summarization.IEEE Transactions on Software Engineering50, 8 (2024), 2077–2095
2024
-
[15]
Shuzheng Gao, Xin-Cheng Wen, Cuiyun Gao, Wenxuan Wang, Hongyu Zhang, and Michael R. Lyu. 2024. What Makes Good In-Context Demonstrations for Code Intelligence Tasks with LLMs?. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering(Echternach, Luxembourg)(ASE ’23). IEEE Press, 761–773. doi:10.1109/ASE56229.2023.00109
-
[16]
Rajarshi Haldar and Julia Hockenmaier. 2024. Analyzing the Performance of Large Language Models on Code Summarization. InJoint 30th International Conference on Computational Linguistics and 14th International Conference on Language Resources and Evaluation, LREC-COLING 2024. European Language Resources Association (ELRA), 995–1008
2024
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Sum- marizing source code using a neural attention model. In54th Annual Meeting of the Association for Computational Linguistics 2016. Association for Computational Linguistics, 2073–2083
2016
-
[20]
Alexander LeClair, Sakib Haque, Lingfei Wu, and Collin McMillan. 2020. Im- proved code summarization via a graph neural network. InProceedings of the 28th International Conference on Program Comprehension. 184–195
2020
-
[21]
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out. 74–81
2004
-
[22]
Shangqing Liu, Yu Chen, Xiaofei Xie, Jingkai Siow, and Yang Liu. 2021. Retrieval- augmented generation for code summarization via hybrid GNN.(2021). InPro- ceedings of the Ninth International Conference on Learning Representations: ICLR. 4–8
2021
-
[23]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambro- sio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al . 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understand- ing and Generation. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)
2021
-
[24]
Vladimir Makharev and Vladimir Ivanov. 2025. Code Summarization Beyond Function Level. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 153–160
2025
-
[25]
Antonio Mastropaolo, Matteo Ciniselli, Massimiliano Di Penta, and Gabriele Bavota. 2024. Evaluating code summarization techniques: A new metric and an empirical characterization. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[26]
Debanjan Mondal, Abhilasha Lodha, Ankita Sahoo, and Beena Kumari. 2023. Understanding Code Semantics: An Evaluation of Transformer Models in Sum- marization. InGenBench: The First Workshop on Generalisation (benchmarking) in NLP. 65
2023
-
[27]
OpenAI. 2025. GPT-5 System Card. (2025)
2025
-
[28]
OpenAI. 2025. Introducing GPT-4.1 in the API. (2025)
2025
-
[29]
Amirkia Rafiei Oskooei, Selcan Yukcu, Mehmet Cevheri Bozoglan, and Mehmet S. Aktas. 2025. Repository-Level Code Understanding by LLMs via Hierarchical Summarization: Improving Code Search and Bug Localization. InComputational Science and Its Applications – ICCSA 2025 Workshops: Istanbul, Turkey, June 30 – July 3, 2025, Proceedings, Part I(Istanbul, Türkiy...
-
[30]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 311–318
2002
-
[31]
Fabian Pedregosa, Ga"el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and ’Edouard Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning ...
2011
-
[32]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
2019
-
[33]
Online Free Websites: Public Repositories. [n. d.]. https://github.com/ twilio/twilio-python, https://github.com/apple/turicreate, https://github.com/ extremenetworks/pybind, https://github.com/iotile/coretools, https://github.com/ pantsbuild/pants
-
[34]
Savio Antony Sebastian, Saurabh Malgaonkar, Paulami Shah, Mudit Kapoor, and Tanay Parekhji. 2016. A study & review on code obfuscation. In2016 World Conference on Futuristic Trends in Research and Innovation for Social Welfare (Startup Conclave). IEEE, 1–6
2016
-
[35]
Ensheng Shi, Yanlin Wang, Lun Du, Junjie Chen, Shi Han, Hongyu Zhang, Dong- mei Zhang, and Hongbin Sun. 2022. On the evaluation of neural code summariza- tion. InProceedings of the 44th International Conference on Software Engineering. 1597–1608
2022
-
[36]
Jiho Shin, Clark Tang, Tahmineh Mohati, Maleknaz Nayebi, Song Wang, and Hadi Hemmati. 2025. Prompt Engineering or Fine-Tuning: An Empirical Assessment of LLMs for Code. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 490–502
2025
- [37]
-
[38]
Chia-Yi Su and Collin McMillan. 2024. Distilled GPT for source code summariza- tion.Automated Software Engineering31, 1 (2024), 22
2024
-
[39]
Weisong Sun, Chunrong Fang, Yuchen Chen, Quanjun Zhang, Guanhong Tao, Yudu You, Tingxu Han, Yifei Ge, Yuling Hu, Bin Luo, et al. 2024. An extractive- and-abstractive framework for source code summarization.ACM Transactions on Software Engineering and Methodology33, 3 (2024), 1–39
2024
- [40]
- [41]
-
[42]
Weisong Sun, Yun Miao, Yuekang Li, Hongyu Zhang, Chunrong Fang, Yi Liu, Gelei Deng, Yang Liu, and Zhenyu Chen. 2025. Source Code Summarization in the Era of Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1882–1894. 10
2025
-
[43]
Yongjian Tang, Rakebul Hasan, and Thomas Runkler. 2024. FsPONER: Few- Shot Prompt Optimization for Named Entity Recognition in Domain-Specific Scenarios. InECAI 2024. IOS Press, 3757–3764. https://ebooks.iospress.nl/doi/10. 3233/FAIA240936
2024
-
[44]
Yongjian Tang and Thomas Runkler. 2026. LLM-Based Agentic Systems for Software Engineering: Challenges and Opportunities. SE2026. doi:10.18420/ se2026-ws_15
2026
-
[45]
Yongjian Tang, Doruk Tuncel, Christian Koerner, and Thomas Runkler. 2025. The Few-shot Dilemma: Over-prompting Large Language Models.arXiv preprint arXiv:2509.13196(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. 2025. Gemma 3 technical report.arXiv preprint arXiv:2503.19786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing Systems30 (2017)
2017
-
[48]
Alessio Viticchié, Leonardo Regano, Marco Torchiano, Cataldo Basile, Mariano Ceccato, Paolo Tonella, and Roberto Tiella. 2016. Assessment of source code obfuscation techniques. In2016 IEEE 16th International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 11–20
2016
-
[49]
Yao Wan, Zhou Zhao, Min Yang, Guandong Xu, Haochao Ying, Jian Wu, and Philip S Yu. 2018. Improving automatic source code summarization via deep rein- forcement learning. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. 397–407
2018
-
[50]
Yang Wu, Yao Wan, Zhaoyang Chu, Wenting Zhao, Ye Liu, Hongyu Zhang, Xuanhua Shi, Hai Jin, and Philip S Yu. 2025. Can large language models serve as evaluators for code summarization?IEEE Transactions on Software Engineering (2025)
2025
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, et al. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv.org/abs/2505. 09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Chunyan Zhang, Junchao Wang, Qinglei Zhou, Ting Xu, Ke Tang, Hairen Gui, and Fudong Liu. 2022. A survey of automatic source code summarization.Symmetry 14, 3 (2022), 471
2022
-
[53]
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2020. Retrieval-based neural source code summarization. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 1385–1397
2020
-
[54]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi
-
[55]
BERTscore: Evaluating text generation with BERT.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[56]
Xuejun Zhang, Xia Hou, Xiuming Qiao, and Wenfeng Song. 2024. A review of automatic source code summarization.Empirical Software Engineering29, 6 (2024), 162
2024
-
[57]
Yuwei Zhao, Ziyang Luo, Yuchen Tian, Hongzhan Lin, Weixiang Yan, Annan Li, and Jing Ma. 2025. CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?. InProceedings of the 31st International Conference on Computational Linguistics. 73–95
2025
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.