Discrete Diffusion Language Models for Interactive Radiology Report Drafting
Pith reviewed 2026-07-03 20:18 UTC · model grok-4.3
The pith
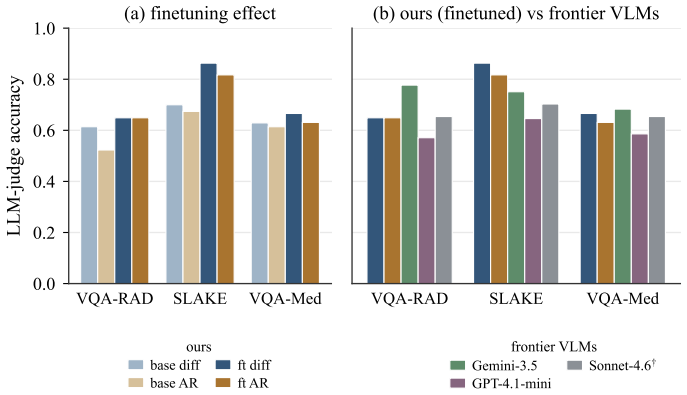
A finetuned diffusion language model matches or exceeds autoregressive models on medical visual question answering while decoding 3.5-4.4 times faster and enabling any-order text infill.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting DiffusionGemma-26B via LoRA on medical visual question answering data, the finetuned diffusion model with 3.8B active parameters reaches or surpasses the performance of its autoregressive sibling Gemma-4-26B on the same benchmarks, delivers 3.5-4.4x faster decoding, and supplies native any-order infill because the token canvas is refined bidirectionally rather than emitted sequentially.
What carries the argument
Bidirectional iterative denoising of a full token canvas in a mixture-of-experts diffusion language model, which refines all positions simultaneously instead of generating tokens left to right.
If this is right
- The finetuned diffusion model becomes competitive with frontier vision-language models on medical visual question answering tasks.
- Generation runs 3.5-4.4 times faster than the same-size autoregressive model under identical fine-tuning.
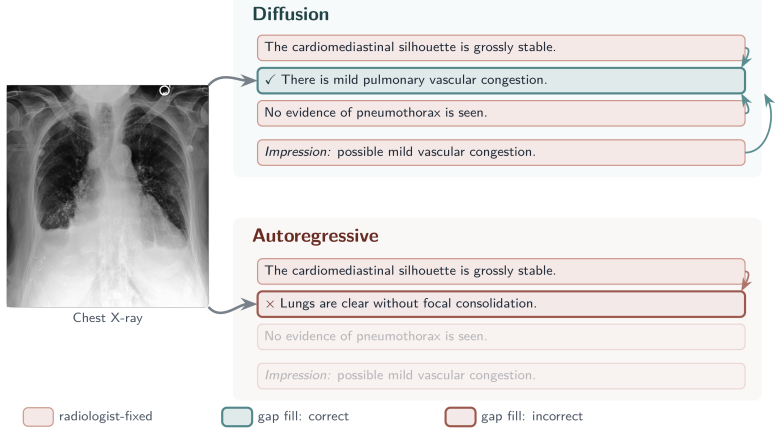
- Any-order infill lets a radiologist fix report fragments and have the model complete the text between them.
- The approach fits real radiology reports that are often terse or vary in structure across clinicians and institutions.
Where Pith is reading between the lines
- Interactive any-order editing could reduce the time radiologists spend revising draft reports in clinical software.
- The same bidirectional mechanism may transfer to other medical document tasks such as discharge summaries or pathology reports that require non-sequential revisions.
- Combining diffusion generation with stronger vision encoders could further close remaining gaps with larger frontier models on image-conditioned medical text.
Load-bearing premise
The verbosity-robust LLM judge used to score outputs accurately captures clinical correctness and usefulness of the generated reports rather than surface-level fluency.
What would settle it
A blinded side-by-side evaluation by practicing radiologists that measures clinical accuracy and usefulness of diffusion-generated versus autoregressive-generated reports on a held-out set of real patient imaging cases.
Figures

read the original abstract
Diffusion language models, which generate text by denoising a token canvas bidirectionally instead of emitting tokens left to right, have become competitive with autoregressive (AR) generation. Medical foundation models, however, remain almost entirely autoregressive. We adapt a mixture-of-experts diffusion language model, DiffusionGemma-26B, and benchmark it against its same-size AR sibling Gemma-4-26B under an identical LoRA recipe on medical visual question answering datasets, scored by a verbosity-robust LLM judge. Diffusion matches or exceeds AR on all of them, and the finetuned model (3.8B active) is competitive with frontier vision-language models; its decoding is also 3.5-4.4x faster. Beyond this parity, the diffusion model offers a drafting capability AR lacks: any-order infill. Because the canvas is denoised bidirectionally, a radiologist can fix report fragments and have the model fill the text between them, an operation inherent to diffusion but not to autoregression, which is subpar at it. This suits real reports, which are often terse or inconsistent across clinicians and institutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adapts the DiffusionGemma-26B mixture-of-experts discrete diffusion language model and compares it to its autoregressive sibling Gemma-4-26B under an identical LoRA fine-tuning recipe on medical visual question answering datasets. Performance is measured exclusively by a verbosity-robust LLM judge; the diffusion model is reported to match or exceed the AR baseline, decode 3.5-4.4x faster, and enable any-order infill for interactive radiology report drafting.
Significance. If the performance parity and speed claims hold under clinical validation, the work would show that discrete diffusion models can reach parity with autoregressive models in a specialized medical domain while adding bidirectional infill capabilities that match real clinical drafting workflows. The any-order infill feature is a genuine architectural advantage not available to standard AR models.
major comments (2)
- [Abstract] Abstract: the central claim that the finetuned diffusion model 'matches or exceeds AR on all of them' rests solely on scores from an unvalidated verbosity-robust LLM judge. No human radiologist ratings, inter-rater agreement statistics, or correlation with established clinical metrics (RadGraph, CheXpert label accuracy, or error-severity scales) are reported to establish that the judge tracks factual correctness rather than surface fluency.
- [Abstract] Abstract: dataset names, sizes, task definitions, and statistical test details for the VQA benchmarks are omitted, preventing assessment of whether the reported parity is robust or limited to particular distributions.
minor comments (1)
- [Abstract] The abstract states '3.8B active parameters' for the finetuned model but does not clarify how this active-parameter count was obtained from the 26B MoE backbone or whether it affects the speed comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation methodology. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the finetuned diffusion model 'matches or exceeds AR on all of them' rests solely on scores from an unvalidated verbosity-robust LLM judge. No human radiologist ratings, inter-rater agreement statistics, or correlation with established clinical metrics (RadGraph, CheXpert label accuracy, or error-severity scales) are reported to establish that the judge tracks factual correctness rather than surface fluency.
Authors: We agree that the reported performance parity relies solely on the verbosity-robust LLM judge without human radiologist validation, inter-rater statistics, or explicit correlation to clinical metrics such as RadGraph or CheXpert. This constitutes a genuine limitation of the current study. We will revise the abstract to explicitly qualify the claims as LLM-judge-based and to moderate the language around 'matches or exceeds.' A limitations discussion on automated evaluation in medical domains will also be added to the manuscript. revision: partial
-
Referee: [Abstract] Abstract: dataset names, sizes, task definitions, and statistical test details for the VQA benchmarks are omitted, preventing assessment of whether the reported parity is robust or limited to particular distributions.
Authors: We will update the abstract to include the specific medical VQA dataset names, their sizes, and task definitions. Statistical test details are already provided in the experimental setup and results sections of the full manuscript; we will ensure the abstract references these details more clearly. revision: yes
- Human radiologist ratings, inter-rater agreement, or direct correlation of the LLM judge with clinical metrics such as RadGraph or CheXpert, as these were not collected in the original experiments and would require new data collection.
Circularity Check
No circularity; empirical benchmarking only
full rationale
The paper reports direct experimental results from fine-tuning a diffusion LM (DiffusionGemma-26B) and its AR sibling (Gemma-4-26B) under an identical LoRA recipe, then measuring VQA performance via an LLM judge and noting the any-order infill property inherent to bidirectional denoising. No equations, parameter fits presented as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmarking rather than any reduction of outputs to the paper's own inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. doi: 10.48550/arXiv.2107.03006
-
[2]
Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando Pérez-García, Valentina Salvatelli, Harshita Sharma, et al. MAIRA-2: Grounded radiology report generation, 2024. arXiv preprint arXiv:2406.04449
-
[3]
Hasan, Vivek V
Asma Ben Abacha, Sadid A. Hasan, Vivek V . Datla, Joey Liu, Dina Demner-Fushman, and Henning Müller. VQA-Med: Overview of the medical visual question answering task at ImageCLEF 2019. InCLEF 2019 Working Notes, CEUR Workshop Proceedings, 2019
2019
-
[4]
ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Lifeng Chen, Tianqi You, Hao Liu, Zhimin Bao, Jile Jiao, Xiao Han, Zhicai Ou, Tao Sun, Xiaofeng Mou, Xiaojie Jin, and Yi Xu. ECHO: Efficient chest x-ray report generation with one-step block diffusion, 2026. arXiv preprint arXiv:2604.09450
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Gemma 4: Open multimodal models
Gemma Team, Google DeepMind. Gemma 4: Open multimodal models. Model card, https: //huggingface.co/google/gemma-4-26B-A4B-it, 2026
2026
-
[6]
DiffusionGemma: Block discrete-diffusion language models
Google DeepMind. DiffusionGemma: Block discrete-diffusion language models. Model card, https://huggingface.co/google/diffusiongemma-26B-A4B-it, 2026
2026
-
[7]
SemEnrich: Self-Supervised Semantic Enrichment of Radiology Reports for Vision-Language Learning
Halil Ibrahim Gulluk and Olivier Gevaert. SemEnrich: Self-supervised semantic enrichment of radiology reports for vision-language learning.arXiv preprint arXiv:2604.09887, 2026. doi: 10.48550/arXiv.2604.09887
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09887 2026
-
[8]
OpenMedQ: Broad Open Pretraining for Medical Vision-Language Models
Halil Ibrahim Gulluk, Max Van Puyvelde, and Olivier Gevaert. OpenMedQ: Broad open pretraining for medical vision-language models.arXiv preprint arXiv:2606.12953, 2026. doi: 10.48550/arXiv.2606.12953
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.12953 2026
-
[9]
SDR: Set-Distance Rewards for Radiology Report Generation
Halil Ibrahim Gulluk, Max Van Puyvelde, Wim Van Criekinge, and Olivier Gevaert. SDR: Set-distance rewards for radiology report generation, 2026. arXiv preprint arXiv:2606.00440
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
arXiv preprint arXiv:2602.01326 , year=
HKU NLP Group. DreamOn: Diffusion language models for code infilling beyond fixed-size canvas, 2026. arXiv preprint arXiv:2602.01326
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. doi: 10.48550/arXiv.2106. 09685
-
[12]
Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C
Stephanie L. Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Mercy Ranjit, Anton Schwaighofer, Fernando Pérez-García, Valentina Salvatelli, Shaury Srivastav, Anja Thieme, et al. MAIRA-1: A specialised large multimodal model for radiology report generation, 2023. arXiv preprint arXiv:2311.13668
-
[13]
Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih-ying Deng, Roger G. Mark, and Steven Horng. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports.Scientific Data, 6(1):317,
-
[14]
doi: 10.1038/s41597-019-0322-0
-
[15]
Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman
Jason J. Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific Data, 5(1): 180251, 2018. doi: 10.1038/sdata.2018.251. 7
-
[16]
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. LLaV A-Med: Training a large language-and-vision assistant for biomedicine in one day. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks, 2023. doi: 10.48550/arXiv.2306.00890
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.00890 2023
-
[17]
SLAKE: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. SLAKE: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. InIEEE Interna- tional Symposium on Biomedical Imaging (ISBI), 2021. doi: 10.1109/ISBI48211.2021.9434010
-
[18]
Discrete diffusion models with MLLMs for unified medical multimodal generation, 2025
Jiawei Mao, Yuhan Wang, Lifeng Chen, Can Zhao, Yucheng Tang, Dong Yang, Liangqiong Qu, Daguang Xu, and Yuyin Zhou. Discrete diffusion models with MLLMs for unified medical multimodal generation, 2025. arXiv preprint arXiv:2510.06131
-
[19]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025. doi: 10.48550/arXiv.2502.09992
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[20]
Chiu, Alexander Rush, and V olodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[21]
doi: 10.48550/arXiv.2406.07524
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tim Tanida, Philip Müller, Georgios Kaissis, and Daniel Rueckert. Interactive and explainable region-guided radiology report generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. doi: 10.1109/CVPR52729.2023.00718
-
[23]
Sheng Wang et al. CopilotCAD: Empowering radiologists with report completion models and quantitative evidence from medical image foundation models, 2024. arXiv preprint arXiv:2404.07424
-
[24]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. doi: 10.48550/arXiv.2508.15487
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15487 2025
-
[25]
Shiying Yu, Jielei Wang, and Guoming Lu. AnchorDiff: Topology-aware masked diffu- sion with confidence-based rewriting for radiology report generation, 2026. arXiv preprint arXiv:2605.17071
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InInternational Conference on Computer Vision (ICCV), 2023. doi: 10.48550/arXiv.2303.15343
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.15343 2023
-
[27]
ReXrank: A public leaderboard for ai-powered radiology report generation, 2024
Xiaoman Zhang, Hong-Yu Zhou, Xiaoli Yang, et al. ReXrank: A public leaderboard for ai-powered radiology report generation, 2024. arXiv preprint arXiv:2411.15122
-
[28]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. doi: 10. 48550/arXiv.2...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.