Unified Panoramic-Gaussian Representation for Monocular 4D Scene Synthesis
Pith reviewed 2026-07-03 16:37 UTC · model grok-4.3
The pith
PanoGaussian distills panoramic representations into dynamic Gaussians to enable consistent 4D scene synthesis from monocular videos under large viewpoint variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By distilling a panoramic representation into an explicit dynamic Gaussian representation, PanoGaussian captures the dynamic physical priors of a 4D scene and removes the scale and shape distortions that arise from object motion in panoramic space, thereby achieving consistent 4D scene synthesis even under large viewpoint variations.
What carries the argument
PanoGaussian, a unified Panoramic-Gaussian representation that distills panoramic trajectory guidance into explicit dynamic 3D Gaussians to encode object motion priors.
If this is right
- The method extends 4D synthesis beyond view interpolation to regions never observed in the input video.
- Panoramic guidance improves cross-view consistency compared with random camera trajectories in video generation models.
- Explicit dynamic Gaussians encode physical motion priors that panoramic representations alone cannot maintain.
- The unified training and inference framework supports both panoramic guidance and Gaussian distillation in one pipeline.
Where Pith is reading between the lines
- The hybrid panoramic-to-Gaussian distillation may apply to other dynamic scene tasks where pure implicit or explicit representations fall short.
- If the Gaussian stage can be made faster, the approach could support interactive 4D scene editing from casual videos.
- The same distortion problem may appear in other panoramic or equirectangular representations of moving scenes, suggesting a broader need for explicit 3D distillation steps.
Load-bearing premise
Distilling the panoramic representation into dynamic Gaussians removes motion-induced scale and shape distortions while preserving physical consistency and without creating new inconsistencies under large trajectory changes.
What would settle it
Generate a 4D scene with a camera trajectory that deviates substantially from the input video path and observe whether object shapes and scales remain geometrically consistent across novel views; visible distortions would falsify the claim.
Figures
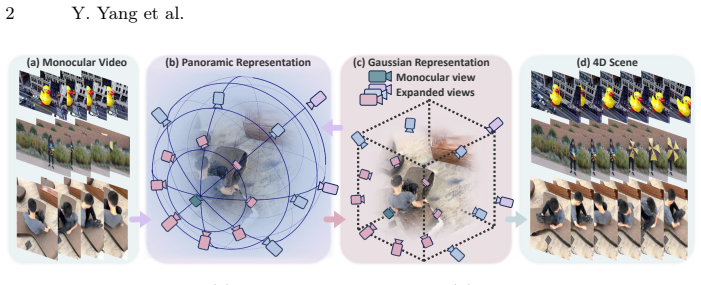
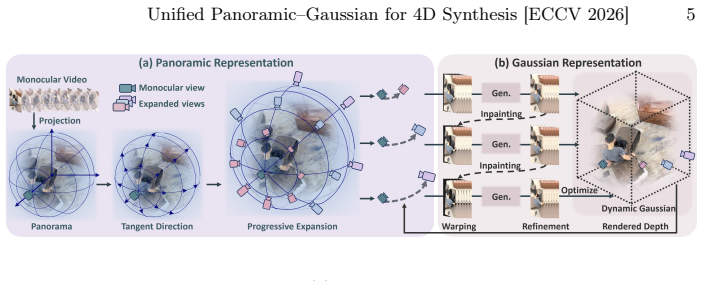




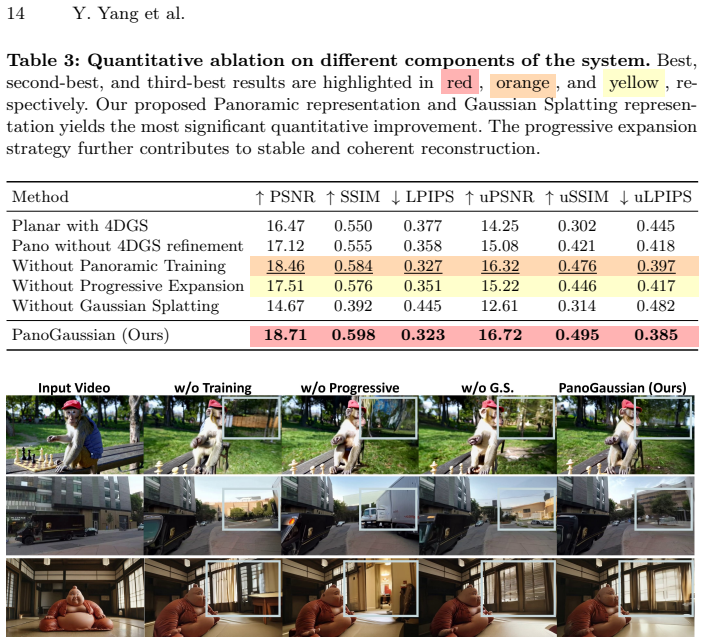


read the original abstract
4D scene synthesis from monocular videos has made significant progress in recent years. However, existing methods are typically constrained by view interpolation. As a result, they struggle to infer unseen regions beyond the observed views. In this paper, we reformulate the task as 4D scene synthesis with unseen regions, which extends beyond traditional interpolation settings. Camera-conditioned video generation enables unseen region synthesis by guiding generation along specified cameras. However, these methods lack explicit 3D priors and are optimized with random camera trajectories. This design leads to severe inconsistencies under large trajectory deviations. To address this limitation, we build a unified training and inference framework with panoramic trajectory guidance. While this design improves cross-view consistency, the panoramic representation alone fails to model dynamic content effectively. Object motion in panoramic space introduces scale and shape distortions. To address this, we propose PanoGaussian, a unified Panoramic-Gaussian representation that distills the panoramic representation into an explicit dynamic Gaussian representation to capture dynamic physical priors of the 4D scene. Experiments demonstrate that PanoGaussian achieves consistent 4D scene synthesis even under large viewpoint variations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that monocular 4D scene synthesis is limited by view interpolation and that camera-conditioned generation with random trajectories produces inconsistencies under large deviations. It introduces panoramic trajectory guidance to improve cross-view consistency but notes that panoramic representations distort dynamic object motion. To fix this, the authors propose PanoGaussian, which distills the panoramic representation into an explicit dynamic Gaussian representation that captures dynamic physical priors, enabling consistent 4D synthesis even under large viewpoint variations.
Significance. If the distillation step reliably removes scale/shape distortions while preserving physical priors and avoiding new inconsistencies, the method would meaningfully extend 4D synthesis beyond interpolation. The abstract, however, contains no equations, loss formulations, ablation results, or quantitative metrics, so the practical significance cannot be assessed from the provided text.
major comments (1)
- The central claim rests on the assertion that distilling the panoramic representation into dynamic Gaussians removes motion-induced scale and shape distortions while capturing physical priors and avoiding new inconsistencies under large trajectories. No mechanism, loss function, constraint, or training objective is described to show how this distillation enforces the required properties. This assumption is load-bearing for the entire improvement over camera-conditioned baselines.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater clarity on the distillation mechanism. We address the major comment below.
read point-by-point responses
-
Referee: The central claim rests on the assertion that distilling the panoramic representation into dynamic Gaussians removes motion-induced scale and shape distortions while capturing physical priors and avoiding new inconsistencies under large trajectories. No mechanism, loss function, constraint, or training objective is described to show how this distillation enforces the required properties. This assumption is load-bearing for the entire improvement over camera-conditioned baselines.
Authors: We agree that the abstract and the provided summary text do not include the specific loss functions or training objectives for the distillation step. The full manuscript expands on the PanoGaussian representation in the methods, but the description of how the distillation explicitly enforces distortion removal and physical priors (via particular constraints or objectives) is insufficiently detailed. We will revise the manuscript to add the key loss terms, constraints, and training objectives in both the abstract and the methods section to make the mechanism explicit. revision: yes
Circularity Check
No circularity: method is an independent design choice
full rationale
The abstract and described framework present panoramic trajectory guidance followed by distillation to dynamic Gaussians as a sequence of engineering decisions to address stated limitations (inconsistencies under large trajectories, scale/shape distortions). No equation, loss term, or parameter is shown to be fitted on a subset and then renamed as a 'prediction' of a closely related quantity. No self-citation is invoked as a load-bearing uniqueness theorem or to smuggle an ansatz. The central claim rests on the empirical success of the proposed representation rather than reducing to its own inputs by construction. This is the expected non-finding for a methods paper whose derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
PanoGaussian
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE transactions on visualization and computer graphics (2024)
Ai, H., Cao, Z., Lu, H., Chen, C., Ma, J., Zhou, P., Kim, T.K., Hui, P., Wang, L.: Dream360: Diverse and immersive outdoor virtual scene creation via transformer- based 360 image outpainting. IEEE transactions on visualization and computer graphics (2024)
2024
-
[2]
arXiv preprint (2025)
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint (2025)
2025
-
[3]
In: 3DV (2025)
Bai, J., Huang, L., Guo, J., Gong, W., Li, Y., Guo, Y.: 360-gs: Layout-guided panoramic gaussian splatting for indoor roaming. In: 3DV (2025)
2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
In: SIGGRAPH (2025)
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unify- ing precisely 3d-enhanced camera and human motion controls for video generation. In: SIGGRAPH (2025)
2025
-
[6]
In: NeurIPS (2025)
Chen, K., Khurana, T., Ramanan, D.: Reconstruct, inpaint, finetune: Dynamic novel-view synthesis from monocular videos. In: NeurIPS (2025)
2025
-
[7]
In: CVPR (2025)
Chen, Z., Wu, C., Shen, Z., Zhao, C., Ye, W., Feng, H., Ding, E., Zhang, S.H.: Splatter-360: Generalizable 360 gaussian splatting for wide-baseline panoramic im- ages. In: CVPR (2025)
2025
-
[8]
In: NeurIPS (2024)
Chu, W.H., Ke, L., Fragkiadaki, K.: Dreamscene4d: Dynamic multi-object scene generation from monocular videos. In: NeurIPS (2024)
2024
-
[9]
In: SIGGRAPH (2024)
Chugunov, I., Joshi, A., Murthy, K., Bleibel, F., Heide, F.: Neural light spheres for implicit image stitching and view synthesis. In: SIGGRAPH (2024)
2024
-
[10]
arXiv preprint arXiv:2312.01196 (2023)
Das, D., Wewer, C., Yunus, R., Ilg, E., Lenssen, J.E.: Neural parametric gaussians for monocular non-rigid object reconstruction. arXiv preprint arXiv:2312.01196 (2023)
-
[11]
ArXiv (2024)
Duan, Y., Wei, F., Dai, Q., He, Y., Chen, W., Chen, B.: 4d gaussian splatting: Towards efficient novel view synthesis for dynamic scenes. ArXiv (2024)
2024
-
[12]
arXiv preprint arXiv:2312.01089 (2023)
Duisterhof, B., Xu, D., Chen, R., Chen, Y.C.: Mvsplat: Efficient 3d gaussian splat- ting from multi-view stereo. arXiv preprint arXiv:2312.01089 (2023)
-
[13]
In: SIGGRAPH (2022)
Fang, J., Yi, T., Wang, X., Xie, L., Zhang, X., Liu, W., Nießner, M., Tian, Q.: Fast dynamic radiance fields with time-aware neural voxels. In: SIGGRAPH (2022)
2022
-
[14]
In: CVPR (2023)
Fridovich-Keil, S., Meanti, G., Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: CVPR (2023)
2023
-
[15]
In: Proceedings of the IEEE International Conference on Com- puter Vision (2021)
Gao, C., Saraf, A., Kopf, J., Huang, J.B.: Dynamic view synthesis from dynamic monocular video. In: Proceedings of the IEEE International Conference on Com- puter Vision (2021)
2021
-
[16]
In: ICCV (2021)
Gao, C., Saraf, A., Kopf, J., Huang, J.B.: Dynamic view synthesis from dynamic monocular video. In: ICCV (2021)
2021
-
[17]
In: NeurIPS (2022)
Gao, H., Li, R., Tulsiani, S., Russell, B., Kanazawa, A.: Monocular dynamic view synthesis: A reality check. In: NeurIPS (2022)
2022
-
[18]
In: ICME (2022)
Gu, K., Maugey, T., Knorr, S., Guillemot, C.: Omni-nerf: neural radiance field from 360 image captures. In: ICME (2022)
2022
-
[19]
ICLR (2026) Unified Panoramic–Gaussian for 4D Synthesis [ECCV 2026] 17
Guo, F., Hsu, C.C., Ding, S., Zhang, C.: Uncertainty matters in dynamic gaussian splatting for monocular 4d reconstruction. ICLR (2026) Unified Panoramic–Gaussian for 4D Synthesis [ECCV 2026] 17
2026
-
[20]
ArXiv (2024)
Guo, Z., Zhou, W.g., Li, L., Wang, M., Li, H.: Motion-aware 3d gaussian splatting for efficient dynamic scene reconstruction. ArXiv (2024)
2024
-
[21]
arXiv preprint (2024)
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: Enabling camera control for text-to-video generation. arXiv preprint (2024)
2024
-
[22]
arXiv preprint (2025)
He, H., Yang, C., Lin, S., Xu, Y., Wei, M., Gui, L., Zhao, Q., Wetzstein, G., Jiang, L., Li, H.: Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. arXiv preprint (2025)
2025
-
[23]
ACM TOG (2017)
Hedman, P., Alsisan, S., Szeliski, R., Kopf, J.: Casual 3d photography. ACM TOG (2017)
2017
-
[24]
ACM TOG (2018)
Hedman, P., Kopf, J.: Instant 3d photography. ACM TOG (2018)
2018
-
[25]
NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
2020
-
[26]
ICLR (2022)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. ICLR (2022)
2022
-
[27]
360Roam: Real- Time Indoor Roaming Using Geometry-Aware 360° Radiance Fields,
Huang, H., Chen, Y., Zhang, T., Yeung, S.K.: 360roam: Real-time indoor roaming using geometry-aware 360 radiance fields. arXiv preprint arXiv:2208.02705 (2022)
-
[28]
In: ICCV (2025)
Huang, J., Miao, S., Yang, B., Ma, Y., Liao, Y.: Vivid4d: Improving 4d reconstruc- tion from monocular video by video inpainting. In: ICCV (2025)
2025
-
[29]
ArXiv (2023)
Katsumata, K., Vo, D.M., Nakayama, H.: An efficient 3d gaussian representation for monocular/multi-view dynamic scenes. ArXiv (2023)
2023
-
[30]
ACM Transactions on Graphics (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (2023)
2023
-
[31]
NeurIPS (2024)
Lee, S., Chung, J., Huh, J., Lee, K.M.: Odgs: 3d scene reconstruction from omni- directional images with 3d gaussian splattings. NeurIPS (2024)
2024
-
[32]
In: CVPR (2025)
Lei, J., Weng, Y., Harley, A.W., Guibas, L., Daniilidis, K.: Mosca: Dynamic gaus- sian fusion from casual videos via 4d motion scaffolds. In: CVPR (2025)
2025
-
[33]
ArXiv (2024)
Li, F., Zhang, H., Ahuja, N.: Self-calibrating 4d novel view synthesis from monoc- ular videos using gaussian splatting. ArXiv (2024)
2024
-
[34]
In: WACV (2025)
Li, L., Huang, H., Yeung, S.K., Cheng, H.: Omnigs: Fast radiance field reconstruc- tion using omnidirectional gaussian splatting. In: WACV (2025)
2025
-
[35]
arXiv preprint arXiv:2406.13527 (2024)
Li, R., Pan, P., Yang, B., Xu, D., Zhou, S., Zhang, X., Li, Z., Kadambi, A., Wang, Z., Tu, Z., et al.: 4k4dgen: Panoramic 4d generation at 4k resolution. arXiv preprint arXiv:2406.13527 (2024)
-
[36]
arXiv preprint arXiv:2312.16812 (2023)
Li, Z., Chen, Z., Li, Z., Xu, Y.: Spacetime gaussian feature splatting for real-time dynamic view synthesis. arXiv preprint arXiv:2312.16812 (2023)
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
2021
-
[38]
In: CVPR (2021)
Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: CVPR (2021)
2021
-
[39]
Li, Z., Wang, Q., Cole, F., Tucker, R., Snavely, N.: Dynibar: Neural dynamic image- basedrendering.In:ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition (2023)
2023
-
[40]
arXiv preprint (2024)
Liang, H., Ren, J., Mirzaei, A., Torralba, A., Liu, Z., Gilitschenski, I., Fidler, S., Oztireli, C., Ling, H., Gojcic, Z., et al.: Feed-forward bullet-time reconstruction of dynamic scenes from monocular videos. arXiv preprint (2024)
2024
-
[41]
ArXiv (2023) 18 Y
Liang, Y., Khan, N., Li, Z., Nguyen-Phuoc, T., Lanman, D., Tompkin, J., Xiao, L.: Gaufre: Gaussian deformation fields for real-time dynamic novel view synthesis. ArXiv (2023) 18 Y. Yang et al
2023
-
[42]
arXiv preprint arXiv:2507.10065 (2025)
Lin, C., Lin, Y., Pan, P., Yu, Y., Yan, H., Fragkiadaki, K., Mu, Y.: Movies: Motion- aware 4d dynamic view synthesis in one second. arXiv preprint arXiv:2507.10065 (2025)
-
[43]
arXiv preprint arXiv:2506.09997 (2025)
Lin, C.H., Lv, Z., Wu, S., Xu, Z., Nguyen-Phuoc, T., Tseng, H.Y., Straub, J., Khan, N., Xiao, L., Yang, M.H., et al.: Dgs-lrm: Real-time deformable 3d gaussian reconstruction from monocular videos. arXiv preprint arXiv:2506.09997 (2025)
-
[44]
Lin, Y., Dai, Z., Zhu, S., Yao, Y.: Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle. arXiv:2312.03431 (2023)
-
[45]
In: CVPR (2025)
Liu, J., Lin, S., Li, Y., Yang, M.H.: Dynamicscaler: Seamless and scalable video generation for panoramic scenes. In: CVPR (2025)
2025
-
[46]
In: AAAI (2024)
Lu, Z., Zheng, Q., Shi, B., Jiang, X.: Pano-nerf: Synthesizing high dynamic range novel views with geometry from sparse low dynamic range panoramic images. In: AAAI (2024)
2024
-
[47]
In: AAAI (2024)
Lu,Z.,Hu,K.,Wang,C.,Bai,L.,Wang,Z.:Autoregressiveomni-awareoutpainting for open-vocabulary 360-degree image generation. In: AAAI (2024)
2024
-
[48]
In: 3DV (2024)
Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 3DV (2024)
2024
-
[49]
arXiv preprint arXiv:2506.03140 (2025)
Luo, Y., Bai, J., Shi, X., Xia, M., Wang, X., Wan, P., Zhang, D., Gai, K., Xue, T.: Camclonemaster: Enabling reference-based camera control for video generation. arXiv preprint arXiv:2506.03140 (2025)
- [50]
-
[51]
PR (2024)
Miao, X., Bai, Y., Duan, H., Wan, F., Huang, Y., Long, Y., Zheng, Y.: Ctnerf: Cross-time transformer for dynamic neural radiance field from monocular video. PR (2024)
2024
-
[52]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Nan, K., Xie, R., Zhou, P., Fan, T., Yang, Z., Chen, Z., Li, X., Yang, J., Tai, Y.: Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv preprint arXiv:2407.02371 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
In: ICML (2021)
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML (2021)
2021
-
[54]
In: ICCV (2021)
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin- Brualla, R.: Nerfies: Deformable neural radiance fields. In: ICCV (2021)
2021
-
[55]
ACM TOG (2021)
Park,K.,Sinha,U.,Hedman,P.,Barron,J.T.,Bouaziz,S.,Goldman,D.B.,Martin- Brualla, R., Seitz, S.M.: Hypernerf: a higher-dimensional representation for topo- logically varying neural radiance fields. ACM TOG (2021)
2021
-
[57]
In: CVPR (2021)
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural ra- diance fields for dynamic scenes. In: CVPR (2021)
2021
-
[58]
In: AAAI (2024)
Ramasinghe, S., Shevchenko, V., Avraham, G., van den Hengel, A.: Blirf: Band limited radiance fields for dynamic scene modeling. In: AAAI (2024)
2024
-
[59]
In: CVPR (2025)
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: CVPR (2025)
2025
-
[60]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[61]
BulletGen: Improving 4D Reconstruction with Bullet-Time Generation
Rozumnyi, D., Luiten, J., Khan, N., Schonberger, J., Kontschieder, P.: Bullet- gen: Improving 4d reconstruction with bullet-time generation. arXiv preprint arXiv:2506.18601 (2025) Unified Panoramic–Gaussian for 4D Synthesis [ECCV 2026] 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
In: Proceedings of the 25th annual conference on Computer graphics and interactive techniques (1998)
Shade, J., Gortler, S., He, L.w., Szeliski, R.: Layered depth images. In: Proceedings of the 25th annual conference on Computer graphics and interactive techniques (1998)
1998
-
[63]
arXiv preprint arXiv:2502.03465 (2025)
Shen, Q., Yi, X., Lin, M., Zhang, H., Yan, S., Wang, X.: Seeing world dynamics in a nutshell. arXiv preprint arXiv:2502.03465 (2025)
-
[64]
In: Proceedings of the 26th annual conference on Computer graphics and interactive techniques (1999)
Shum, H.Y., He, L.W.: Rendering with concentric mosaics. In: Proceedings of the 26th annual conference on Computer graphics and interactive techniques (1999)
1999
-
[65]
IEEE Transactions on Visualization and Computer Graphics (2023)
Song, L., Chen, A., Li, Z., Chen, Z., Chen, L., Yuan, J., Xu, Y., Geiger, A.: Nerf- player: A streamable dynamic scene representation with decomposed neural radi- ance fields. IEEE Transactions on Visualization and Computer Graphics (2023)
2023
-
[66]
In: SIGGRAPH (2024)
Stearns, C., Harley, A., Uy, M., Dubost, F., Tombari, F., Wetzstein, G., Guibas, L.: Dynamic gaussian marbles for novel view synthesis of casual monocular videos. In: SIGGRAPH (2024)
2024
-
[67]
arXiv preprint arXiv:2403.01444 (2024)
Sun, J., Jiao, H., Li, G., Zhang, Z., Zhao, L., Xing, W.: 3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos. arXiv preprint arXiv:2403.01444 (2024)
-
[68]
In: ICCV (2023)
Tian, F., Du, S., Duan, Y.: Mononerf: Learning a generalizable dynamic radiance field from monocular videos. In: ICCV (2023)
2023
-
[69]
In: ICCV (2021)
Tretschk, E., Tewari, A., Golyanik, V., Zollhöfer, M., Lassner, C., Theobalt, C.: Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dy- namic scene from monocular video. In: ICCV (2021)
2021
-
[71]
In: ECCV (2024)
Van Hoorick, B., Wu, R., Ozguroglu, E., Sargent, K., Liu, R., Tokmakov, P., Dave, A., Zheng, C., Vondrick, C.: Generative camera dolly: Extreme monocular dynamic novel view synthesis. In: ECCV (2024)
2024
-
[72]
In: ArXiv Preprint (2021)
Wang, C., Eckart, B., Lucey, S., Gallo, O.: Neural trajectory fields for dynamic novel view synthesis. In: ArXiv Preprint (2021)
2021
-
[73]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Wang,G.,Wang,P.,Chen,Z.,Wang,W.,Loy,C.C.,Liu,Z.:Perf:Panoramicneural radiance field from a single panorama. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[74]
In: CVPR (2024)
Wang, Q., Li, W., Mou, C., Cheng, X., Zhang, J.: 360dvd: Controllable panorama video generation with 360-degree video diffusion model. In: CVPR (2024)
2024
-
[75]
In: ICCV (2025)
Wang, Q., Ye, V., Gao, H., Zeng, W., Austin, J., Li, Z., Kanazawa, A.: Shape of motion: 4d reconstruction from a single video. In: ICCV (2025)
2025
-
[76]
In: AAAI (2025)
Wang, S., Yang, X., Shen, Q., Jiang, Z., Wang, X.: Gflow: Recovering 4d world from monocular video. In: AAAI (2025)
2025
-
[77]
In: CVPR (2025)
Wu, D., Liu, F., Hung, Y.H., Qian, Y., Zhan, X., Duan, Y.: 4d-fly: Fast 4d recon- struction from a single monocular video. In: CVPR (2025)
2025
-
[78]
arXiv preprint arXiv:2310.08528 (2023)
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. arXiv preprint arXiv:2310.08528 (2023)
-
[79]
In: CVPR (2024)
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: CVPR (2024)
2024
-
[80]
arXiv preprint (2024)
Wu, R., Gao, R., Poole, B., Trevithick, A., Zheng, C., Barron, J.T., Holynski, A.: Cat4d: Create anything in 4d with multi-view video diffusion models. arXiv preprint (2024)
2024
-
[81]
arXiv preprint arXiv:2307.03177 (2023) 20 Y
Wu, T., Zheng, C., Cham, T.J.: Panodiffusion: 360-degree panorama outpainting via diffusion. arXiv preprint arXiv:2307.03177 (2023) 20 Y. Yang et al
-
[82]
arXiv preprint (2025)
Wu, T., Yang, S., Po, R., Xu, Y., Liu, Z., Lin, D., Wetzstein, G.: Video world models with long-term spatial memory. arXiv preprint (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.