PairCoder++: Pair Programming as a Universal Paradigm for Verified Code-Driven Multimodal and Structured-Artifact Generation
Pith reviewed 2026-07-03 15:13 UTC · model grok-4.3
The pith
Pair programming between Driver and Navigator agents, grounded in toolchain verification evidence, raises success rates on code-driven generation of structured artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
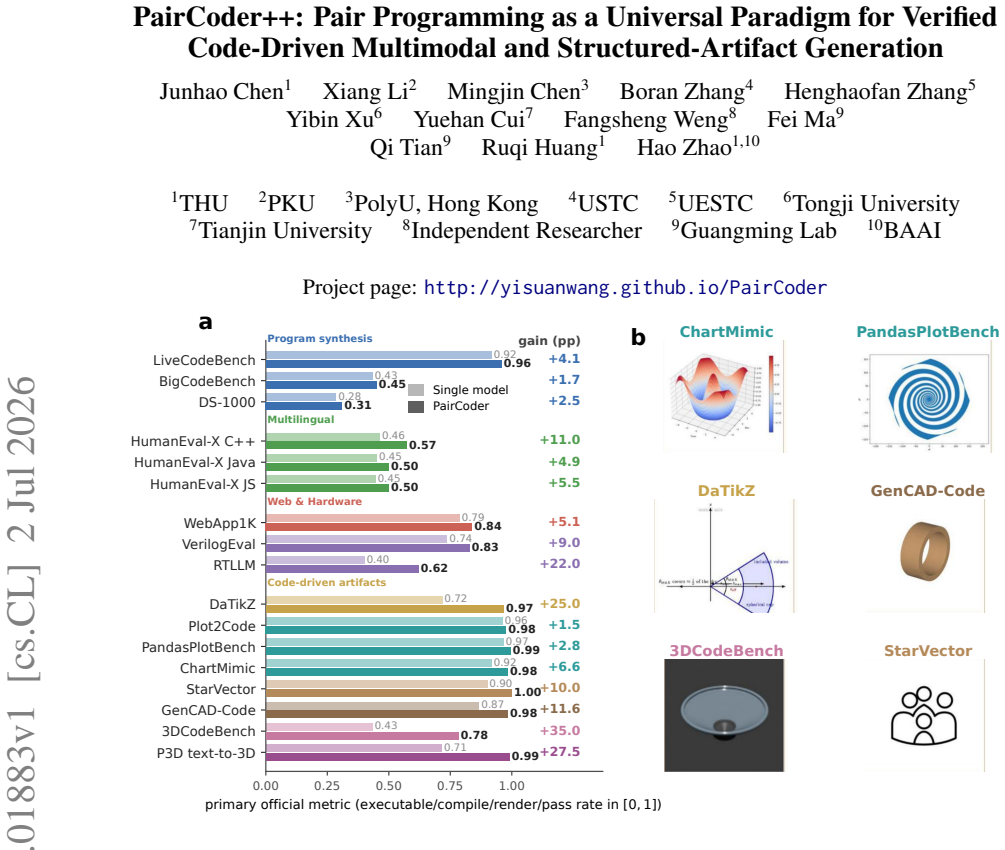
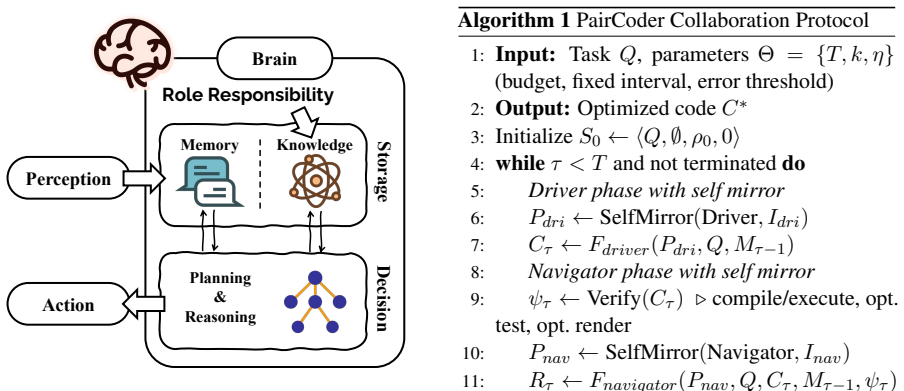
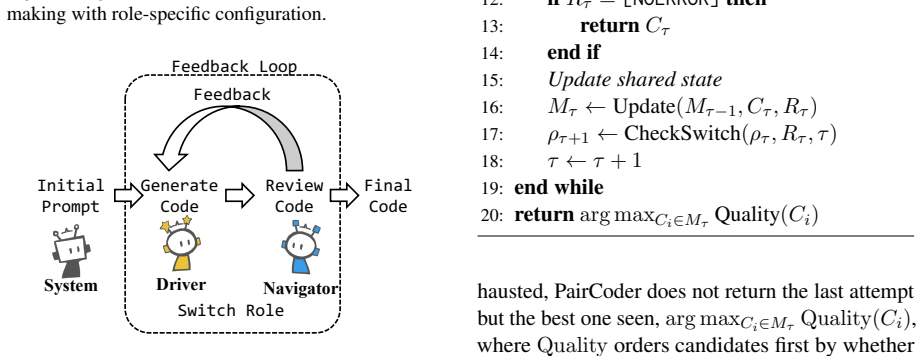
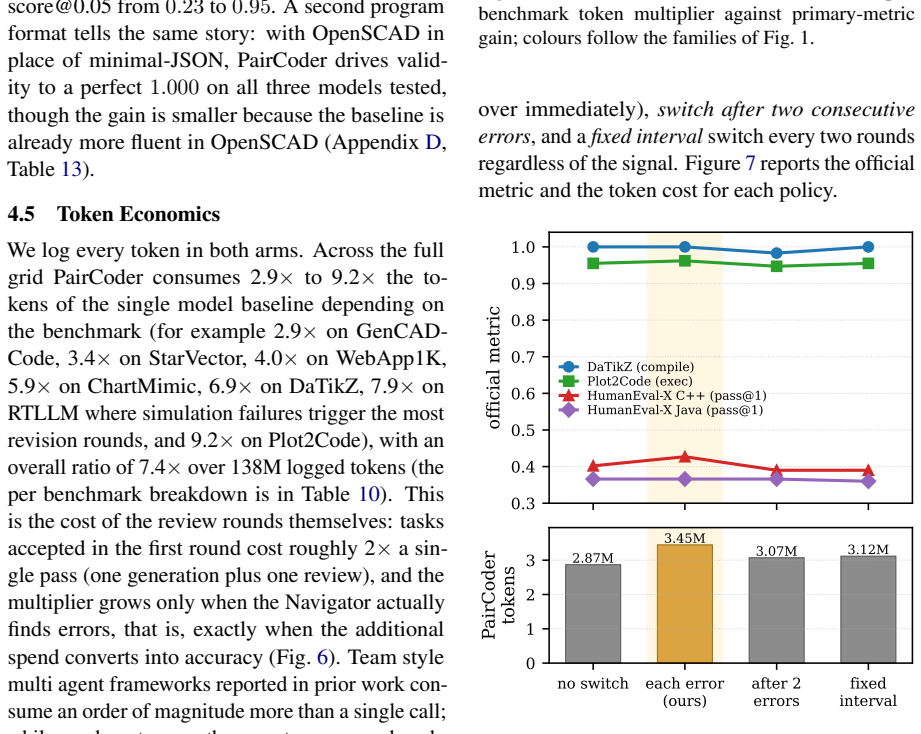
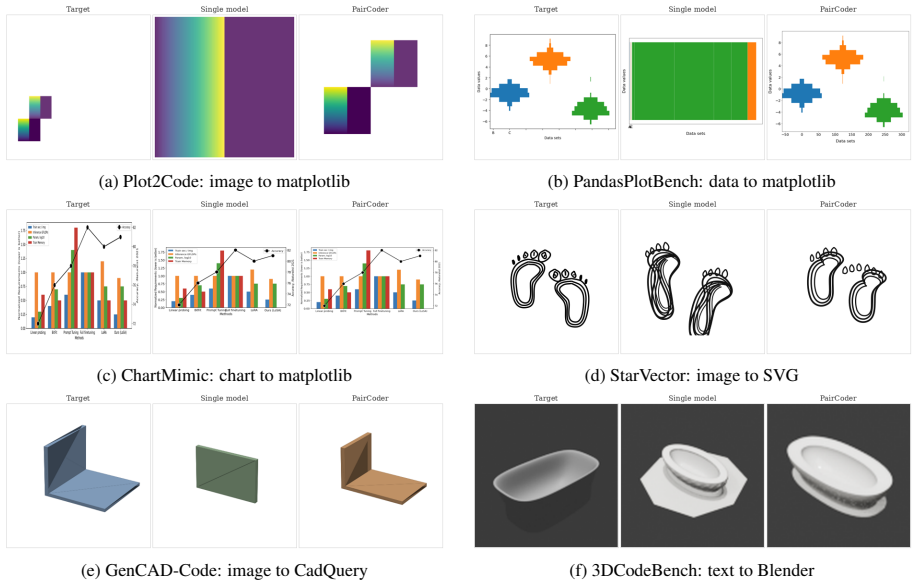
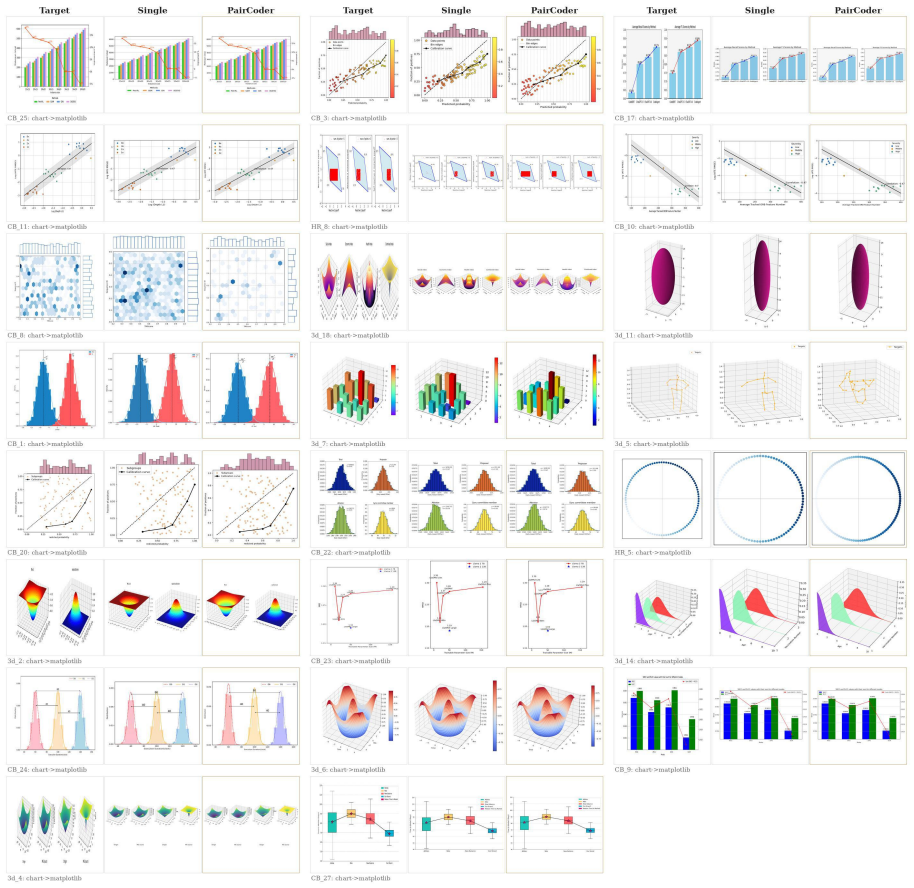
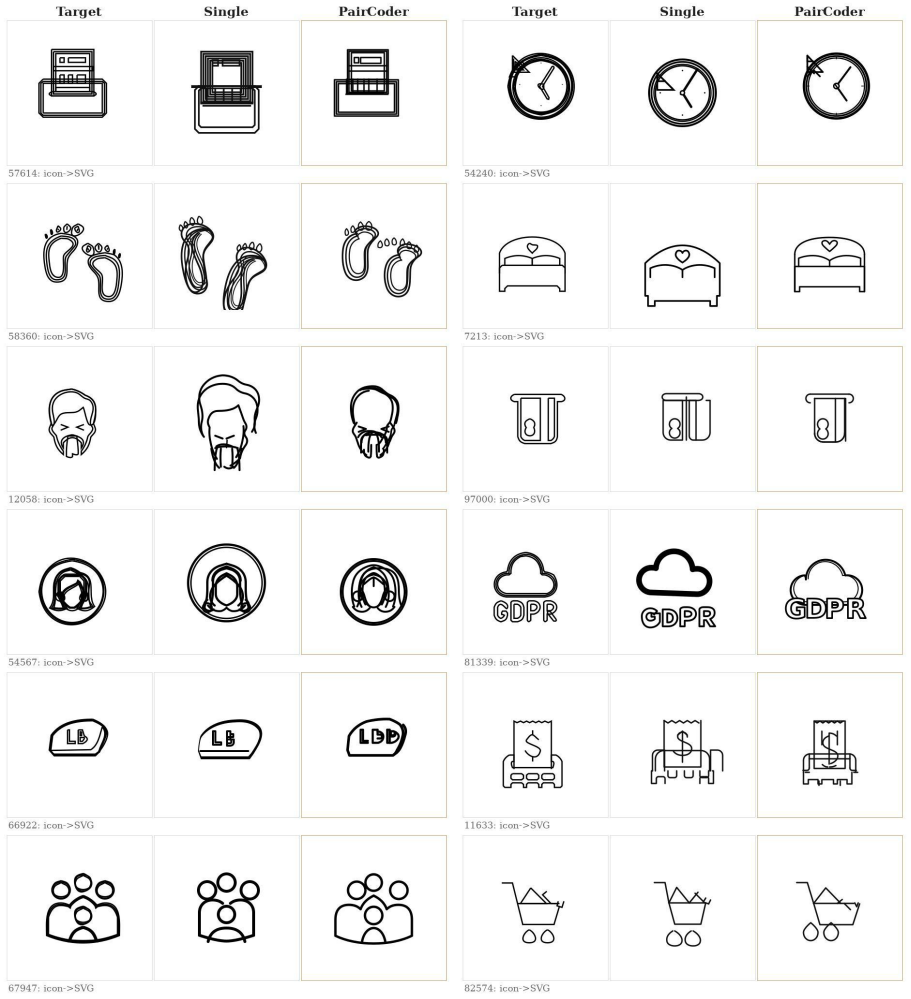
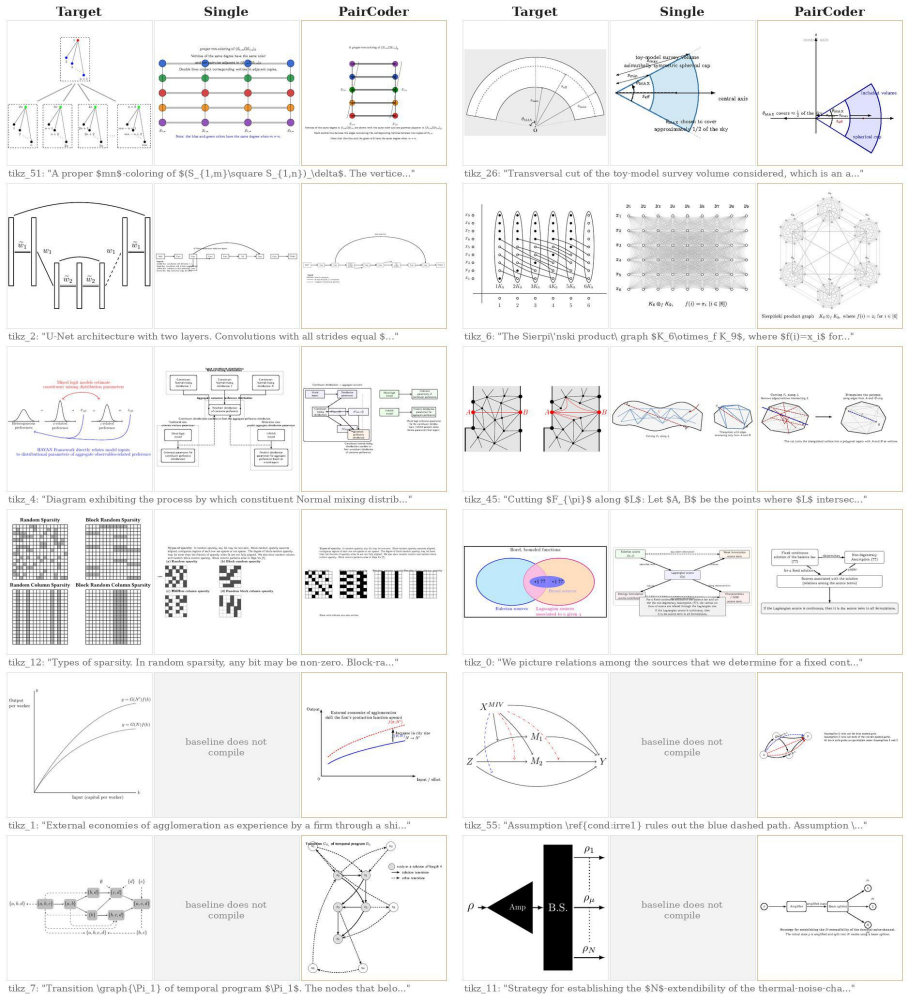
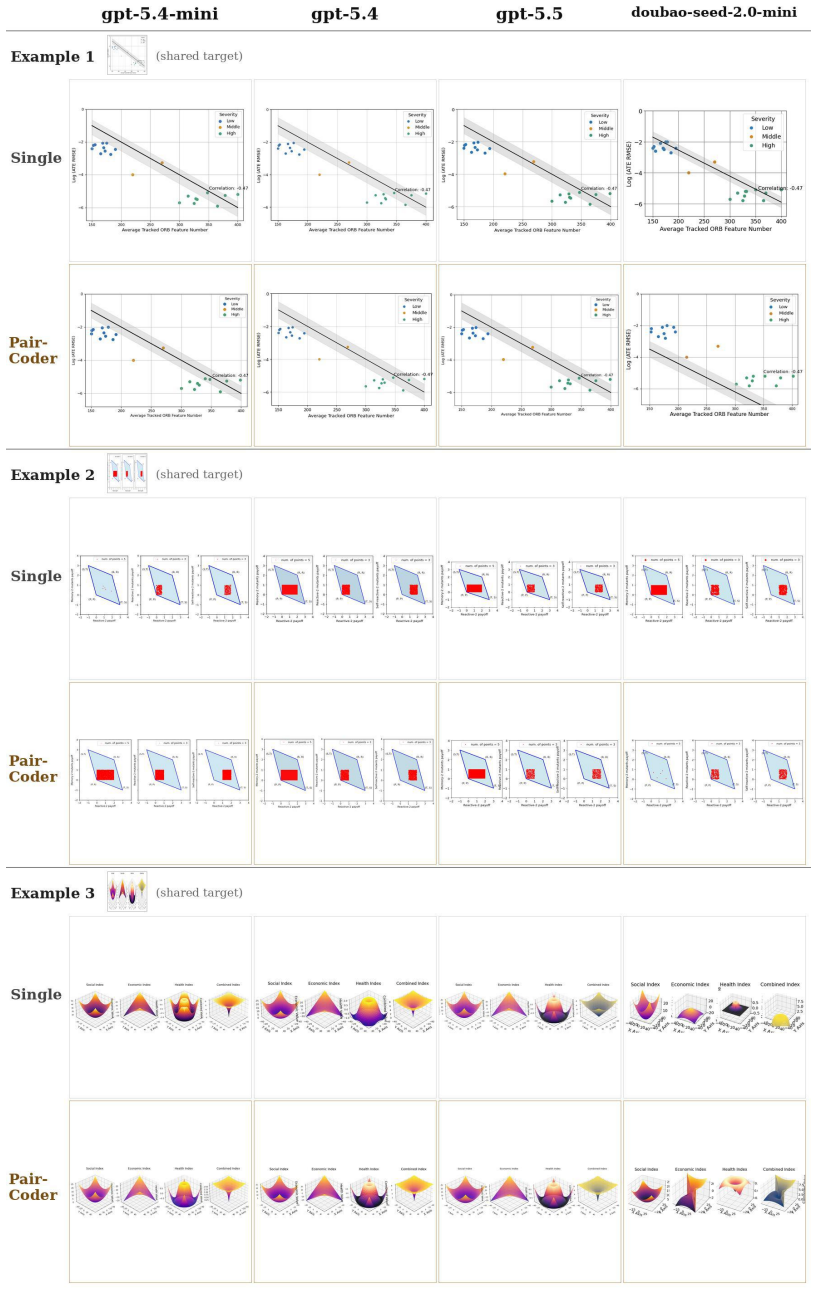
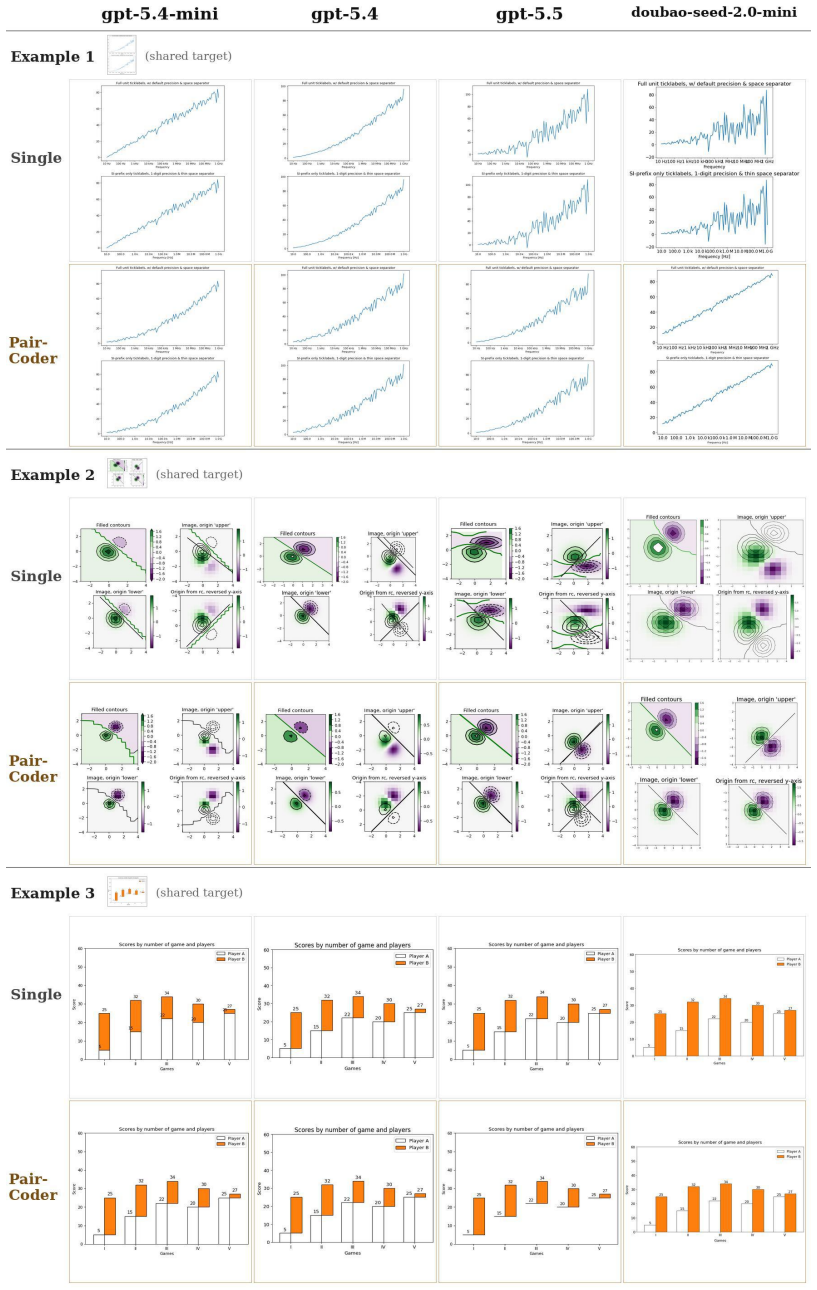
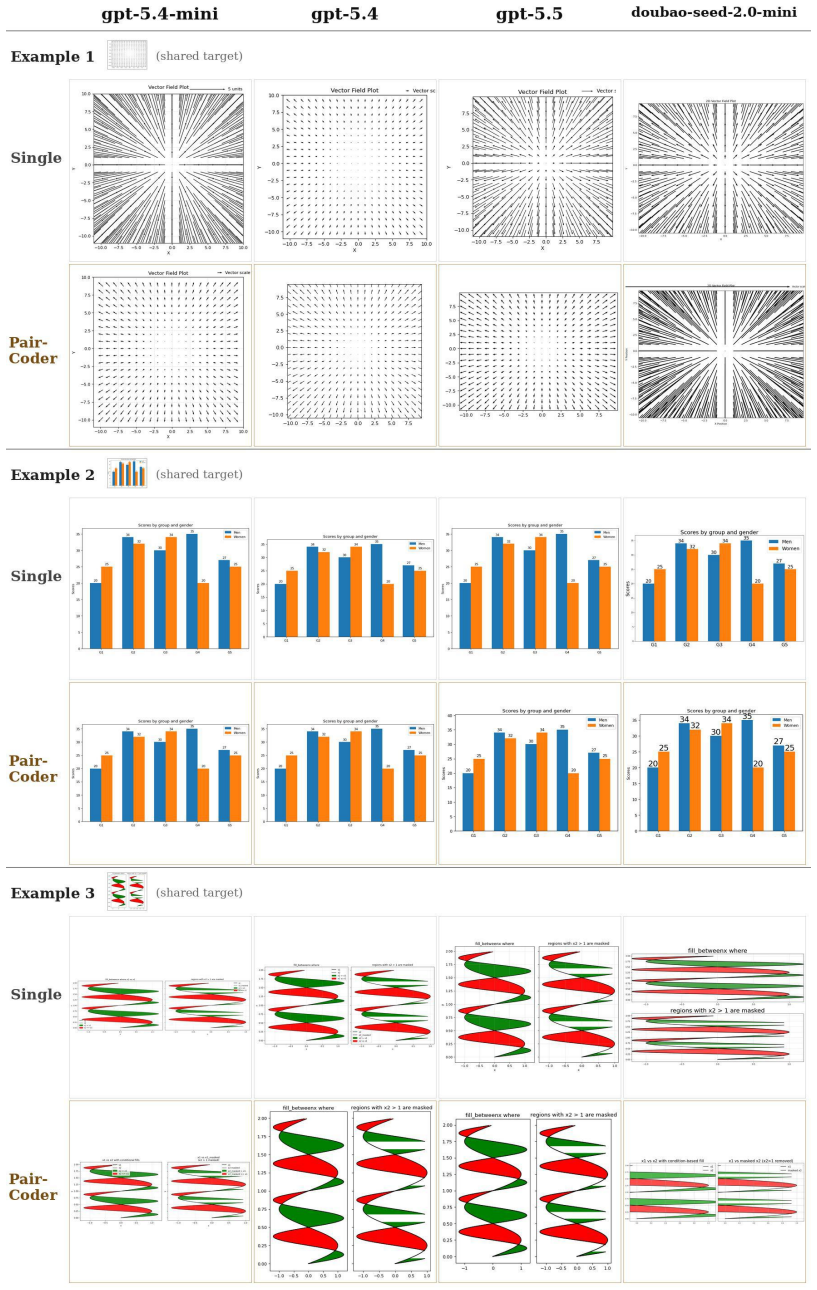
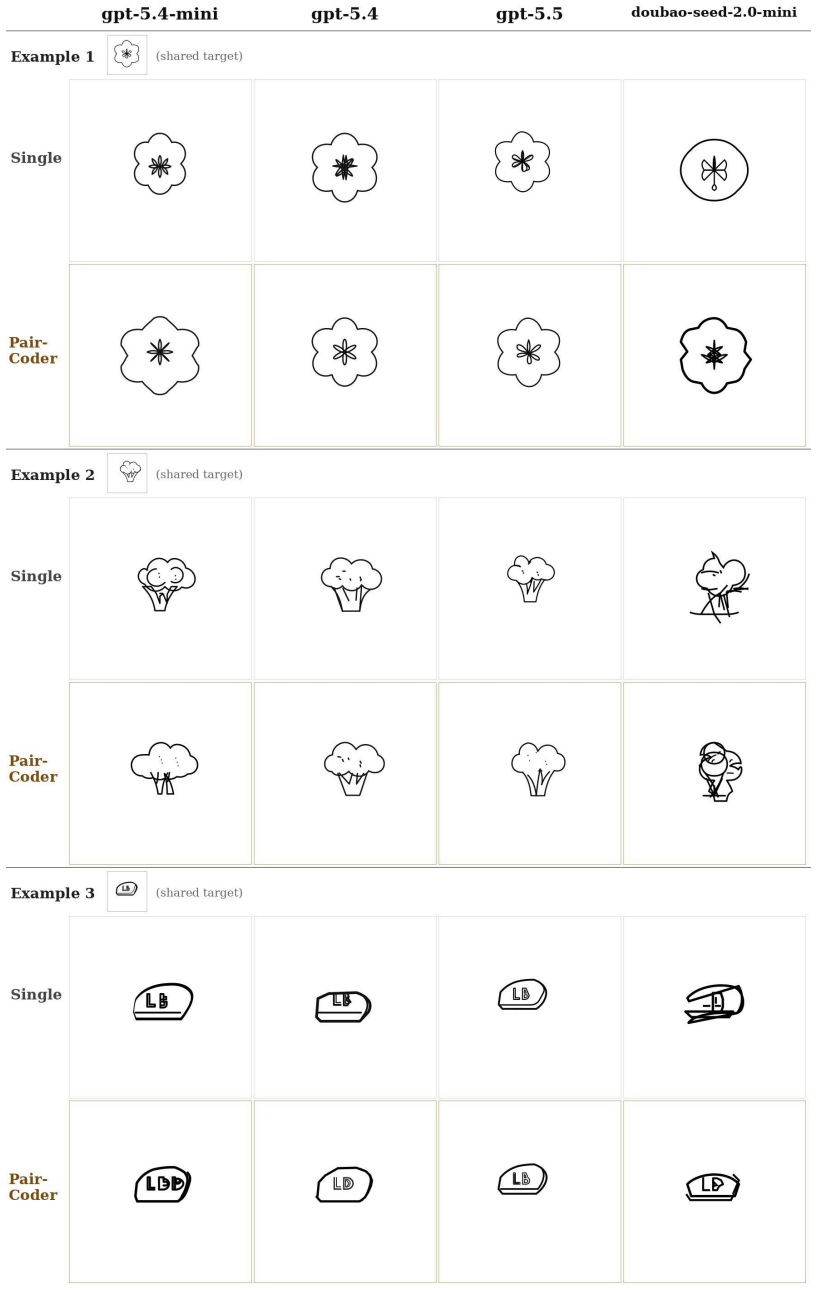
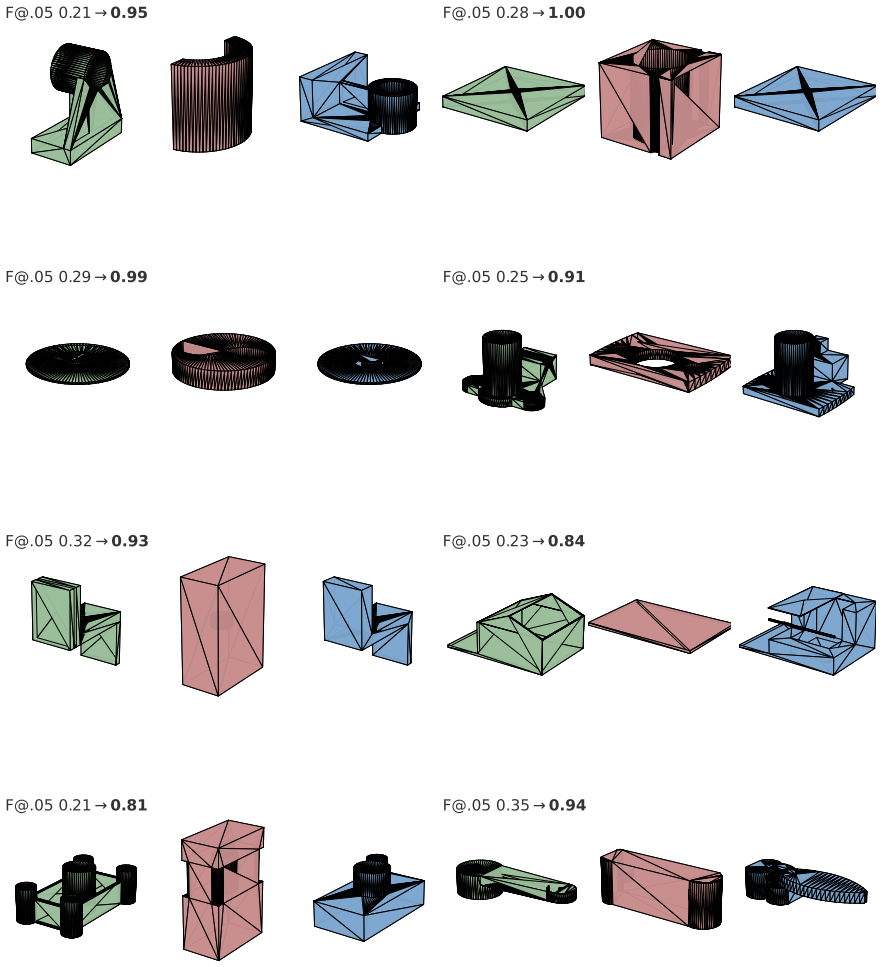
PairCoder realizes review through two-agent pair programming in which a Driver agent generates the program and a Navigator agent critiques it against verification evidence consisting of diagnostics, execution results, and renderings of the current artifact beside the target; the agents switch roles when errors persist. Across 17 benchmarks and seven models this yields consistent gains on every benchmark whose artifact is verifiable, measured on full official metric suites, at 2.9 to 9.2 times single-model cost, with the largest improvements where the baseline leaves headroom and the oracle is informative.
What carries the argument
The Driver-Navigator pair programming loop that uses toolchain-provided verification evidence (diagnostics, execution results, renderings) to drive corrections and triggers role switches on persistent errors.
If this is right
- Improvements concentrate on benchmarks that supply informative oracles and where single-model baselines leave headroom.
- The method ties or mildly regresses on tasks where the oracle is weak.
- Gains are measured on full official metric suites rather than execution success alone.
- Pair programming serves as a reliable recipe for verified code-driven generation of charts, figures, vector graphics, CAD models, 3D scenes, and hardware designs.
Where Pith is reading between the lines
- If toolchain oracles were strengthened with richer feedback signals, the same agent roles might achieve further gains without additional model calls.
- The approach could be tested on code-generation tasks outside artifact creation, such as algorithmic problem solving, to see whether the oracle-and-role-switch pattern transfers.
- Cost multipliers might be reduced by limiting the number of role switches or by using smaller models for the Navigator role once an informative oracle is available.
Load-bearing premise
The toolchain must supply an informative oracle that the Navigator agent can reliably interpret and that role switching will resolve persistent errors when the oracle is present.
What would settle it
A benchmark in which the oracle supplies no usable diagnostics or renderings, or in which repeated role switches still leave errors uncorrected, would produce no improvement or a regression relative to single-model baselines.
Figures








read the original abstract
Code is the medium through which large language models generate structured artifacts: charts, scientific figures, vector graphics, CAD models, 3D scenes, and hardware designs are all produced by writing programs. In this regime single pass inference is brittle, because the compiler, renderer, or simulator that decides whether the artifact exists is invisible to the model. We present PairCoder, which grounds review in the toolchain and realizes it as two agent pair programming: a Driver agent writes the program, a Navigator agent reviews it against verification evidence (diagnostics, execution results, and renderings of the current artifact beside the target), and the two switch roles when errors persist. Across 17 public benchmarks and seven models from three vendors, PairCoder improves essentially every benchmark whose artifact is verifiable, on full official metric suites rather than execution alone (for example, Blender scene executability 0.20 to 0.78; TikZ compile rate up 10 to 30 points on every model), at 2.9 to 9.2 times single model cost (about 7 times overall). The improvements concentrate where the toolchain provides an informative oracle and the baseline leaves headroom, and the method ties or mildly regresses where the oracle is weak; we frame pair programming as a reliable recipe for verified code driven generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PairCoder, a two-agent pair-programming system for code-driven generation of structured artifacts (charts, TikZ, Blender scenes, CAD, etc.). A Driver agent emits code while a Navigator agent reviews it against toolchain oracles (diagnostics, execution output, renderings); the agents switch roles on persistent errors. Across 17 public benchmarks and seven models the method is reported to raise official metrics on every verifiable-artifact task (e.g., Blender executability 0.20 o0.78, TikZ compile rate +10–30 points) at 2.9–9.2 imes single-model cost, with gains concentrated where the oracle is informative.
Significance. If the causal contribution of the pair-programming structure can be isolated, the work supplies a concrete, broadly applicable recipe for grounding LLM generation in external verifiers rather than internal model confidence. The scale of the evaluation (17 benchmarks, multiple vendors) would make the result a useful reference point for agentic code-generation research.
major comments (2)
- [Experimental Results] Experimental Results section: the headline gains (Blender 0.20 o0.78, TikZ +10–30 points) are presented without ablations that hold total inference budget fixed while removing either the explicit Driver/Navigator division or the role-switching rule. Consequently it remains unclear whether the reported improvements require the pair-programming architecture or would be obtained by simply allocating the same extra model calls to a single agent.
- [Method] Method section: the central assumption that the Navigator can reliably translate toolchain renderings and diagnostics into actionable edits is stated but not quantified. No success-rate statistics on oracle interpretation, no failure-case analysis, and no comparison of continued single-agent turns versus forced role switches are supplied, leaving the load-bearing mechanism untested.
minor comments (3)
- [Abstract] Abstract: the title contains “PairCoder++” while the text consistently refers to “PairCoder”; the relationship between the two should be clarified.
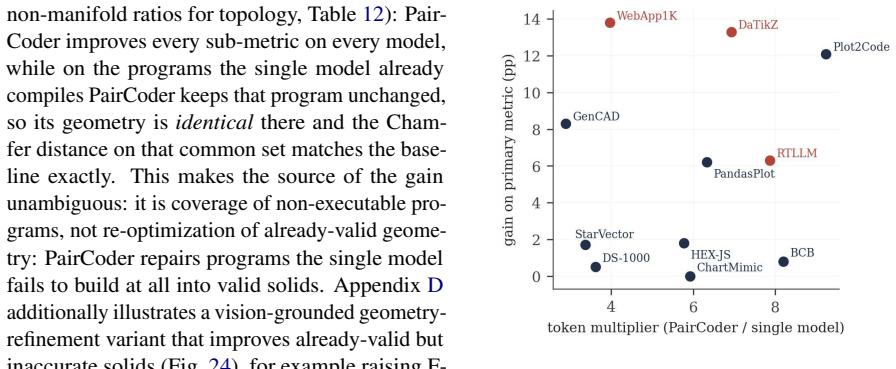
- [Experimental Results] The cost multiplier is given only as a range (2.9–9.2 imes); a per-benchmark or per-model table would allow readers to assess whether the overhead is uniform or driven by a few hard cases.
- [Experimental Results] No error bars, statistical significance tests, or dataset-split details are mentioned; these should be added to the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each of the major comments below.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the headline gains (Blender 0.20 to 0.78, TikZ +10–30 points) are presented without ablations that hold total inference budget fixed while removing either the explicit Driver/Navigator division or the role-switching rule. Consequently it remains unclear whether the reported improvements require the pair-programming architecture or would be obtained by simply allocating the same extra model calls to a single agent.
Authors: We agree that an ablation holding the inference budget fixed would help isolate the contribution of the pair-programming structure. The current results report performance at increased cost (2.9–9.2 times), but do not directly compare to a single agent with equivalent calls. In the revised manuscript, we will add such an ablation study, comparing PairCoder to a single-agent setup with the same total number of model invocations, to determine if the structured roles and switching provide benefits beyond additional computation. revision: yes
-
Referee: [Method] Method section: the central assumption that the Navigator can reliably translate toolchain renderings and diagnostics into actionable edits is stated but not quantified. No success-rate statistics on oracle interpretation, no failure-case analysis, and no comparison of continued single-agent turns versus forced role switches are supplied, leaving the load-bearing mechanism untested.
Authors: The manuscript indeed does not include quantitative metrics on the Navigator's interpretation success or detailed failure analysis of role switches. We will revise the Method and Experimental Results sections to include: (1) statistics on how often Navigator edits lead to error reduction, (2) analysis of role-switch frequency and its correlation with progress, and (3) a comparison of performance when role-switching is disabled (i.e., continued single-agent turns). This will provide evidence on the effectiveness of the oracle-driven review mechanism. revision: yes
Circularity Check
No circularity; empirical method grounded in external toolchain oracles
full rationale
The paper presents PairCoder as an agent-based pair-programming method (Driver writes code; Navigator reviews against diagnostics/execution/renderings) and reports empirical gains on 17 benchmarks across models. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claim is validated against external verifiable artifacts and official metrics rather than reducing to internal definitions or self-referential logic by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IW -Bench: Evaluating Large Multimodal Models for Converting Image-to-Web
Guo, Hongcheng and Zhang, Wei and Chen, Junhao and Gu, Yaonan and Yang, Jian and Du, Junjia and Cao, Shaosheng and Hui, Binyuan and Liu, Tianyu and Ma, Jianxin and Zhou, Chang and Li, Zhoujun. IW -Bench: Evaluating Large Multimodal Models for Converting Image-to-Web. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v...
-
[2]
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ , url =
Belouadi, Jonas and Ponzetto, Simone Paolo and Eger, Steffen , booktitle =. DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ , url =. doi:10.52202/079017-2701 , editor =
-
[3]
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes , author=. arXiv preprint arXiv:2602.09153 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2026 , eprint=
One Video, One World: Turning Monocular Video into Physical 4D Scenes , author=. 2026 , eprint=
2026
-
[5]
arXiv preprint arXiv:2409.16294 , year=
GenCAD: Image-Conditioned Computer-Aided Design Generation with Transformer-Based Contrastive Representation and Diffusion Priors , author=. arXiv preprint arXiv:2409.16294 , year=
-
[6]
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features , author=. arXiv preprint arXiv:2502.14786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
The Twelfth International Conference on Learning Representations , year=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
International Conference on Machine Learning , year=
SceneCraft: An LLM Agent for Synthesizing 3D Scenes as Blender Code , author=. International Conference on Machine Learning , year=
-
[10]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Metagpt: Meta programming for multi-agent collaborative framework , author=. arXiv preprint arXiv:2308.00352 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Machine Vision and Applications , volume=
Ultraman: ultra-fast and high-resolution texture generation for 3D human reconstruction from a single image , author=. Machine Vision and Applications , volume=. 2026 , publisher=
2026
-
[12]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
International Conference on Machine Learning , pages=
LEVER: Learning to Verify Language-to-Code Generation with Execution , author=. International Conference on Machine Learning , pages=
-
[14]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. arXiv preprint arXiv:2308.08155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Advances in neural information processing systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in neural information processing systems , volume=
-
[16]
Proceedings of the ACM on Software Engineering , volume=
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[17]
The Thirteenth International Conference on Learning Representations , year=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
ChatDev: Communicative Agents for Software Development
Communicative agents for software development , author=. arXiv preprint arXiv:2307.07924 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
expert--expert , author=
Pair programming productivity: Novice--novice vs. expert--expert , author=. International Journal of Human-computer studies , volume=. 2006 , publisher=
2006
-
[20]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
The Twelfth International Conference on Learning Representations , year=
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
arXiv preprint arXiv:2305.02309 , year=
Codegen2: Lessons for training llms on programming and natural languages , author=. arXiv preprint arXiv:2305.02309 , year=
-
[23]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[25]
Fangsheng Weng and Junhao Chen and Xiang Li and Jie Qin and Hanzhong Guo and ShaochunHao and Xiaoguang Han , booktitle=. Garment. 2026 , url=
2026
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Sun, Mingze and Chen, Junhao and Dong, Junting and Chen, Yurun and Jiang, Xinyu and Mao, Shiwei and Jiang, Puhua and Wang, Jingbo and Dai, Bo and Huang, Ruqi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[27]
arXiv preprint arXiv:2408.00019 , year=
WebApp1K: A Practical Code-Generation Benchmark for Web App Development , author=. arXiv preprint arXiv:2408.00019 , year=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Sun, Mingze and Zeng, Cheng and Pei, Jiansong and Chen, Junhao and Song, Chaoyue and Wang, Shaohui and Chang, Tianyuan and Huang, Bin and Zeng, Zijiao and Huang, Ruqi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Codehalu: Investigating code hallucinations in llms via execution-based verification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Generating CAD Code with Vision-Language Models for 3D Designs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Idea23d: Collaborative lmm agents enable 3d model generation from interleaved multimodal inputs , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[33]
International Conference on Artificial Neural Networks , pages=
Towards energy-efficient sentiment classification with spiking neural networks , author=. International Conference on Artificial Neural Networks , pages=. 2023 , organization=
2023
-
[34]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
GPT-3.5 Documentation
OpenAI. GPT-3.5 Documentation. 2023 , howpublished =
2023
-
[36]
2026 , eprint=
From Frames to Sequences: Temporally Consistent Human-Centric Dense Prediction , author=. 2026 , eprint=
2026
-
[37]
IEEE Transactions on Image Processing , volume=
Image Quality Assessment: From Error Visibility to Structural Similarity , author=. IEEE Transactions on Image Processing , volume=
-
[38]
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code , author=. arXiv preprint arXiv:2606.01057 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Benchmarking PhD-Level Coding in 3D Geometric Computer Vision , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
LLM s P ark: A Benchmark for Evaluating Large Language Models in Strategic Gaming Contexts
Chen, Junhao and Sun, Jingbo and Li, Xiang and Xin, Haidong and Xue, Yuhao and Xu, Yibin and Zhao, Hao. LLM s P ark: A Benchmark for Evaluating Large Language Models in Strategic Gaming Contexts. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.12
-
[41]
ACM Transactions on Software Engineering and Methodology , volume=
Self-collaboration code generation via chatgpt , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2024 , publisher=
2024
-
[42]
StarCoder: may the source be with you!
Starcoder: may the source be with you! , author=. arXiv preprint arXiv:2305.06161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems , volume=
CAMEL: Communicative Agents for ``Mind'' Exploration of Large Language Model Society , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Starvector: Generating scalable vector graphics code from images and text , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Chat2SVG: Vector Graphics Generation with Large Language Models and Image Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[46]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. arXiv preprint arXiv:2406.15877 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
The Fourteenth International Conference on Learning Representations , year=
DanceTogether: Generating Interactive Multi-Person Video without Identity Drifting , author=. The Fourteenth International Conference on Learning Representations , year=
-
[49]
2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC) , pages=
RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model , author=. 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC) , pages=
2024
-
[50]
The Thirteenth International Conference on Learning Representations , year=
Can Large Language Models Understand Symbolic Graphics Programs? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[51]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
International Conference on Machine Learning , pages=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning , pages=
-
[55]
arXiv preprint arXiv:2311.13562 , year=
Soulstyler: Using large language model to guide image style transfer for target object , author=. arXiv preprint arXiv:2311.13562 , year=
-
[56]
2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD) , pages=
VerilogEval: Evaluating Large Language Models for Verilog Code Generation , author=. 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD) , pages=
2023
-
[57]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
MMAD: Multi-modal movie audio description , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[58]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[59]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Cctest: Testing and repairing code completion systems , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
2023
-
[60]
arXiv preprint arXiv:2406.09961 , year=
ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation , author=. arXiv preprint arXiv:2406.09961 , year=
-
[61]
Design2code: Benchmarking multimodal code generation for automated front-end engineering , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[62]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Information and software technology , volume=
The effectiveness of pair programming: A meta-analysis , author=. Information and software technology , volume=. 2009 , publisher=
2009
-
[64]
Transactions on Machine Learning Research , year=
DINOv2: Learning Robust Visual Features without Supervision , author=. Transactions on Machine Learning Research , year=
-
[65]
The Twelfth International Conference on Learning Representations , year=
AutomaTikZ: Text-Guided Synthesis of Scientific Vector Graphics with TikZ , author=. The Twelfth International Conference on Learning Representations , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Matplotagent: Method and evaluation for llm-based agentic scientific data visualization , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Mingjin and Chen, Junhao and Fan, Zhaoxin and Lee, Yujian and Dang, Zichen and Wang, Lili and Cui, Yawen and Chau, Lap-Pui and Wang, Yi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[69]
arXiv preprint arXiv:2501.06598 , year=
ChartCoder: Advancing Multimodal Large Language Model for Chart-to-Code Generation , author=. arXiv preprint arXiv:2501.06598 , year=
-
[70]
arXiv preprint arXiv:2412.02764 , year=
Drawing Pandas: A Benchmark for LLMs in Generating Plotting Code , author=. arXiv preprint arXiv:2412.02764 , year=
-
[71]
arXiv preprint arXiv:2310.12945 , year=
3D-GPT: Procedural 3D Modeling with Large Language Models , author=. arXiv preprint arXiv:2310.12945 , year=
-
[72]
Proceedings of the 61st ACM/IEEE Design Automation Conference , year=
RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Model , author=. Proceedings of the 61st ACM/IEEE Design Automation Conference , year=
-
[73]
A Survey on Large Language Models for Code Generation
A survey on large language models for code generation , author=. arXiv preprint arXiv:2406.00515 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Junhao and Gao, Kejun and Cui, Yuehan and Sun, Mingze and Chen, Mingjin and Wang, Shaohui and Long, Xiaoxiao and Ma, Fei and Tian, Qi and Zhao, Hao and Huang, Ruqi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[76]
The Twelfth International Conference on Learning Representations , year=
Teaching Large Language Models to Self-Debug , author=. The Twelfth International Conference on Learning Representations , year=
-
[77]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
2026 , eprint=
Feedforward 3D Editing Learns from Semantic-Part Transformation , author=. 2026 , eprint=
2026
-
[79]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Agentcoder: Multi-agent-based code generation with iterative testing and optimisation , author=. arXiv preprint arXiv:2312.13010 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
IEEE software , volume=
Strengthening the case for pair programming , author=. IEEE software , volume=. 2000 , publisher=
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.