Understanding Geometric Representations in Self-Supervised Vision Transformers via Subspace Intervention
Pith reviewed 2026-07-03 15:33 UTC · model grok-4.3
The pith
Decomposing linear probe weights via SVD isolates low-rank subspaces carrying explicit geometric signals in self-supervised ViTs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
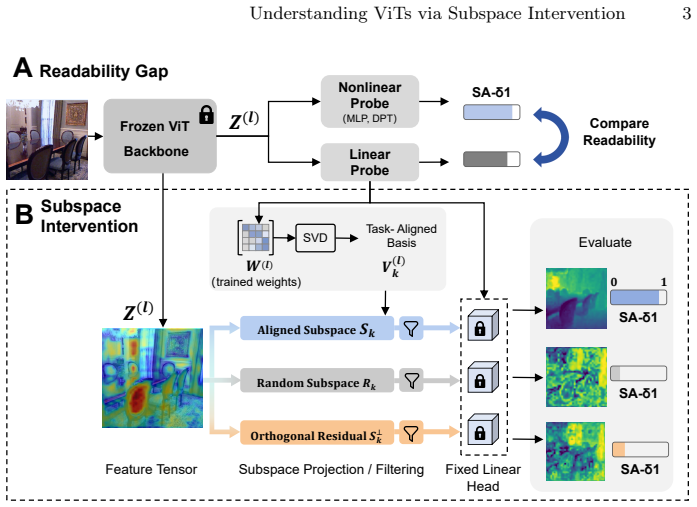
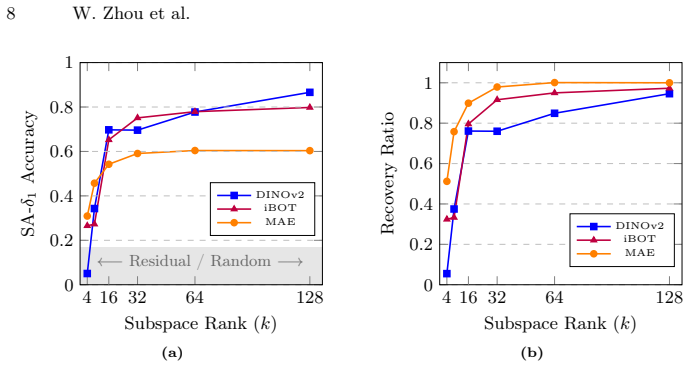
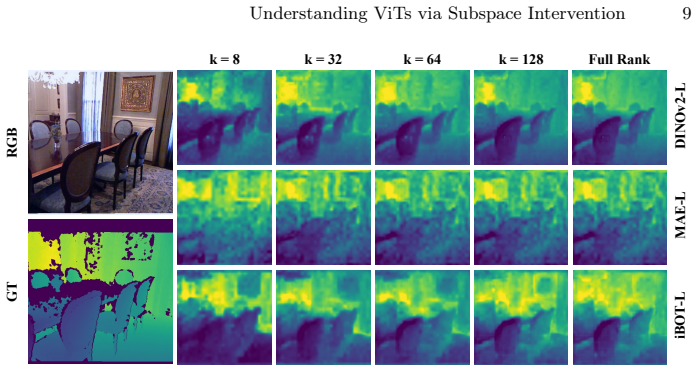
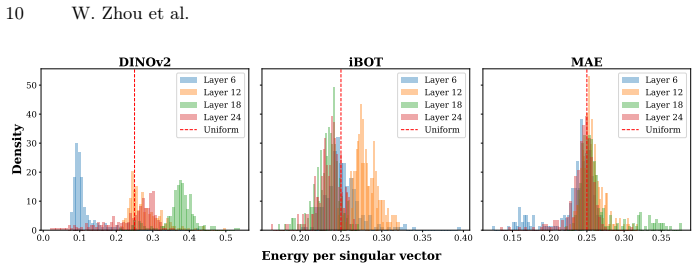
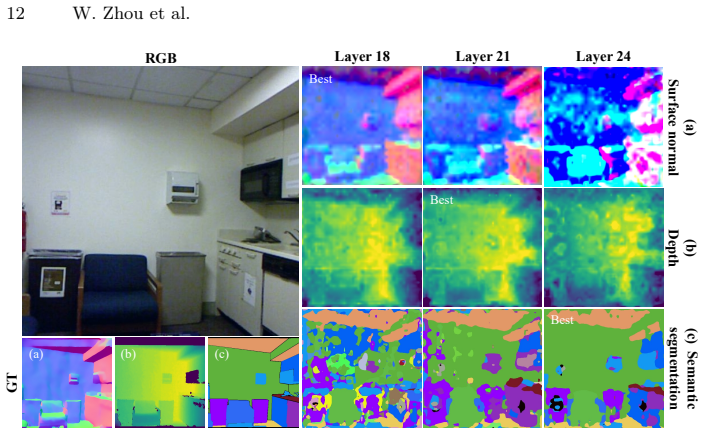
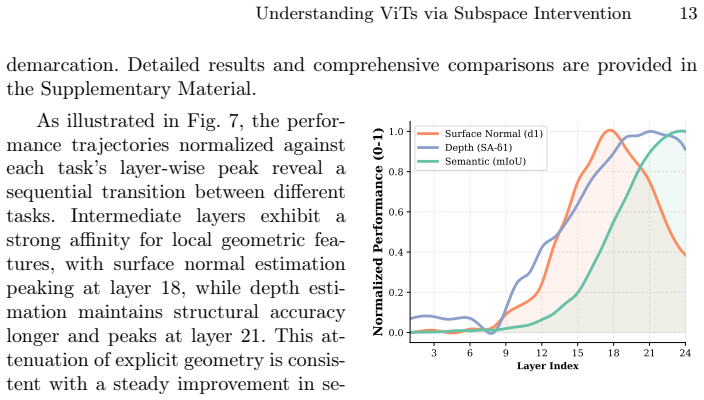
By decomposing the weights of converged linear probes via SVD, the framework isolates low-rank subspaces that contain explicit geometric signals. This yields three observations on the paper's terms: pre-training objectives determine encoding, with DINOv2 aligning spatial features for efficient linear extraction while MAE disperses signals and requires broader context; explicit geometric representations are highly compressible; and layer-wise task affinity shows geometric precision peaking at intermediate layers before yielding to semantic abstraction in final layers.
What carries the argument
Subspace intervention framework that decomposes converged linear probe weights using Singular Value Decomposition to isolate low-rank subspaces containing explicit geometric signals.
If this is right
- DINOv2 features support more efficient linear extraction of spatial information than MAE features.
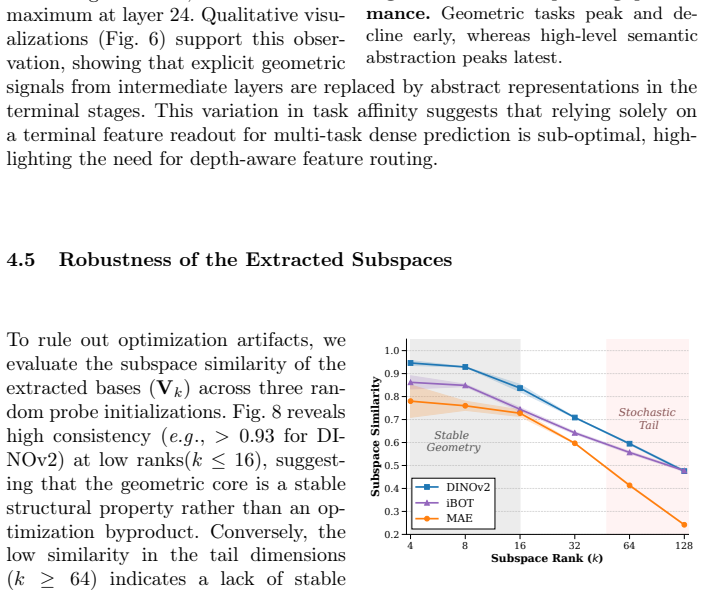
- Geometric representations remain effective when restricted to low-rank subspaces, allowing dense heads to use fewer parameters.
- Geometric task performance peaks in intermediate ViT layers rather than final layers.
- Feature selection for geometry-related tasks can target the identified subspaces without large performance loss.
Where Pith is reading between the lines
- Lightweight decoder designs for dense prediction could constrain weights to the low-rank geometric subspaces identified by the method.
- Downstream applications might select intermediate-layer features when geometry matters more than semantics.
- The intervention technique could be applied to probe other non-semantic properties encoded in the same representations.
Load-bearing premise
The decomposition of converged linear probe weights via SVD isolates the low-rank subspaces that contain explicit geometric signals in the ViT representations.
What would settle it
A controlled experiment that measures geometric task accuracy after zeroing out only the identified low-rank SVD components versus zeroing out random components of equal rank would falsify the claim if the two interventions produce equivalent drops.
Figures

read the original abstract
We introduce a controlled subspace intervention framework to investigate how self-supervised Vision Transformers (ViTs) encode dense geometric information. While linear probing is widely used to assess geometric representations, it treats features as a black box, failing to disentangle the underlying topology. To address this issue, we decompose the weights of converged linear probes to isolate the low-rank subspaces containing explicit geometric signals using Singular Value Decomposition (SVD). Our perspective yields three key insights: (1) Pre-training objectives determine how features are encoded. DINOv2 aligns spatial features for efficient linear extraction, while Masked Autoencoders (MAE) tend to disperse these signals, requiring a broader spatial context. (2) Explicit geometric representations are highly compressible, suggesting dense predictive heads could potentially be constrained to low-rank subspaces with minimal performance loss. (3) The layer-wise task affinity suggests that geometric precision peaks at intermediate layers before yielding to semantic abstraction in the final layers. By connecting internal encoding mechanics with downstream performance, these findings provide a basis for effective feature selection and lightweight decoder design. The source code is available at https://github.com/Zhou-Weichen/Geosubprobe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a subspace intervention framework to analyze how self-supervised ViTs encode dense geometric information. It decomposes converged linear probe weights via SVD to isolate low-rank subspaces containing explicit geometric signals, yielding three insights: (1) pre-training objectives determine encoding (DINOv2 aligns spatial features efficiently while MAE disperses them), (2) explicit geometric representations are highly compressible, and (3) geometric precision peaks at intermediate layers before semantic abstraction dominates.
Significance. If the SVD-based identification of geometric subspaces is validated, the framework could link internal encoding mechanics to downstream performance and support efficient feature selection or low-rank decoder designs. The public code release aids reproducibility, though the absence of quantitative results in the abstract limits immediate assessment of impact.
major comments (2)
- [Method / Abstract] The core identification assumption—that SVD on converged linear probe weights isolates low-rank subspaces specifically encoding explicit geometric signals rather than any sufficient statistic for the probe task—is untested and load-bearing for all three insights. Linear probes can exploit entangled or spurious correlations, and SVD yields an orthogonal basis ordered by probe variance without reference to original feature geometry or control tasks (see skeptic analysis and abstract description of the framework).
- [Abstract] The abstract outlines the method and states three insights but includes no numerical results, validation experiments, or details on derivation; the full manuscript must supply quantitative evidence (e.g., performance deltas under subspace intervention, compressibility curves, layer-wise metrics) to support claims about alignment, compressibility, and layer affinity.
minor comments (2)
- [Abstract] Ensure the GitHub link is explicitly stated in the abstract and methods for the claimed code release.
- [Method] Clarify notation for the probe weight matrix W, its SVD decomposition, and the resulting subspaces V_k to avoid ambiguity in the intervention procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Method / Abstract] The core identification assumption—that SVD on converged linear probe weights isolates low-rank subspaces specifically encoding explicit geometric signals rather than any sufficient statistic for the probe task—is untested and load-bearing for all three insights. Linear probes can exploit entangled or spurious correlations, and SVD yields an orthogonal basis ordered by probe variance without reference to original feature geometry or control tasks.
Authors: We acknowledge the importance of validating that the subspaces capture geometric signals specifically. The manuscript supports this through cross-model comparisons (DINOv2 vs. MAE) showing distinct encoding patterns that align with known pre-training differences, and through intervention results where subspace removal degrades geometric tasks more than controls would predict. To strengthen against concerns of spurious correlations, we will add ablations with non-geometric control probes and random subspace baselines in the revision. revision: partial
-
Referee: [Abstract] The abstract outlines the method and states three insights but includes no numerical results, validation experiments, or details on derivation; the full manuscript must supply quantitative evidence (e.g., performance deltas under subspace intervention, compressibility curves, layer-wise metrics) to support claims about alignment, compressibility, and layer affinity.
Authors: We agree that the abstract would benefit from quantitative support. We will revise it to include key metrics such as compressibility ratios from SVD, layer-wise peak accuracies, and intervention performance deltas. revision: yes
Circularity Check
No significant circularity; derivation is empirical analysis of existing models
full rationale
The paper trains linear probes on ViT features for geometric tasks, decomposes converged probe weights W via SVD to obtain subspaces V_k, and reports observational patterns across DINOv2/MAE models and layers. These steps use standard techniques (linear probing + SVD) whose outputs are not equivalent to the inputs by construction, nor justified by self-citation chains. The three insights follow from measured performance differences after subspace interventions, which remain falsifiable against held-out data and control tasks. No load-bearing step reduces to a fitted parameter renamed as prediction or an ansatz smuggled via prior work by the same authors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The weights of linear probes trained on ViT features encode geometric information in a way that SVD can isolate explicit low-rank subspaces.
Reference graph
Works this paper leans on
-
[1]
In: Annual Meeting of the Association for Computational Linguistics (2020)
Aghajanyan, A., Zettlemoyer, L., Gupta, S.: Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In: Annual Meeting of the Association for Computational Linguistics (2020)
2020
-
[2]
Understanding intermediate layers using linear classifier probes
Alain, G., Bengio, Y.: Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
arXiv preprint arXiv:2601.09954 (2026)
Alam, N., Murali, L.K., Bharadwaj, S., Liu, P., Chung, T., Sharma, D., Kiran, K., Tam, W., Vegesna, B.K.S., et al.: The spatial blindspot of vision-language models. arXiv preprint arXiv:2601.09954 (2026)
-
[4]
arXiv preprint arXiv:2112.058142(3), 4 (2021)
Amir, S., Gandelsman, Y., Bagon, S., Dekel, T.: Deep vit features as dense visual descriptors. arXiv preprint arXiv:2112.058142(3), 4 (2021)
-
[5]
In: Neural Information Processing Systems (2019)
Ansuini, A., Laio, A., Macke, J.H., Zoccolan, D.: Intrinsic dimension of data rep- resentations in deep neural networks. In: Neural Information Processing Systems (2019)
2019
-
[6]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Bae, G., Budvytis, I., Cipolla, R.: Estimating and exploiting the aleatoric uncer- tainty in surface normal estimation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 13137–13146 (2021) 16 W. Zhou et al
2021
-
[7]
arXiv preprint arXiv:2503.18762 (2025)
Bahador, N.: Mechanistic interpretability of fine-tuned vision transformers on dis- torted images: Decoding attention head behavior for transparent and trustworthy ai. arXiv preprint arXiv:2503.18762 (2025)
-
[8]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) pp
Banani, M.E., Raj, A., Maninis, K.K., Kar, A., Li, Y., Rubinstein, M., Sun, D., Guibas, L.J., Johnson, J., Jampani, V.: Probing the 3d awareness of visual founda- tion models. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) pp. 21795–21806 (2024)
2024
-
[9]
Compu- tational Linguistics48, 207–219 (2021)
Belinkov, Y.: Probing classifiers: Promises, shortcomings, and advances. Compu- tational Linguistics48, 207–219 (2021)
2021
-
[10]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Bhat, S.F., Alhashim, I., Wonka, P.: Adabins: Depth estimation using adaptive bins. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 4008–4017 (2020)
2021
-
[11]
7068–7077 (2021)
Cao, J., Leng, H., Lischinski, D., Cohen-Or, D., Tu, C., Li, Y.: Shapeconv: Shape- awareconvolutionallayerforindoorrgb-dsemanticsegmentation.2021IEEE/CVF International Conference on Computer Vision (ICCV) pp. 7068–7077 (2021)
2021
-
[12]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Caron, M., Touvron, H., Misra, I., J’egou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 9630–9640 (2021)
2021
-
[13]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Chen, X., Marks, M., Cheng, Z.: Probing the mid-level vision capabilities of self- supervised learning. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 30095–30105 (2024)
2025
-
[14]
In: International conference on machine learning
Dong, Y., Cordonnier, J.B., Loukas, A.: Attention is not all you need: Pure atten- tion loses rank doubly exponentially with depth. In: International conference on machine learning. pp. 2793–2803. PMLR (2021)
2021
-
[15]
In: Neural Information Processing Systems (2014)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: Neural Information Processing Systems (2014)
2014
-
[16]
Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
Fel, T., Wang, B., Lepori, M.A., Kowal, M., Lee, A., Balestriero, R., Joseph, S., Lubana, E.S., Konkle, T., Ba, D., et al.: Into the rabbit hull: From task-relevant concepts in dino to minkowski geometry. arXiv preprint arXiv:2510.08638 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
arXiv preprint arXiv:2410.23169 (2024)
Garrod, C., Keating, J.P.: The persistence of neural collapse despite low-rank bias. arXiv preprint arXiv:2410.23169 (2024)
-
[18]
The international journal of robotics research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research32(11), 1231–1237 (2013)
2013
-
[19]
In: 2012 IEEE conference on computer vision and pattern recognition
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 3354–3361. IEEE (2012)
2012
-
[20]
2019 IEEE/CVF International Confer- ence on Computer Vision (ICCV) pp
Goyal, P., Mahajan, D.K., Gupta, A.K., Misra, I.: Scaling and benchmarking self- supervised visual representation learning. 2019 IEEE/CVF International Confer- ence on Computer Vision (ICCV) pp. 6390–6399 (2019)
2019
-
[21]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
He, K., Chen, X., Xie, S., Li, Y., Doll’ar, P., Girshick, R.B.: Masked autoencoders are scalable vision learners. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 15979–15988 (2021)
2022
-
[22]
Hewitt, J., Liang, P.: Designing and interpreting probes with control tasks. In: Proceedings of the 2019 conference on empirical methods in natural language pro- cessing and the 9th international joint conference on natural language processing (emnlp-ijcnlp). pp. 2733–2743 (2019)
2019
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence46, 2506–2517 (2022) Understanding ViTs via Subspace Intervention 17
Huang, Z., Jin, X., Lu, C., Hou, Q., Cheng, M.M., Fu, D., Shen, X., Feng, J.: Contrastive masked autoencoders are stronger vision learners. IEEE Transactions on Pattern Analysis and Machine Intelligence46, 2506–2517 (2022) Understanding ViTs via Subspace Intervention 17
2022
-
[24]
Advances in Neural Information Processing Systems36, 76061–76084 (2023)
Jampani, V., Maninis, K.K., Engelhardt, A., Karpur, A., Truong, K., Sargent, K., Popov, S., Araujo, A., Martin Brualla, R., Patel, K., et al.: Navi: Category-agnostic image collections with high-quality 3d shape and pose annotations. Advances in Neural Information Processing Systems36, 76061–76084 (2023)
2023
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jevtić, A., Reich, C., Wimbauer, F., Hahn, O., Rupprecht, C., Roth, S., Cre- mers, D.: Feed-forward scenedino for unsupervised semantic scene completion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6784–6796 (2025)
2025
-
[26]
arXiv preprint arXiv:2408.17059 (2024)
Khan, A., Sohail, A., Fiaz, M., Hassan, M., Afridi, T.H., Marwat, S.U., Munir, F., Ali, S., Naseem, H., Zaheer, M.Z., et al.: A survey of the self supervised learning mechanisms for vision transformers. arXiv preprint arXiv:2408.17059 (2024)
-
[27]
arXiv preprint arXiv:2602.10099 (2026)
Kumar, A., Patel, V.M.: Learning on the manifold: Unlocking standard diffusion transformers with representation encoders. arXiv preprint arXiv:2602.10099 (2026)
-
[28]
Measuring the Intrinsic Dimension of Objective Landscapes
Li, C., Farkhoor, H., Liu, R., Yosinski, J.: Measuring the intrinsic dimension of objective landscapes. arXiv preprint arXiv:1804.08838 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Advances in Neural Information Processing Systems37, 76819–76847 (2024)
Man, Y., Zheng, S., Bao, Z., Hebert, M., Gui, L., Wang, Y.X.: Lexicon3d: Probing visual foundation models for complex 3d scene understanding. Advances in Neural Information Processing Systems37, 76819–76847 (2024)
2024
-
[30]
arXiv preprint arXiv:2403.05056 (2024)
Mao, Y., Liu, J., Liu, X.: Stealing stable diffusion prior for robust monocular depth estimation. arXiv preprint arXiv:2403.05056 (2024)
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Proceedings of the National Academy of Sciences of the United States of America117, 24652 – 24663 (2020)
Papyan, V., Han, X., Donoho, D.L.: Prevalence of neural collapse during the ter- minal phase of deep learning training. Proceedings of the National Academy of Sciences of the United States of America117, 24652 – 24663 (2020)
2020
- [33]
-
[34]
arXiv preprint arXiv:2410.07687 (2024)
Patel, N., Shwartz-Ziv, R.: Learning to compress: Local rank and information com- pression in deep neural networks. arXiv preprint arXiv:2410.07687 (2024)
-
[35]
In: Annual Meeting of the Association for Computational Linguistics (2020)
Pimentel, T., Valvoda, J., Maudslay, R.H., Zmigrod, R., Williams, A., Cotterell, R.: Information-theoretic probing for linguistic structure. In: Annual Meeting of the Association for Computational Linguistics (2020)
2020
-
[36]
arXiv preprint arXiv:2104.08894 (2021)
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., Goldstein, T.: The intrinsic dimension of images and its impact on learning. arXiv preprint arXiv:2104.08894 (2021)
-
[37]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 12159– 12168 (2021)
2021
-
[38]
In: European Conference on Computer Vision (2012)
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: European Conference on Computer Vision (2012)
2012
-
[39]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotný, D.: Vggt: Visual geometry grounded transformer. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5294–5306 (2025)
2025
-
[40]
In: International conference on ma- chine learning
Wang, T., Isola, P.: Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In: International conference on ma- chine learning. pp. 9929–9939. PMLR (2020)
2020
-
[41]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Xie, Z., Geng, Z., Hu, J., Zhang, Z., Hu, H., Cao, Y.: Revealing the dark secrets of masked image modeling. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 14475–14485 (2022) 18 W. Zhou et al
2023
-
[42]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 10371–10381 (2024)
2024
-
[43]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[44]
Advances in Neural Information Pro- cessing Systems 37 (2023)
Zhan, G., Zheng, C., Xie, W., Zisserman, A.: A general protocol to probe large vision models for 3d physical understanding. Advances in Neural Information Pro- cessing Systems 37 (2023)
2023
-
[45]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Zhang, J., Herrmann, C., Hur, J., Chen, E., Jampani, V., Sun, D., Yang, M.H.: Telling left from right: Identifying geometry-aware semantic correspondence. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 3076–3085 (2023)
2024
-
[46]
Advances in Neural Information Processing Systems35, 27127–27139 (2022)
Zhang, Q., Wang, Y., Wang, Y.: How mask matters: Towards theoretical under- standings of masked autoencoders. Advances in Neural Information Processing Systems35, 27127–27139 (2022)
2022
-
[47]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.