InduceKV: Fixed-Footprint Continual Adaptation of Multimodal LLMs via Inducing KV Memories
Pith reviewed 2026-07-03 13:39 UTC · model grok-4.3
The pith
InduceKV stores selected training prefixes as compact KV memories to enable continual adaptation of multimodal LLMs under a fixed memory budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
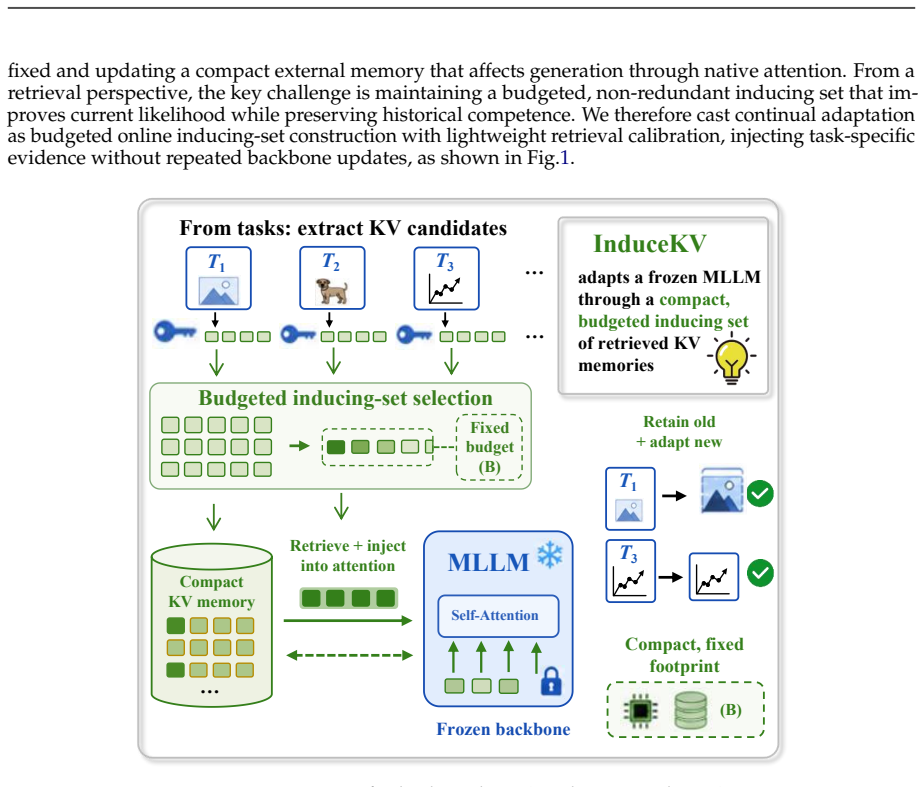
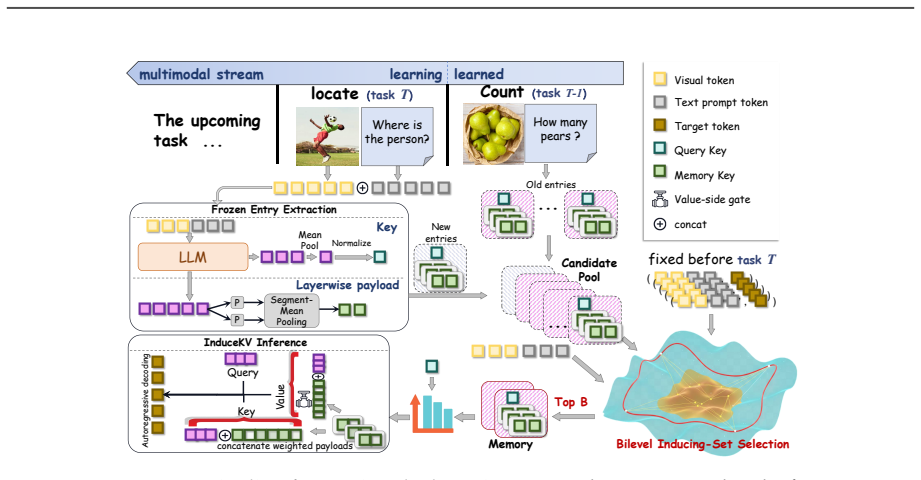
InduceKV constructs a compact inducing set of KV memories through bilevel selection, where a lightweight calibration fits retrieval while the selected memories balance current-task likelihood, anchor-based retention, and coverage in the frozen retrieval space, allowing the backbone to remain frozen and the adaptation state to stay bounded.
What carries the argument
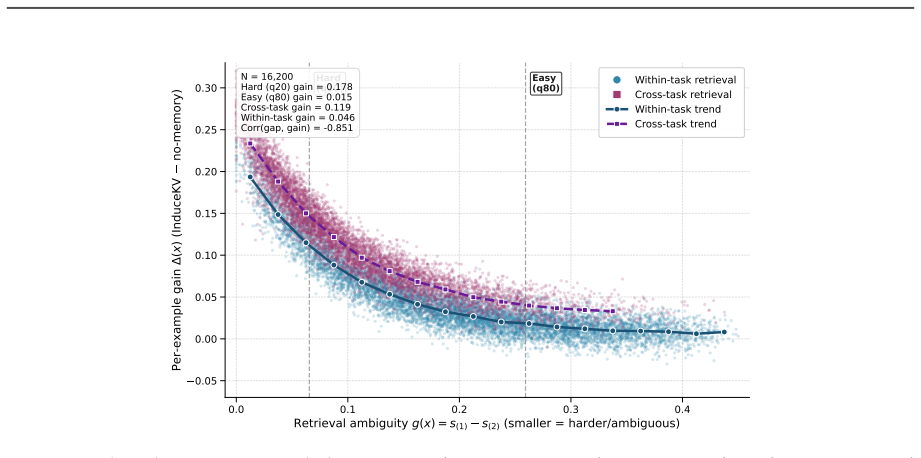
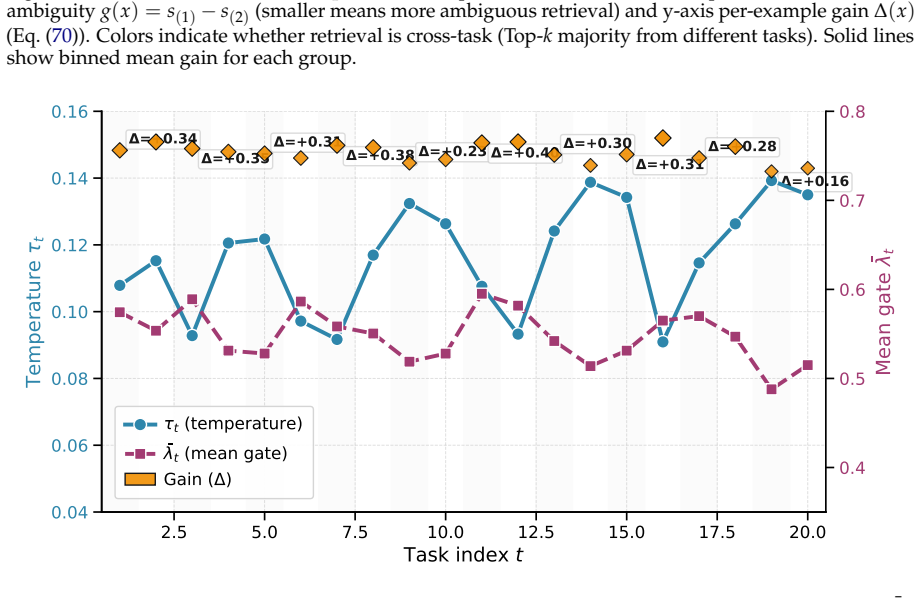
Bilevel selection procedure that produces a compact inducing set of attention-ready KV memory entries from training prefixes.
If this is right
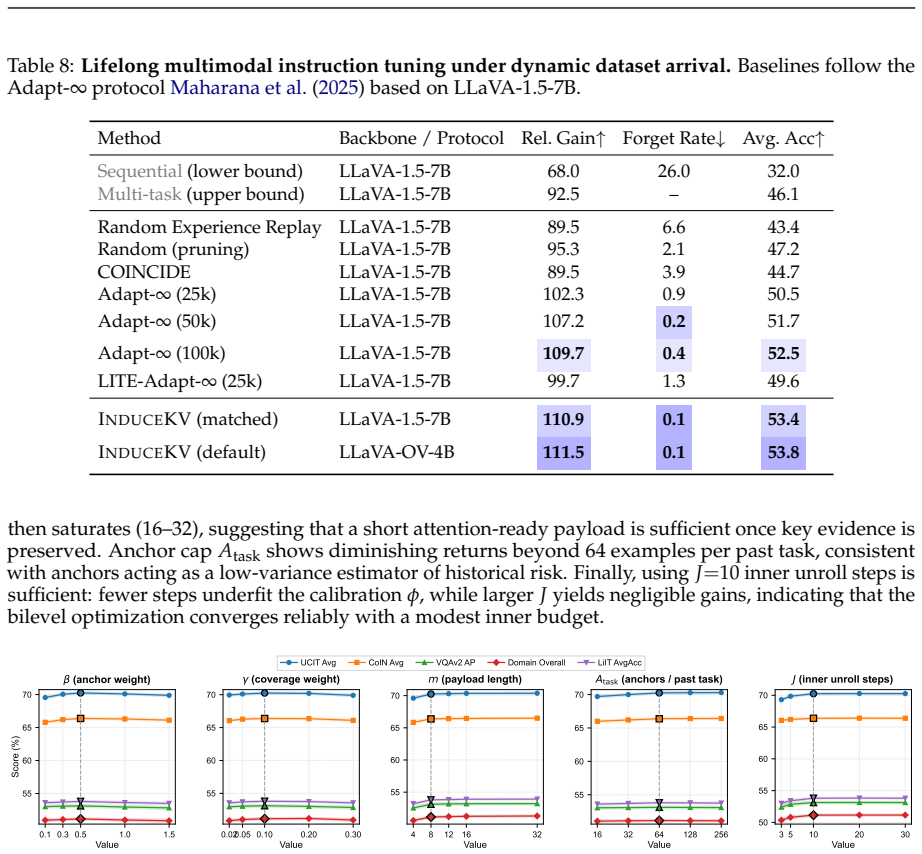
- Consistent outperformance over PEFT, MoE, replay, and prompt-retrieval baselines under matched memory budgets holds across task-incremental instruction tuning, continual VQA, domain-incremental adaptation, and lifelong multimodal instruction tuning.
- Gains remain after controlling for backbone strength, stage-1 CoIN, compute matching, and candidate-pool size.
- Adaptation state stays bounded while the backbone model itself receives no updates.
- The method externalizes task-specific state into retrieval-ready KV payloads rather than parameter changes or growing replay buffers.
Where Pith is reading between the lines
- The separation of adaptation state into fixed KV memories could simplify deployment across hardware with strict memory limits.
- If the inducing set remains effective as task count grows, the approach may reduce reliance on replay buffers in other continual-learning regimes.
- The bilevel balancing of likelihood, retention, and coverage might generalize to selecting memories for non-multimodal instruction streams.
Load-bearing premise
The bilevel selection reliably produces a compact inducing set whose performance holds when the backbone model stays frozen and no parameters are updated.
What would settle it
A head-to-head comparison under identical memory budgets in which InduceKV fails to improve over at least one of the PEFT, MoE, replay, or prompt-retrieval baselines in any of the four reported continual adaptation settings.
Figures
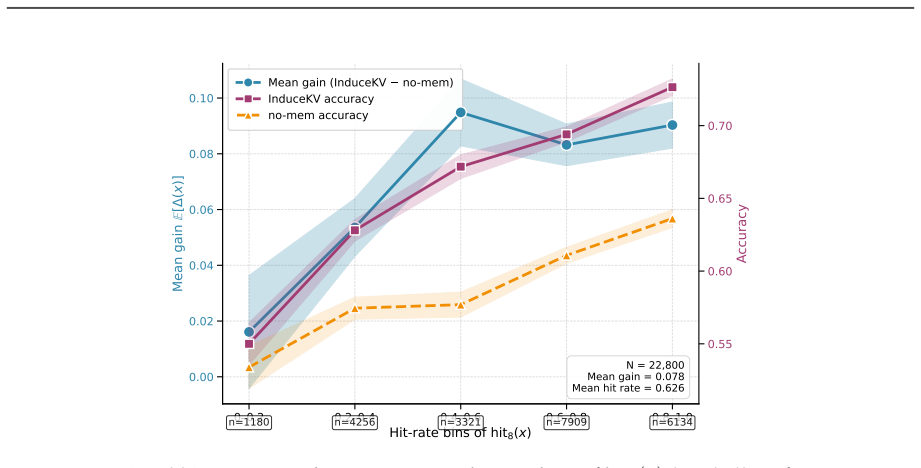
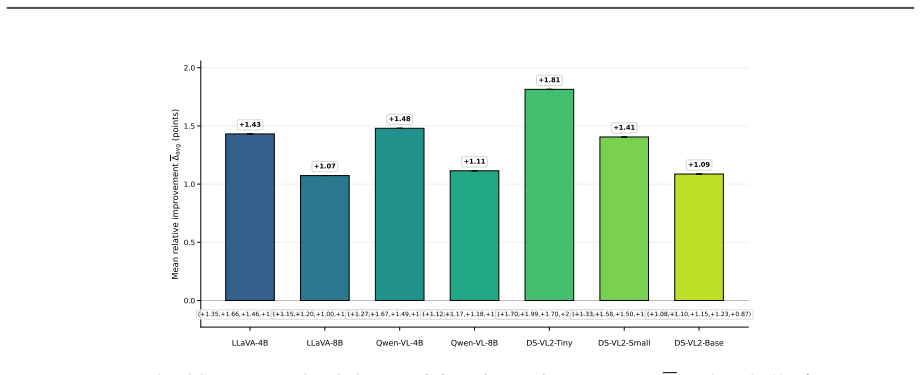
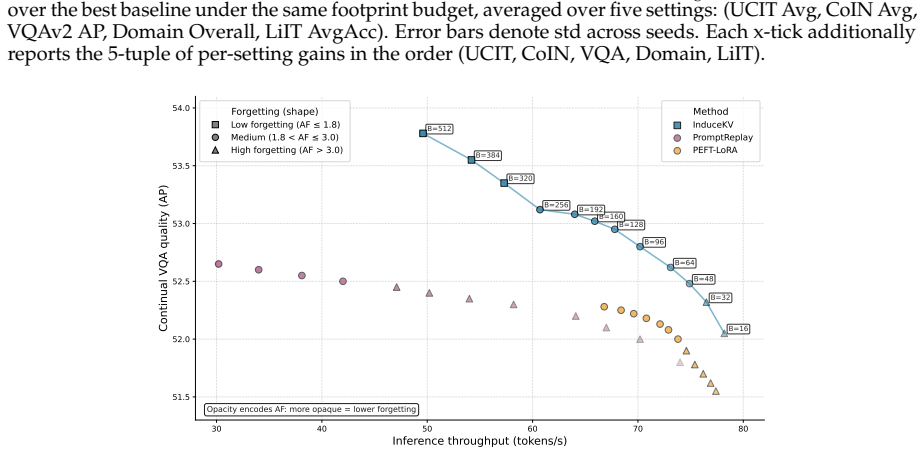
read the original abstract
Multimodal large language models must adapt to evolving tasks and domains, yet continual improvement under bounded deployment footprint remains difficult because repeated parameter updates or growing replay stores can accumulate adaptation state over time. We study fixed-footprint continual adaptation: the deployed adaptation state is kept under a fixed memory budget, while the backbone model is left unchanged and task-specific updates are externalized. We propose InduceKV, a retrieval-based method that stores each selected training prefix as an attention-ready memory entry, consisting of a frozen retrieval key and compact layerwise key--value (KV) payloads that can be appended to the model's self-attention cache. Under a strict memory budget, InduceKV constructs a compact inducing set through bilevel selection: a lightweight calibration is fit for retrieval, while the selected memory balances current-task likelihood, anchor-based retention, and coverage in the frozen retrieval space. Across task-incremental instruction tuning, continual VQA, domain-incremental adaptation, and lifelong multimodal instruction tuning, InduceKV consistently improves over PEFT, MoE, replay, and prompt-retrieval baselines under matched memory budgets. We further report backbone-matched, stage-1 CoIN, compute-matched, and scalability diagnostics, showing that the gains are not due to a stronger backbone, replay alone, or an unbounded candidate pool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InduceKV, a retrieval-based approach for fixed-footprint continual adaptation of multimodal LLMs. It externalizes task-specific state by storing selected training prefixes as attention-ready memory entries consisting of a frozen retrieval key and compact layerwise KV payloads that append to the self-attention cache. A bilevel selection procedure (lightweight calibration for retrieval keys plus balancing of current-task likelihood, anchor-based retention, and coverage) constructs a compact inducing set under a strict memory budget while leaving the backbone frozen. The central claim is that InduceKV yields consistent gains over PEFT, MoE, replay, and prompt-retrieval baselines across task-incremental instruction tuning, continual VQA, domain-incremental adaptation, and lifelong multimodal instruction tuning, with additional backbone-matched, compute-matched, and scalability diagnostics ruling out alternative explanations.
Significance. If the results hold under the reported controls, the work would provide a concrete mechanism for bounded-memory continual adaptation without parameter growth or unbounded replay, which is practically relevant for deployed multimodal models. The explicit use of inducing KV payloads and the suite of matched-budget diagnostics are positive features that strengthen the fixed-footprint framing.
major comments (2)
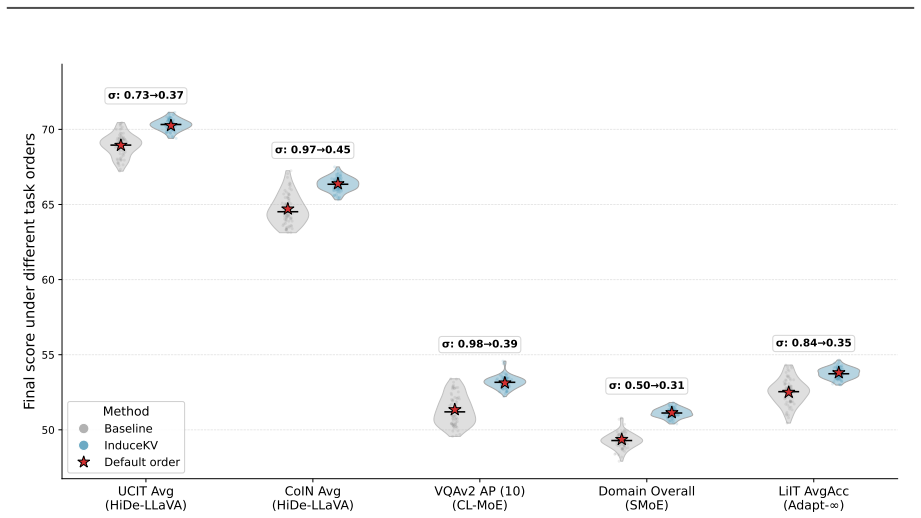
- [Bilevel selection procedure] Bilevel selection (described in the method section): the headline fixed-footprint claim rests on the selected inducing set improving performance with a frozen backbone and no additional parameters. No ablation isolating the three balancing terms (current-task likelihood, anchor-based retention, coverage) or testing stability of the selected set across task orderings is referenced, leaving the reliability of the compact set under-specified.
- [Results and diagnostics] Experimental claims (abstract and results): the assertion of consistent gains under matched memory budgets is load-bearing, yet the manuscript text supplies no quantitative deltas, error bars, or per-setting tables that would allow verification of the data-to-claim link against the listed baselines.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one concrete performance number or effect size rather than the qualitative statement 'consistently improves'.
- [Method and experimental setup] Clarify how the memory budget is computed for the KV payloads versus the replay and prompt-retrieval baselines to make the 'matched' comparison fully transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate the suggested additions for greater clarity and verifiability.
read point-by-point responses
-
Referee: [Bilevel selection procedure] Bilevel selection (described in the method section): the headline fixed-footprint claim rests on the selected inducing set improving performance with a frozen backbone and no additional parameters. No ablation isolating the three balancing terms (current-task likelihood, anchor-based retention, coverage) or testing stability of the selected set across task orderings is referenced, leaving the reliability of the compact set under-specified.
Authors: We agree that additional analysis would strengthen the reliability of the bilevel selection procedure. In the revised manuscript we will add a dedicated ablation subsection that isolates the contribution of each of the three balancing terms by reporting performance when each term is removed in turn. We will also include results across multiple task orderings to demonstrate stability of the selected inducing set. These experiments will use the same memory budgets and evaluation protocols as the main results. revision: yes
-
Referee: [Results and diagnostics] Experimental claims (abstract and results): the assertion of consistent gains under matched memory budgets is load-bearing, yet the manuscript text supplies no quantitative deltas, error bars, or per-setting tables that would allow verification of the data-to-claim link against the listed baselines.
Authors: We acknowledge that the main text would benefit from more explicit quantitative reporting. Although detailed per-setting tables appear in the appendix, we will add a consolidated summary table to the main results section that reports average deltas, standard errors across runs, and direct head-to-head comparisons against all baselines under matched memory budgets. Error bars will also be added to the primary figures. These changes will make the claimed gains directly verifiable from the main text. revision: yes
Circularity Check
No circularity: method is a described algorithm with external empirical claims
full rationale
The paper presents InduceKV as a retrieval-based procedure whose bilevel selection (calibration plus balancing of likelihood, retention, and coverage) is an explicit algorithmic construction, not a fitted quantity renamed as a prediction. No equations or steps in the abstract reduce the reported gains to the inputs by definition; the central claims are comparative improvements over PEFT/MoE/replay baselines under matched budgets, which are externally falsifiable. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[3]
International Conference on Machine Learning , pages=
MOMENT: A Family of Open Time-series Foundation Models , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[4]
Timer-XL: Long-Context Transformers for Unified Time Series Forecasting , author=
-
[5]
ICLR 2025: The Thirteenth International Conference on Learning Representations , year=
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts , author=. ICLR 2025: The Thirteenth International Conference on Learning Representations , year=
2025
-
[6]
arXiv preprint arXiv:2507.14507 , year=
Diffusion models for time series forecasting: A survey , author=. arXiv preprint arXiv:2507.14507 , year=
-
[7]
International conference on machine learning , pages=
Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[8]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[9]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[10]
The eleventh international conference on learning representations , year=
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting , author=. The eleventh international conference on learning representations , year=
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Construct-vl: Data-free continual structured vl concepts learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Continual learning for visual search with backward consistent feature embedding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Advances in neural information processing systems , volume=
Dark experience for general continual learning: a strong, simple baseline , author=. Advances in neural information processing systems , volume=
-
[14]
Workshop on Multi-Task and Lifelong Reinforcement Learning , year=
Continual learning with tiny episodic memories , author=. Workshop on Multi-Task and Lifelong Reinforcement Learning , year=
-
[15]
IEEE Transactions on Instrumentation and Measurement , year=
GALMOR: Memory-Constrained Continual Learning With Efficient Replay for Fault Diagnosis of Rotating Machinery , author=. IEEE Transactions on Instrumentation and Measurement , year=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Guilin Zhu and Dongyue Wu and Changxin Gao and Runmin Wang and Weidong Yang and Nong Sang , title =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[17]
arXiv preprint arXiv:2503.06683 , year =
Dynamic Dictionary Learning for Remote Sensing Image Segmentation , author =. arXiv preprint arXiv:2503.06683 , year =
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
SCORE: Scene Context Matters in Open-Vocabulary Remote Sensing Instance Segmentation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[19]
arXiv preprint arXiv:2501.13925 , year =
GeoPixel: Pixel Grounding Large Multimodal Model in Remote Sensing , author =. arXiv preprint arXiv:2501.13925 , year =
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
SkySense-O: Towards Open-World Remote Sensing Interpretation with Vision-Centric Visual-Language Modeling , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Towards Open-Vocabulary Remote Sensing Image Semantic Segmentation , author =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Learning at a glance: Towards interpretable data-limited continual semantic segmentation via semantic-invariance modelling , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
2024
-
[24]
IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium , pages=
Self-training and curriculum learning guided dynamic refined network for remote sensing class-incremental semantic segmentation , author=. IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium , pages=. 2024 , month=
2024
-
[25]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Domain-Incremental Learning for Remote Sensing Semantic Segmentation With Multifeature Constraints in Graph Space , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2024 , publisher=
2024
-
[26]
Science China Information Sciences , volume=
Mitigating representation bias for class-incremental semantic segmentation of remote sensing images , author=. Science China Information Sciences , volume=. 2025 , doi=
2025
-
[27]
IEEE Transactions on Geoscience and Remote Sensing , volume=
MiSSNet: Memory-inspired semantic segmentation augmentation network for class-incremental learning in remote sensing images , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2024 , publisher=
2024
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Yirui Wu and Yuhang Xia and Hao Li and Lixin Yuan and Junyang Chen and Jun Liu and Tong Lu and Shaohua Wan , title =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Zhidong Yu and Xiaoman Liu and Jiajun Hu and Zhenbo Shi and Wei Yang , title =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Cheng Xu and Weiwen Zhang and Hongrui Zhang and Xuemiao Xu and Huaidong Zhang and Jing Zou and Jing Qin , title =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Hongmei Yin and Tingliang Feng and Fan Lyu and Fanhua Shang and Hongying Liu and Wei Feng and Liang Wan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[33]
IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , volume=
Understanding video events: A survey of methods for automatic interpretation of semantic occurrences in video , author=. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , volume=. 2009 , publisher=
2009
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Revisiting the" video" in video-language understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
Advances in Neural Information Processing Systems , volume=
A Practitioner's Guide to Real-World Continual Multimodal Pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Yuchen Zhu and Cheng Shi and Dingyou Wang and Jiajin Tang and Zhengxuan Wei and Yu Wu and Guanbin Li and Sibei Yang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Kai Fang and Anqi Zhang and Guangyu Gao and Jianbo Jiao and Chi Harold Liu and Yunchao Wei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Maoxian Wan and Kaige Li and Qichuan Geng and Weimin Shi and Zhong Zhou , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Ruitao Wu and Yifan Zhao and Jia Li , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[40]
Advances in Neural Information Processing Systems , year=
OVS Meets Continual Learning: Towards Sustainable Open-Vocabulary Segmentation , author=. Advances in Neural Information Processing Systems , year=
-
[41]
Advances in Neural Information Processing Systems , year=
Leveraging Depth and Language for Open-Vocabulary Domain-Generalized Semantic Segmentation , author=. Advances in Neural Information Processing Systems , year=
-
[42]
Advances in Neural Information Processing Systems , year=
Open-Vocabulary Part Segmentation via Progressive and Boundary-Aware Strategy , author=. Advances in Neural Information Processing Systems , year=
-
[43]
Advances in Neural Information Processing Systems , year=
Seg4Diff: Unveiling Open-Vocabulary Segmentation in Text-to-Image Diffusion Transformers , author=. Advances in Neural Information Processing Systems , year=
-
[44]
Advances in Neural Information Processing Systems , year=
OPMapper: Enhancing Open-Vocabulary Semantic Segmentation with Multi-Guidance Information , author=. Advances in Neural Information Processing Systems , year=
-
[45]
Advances in Neural Information Processing Systems , year=
LangHOPS: Language Grounded Hierarchical Open-Vocabulary Part Segmentation , author=. Advances in Neural Information Processing Systems , year=
-
[46]
Advances in Neural Information Processing Systems , year=
Continual Gaussian Mixture Distribution Modeling for Class Incremental Semantic Segmentation , author=. Advances in Neural Information Processing Systems , year=
-
[47]
Advances in Neural Information Processing Systems , year=
Test-Time Adaptation of Vision-Language Models for Open-Vocabulary Semantic Segmentation , author=. Advances in Neural Information Processing Systems , year=
-
[48]
Forty-second International Conference on Machine Learning , year=
Divide and Conquer: Exploring Language-centric Tree Reasoning for Video Question-Answering , author=. Forty-second International Conference on Machine Learning , year=
-
[49]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
VideoLLaMB: Long Streaming Video Understanding with Recurrent Memory Bridges , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[50]
arXiv preprint arXiv:2507.00469 , year=
Bisecle: Binding and Separation in Continual Learning for Video Language Understanding , author=. arXiv preprint arXiv:2507.00469 , year=
-
[51]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Gpt4video: A unified multimodal large language model for lnstruction-followed understanding and safety-aware generation , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[52]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Dam: Dynamic adapter merging for continual video qa learning , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
2025
-
[53]
arXiv preprint arXiv:2502.00843 , year=
VLM-assisted continual learning for visual question answering in self-driving , author=. arXiv preprint arXiv:2502.00843 , year=
-
[54]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
VQAGuider: Guiding Multimodal Large Language Models to Answer Complex Video Questions , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Feature Decomposition-Recomposition in Large Vision-Language Model for Few-Shot Class-Incremental Learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[56]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Longvu: Spatiotemporal adaptive compression for long video-language understanding , author=. arXiv preprint arXiv:2410.17434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2503.14963 , year=
Continual multimodal contrastive learning , author=. arXiv preprint arXiv:2503.14963 , year=
-
[58]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Learning without forgetting for vision-language models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[59]
International conference on machine learning , pages=
Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[60]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Empowering Large Language Model for Continual Video Question Answering with Collaborative Prompting , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[61]
Advances in Neural Information Processing Systems , volume=
BMU-MoCo: Bidirectional momentum update for continual video-language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Advances in Neural Information Processing Systems , volume=
Vilco-bench: Video language continual learning benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Continual Learning for VLMs: A Survey and Taxonomy Beyond Forgetting
Continual Learning for VLMs: A Survey and Taxonomy Beyond Forgetting , author=. arXiv preprint arXiv:2508.04227 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Forty-second International Conference on Machine Learning , year=
Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning , author=. Forty-second International Conference on Machine Learning , year=
-
[65]
International conference on machine learning , pages=
Deep canonical correlation analysis , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[66]
arXiv preprint arXiv:2110.08733 , year=
LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation , author=. arXiv preprint arXiv:2110.08733 , year=
-
[67]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Historical information-guided class-incremental semantic segmentation in remote sensing images , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2022 , publisher=
2022
-
[68]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Automated high-resolution earth observation image interpretation: Outcome of the 2020 Gaofen challenge , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2021 , publisher=
2020
-
[69]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
isaid: A large-scale dataset for instance segmentation in aerial images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[70]
Proceedings of COMPSTAT'2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=
Large-scale machine learning with stochastic gradient descent , author=. Proceedings of COMPSTAT'2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=. 2010 , organization=
2010
-
[71]
ISPRS: Leopoldsh
ISPRS semantic labeling contest , author=. ISPRS: Leopoldsh
-
[72]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Deepglobe 2018: A challenge to parse the earth through satellite images , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
2018
-
[73]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dynamic Multi-Layer Null Space Projection for Vision-Language Continual Learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[74]
Automation in Construction , volume=
Context-aware vision-language model agent enriched with domain-specific ontology for construction site safety monitoring , author=. Automation in Construction , volume=. 2025 , publisher=
2025
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Overcoming Dual Drift for Continual Long-Tailed Visual Question Answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[76]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Pretrained language models as visual planners for human assistance , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[77]
Proceedings of the Nineteenth ACM Conference on Recommender Systems , pages=
Improving Visual Recommendation on E-commerce Platforms Using Vision-Language Models , author=. Proceedings of the Nineteenth ACM Conference on Recommender Systems , pages=
-
[78]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Foundation models defining a new era in vision: a survey and outlook , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[79]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maple: Multi-modal prompt learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[80]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.