DeepGaze3.5-VL: Modeling Scanpaths via Autoregressive Token Prediction
Pith reviewed 2026-07-03 15:47 UTC · model grok-4.3
The pith
Scanpath prediction reduces to autoregressive token prediction by mapping fixations to text tokens inside pretrained vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
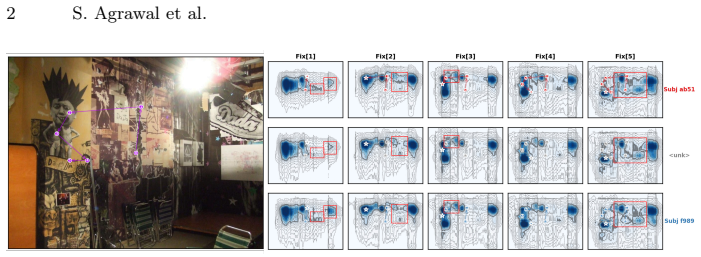
By mapping continuous fixation coordinates into a fixed text vocabulary and treating scanpath generation as autoregressive token prediction inside a pretrained vision-language model, DeepGaze3.5-VL obtains state-of-the-art performance across datasets while allowing flexible conditioning on viewer identity, task instructions, and per-fixation attributes through standard prompting.
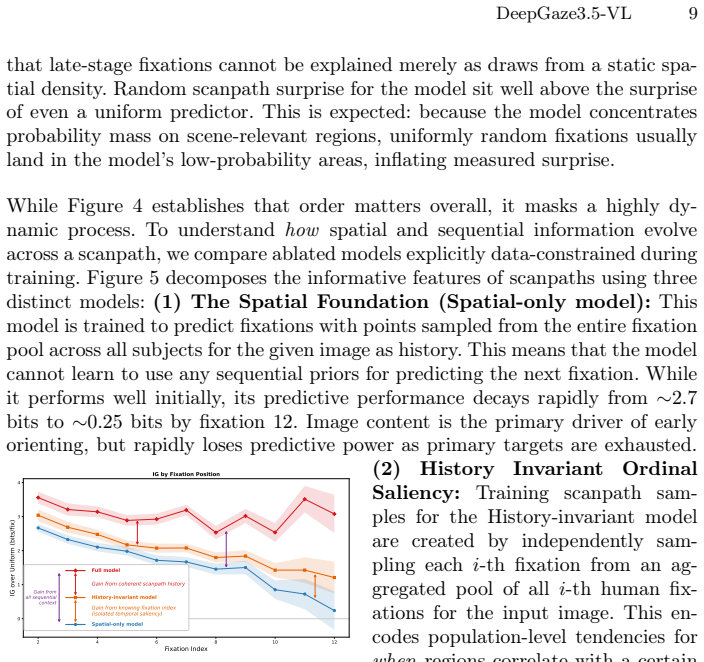
What carries the argument
Autoregressive token prediction on discretized fixation coordinates inside a vision-language model, which supplies exact per-fixation log-likelihoods equivalent to information gain.
If this is right
- Prompting with viewer identity directly captures personalized attention biases without new parameters.
- Natural-language task descriptions such as visual-search instructions can be added at inference time.
- Fixation durations and other per-fixation attributes can be predicted jointly with location tokens.
- The generative model supports controlled in-silico interventions on fixation timing that recover known oculomotor phenomena.
Where Pith is reading between the lines
- The same tokenization approach could be applied to other sequential visual-motor behaviors such as pointing or grasping trajectories.
- Exact per-token likelihoods open the door to uncertainty-aware attention models for interface evaluation.
- Scaling the underlying vision-language model on larger eye-tracking corpora may further widen the performance gap.
Load-bearing premise
Discretizing continuous fixation locations into a fixed text vocabulary keeps enough spatial and temporal structure for accurate scanpath prediction without task-specific architectural changes.
What would settle it
A controlled experiment in which an otherwise identical model using continuous coordinate regression or a non-VLM backbone yields equal or higher information gain on the same test sets.
Figures









read the original abstract
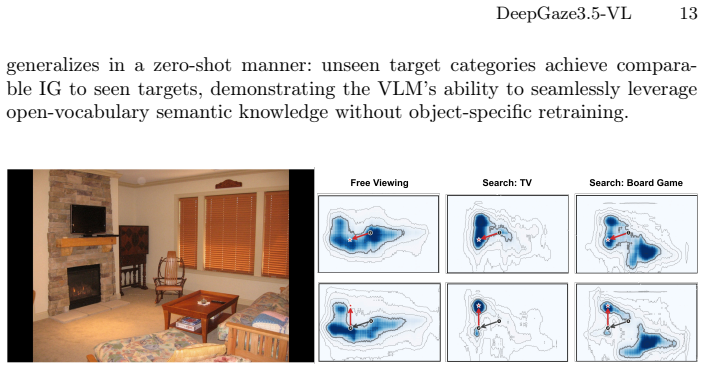
Understanding human visual attention on a scene over time has applications in domains such as interface design and inferring cognitive states. Modeling visual scanpaths has historically relied on specialized architectures with hand-crafted priors. While these architectures can model fixation sequences, their rigid structural biases restrict easy extendability and flexible conditioning. For instance, integrating task-specific instructions or adapting to distinct viewer identities requires custom, disjoint architectural additions. We frame scanpath prediction purely as a discrete sequence modeling task. By mapping coordinates into a text vocabulary, we leverage the pretrained representations of Vision-Language Models. This framing absorbs diverse factors of variation: simple prompting allows for global conditioning, such as providing viewer identities to capture personalized biases, or task-specific objectives like visual search. The framework can also integrate per-fixation attributes, such as individual fixation durations, alongside spatial locations. The autoregressive alignment enables the scalable, exact computation of per-fixation log-likelihoods, directly equivalent to the commonly used Information Gain (IG) metric. Our model, DeepGaze3.5-VL, establishes a new state-of-the-art across multiple datasets, achieving 2.18 bits of IG on MIT1003, a 46% improvement over DeepGaze III. This advantage persists even when baselines use identical high-capacity vision encoders. Beyond predictive performance, our generative framework serves as a powerful computational tool for direct behavioral interventions, allowing for controlled in-silico simulations that would be experimentally difficult or impossible to conduct in vivo. We demonstrate this ability by performing controlled interventions on the durations of pre-saccadic fixations, recovering known oculomotor phenomena purely from data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames scanpath modeling as autoregressive discrete sequence prediction by mapping continuous fixation coordinates to a text vocabulary and leveraging pretrained vision-language models. It claims this yields a new SOTA of 2.18 bits IG on MIT1003 (46% improvement over DeepGaze III) that holds with matched high-capacity encoders, that per-fixation autoregressive log-likelihoods are mathematically identical to the standard IG metric, and that simple prompting enables flexible conditioning on viewer identity or task while also supporting generative interventions on fixation durations.
Significance. If the coordinate-to-token mapping preserves spatial/temporal fidelity and the IG equivalence is rigorously verified, the approach would be significant for removing the need for hand-crafted architectural priors in scanpath models and enabling prompt-based extensions. The generative simulation capability is a clear strength not present in prior discriminative models.
major comments (3)
- [Abstract and §3] Abstract and §3 (coordinate-to-token mapping): the manuscript provides no equation, pseudocode, or parameter for the discretization function, vocabulary size, or spatial resolution (pixels per token). This is load-bearing for the central claim that the discrete space preserves the structure needed for accurate per-fixation likelihoods and for the assertion that reported IG values are comparable to continuous baselines.
- [Abstract and §4] Abstract and §4 (IG equivalence): the statement that autoregressive log-likelihood is 'directly equivalent' to the standard IG metric is asserted without derivation, proof of measure equivalence after discretization, or explicit verification that the token space matches the evaluation metric's support. This directly affects whether the 2.18-bit figure and 46% improvement can be interpreted as a genuine advance.
- [§5] §5 (results): the SOTA claim and the statement that the advantage 'persists even when baselines use identical high-capacity vision encoders' are presented without reference to specific tables, error bars, cross-validation splits, or the exact encoder-matching ablation protocol, leaving the robustness of the matched-encoder result unassessable.
minor comments (1)
- [§3] Notation for the token vocabulary and the conditioning prompt format should be introduced with explicit symbols in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (coordinate-to-token mapping): the manuscript provides no equation, pseudocode, or parameter for the discretization function, vocabulary size, or spatial resolution (pixels per token). This is load-bearing for the central claim that the discrete space preserves the structure needed for accurate per-fixation likelihoods and for the assertion that reported IG values are comparable to continuous baselines.
Authors: We agree that the discretization details are essential for reproducibility and for validating that the discrete token space preserves the necessary spatial and temporal structure. Although §3 describes the high-level mapping of fixation coordinates to a text vocabulary, we did not provide an explicit equation, pseudocode, vocabulary size, or spatial resolution parameter. In the revised manuscript we will add these elements, including the precise discretization function and resolution (pixels per token), to substantiate the fidelity claims. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (IG equivalence): the statement that autoregressive log-likelihood is 'directly equivalent' to the standard IG metric is asserted without derivation, proof of measure equivalence after discretization, or explicit verification that the token space matches the evaluation metric's support. This directly affects whether the 2.18-bit figure and 46% improvement can be interpreted as a genuine advance.
Authors: The equivalence arises because the autoregressive factorization of the joint token probability yields per-fixation log-likelihoods that match the binned information-gain computation once coordinates are discretized. We acknowledge that the manuscript asserts this without a formal derivation or explicit verification of measure equivalence. In the revision we will insert a mathematical derivation in §4 demonstrating the identity after discretization and confirming that the token support aligns with the evaluation bins used for the reported IG values. revision: yes
-
Referee: [§5] §5 (results): the SOTA claim and the statement that the advantage 'persists even when baselines use identical high-capacity vision encoders' are presented without reference to specific tables, error bars, cross-validation splits, or the exact encoder-matching ablation protocol, leaving the robustness of the matched-encoder result unassessable.
Authors: The SOTA results and matched-encoder comparisons are supported by the quantitative tables and ablation experiments in §5. We agree that the text should explicitly reference these elements. In the revision we will add direct citations to the relevant tables, include error bars, specify the cross-validation splits, and provide a detailed description of the encoder-matching protocol so that the robustness of the 2.18-bit IG claim and the 46% improvement can be fully assessed. revision: yes
Circularity Check
No significant circularity; log-likelihood equivalence to IG is definitional, not fitted
full rationale
The paper frames scanpath modeling as autoregressive token prediction after coordinate discretization and states that per-fixation log-likelihoods are 'directly equivalent to the commonly used Information Gain (IG) metric.' This equivalence follows from the standard definition of IG in saliency/scanpath literature (model log-likelihood relative to baseline) rather than any parameter being fitted to match the evaluation metric. No self-citations are load-bearing for the central claim, no uniqueness theorems are invoked, no ansatz is smuggled, and no predictions reduce to inputs by construction. The reported SOTA numbers (e.g., 2.18 bits IG) are therefore independent empirical outcomes of the trained model, not forced by the evaluation procedure itself. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discretizing fixation coordinates into a text vocabulary allows pretrained VLM representations to capture the necessary spatial and sequential structure of human scanpaths.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Aydemir, B., Hoffstetter, L., Zhang, T., Salzmann, M., S"usstrunk, S.: Tempsal - uncovering temporal information for deep saliency prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[2]
Vision Research19(9), 967–983 (1979)
Becker, W., Jürgens, R.: An analysis of the saccadic system by means of double step stimuli. Vision Research19(9), 967–983 (1979)
1979
-
[3]
Physica A: Statistical Mechanics and its Applications331(1-2), 207–218 (2004)
Boccignone, G., Ferraro, M.: Modelling gaze shift as a constrained random walk. Physica A: Statistical Mechanics and its Applications331(1-2), 207–218 (2004)
2004
-
[4]
CAT2000: A Large Scale Fixation Dataset for Boosting Saliency Research
Borji, A., Itti, L.: Cat2000: A large scale fixation dataset for boosting saliency research. arXiv preprint arXiv:1505.03581 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Vision Research116, 165–178 (2015)
Bylinskii, Z., Isola, P., Bainbridge, C., Torralba, A., Oliva, A.: Intrinsic and ex- trinsic effects on image memorability. Vision Research116, 165–178 (2015)
2015
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Cartella, G., Cuculo, V., D’Amelio, A., Cornia, M., Boccignone, G., Cucchiara, R.: Modeling human gaze behavior with diffusion models for unified scanpath pre- diction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[7]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023) 16 S. Agrawal et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
arXiv preprint arXiv:2109.10852 , year=
Chen, T., Saxena, S., Li, L., Fleet, D.J., Hinton, G.: Pix2seq: A language modeling framework for object detection. arXiv preprint arXiv:2109.10852 (2021)
-
[9]
Scientific Reports11(1), 8776 (2021)
Chen, Y., Yang, Z., Ahn, S., Samaras, D., Hoai, M., Zelinsky, G.: Coco-search18: A dataset for predicting goal-directed attention control. Scientific Reports11(1), 8776 (2021)
2021
-
[10]
In: NeurIPS Workshop on Gaze Meets ML (2022)
D’Agostino, F., Schwetlick, L., Bethge, M., Kümmerer, M.: What moves the eyes: Doubling mechanistic model performance using deep networks to discover and test cognitive hypotheses. In: NeurIPS Workshop on Gaze Meets ML (2022)
2022
-
[11]
Frontiers in Psychology15(2024)
David, E.v.d.H., et al.: Potsdam data set of eye movement on natural scenes (dae- mons). Frontiers in Psychology15(2024)
2024
-
[12]
Behavior Research Methods, Instruments, & Computers34(4), 455–470 (2002)
Duchowski, A.T.: A breadth-first survey of eye-tracking applications. Behavior Research Methods, Instruments, & Computers34(4), 455–470 (2002)
2002
-
[13]
Journal of Vision15(4), 1–1 (2015)
Engbert, R., Rothkegel, L.O., Metzner, P., Nuthmann, A.: Scenewalk: A cognitive model for eye movements during natural scene viewing. Journal of Vision15(4), 1–1 (2015)
2015
-
[14]
Proceedings of the National Academy of Sciences116(24), 11687–11692 (2019)
de Haas, B., Iakovidis, A.L., Schwarzkopf, D.S., Gegenfurtner, K.R.: Individual differences in visual salience vary along a single semantic dimension. Proceedings of the National Academy of Sciences116(24), 11687–11692 (2019)
2019
-
[15]
de Haas, B., Iakovidis, A.L., Schwarzkopf, D.S., Gegenfurtner, K.R.: Individual differences in visual salience vary along semantic dimensions. Proceedings of the National Academy of Sciences116(24), 11687–11692 (2019).https://doi.org/ 10.1073/pnas.1820553116,https://www.pnas.org/doi/abs/10.1073/pnas. 1820553116
-
[16]
In: International Conference on Learning Representations (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022)
2022
-
[17]
In: Proceedings of the IEEE international conference on computer vision
Huang, X., Shen, C., Boix, X., Zhao, Q.: Salicon: Reducing the semantic gap in saliency prediction by adapting deep neural networks. In: Proceedings of the IEEE international conference on computer vision. pp. 262–270 (2015)
2015
-
[18]
Cognitive vision systems: spatial communication and scene understanding pp
Itti, L., Koch, C.: A saliency-based search mechanism for guiding visual attention. Cognitive vision systems: spatial communication and scene understanding pp. 97– 106 (2000)
2000
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence 20(11), 1254–1259 (1998)
Itti, L., Koch, C., Niebur, E.: A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 20(11), 1254–1259 (1998)
1998
-
[20]
Jelinek, F., Mercer, R.L., Bahl, L.R., Baker, J.K.: Perplexity—a measure of the difficulty of speech recognition tasks. The Journal of the Acoustical Society of America62(S1), S63–S63 (08 2005).https://doi.org/10.1121/1.2016299, https://doi.org/10.1121/1.2016299
-
[21]
Image and Vision Computing95, 103887 (2020)
Jia, S., Bruce, N.D.: Eml-net: An expandable multi-layer network for saliency pre- diction. Image and Vision Computing95, 103887 (2020)
2020
-
[22]
In: Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology
Jiang, Y., Guo, Z., Rezazadegan Tavakoli, H., Leiva, L.A., Oulasvirta, A.: Eye- former: Predicting personalized scanpaths with transformer-guided reinforcement learning. In: Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. pp. 1–15. UIST ’24, ACM (Oct 2024).https://doi. org/10.1145/3654777.3676436,http://dx.doi.org/1...
-
[23]
In: IEEE International Conference on Computer Vision (ICCV)
Judd, T., Ehinger, K., Durand, F., Torralba, A.: Learning to predict where humans look. In: IEEE International Conference on Computer Vision (ICCV). pp. 2106– 2113 (2009)
2009
-
[24]
Khanuja,H.S.,Kümmerer,M.,Bethge,M.:Modelingsaliencydatasetbias.In:Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (2025) DeepGaze3.5-VL 17
2025
-
[25]
arXiv preprint arXiv:2102.12112 (2021)
Kümmerer, M., Bethge, M.: State-of-the-art in human scanpath prediction. arXiv preprint arXiv:2102.12112 (2021)
-
[26]
In: ICLR (2015)
Kümmerer, M., Theis, L., Bethge, M.: Deepgaze i: Boosting saliency prediction with feature maps trained on imagenet. In: ICLR (2015)
2015
-
[27]
In: Proceedings of the National Academy of Sciences
Kümmerer, M., Wallis, T.S., Bethge, M.: Information-theoretic model compari- son unifies saliency metrics. In: Proceedings of the National Academy of Sciences. vol. 112, pp. 16054–16059 (2015)
2015
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kümmerer, M., Wallis, T.S., Bethge, M.: Deepgaze iii: Modeling spatial stimulus context and image processing for gaze prediction in scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6817–6826 (2021)
2021
-
[29]
Vision research121, 72–84 (2016)
Le Meur, O., Coutrot, A.: Introducing context-dependent and spatially-variant viewing biases in saccadic models. Vision research121, 72–84 (2016)
2016
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Linardos, A., Kümmerer, M., Press, O., Bethge, M.: Deepgaze iie: Calibrated pre- diction in and out-of-domain for state-of-the-art saliency modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6107–6116 (2021)
2021
-
[31]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Mondal, S., Yang, Z., Ahn, S., Samaras, D., Zelinsky, G., Hoai, M.: Gazeformer: Scalable, effective and fast prediction of goal-directed human attention. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1441–1450. IEEE (2023)
2023
-
[32]
In: Euro- pean Conference on Computer Vision (ECCV)
Mondal, S., Yang, Z., Ahn, S., Samaras, D., Zelinsky, G., Hoai, M.: Gazexplain: Learning to predict natural language explanations of visual scanpaths. In: Euro- pean Conference on Computer Vision (ECCV). Springer (2024)
2024
-
[33]
IEEE Transactions on Pattern Analysis and Machine Intelligence41(7), 1720–1733 (2018)
Palazzi, A., Abati, D., Calderara, S., Solera, F., Cucchiara, R.: Predicting the driver’s focus of attention: the DR(eye)VE project. IEEE Transactions on Pattern Analysis and Machine Intelligence41(7), 1720–1733 (2018)
2018
-
[34]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Zheng, F.: Kosmos- 2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Journal of Vision19(3), 1–1 (03 2019).https: //doi.org/10.1167/19.3.1,https://doi.org/10.1167/19.3.1
Schütt, H.H., Rothkegel, L.O.M., Trukenbrod, H.A., Engbert, R., Wichmann, F.A.: Disentangling bottom-up versus top-down and low-level versus high-level influences on eye movements over time. Journal of Vision19(3), 1–1 (03 2019).https: //doi.org/10.1167/19.3.1,https://doi.org/10.1167/19.3.1
-
[36]
Visual Cognition17(6-7), 1007–1028 (2009)
Smith, T.J., Henderson, J.M.: Facilitation of return during scene viewing. Visual Cognition17(6-7), 1007–1028 (2009)
2009
-
[37]
Incomplete Ideas (blog)13(1), 38 (2019)
Sutton, R.S.: The bitter lesson. Incomplete Ideas (blog)13(1), 38 (2019)
2019
-
[38]
Journal of Vision7(14), 4–4 (11 2007).https://doi.org/10.1167/7.14.4, https://doi.org/10.1167/7.14.4
Tatler, B.W.: The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions. Journal of Vision7(14), 4–4 (11 2007).https://doi.org/10.1167/7.14.4, https://doi.org/10.1167/7.14.4
-
[39]
Visual Cognition12(3), 473–494 (2005)
Unema, P.J.A., Pannasch, S., Joos, M., Velichkovsky, B.M.: Time course of in- formation processing during scene perception. Visual Cognition12(3), 473–494 (2005)
2005
-
[40]
In: Proceedings of the XXVII Conference of the Cognitive Science Society, pp
Velichkovsky, B.M., Joos, M., Helmert, J.R., Pannasch, S.: Two visual systems and their eye movements: evidence from static and dynamic scene perception. In: Proceedings of the XXVII Conference of the Cognitive Science Society, pp. 2283–
-
[41]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2025) 18 S
Wang, Y., Cheng, Z., Zhang, H., Zheng, X., Chen, X., Jiang, Y.: Tpp-gaze: Mod- elling gaze dynamics in space and time with neural temporal point processes. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2025) 18 S. Agrawal et al
2025
-
[42]
Psychonomic Bulletin & Review28(4), 1060–1092 (2021)
Wolfe, J.M.: Guided search 6.0: An updated model of visual search. Psychonomic Bulletin & Review28(4), 1060–1092 (2021)
2021
-
[43]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Xue, R., Xu, J., Mondal, S., Le, H., Zelinsky, G., Hoai, M., Samaras, D.: Few-shot personalized scanpath prediction. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13497–13507. IEEE (Jun 2025). https://doi.org/10.1109/cvpr52734.2025.01260,http://dx.doi.org/10. 1109/cvpr52734.2025.01260
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Z., Huang, L., Chen, Y., Wei, Z., Ahn, S., Zelinsky, G., Samaras, D., Hoai, M.:Predictinggoal-directedhumanattentionusingahumanattentiontransformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5039–5049 (2022)
2022
-
[45]
mean scanpath
Zelinsky, G.J.: A theory of eye movements during target acquisition. Psychological Review115(4), 787–835 (2008) DeepGaze3.5-VL 1 6 Appendix 6.1 Few-Shot Adaptation to New Datasets 1 10 50 100 250 500 1000 Number of adaptation samples 1.95 2.00 2.05 2.10 2.15Information Gain [bits/fix] 0% 3% 3% 9% 31% 54% 61% Few-Shot Dataset Adaptation MIT 5 Datasets (upp...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.