TCG-AR: Real-Time Multi-View Augmented Reality for Trading Card Game Streaming
Pith reviewed 2026-07-03 15:44 UTC · model grok-4.3
The pith
TCG-AR detects, orients, and identifies cards from ordinary RGB cameras then renders virtual models onto them in real time across multiple views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
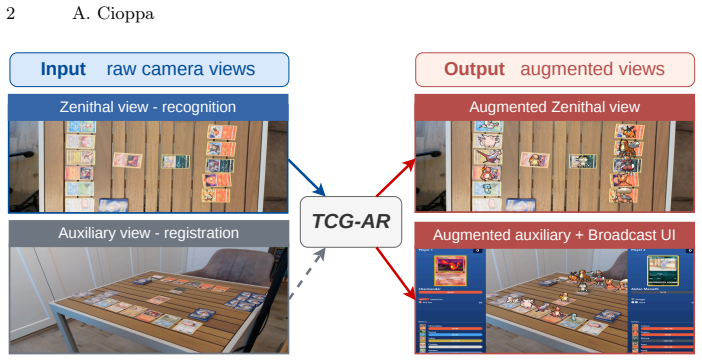
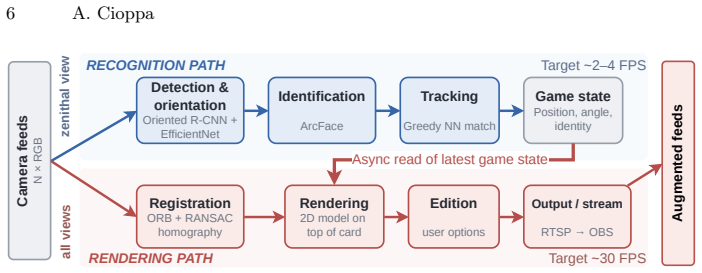
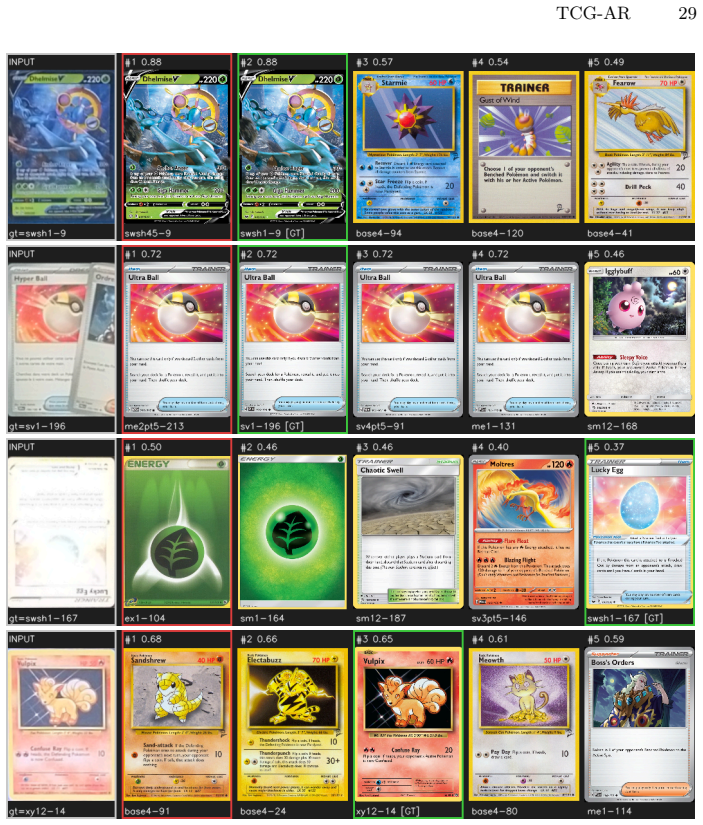
TCG-AR is a real-time pipeline that augments trading card games using ordinary RGB cameras alone, without physical markers or specialized hardware. It detects, orients, and identifies the cards on the board, renders virtual content onto each card across all views, and can compose a broadcast-style view that summarizes the game state for spectators before streaming the augmented feeds to standard broadcasting software such as OBS. Models for detection, orientation, and identification are trained on annotated synthetic data produced automatically from a reference set of card images, and performance is measured on a new manually annotated real-image dataset to assess usability.
What carries the argument
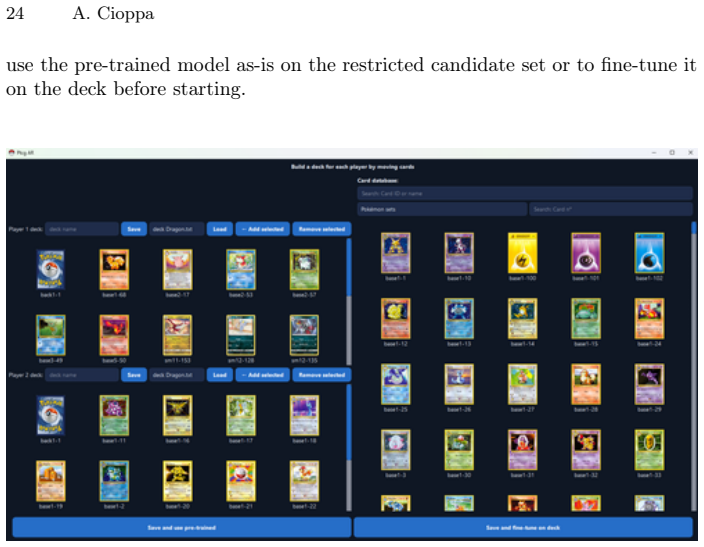
The automatic procedure that generates annotated synthetic training data from a reference set of card images, which supplies the labeled examples needed to train the detection, orientation, and identification models.
If this is right
- Augmentation becomes possible without instrumented tables or embedded chips.
- Multiple ordinary cameras can supply consistent overlays on the same physical cards.
- A summarized game-state view can be produced and sent directly to OBS or similar software.
- All models, code, and the real-image evaluation dataset are released for community use.
- Runtime throughput measurements establish whether the pipeline meets live-streaming latency limits.
Where Pith is reading between the lines
- The same synthetic-data generator could be adapted to other physical card or board games that lack large labeled datasets.
- Adding a temporal consistency term across video frames might reduce flickering of the rendered overlays without changing the core pipeline.
- The broadcast view could be extended to highlight legal moves or track life totals if game rules are encoded as additional input.
- Performance on the real dataset provides a baseline for measuring whether future improvements in synthetic rendering close the remaining domain gap.
Load-bearing premise
Synthetic images created automatically from reference card pictures capture enough of the lighting, perspective, and occlusion variation present in real camera footage for models trained on them to work on actual streams.
What would settle it
If a model trained solely on the generated synthetic data records substantially lower accuracy on the manually annotated real-image test set than on synthetic test images, the generalization premise fails.
Figures



read the original abstract
Trading card games are increasingly played and broadcast online, yet live streams remain mostly limited to flat top-down footage of the playing area. Augmenting such streams with virtual models of the played cards would improve the viewing experience, but most existing systems rely on instrumented playing surfaces and embedded chips, which are costly and impractical for casual players and large-scale events. In this work, we present TCG-AR, a novel real-time pipeline that augments trading card games using ordinary RGB cameras alone, without any physical markers or specialized hardware. Our pipeline detects, orients, and identifies the cards on the board, renders virtual content onto each card across all views, and can additionally compose a broadcaststyle view that summarizes the game state for spectators, streaming the augmented feeds to standard broadcasting software such as OBS. To train the detection, orientation, and identification models without manual labeling, we introduce an automatic procedure that generates annotated synthetic training data from a reference set of card images. Then, we evaluate several trained models on a new manually annotated dataset with real images, analyzing performance and runtime throughput that determine real-world usability. Overall, by relying only on commodity cameras and hardware, and by open-sourcing all code, models, and datasets, this work aims to serve as a reference for real-time trading card recognition and to make real-time augmented-reality streaming accessible to the broader community of players and streamers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TCG-AR, a real-time multi-view AR pipeline for trading card game streaming that relies solely on ordinary RGB cameras. It detects, orients, and identifies cards using models trained via an automatic synthetic data generation procedure from reference card images (no manual labeling), renders virtual content onto detected cards across views, and optionally composes a broadcast-style summary view streamed to tools such as OBS. The work claims to evaluate the trained models on a new manually annotated real-image dataset, analyze performance and runtime throughput for real-world usability, and open-sources all code, models, and datasets.
Significance. If the synthetic-to-real transfer achieves usable accuracy, the approach would offer a practical, hardware-free method for enhancing TCG streams with per-card AR overlays and spectator views, addressing limitations of existing instrumented systems. Open-sourcing strengthens potential for reproducibility and adoption in the computer vision and streaming communities.
major comments (2)
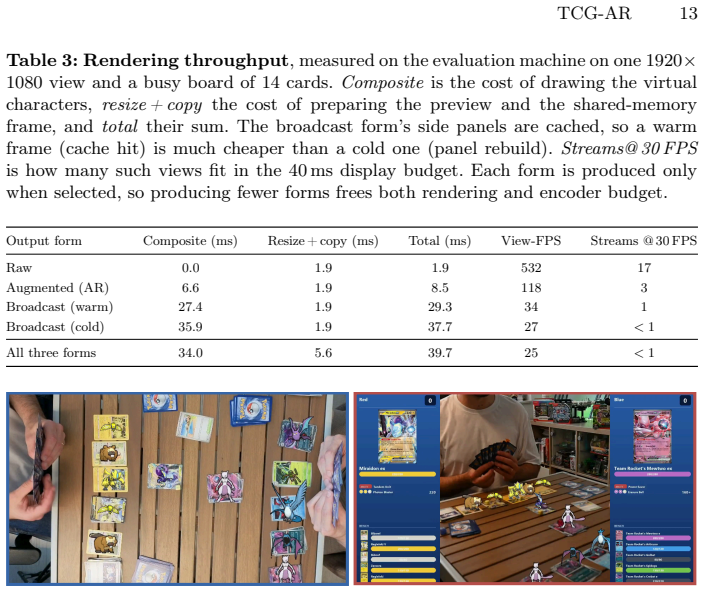
- [Abstract; evaluation section] Abstract and evaluation section: the manuscript states that models were evaluated on a manually annotated real-image dataset with analysis of performance and runtime throughput, yet reports no quantitative metrics (accuracy, mAP, precision/recall, FPS, baselines, or error bars), preventing verification of whether the results support the real-time multi-view AR and usability claims.
- [§3] Synthetic data generation procedure (described in §3): the end-to-end pipeline depends on this procedure producing training data representative of real-world lighting, perspective, and occlusion variations so that models generalize to ordinary RGB footage; no domain-gap analysis, ablation studies, or transfer results on the real dataset are provided to substantiate this load-bearing assumption.
minor comments (1)
- Figure captions and pipeline diagrams could more explicitly label the multi-view fusion and broadcast composition stages for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the evaluation and analysis sections.
read point-by-point responses
-
Referee: [Abstract; evaluation section] Abstract and evaluation section: the manuscript states that models were evaluated on a manually annotated real-image dataset with analysis of performance and runtime throughput, yet reports no quantitative metrics (accuracy, mAP, precision/recall, FPS, baselines, or error bars), preventing verification of whether the results support the real-time multi-view AR and usability claims.
Authors: We agree that the evaluation section would be strengthened by explicit quantitative results. In the revised version we will report detection and identification accuracy, mAP, precision/recall, runtime FPS (with and without multi-view fusion), relevant baselines, and error bars computed over multiple runs on the manually annotated real-image dataset. revision: yes
-
Referee: [§3] Synthetic data generation procedure (described in §3): the end-to-end pipeline depends on this procedure producing training data representative of real-world lighting, perspective, and occlusion variations so that models generalize to ordinary RGB footage; no domain-gap analysis, ablation studies, or transfer results on the real dataset are provided to substantiate this load-bearing assumption.
Authors: The effectiveness of the synthetic-to-real transfer is central to the pipeline. While the manuscript already evaluates the resulting models on real images, we did not include explicit domain-gap quantification or ablations. In the revision we will add (i) an analysis of the domain gap (e.g., feature distribution distances), (ii) ablation studies on the synthetic data augmentations for lighting/perspective/occlusion, and (iii) detailed per-model transfer results comparing synthetic-only training against the real test set. revision: yes
Circularity Check
No circularity; pipeline is empirical engineering with external validation
full rationale
The paper describes a standard computer-vision pipeline (detection, orientation, identification) trained on automatically generated synthetic data from reference card images and evaluated on a separate manually annotated real-image dataset. No equations, derivations, or mathematical claims appear. No self-citations are invoked as load-bearing uniqueness theorems, no fitted parameters are relabeled as predictions, and no ansatz or renaming reduces the central claim to its own inputs by construction. The synthetic-to-real generalization is an empirical precondition that can be falsified by the held-out real test set; it is not circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data generated from reference card images is representative enough of real-world conditions for model training and generalization
Reference graph
Works this paper leans on
-
[1]
Presence: Teleoperators Vir- tual Environ.6(4), 355–385 (Aug 1997).https://doi.org/10.1162/pres
Azuma, R.T.: A survey of augmented reality. Presence: Teleoperators Vir- tual Environ.6(4), 355–385 (Aug 1997).https://doi.org/10.1162/pres. 1997.6.4.355
-
[2]
Github site,https://github
Backes, A.: Pokémon TCG SDK for Python. Github site,https://github. com/PokemonTCG/pokemon-tcg-sdk-python(2021)
2021
-
[3]
Big Orbit Cards: A brief history of trading card games.https : / / www.bigorbitcards.co.uk/blog/a-brief-history-of-trading-card- games.html(2023)
2023
-
[4]
Billinghurst, M., Clark, A., Lee, G.: A survey of augmented reality. Found. Trends®Human-Comput. Interact.8(2-3), 73–272 (Mar 2015).https:// doi.org/10.1561/1100000049
-
[5]
Bromley, J., Guyon, I., LeCun, Y., Säckinger, E., Shah, R.: Signature ver- ification using a “siamese” time delay neural network. In: Adv. Neural Inf. Process. Syst. (NeurIPS). vol. 6, pp. 737–744 (1993)
1993
-
[6]
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: Eur. Conf. Comput. Vis. (ECCV). Lect. Notes Comput. Sci., vol. 12346, pp. 213–229. Springer Int. Publ. (2020).https://doi.org/10.1007/978-3-030-58452-8_13
-
[7]
Chen, Q., Rigall, E., Wang, X., Fan, H., Dong, J.: Poker watcher: Playing card detection based on EfficientDet and sandglass block. In: Int. Conf. Aware. Sci. Technol. (icast). pp. 1–6. IEEE, Qingdao, China (Dec 2020). https://doi.org/10.1109/icast51195.2020.9319468
-
[8]
Chum, O., Pajdla, T., Sturm, P.: The geometric error for homographies. Comput. Vis. Image Underst.97(1), 86–102 (Jan 2005).https://doi. org/10.1016/j.cviu.2004.03.004
-
[9]
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describ- ing textures in the wild. In: IEEE Conf. Comput. Vis. Pattern Recog- nit. (CVPR). pp. 3606–3613. IEEE, Columbus, OH, USA (Jun 2014). https://doi.org/10.1109/cvpr.2014.461
-
[10]
Deng, J., Guo, J., Yang, J., Xue, N., Kotsia, I., Zafeiriou, S.: ArcFace: Additive angular margin loss for deep face recognition. IEEE Trans. Pattern Anal. Mach. Intell.44(10), 5962–5979 (Oct 2022).https://doi.org/10. 1109/tpami.2021.3087709
-
[11]
DeTone, D., Malisiewicz, T., Rabinovich, A.: SuperPoint: Self-supervised interest point detection and description. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Work. (CVPRW). pp. 337–33712. IEEE, Salt Lake City, UT, USA (Jun 2018).https://doi.org/10.1109/cvprw.2018.00060
-
[12]
Ding, J., Xue, N., Long, Y., Xia, G.S., Lu, Q.: Learning RoI transformer for oriented object detection in aerial images. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 2844–2853. IEEE, Long Beach, CA, USA (Jun 2019).https://doi.org/10.1109/cvpr.2019.00296 16 A. Cioppa
-
[13]
In: IEEE Int
Dwibedi, D., Misra, I., Hebert, M.: Cut, paste and learn: Surprisingly easy synthesis for instance detection. In: IEEE Int. Conf. Comput. Vis. (ICCV). pp. 1310–1319. IEEE, Venice, Italy (Oct 2017).https://doi.org/10. 1109/iccv.2017.146
2017
-
[14]
Web site
Eyevo: Eyevo: Pokémon TCG scanner. Web site
-
[15]
Fischler, M.A., Bolles, R.C.: Random sample consensus. Commun. ACM 24(6), 381–395 (Jun 1981).https://doi.org/10.1145/358669.358692
-
[16]
Fonder, M., Van Droogenbroeck, M.: Mid-air: A multi-modal dataset for ex- tremely low altitude drone flights. In: IEEE Int. Conf. Comput. Vis. Pattern Recognit. Work. (CVPRW), UAVision. pp. 553–562. IEEE, Long Beach, CA, USA (Jun 2019).https://doi.org/10.1109/cvprw.2019.00081
-
[17]
In: Robotics: Science and Systems XIII
Georgakis, G., Mousavian, A., Berg, A., Kosecka, J.: Synthesizing training data for object detection in indoor scenes. In: Robotics: Science and Systems XIII. vol. XIII, pp. 1–9. Cambridge, MA, USA (Jul 2017).https://doi. org/10.15607/rss.2017.xiii.043
-
[18]
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: IEEE Int. Conf. Comput.Vis.PatternRecognit.(CVPR).pp.580–587.Columbus,OH,USA (Jun 2014).https://doi.org/10.1109/CVPR.2014.81
-
[19]
Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learn- ing an invariant mapping. In: IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR). vol. 2, pp. 1735–1742. Inst. Electr. Electron. Eng. (IEEE), New York City, NY, USA (Jun 2006).https://doi.org/10.1109/CVPR.2006. 100
-
[20]
Zee- shan Zia, and Quoc-Huy Tran
Han, J., Ding, J., Xue, N., Xia, G.S.: ReDet: A rotation-equivariant detec- tor for aerial object detection. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 2785–2794. IEEE, Nashville, TN, USA (Jun 2021). https://doi.org/10.1109/cvpr46437.2021.00281
-
[21]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recogni- tion. In: IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 770–778. IEEE, Las Vegas, NV, USA (Jun 2016).https://doi.org/10.1109/CVPR. 2016.90
-
[22]
Swin transformer: Hierarchical vision transformer using shifted windows,
He, S., Luo, H., Wang, P., Wang, F., Li, H., Jiang, W.: TransReID: Transformer-based object re-identification. In: IEEE/CVF Int. Conf. Com- put. Vis. (ICCV). pp. 14993–15002. IEEE, Montréal, Can. (Oct 2021). https://doi.org/10.1109/iccv48922.2021.01474
-
[23]
Web site,https://www.hitscantcg.com(2025)
HitScanTCG: HitScanTCG: AI-powered card scanning for streamers. Web site,https://www.hitscantcg.com(2025)
2025
-
[24]
In: IEEE/CVF Int
Howard, A., Sandler, M., Chen, B., Wang, W., Chen, L.C., Tan, M., Chu, G., Vasudevan, V., Zhu, Y., Pang, R., Adam, H., Le, Q.: Searching for MobileNetV3. In: IEEE/CVF Int. Conf. Comput. Vis. (ICCV). pp. 1314–
- [25]
-
[26]
Web site,https://hypeoverlay.com(2026) TCG-AR 17
Hype Overlay: Hype Overlay: OBS-native trading card game scanner. Web site,https://hypeoverlay.com(2026) TCG-AR 17
2026
-
[27]
Kendall, A., Cipolla, R.: Modelling uncertainty in deep learning for camera relocalization. In: IEEE Int. Conf. Robot. Autom. (ICRA). pp. 4762–4769. IEEE, Stockholm, Sweden (May 2016).https://doi.org/10.1109/icra. 2016.7487679
-
[28]
Kendall, A., Grimes, M., Cipolla, R.: PoseNet: A convolutional network for real-time 6-DOF camera relocalization. In: IEEE Int. Conf. Comput. Vis. (ICCV). pp. 2938–2946. Inst. Electr. Electron. Eng. (IEEE), Santiago, Chile (Dec 2015).https://doi.org/10.1109/iccv.2015.336
-
[29]
Lam, A.H.T., Chow, K.C.H., Yau, E.H.H., Lyu, M.R.: ART: augmented reality table for interactive trading card game. In: ACM Int. Conf. Virtual Real. Contin. Its Appl. pp. 357–360. ACM, Hong Kong, China (Jun 2006). https://doi.org/10.1145/1128923.1128987
-
[30]
In: PerGames
Lee, W., Woo, W., Lee, J.: TARBoard: Tangible augmented reality system for table-top game environment. In: PerGames. pp. 1–5. Munich, Germany (May 2005)
2005
-
[31]
Lin, T.Y., Dollar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Featurepyramidnetworks forobjectdetection.In:IEEEInt.Conf.Comput. Vis. Pattern Recognit. (CVPR). pp. 2117–2125. Honolulu, HI, USA (Jul 2017).https://doi.org/10.1109/CVPR.2017.106
-
[32]
Focal Loss for Dense Object Detection
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollar, P.: Focal loss for dense object detection. arXivabs/1708.02002(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: LightGlue: Local feature matching at light speed. In: IEEE/CVF Int. Conf. Comput. Vis. (ICCV). pp. 17581–17592. IEEE, Paris, Fr. (Oct 2023).https://doi.org/10.1109/ iccv51070.2023.01616
-
[34]
SSD: Single Shot MultiBox Detector
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.: SSD: Single shot multibox detector. arXivabs/1512.02325(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Lowe, D.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis.60(2), 91–110 (Nov 2004)
2004
-
[36]
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: ShuffleNet v2: Practical guide- lines for efficient CNN architecture design. In: Eur. Conf. Comput. Vis. (ECCV). Lect. Notes Comput. Sci., vol. 11218, pp. 122–138. Springer Int. Publ. (2018).https://doi.org/10.1007/978-3-030-01264-9_8
-
[37]
arXivabs/2106.03146(2021).https : / / doi
Ma, T., Mao, M., Zheng, H., Gao, P., Wang, X., Han, S., Ding, E., Zhang, B., Doermann, D.: Oriented object detection with transformer. arXivabs/2106.03146(2021).https : / / doi . org / 10 . 48550 / arXiv . 2106.03146
-
[38]
Marchand, E., Uchiyama, H., Spindler, F.: Pose estimation for augmented reality: A hands-on survey. IEEE Trans. Vis. Comput. Graph.22(12), 2633– 2651 (Dec 2016).https://doi.org/10.1109/tvcg.2015.2513408
-
[39]
Mittal, K., Gill, K.S., Chauhan, R., Sharma, M., Sunil, G.: Playing cards classification and detection using sequential CNN model through machine learning techniques using artificial intelligence. In: Int. Conf. E-mobility, Power Control Smart Syst. (ICEMPS). pp. 1–4. IEEE, Thiruvananthapu- ram, India (Apr 2024).https://doi.org/10.1109/icemps60684.2024. 1...
-
[40]
Movshovitz-Attias, Y., Toshev, A., Leung, T.K., Ioffe, S., Singh, S.: No fuss distance metric learning using proxies. In: IEEE Int. Conf. Comput. Vis. (ICCV). pp. 360–368. IEEE, Venice, Italy (Oct 2017).https://doi.org/ 10.1109/iccv.2017.47
-
[41]
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot.31(5), 1147–1163 (Oct 2015).https://doi.org/10.1109/tro.2015.2463671
-
[42]
Musgrave, K., Belongie, S., Lim, S.N.: A metric learning reality check. In: Eur. Conf. Comput. Vis. (ECCV). Lect. Notes Comput. Sci., vol. 12370, pp. 681–699. Springer Int. Publ. (2020).https://doi.org/10.1007/978- 3-030-58595-2_41
-
[43]
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 779–788. Inst. Electr. Electron. Eng. (IEEE), Las Vegas, NV, USA (Jun 2016).https://doi.org/10.1109/cvpr.2016.91
-
[44]
Rematas, K., Kemelmacher-Shlizerman, I., Curless, B., Seitz, S.: Soccer on your tabletop. In: IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 4738–4747. Salt Lake City, UT, USA (Jun 2018).https://doi.org/ 10.1109/CVPR.2018.00498
-
[45]
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell.39(6), 1137–1149 (Jun 2017).https://doi.org/10.1109/ TPAMI.2016.2577031
-
[46]
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: Ground truth from computer games. In: Eur. Conf. Comput. Vis. (ECCV). Lect. Notes Comput. Sci., vol. 9906, pp. 102–118. Springer Int. Publ. (2016). https://doi.org/10.1007/978-3-319-46475-6_7
-
[47]
Ros, G., Sellart, L., Materzynska, J., Vazquez, D., Lopez, A.M.: The SYN- THIA dataset: A large collection of synthetic images for semantic seg- mentation of urban scenes. In: IEEE Conf. Comput. Vis. Pattern Recog- nit. (CVPR). pp. 3234–3243. IEEE, Las Vegas, NV, USA (Jun 2016). https://doi.org/10.1109/cvpr.2016.352
-
[48]
Rublee, E., Rabaud, V., Konolige, K., Bradski, G.: ORB: An efficient al- ternative to SIFT or SURF. In: IEEE Int. Conf. Comput. Vis. (ICCV). pp. 2564–2571. IEEE, Barcelona, Spain (Nov 2011).https://doi.org/10. 1109/iccv.2011.6126544
-
[49]
Sarlin,P.E.,DeTone,D.,Malisiewicz,T.,Rabinovich,A.:SuperGlue:Learn- ing feature matching with graph neural networks. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 4937–4946. IEEE, Seattle, WA, USA (Jun 2020).https://doi.org/10.1109/CVPR42600.2020. 00499
-
[50]
Schroff, F., Kalenichenko, D., Philbin, J.: FaceNet: A unified embedding for face recognition and clustering. In: IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 815–823. IEEE, Boston, MA, USA (Jun 2015). https://doi.org/10.1109/cvpr.2015.7298682 TCG-AR 19
-
[51]
Scrydex: Scrydex: TCG API and toolkit for pokémon, magic, lorcana, and yu-gi-oh! Web site,https://scrydex.com(2025)
2025
-
[52]
Sohn, K.: Improved deep metric learning with multi-class N-pair loss objec- tive. In: Adv. Neural Inf. Process. Syst. (NeurIPS). vol. 29, pp. 1857–1865. Curran Assoc. Inc., Barcelona, Spain (Dec 2016)
2016
-
[53]
Somers, V.: Person Re-Identification and its Application to Multi-Object Tracking. Ph.D. thesis, Cathol. Univ. Louvain, Belg. (May 1995)
1995
-
[54]
Somers, V., De Vleeschouwer, C., Alahi, A.: Body part-based representation learning for occluded person re-identification. In: IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV). pp. 1613–1623. IEEE, Waikoloa, HI, USA (Jan 2023).https://doi.org/10.1109/wacv56688.2023.00166
-
[55]
statista.com/statistics/672617/most-valuable-pokemon-trading- cards/(2025)
Statista: Pokémon trading card game - statistics & facts.https://www. statista.com/statistics/672617/most-valuable-pokemon-trading- cards/(2025)
2025
-
[56]
Zee- shan Zia, and Quoc-Huy Tran
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: LoFTR: Detector-free local feature matching with transformers. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 8918–8927. IEEE, Nashville, TN, USA (Jun 2021).https://doi.org/10.1109/cvpr46437.2021.00881
-
[57]
youtube.com/watch?v=64-LfbggqKI
SuperZouloux:LerêvedetouslesfansdeYu-Gi-Oh!YouTubevideo,https: //www.youtube.com/watch?v=64-LfbggqKI(Oct 2005),https://www. youtube.com/watch?v=64-LfbggqKI
2005
-
[58]
PMLR, Long Beach, CA, USA (Jun 2019)
Tan, M., Le, Q.V.: EfficientNet: Rethinking model scaling for convolutional neuralnetworks.In:Int.Conf.Mach.Learn.(ICML).vol.97,pp.6105–6114. PMLR, Long Beach, CA, USA (Jun 2019)
2019
-
[59]
Tan, M., Pang, R., Le, Q.V.: EfficientDet: Scalable and efficient object de- tection. In: IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 10778–10787. Seattle, WA, USA (Jun 2020).https://doi.org/10.1109/ CVPR42600.2020.01079
-
[60]
https://worlds.2025.pokemon.com/en-us/championships/(2025)
The Pokémon Company International: 2025 pokémon world championships. https://worlds.2025.pokemon.com/en-us/championships/(2025)
2025
-
[61]
The Pokémon Company International: Media alert: Pokémon unveils new pokémon trading card game: 30th celebration expansion, commemorat- ing 30 years.https://press.pokemon.com/en/releases/MEDIA-ALERT- Pokemon - Unveils - New - Pokemon - Trading - Card - Game - 30th - Celebra (2026)
2026
- [62]
-
[63]
Tian, Z., Shen, C., Chen, H., He, T.: FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell.44(4), 1922–1933 (Apr 2020).https://doi.org/10.1109/tpami.2020.3032166
-
[64]
Tobin,J.,Fong,R.,Ray,A.,Schneider,J.,Zaremba,W.,Abbeel,P.:Domain randomization for transferring deep neural networks from simulation to the real world. In: IEEE/RSJ Int. Conf. Intell. Robot. Syst. (IROS). pp. 23–30. IEEE, Vancouver, Can. (Sept 2017).https://doi.org/10.1109/iros. 2017.8202133 20 A. Cioppa
-
[65]
Tremblay, J., Prakash, A., Acuna, D., Brophy, M., Jampani, V., Anil, C., To, T., Cameracci, E., Boochoon, S., Birchfield, S.: Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Work. (CVPRW). pp. 1082–10828. IEEE, Salt Lake City, UT, USA (Jun 2018).https://doi. or...
-
[66]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, X., Han, X., Huang, W., Dong, D., Scott, M.R.: Multi-similarity loss with general pair weighting for deep metric learning. In: IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). pp. 5017–5025. IEEE, Long Beach, CA, USA (Jun 2019).https://doi.org/10.1109/cvpr.2019. 00516
-
[67]
Woods, D.L., Wyma, J.M., Yund, E.W., Herron, T.J., Reed, B.: Factors influencing the latency of simple reaction time. Front. Hum. Neurosci.9 (Mar 2015).https://doi.org/10.3389/fnhum.2015.00131
-
[68]
In: IEEE Int
Wu, C.Y., Manmatha, R., Smola, A.J., Krahenbuhl, P.: Sampling matters in deep embedding learning. In: IEEE Int. Conf. Comput. Vis. (ICCV). pp. 2859–2867. IEEE, Venice, Italy (Oct 2017).https://doi.org/10.1109/ iccv.2017.309
2017
-
[69]
arXivabs/2109.11861(2021).https://doi.org/10.48550/ arXiv.2109.11861
Wzorek, P., Kryjak, T.: Training dataset generation for bridge game reg- istration. arXivabs/2109.11861(2021).https://doi.org/10.48550/ arXiv.2109.11861
-
[70]
Xie, X., Cheng, G., Wang, J., Yao, X., Han, J.: Oriented r-CNN for object detection. In: IEEE/CVF Int. Conf. Comput. Vis. (ICCV). pp. 3500–3509. IEEE,Montréal,Can. (Oct2021).https://doi.org/10.1109/iccv48922. 2021.00350
-
[71]
Xu, Y., Fu, M., Wang, Q., Wang, Y., Chen, K., Xia, G.S., Bai, X.: Glid- ing vertex on the horizontal bounding box for multi-oriented object detec- tion. IEEE Trans. Pattern Anal. Mach. Intell.43(4), 1452–1459 (Apr 2021). https://doi.org/10.1109/tpami.2020.2974745
-
[72]
Yang, X., Yan, J., Feng, Z., He, T.: R3Det: Refined single-stage detec- tor with feature refinement for rotating object. In: AAAI Conf. Artif. In- tell. vol. 35, pp. 3163–3171. Assoc. Adv. Artif. Intell. (AAAI) (May 2021). https://doi.org/10.1609/aaai.v35i4.16426
-
[73]
Ye, M., Chen, S., Li, C., Zheng, W.S., Crandall, D., Du, B.: Transformer for object re-identification: A survey. Int. J. Comput. Vis.133(5), 2410–2440 (Nov 2024).https://doi.org/10.1007/s11263-024-02284-4
-
[74]
Yi, D., Lei, Z., Liao, S., Li, S.Z.: Deep metric learning for person re- identification. In: Int. Conf. Pattern Recognit. (ICPR). pp. 34–39. IEEE, Stockholm, Sweden (Aug 2014).https://doi.org/10.1109/icpr.2014. 16
-
[75]
Zhai, A., Wu, H.Y.: Classification is a strong baseline for deep metric learn- ing. arXivabs/1811.12649(2018).https://doi.org/10.48550/arXiv. 1811.12649
work page internal anchor Pith review doi:10.48550/arxiv 2018
-
[76]
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing through ADE20K dataset. In: IEEE Conf. Comput. Vis. Pattern TCG-AR 21 Recognit. (CVPR). pp. 5122–5130. IEEE, Honolulu, HI, USA (Jul 2017). https://doi.org/10.1109/cvpr.2017.544 22 A. Cioppa 7 Supplementary Material This appendix presents more information about the interfac...
-
[77]
this energy powers that Pokémon,
A linear warm-up over500iterations (ratio1/3) precedes a step schedule that divides the learning rate by10at epochs2and4. Training runs for5epochs with a batch size of2images on one GPU (∼9,000iterations/epoch over the18,000 training images); a checkpoint is saved every epoch. The RPN uses anchors of scale8with aspect ratios{0.5,1,2}over strides{4,8,16,32...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.