Efficient PEFT Methods with Adaptive Checkpointing for Vision Models and VLMs on Resource Constrained Consumer-GPUs
Pith reviewed 2026-07-03 15:18 UTC · model grok-4.3
The pith
QLoRA and BitFit cut energy use 20-30% for vision model fine-tuning on 2GB GPUs at a 1-2% accuracy cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
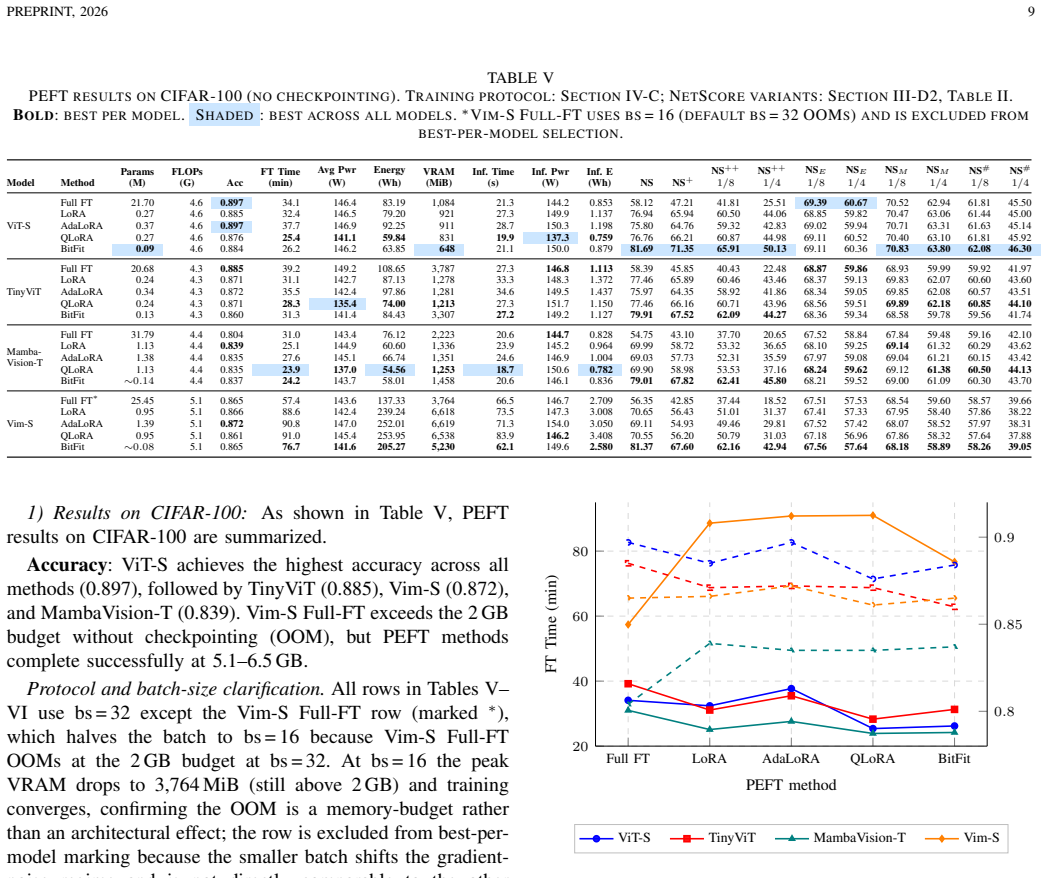
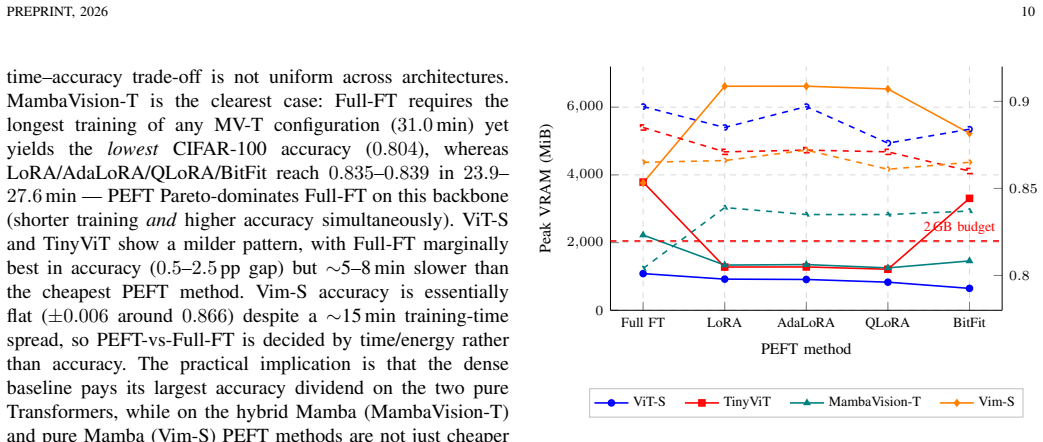
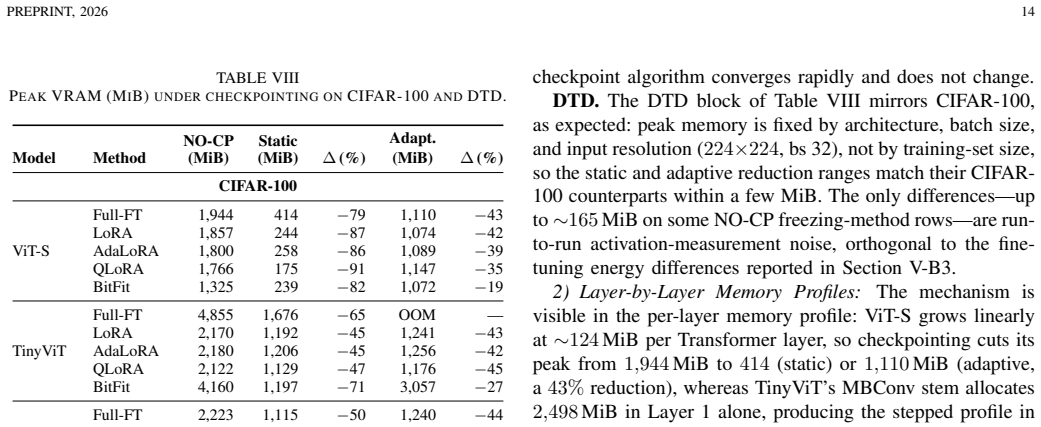
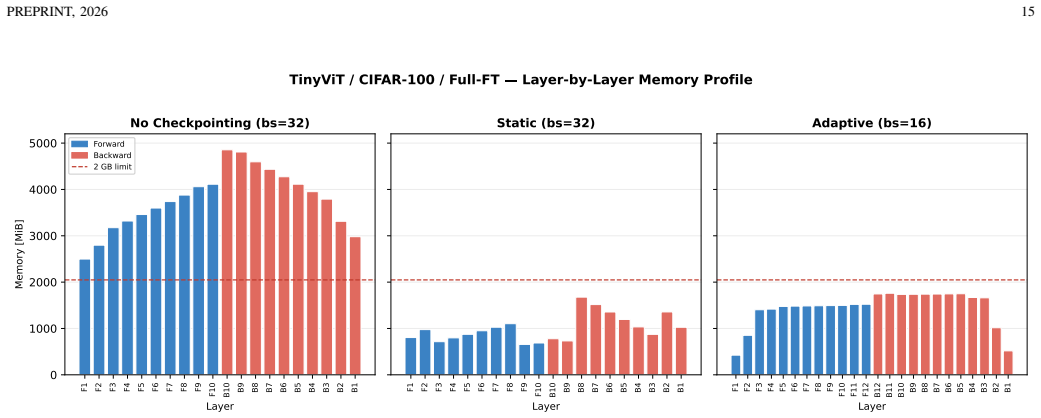
Under a fixed 2 GB VRAM budget the paper claims that QLoRA and BitFit achieve 20-30% lower energy consumption than full fine-tuning at a 1-2% accuracy penalty on CIFAR-100 and DTD. The memory-budget-aware adaptive gradient-checkpointing algorithm reduces peak memory usage 43-79% while adding only 9-30% energy overhead. DINOv2 records 0.917 accuracy on CIFAR-100 against 0.897 for the best fine-tuned models and does so at a fraction of the energy cost. The comparisons cover ViT-Small, TinyViT, Vim-Small and MambaVision-T together with zero-shot and lightly evaluated foundation-model baselines.
What carries the argument
memory-budget-aware adaptive gradient-checkpointing algorithm that dynamically selects checkpoint locations to stay inside a target VRAM limit
If this is right
- QLoRA and BitFit become practical defaults for energy-constrained fine-tuning of both transformer and Mamba vision backbones.
- The adaptive checkpointing method makes fine-tuning feasible inside 2 GB VRAM envelopes that would otherwise cause out-of-memory failures.
- DINOv2 supplies a lower-energy alternative that can exceed the accuracy of PEFT-tuned models on CIFAR-100.
- Extended NetScore metrics that incorporate deployment-aware memory and energy terms become usable for ranking methods under consumer-GPU constraints.
Where Pith is reading between the lines
- The same adaptive checkpointing logic could be ported to other memory-constrained training regimes such as on-device personalization of mobile vision models.
- If the energy advantage of DINOv2 persists across additional datasets it would reduce the incentive to fine-tune at all in low-resource settings.
- Mamba-based vision backbones appear to respond to PEFT and checkpointing in the same qualitative way as transformers, suggesting the techniques are backbone-agnostic within the tested size range.
Load-bearing premise
The accuracy, energy and memory numbers measured on ViT-Small, TinyViT, Vim-Small, MambaVision-T with CIFAR-100 and DTD under a fixed 2 GB VRAM budget will generalize to other models, datasets and real consumer-GPU deployments.
What would settle it
Re-running the identical protocol on ImageNet or with a 4 GB VRAM budget and observing that QLoRA and the adaptive checkpointing no longer produce the reported energy and memory gains.
Figures
read the original abstract
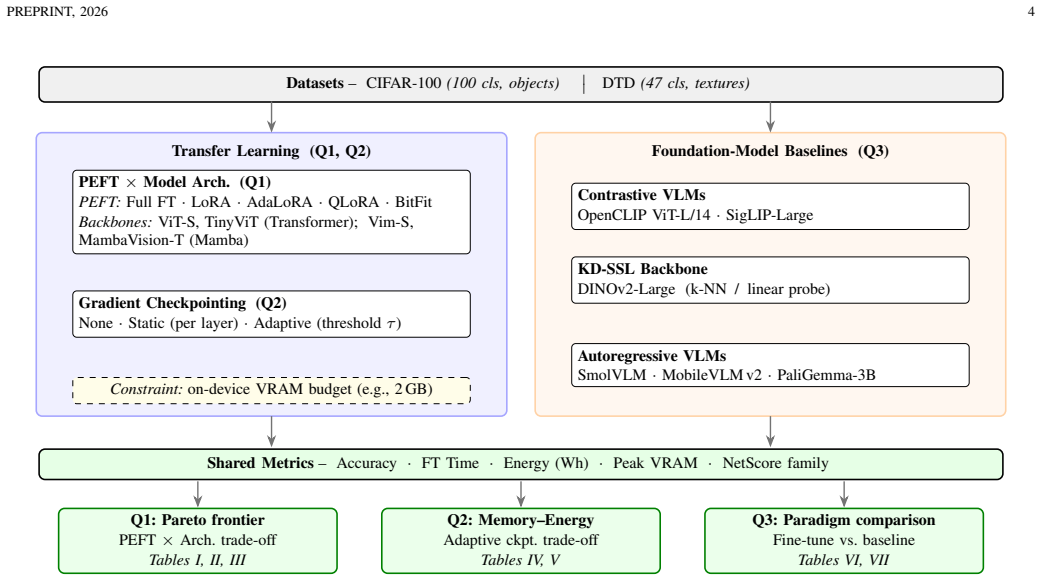
Modern pretrained vision models achieve strong accuracy but demand substantial GPU memory for fine-tuning, making edge deployment impractical. This paper compares five parameter-efficient fine-tuning (PEFT) methods (Full FT, LoRA, AdaLoRA, QLoRA, BitFit) on Transformers- (ViT-Small, TinyViT) and Mamba-based vision backbones (Vim-Small, MambaVision-T) under an on-device VRAM budget (e.g., 2 GB), together with three gradient-checkpointing strategies (none, static, and a proposed memory-budget-aware adaptive algorithm); and we evaluate three families of foundation-model baselines: zero-shot contrastive vision language models (OpenCLIP, SigLIP), self-supervised vision backbones with lightweight evaluation protocols (DINOv2), and autoregressive VLMs for prompt-based classification (PaliGemma, MobileVLM, SmolVLM). Experiments on CIFAR-100 and DTD report accuracy, training time, energy, and the NetScore family of multi-objective metrics, which we extend with two deployment-aware variants. QLoRA and BitFit cut energy 20-30% at a 1-2% accuracy cost; the adaptive algorithm reduces peak memory 43-79% with 9-30% energy overhead. DINOv2 surpasses fine-tuned models on CIFAR-100 (0.917 vs. 0.897) at a fraction of the energy, while small autoregressive VLMs remain uncompetitive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents an empirical comparison of parameter-efficient fine-tuning (PEFT) methods (Full FT, LoRA, AdaLoRA, QLoRA, BitFit) and gradient checkpointing strategies (none, static, adaptive) for vision Transformers and Mamba models under a constrained 2GB VRAM budget. It evaluates these on CIFAR-100 and DTD datasets, reporting accuracy, energy consumption, training time, and extended NetScore metrics, while also benchmarking against zero-shot VLMs and self-supervised models like DINOv2. Key claims include 20-30% energy savings with QLoRA/BitFit at minor accuracy cost, 43-79% peak memory reduction via adaptive checkpointing, and superior performance of DINOv2 on CIFAR-100 with lower energy.
Significance. If the empirical results hold under broader conditions, this work provides practical guidance for energy-efficient fine-tuning of vision models on consumer GPUs with limited VRAM. The extension of the NetScore family with deployment-aware variants and the direct comparison to foundation-model baselines (including DINOv2) are strengths that support multi-objective evaluation.
major comments (2)
- [Abstract] Abstract: the abstract states specific quantitative outcomes (QLoRA/BitFit energy savings of 20-30%, adaptive checkpointing memory reduction of 43-79%) but the manuscript provides no full methods description, error bars, statistical details, or raw data to allow verification of support for these central claims.
- [Experimental evaluation] Experimental evaluation: the claims rest on a narrow setup (ViT-Small/TinyViT/Vim-Small/MambaVision-T, CIFAR-100/DTD, fixed 2GB VRAM) with no scaling curves, resolution ablations, or cross-hardware tests; this undermines generalization to broader consumer-GPU deployment scenarios asserted in the introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states specific quantitative outcomes (QLoRA/BitFit energy savings of 20-30%, adaptive checkpointing memory reduction of 43-79%) but the manuscript provides no full methods description, error bars, statistical details, or raw data to allow verification of support for these central claims.
Authors: Section 3 and the appendix fully specify the models, PEFT ranks, quantization bits, adaptive checkpointing logic (including the memory-budget threshold and recomputation policy), training hyperparameters, and NetScore extensions. We agree that error bars and run counts are absent. In revision we will report mean ± std over three random seeds for the headline energy and memory figures and state the number of trials explicitly. Code and per-run logs will be released with the camera-ready version. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation: the claims rest on a narrow setup (ViT-Small/TinyViT/Vim-Small/MambaVision-T, CIFAR-100/DTD, fixed 2GB VRAM) with no scaling curves, resolution ablations, or cross-hardware tests; this undermines generalization to broader consumer-GPU deployment scenarios asserted in the introduction.
Authors: The introduction explicitly positions the work as addressing the 2 GB VRAM consumer-GPU regime; the chosen backbones and datasets are the largest that fit this budget while remaining representative. We do not assert results outside this constraint. We will add a limitations subsection that reiterates the scoped setting and notes the absence of scaling or cross-device experiments as future work. revision: partial
Circularity Check
No circularity; purely empirical comparisons with no derivations
full rationale
The manuscript contains no equations, derivations, or predictive claims that could reduce to inputs by construction. All reported results (accuracy, energy, memory deltas for QLoRA/BitFit/adaptive checkpointing) are direct experimental measurements on fixed models (ViT-Small, TinyViT, Vim-Small, MambaVision-T), datasets (CIFAR-100, DTD), and a 2 GB VRAM budget. No fitted parameters are relabeled as predictions, no self-citation chains support load-bearing premises, and no ansatzes or uniqueness theorems are invoked. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Tinyvit: Fast pretraining distillation for small vision transformers,
K. Wu, J. Zhang, H. Peng, M. Liu, B. Xiao, J. Fu, and L. Yuan, “Tinyvit: Fast pretraining distillation for small vision transformers,” inEuropean Conference on Computer Vision, 2022, pp. 68–85
2022
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,”arXiv preprint arXiv:2401.09417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Mambavision: A hybrid mamba- transformer vision backbone,
A. Hatamizadeh and J. Kautz, “Mambavision: A hybrid mamba- transformer vision backbone,”arXiv preprint arXiv:2407.08083, 2024
-
[6]
Jetson nano developer kit: Module data sheet,
NVIDIA Corporation, “Jetson nano developer kit: Module data sheet,” https://developer.nvidia.com/embedded/jetson-nano-developer-kit, 2020, 5–10 W power profiles; Accessed 2026
2020
-
[7]
GeForce GTX 1650 graphics card: Specifications,
——, “GeForce GTX 1650 graphics card: Specifications,” https://www. nvidia.com/en-us/geforce/graphics-cards/16-series/geforce-gtx-1650/, 2019, 75 W TDP; Accessed 2026
2019
-
[8]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, “Carbon emissions and large neural network training,”arXiv preprint arXiv:2104.10350, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
NVIDIA H100 tensor core gpu datasheet,
NVIDIA Corporation, “NVIDIA H100 tensor core gpu datasheet,” https://resources.nvidia.com/en-us-tensor-core/ nvidia-tensor-core-gpu-datasheet, 2023, up to 700 W TDP (SXM5); Accessed 2026
2023
-
[10]
Green ai,
R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni, “Green ai,” Communications of the ACM, vol. 63, no. 12, pp. 54–63, 2020
2020
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Qlora: Efficient finetuning of quantized language models,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized language models,”Advances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[14]
Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,
E. Ben-Zaken, Y . Goldberg, and S. Ravfogel, “Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,” arXiv preprint arXiv:2106.10199, 2021
-
[15]
Training Deep Nets with Sublinear Memory Cost
T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training deep nets with sublinear memory cost,”arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[17]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, “Training data-efficient image transformers & distillation through attention,” inInternational Conference on Machine Learning, 2021, pp. 10 347–10 357
2021
-
[18]
Swin Transformer: Hierarchical vision transformer using shifted win- dows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical vision transformer using shifted win- dows,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10 012–10 022
2021
-
[19]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. Ré, “Efficiently modeling long sequences with structured state spaces,” inInternational Conference on Learning Representations, 2022. PREPRINT, 2026 20
2022
-
[20]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” inProceedings of the 36th International Conference on Machine Learning (ICML), 2019, pp. 2790–2799
2019
-
[21]
AdapterHub: A framework for adapting transformers,
J. Pfeiffer, A. Rücklé, C. Poth, A. Kamath, I. Vuli ´c, S. Ruder, K. Cho, and I. Gurevych, “AdapterHub: A framework for adapting transformers,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020, pp. 46–54
2020
-
[22]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,”arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Dynamic tensor rematerialization,
M. Kirisame, S. Lyubomirsky, A. Haan, J. Brennan, M. He, J. Roesch, T. Chen, and Z. Tatlock, “Dynamic tensor rematerialization,”arXiv preprint arXiv:2006.09616, 2020
-
[24]
Checkmate: Breaking the memory wall with optimal tensor rematerialization,
P. Jain, A. Jain, A. Nrusimha, A. Gholami, P. Abbeel, J. Gonzalez, K. Keutzer, and I. Stoica, “Checkmate: Breaking the memory wall with optimal tensor rematerialization,” inProceedings of Machine Learning and Systems, vol. 2, 2020, pp. 497–511
2020
-
[25]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inInternational Conference on Machine Learning, 2021, pp. 8748–8763
2021
-
[26]
Reproducible scaling laws for contrastive language-image learning,
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev, “Reproducible scaling laws for contrastive language-image learning,”arXiv preprint arXiv:2212.07143, 2023
-
[27]
Sigmoid Loss for Language Image Pre-Training
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,”arXiv preprint arXiv:2303.15343, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9650–9660
2021
-
[30]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello et al., “Paligemma: A versatile 3b vlm for transfer,”arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
X. Chu, L. Qiao, X. Zhang, S. Xu, F. Wei, Y . Yang, X. Sun, Y . Hu, X. Lin, B. Zhanget al., “Mobilevlm v2: Faster and stronger baseline for vision language model,”arXiv preprint arXiv:2402.03766, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
SmolVLM: Redefining small and efficient multimodal models
L. B. Allal, A. Lozhkov, O. Penber, T. Wolf, and R. Lacroix, “Smolvlm: Redefining small and efficient multimodal models,”arXiv preprint arXiv:2504.05299, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Energy and policy consid- erations for deep learning in nlp,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consid- erations for deep learning in nlp,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 3645–3650
2019
-
[34]
Towards the systematic reporting of the energy and carbon footprints of machine learning,
P. Henderson, J. Hu, J. Romoff, E. Brunskill, D. Jurafsky, and J. Pineau, “Towards the systematic reporting of the energy and carbon footprints of machine learning,”Journal of Machine Learning Research, vol. 21, no. 248, pp. 1–43, 2020
2020
-
[35]
The com- putational limits of deep learning,
N. C. Thompson, K. Greenewald, K. Lee, and G. F. Manso, “The com- putational limits of deep learning,”arXiv preprint arXiv:2007.05558, 2020
-
[36]
A. Wong, “NetScore: Towards universal metrics for large-scale perfor- mance analysis of deep neural networks for practical on-device edge usage,”arXiv preprint arXiv:1806.05512, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
A. Wong, M. Famouri, M. Pavlova, and M. J. Shafiee, “AttoNets: Compact and efficient deep neural networks for the edge via human- machine collaborative design,”arXiv preprint arXiv:1903.07209, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[38]
SLNet: A super-lightweight geometry-adaptive network for 3D point cloud recognition,
Anonymous, “SLNet: A super-lightweight geometry-adaptive network for 3D point cloud recognition,”arXiv preprint arXiv:2603.07454, 2026
-
[39]
How green is continual learning, really? analyzing the energy consumption in continual training of vision foundation models,
C. González, T. Deschamps, M. Cord, and P. Pérez, “How green is continual learning, really? analyzing the energy consumption in continual training of vision foundation models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
2024
-
[40]
An attention-based feature memory design for energy-efficient continual learning,
Y . Shi and J. G. Park, “An attention-based feature memory design for energy-efficient continual learning,”IEEE Access, 2024
2024
-
[41]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[42]
Pytorch image models,
R. Wightman, “Pytorch image models,” https://github.com/rwightman/ pytorch-image-models, 2019, accessed: 2024
2019
-
[43]
Peft: State-of-the-art parameter-efficient fine-tuning methods,
S. Mangrulkar, S. Gugger, L. Debut, Y . Belkada, and S. Paul, “Peft: State-of-the-art parameter-efficient fine-tuning methods,” https://github. com/huggingface/peft, 2023, accessed: 2024
2023
-
[44]
8-bit optimizers via block-wise quantization,
T. Dettmers, M. Lewis, S. Shleifer, and L. Zettlemoyer, “8-bit optimizers via block-wise quantization,” inInternational Conference on Learning Representations, 2022
2022
-
[45]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019
2019
-
[46]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep., 2009
2009
-
[47]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255
2009
-
[48]
Describing textures in the wild,
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 3606– 3613
2014
-
[49]
Why are visually-grounded language models bad at image classification?
Y . Zhang, A. Unell, X. Wang, D. Ghosh, Y . Su, L. Schmidt, and S. Yeung-Levy, “Why are visually-grounded language models bad at image classification?” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[50]
Rethinking VLMs and LLMs for image classification,
A. Epstein, T. Reusch, O. Caelen, and S. Maréchal, “Rethinking VLMs and LLMs for image classification,”Scientific Reports, 2025, arXiv preprint arXiv:2410.14690
-
[51]
Neural Machine Translation of Rare Words with Subword Units
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), 2016, arXiv preprint arXiv:1508.07909
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[52]
T. Kudo and J. Richardson, “SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text process- ing,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP): System Demonstrations, 2018, arXiv preprint arXiv:1808.06226
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
What does a platypus look like? Generating customized prompts for zero-shot image classification,
S. Pratt, I. Covert, R. Liu, and A. Farhadi, “What does a platypus look like? Generating customized prompts for zero-shot image classification,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[54]
Visual classification via description from large language models,
S. Menon and C. V ondrick, “Visual classification via description from large language models,” inInternational Conference on Learning Rep- resentations (ICLR), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.