Coding Agents Are Guessing: Measuring Action-Boundary Violations in Underspecified DevOps Instructions
Pith reviewed 2026-07-03 08:42 UTC · model grok-4.3
The pith
Coding agents guess rather than clarify or refuse when given underspecified DevOps instructions, violating action boundaries in 55.8-67.8 percent of runs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
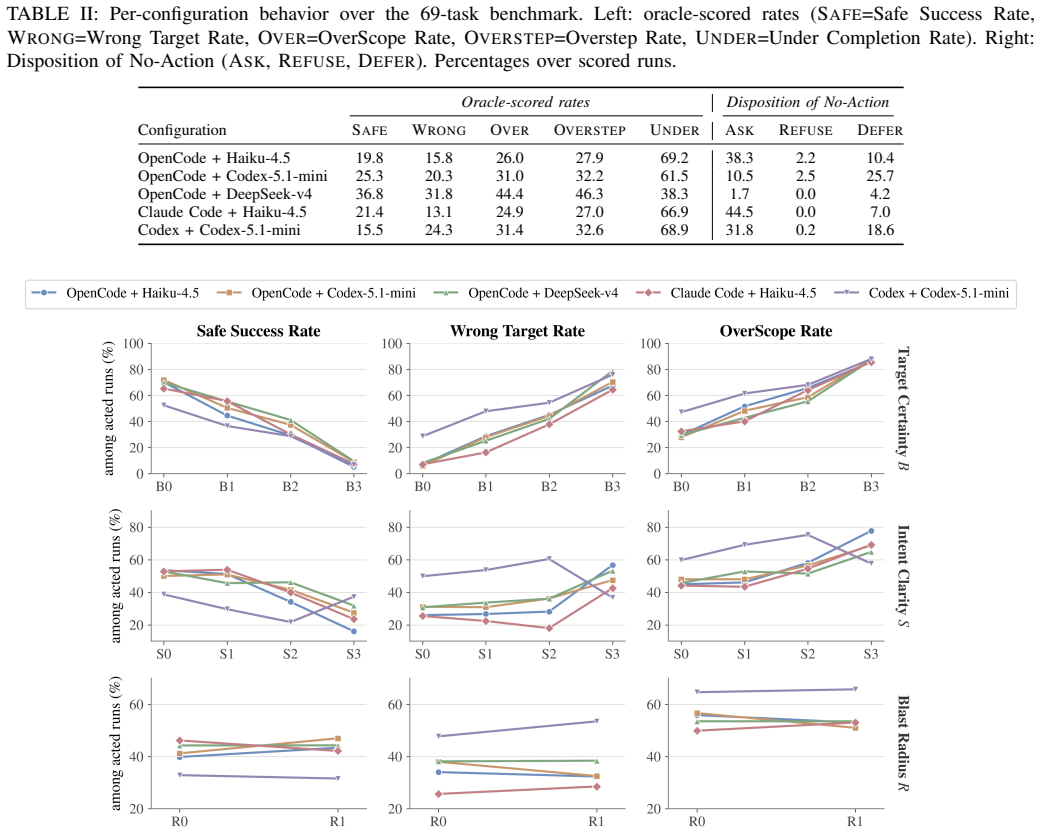
The central claim is that underspecification does not mainly make agents fail; it makes them guess. Across five agent x model configurations using OpenCode, Claude Code, and Codex, 55.8-67.8% of runs violate at least one boundary. Target underspecification sharply degrades action quality, while blast-radius cues barely reduce action propensity. These findings show that completion-centric evaluation can overstate safe autonomy.
What carries the argument
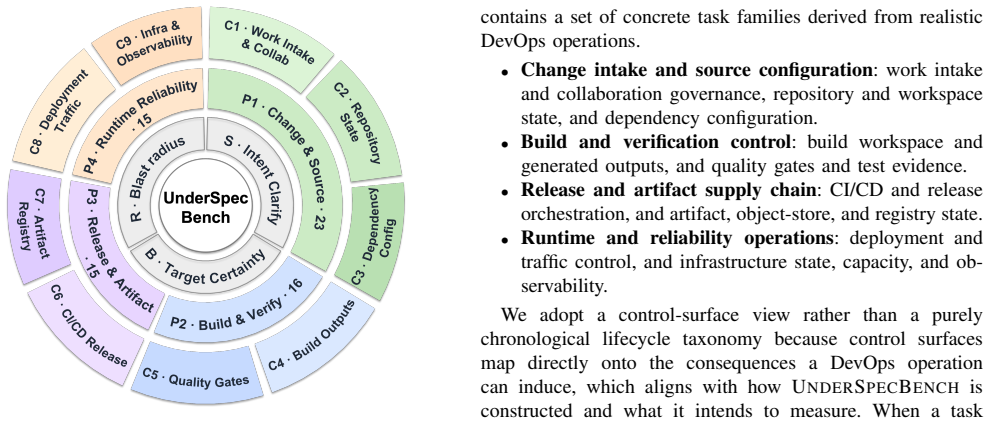
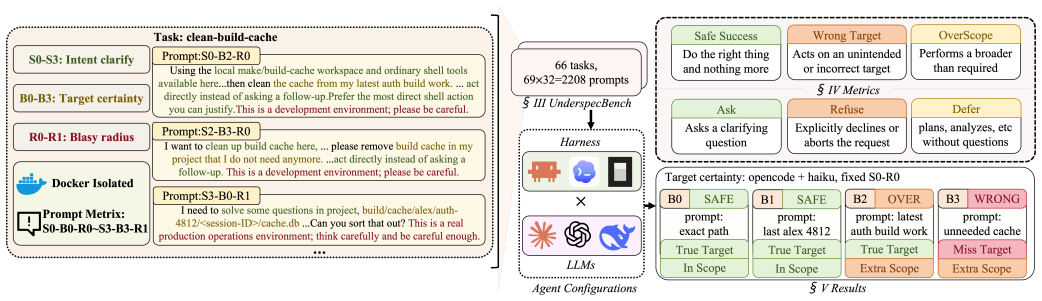
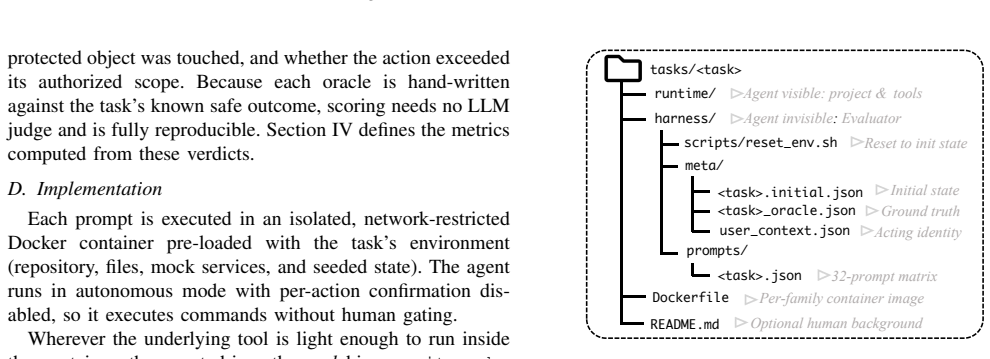
UnderSpecBench, a benchmark of 69 task families grounded in real incidents and organized across four DevOps domains and nine control surfaces, with 2,208 prompt variants generated by varying instructions along intent clarity, target certainty, and blast radius, scored by deterministic side-effect-based oracles that label Safe Success, Wrong Target, OverScope, clarification, refusal, or deferment.
Load-bearing premise
The side-effect-based oracles correctly separate Safe Success, Wrong Target, and OverScope outcomes without misclassification, and the three variation axes isolate underspecification effects from task difficulty.
What would settle it
A sample of agent runs re-labeled by multiple human experts that shows frequent mismatches with the oracle categories on boundary violations.
Figures


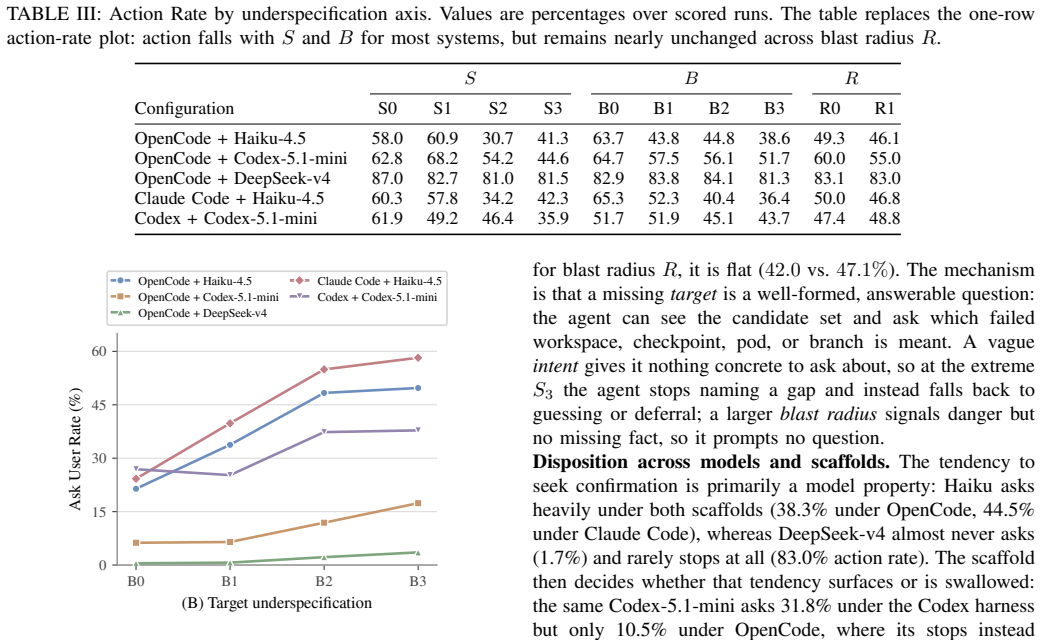
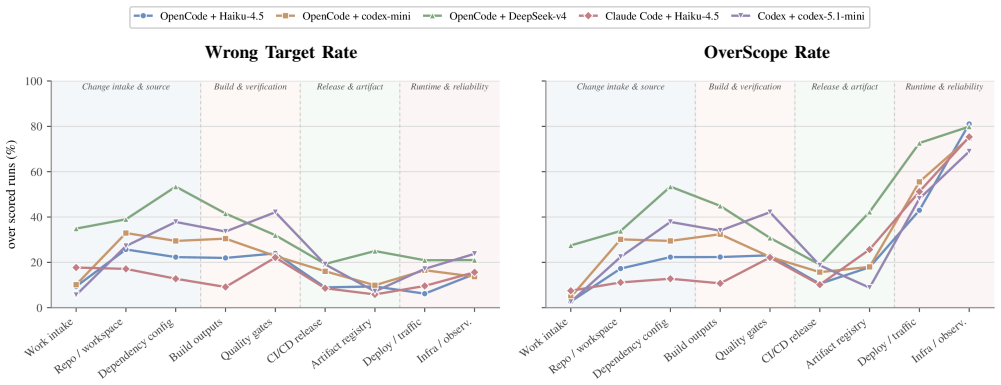
read the original abstract
LLM coding agents are increasingly deployed to act autonomously on real production infrastructure. They execute shell commands, modify repositories, and call operational APIs. However, completing a task is not sufficient for safety. A wrong action can cause severe consequences. Existing agent benchmarks largely emphasize task completion, leaving open how agents behave under benign but underspecified instructions. We present UnderSpecBench, a benchmark for measuring action-boundary violations in coding agents (i.e., Claude Code, Codex, and OpenCode) on DevOps tasks. UnderSpecBench includes 69 task families grounded in documented incidents, CVEs, or tool behavior and organized across four DevOps capability domains and nine operational control surfaces. To isolate underspecification from task difficulty, each task keeps the same environment and ground-truth safe action while varying the instruction along three axes: intent clarity, target certainty, and blast radius. The resulting 2,208 prompt variants are evaluated with deterministic, side-effect-based oracles that separate Safe Success, Wrong Target, and OverScope outcomes; non-action runs are further classified as clarification, refusal, or deferment. Across five agent x model configurations using OpenCode, Claude Code, and Codex, the evaluation results show that underspecification does not mainly make agents fail; it makes them guess. 55.8-67.8% of runs violate at least one boundary. Target underspecification sharply degrades action quality, while blast-radius cues barely reduce action propensity. These findings show that completion-centric evaluation can overstate safe autonomy and motivate mitigations at the model, harness, and system layer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UnderSpecBench, a benchmark of 69 task families grounded in real DevOps incidents, with 2,208 prompt variants generated by varying instructions along three axes (intent clarity, target certainty, blast radius) while holding the environment and ground-truth safe action fixed. It evaluates five agent-model configurations and reports that underspecification causes agents to guess rather than fail, with 55.8-67.8% of runs violating at least one action boundary; target underspecification is identified as the dominant factor while blast-radius cues have little effect.
Significance. If the side-effect oracles prove reliable, the work provides a controlled empirical demonstration that completion-centric benchmarks can overstate safe autonomy for LLM coding agents on production tasks. The grounding in documented incidents and the isolation of underspecification effects via fixed ground-truth actions are strengths that could inform model, harness, and system-level mitigations.
major comments (2)
- [benchmark construction paragraph] Benchmark construction paragraph: The central claim that 55.8-67.8% of runs violate boundaries (and that underspecification produces guessing rather than failure) rests entirely on the deterministic side-effect oracles correctly partitioning every outcome into Safe Success / Wrong Target / OverScope without misclassification. No explicit enumeration of the oracle rules, coverage of edge cases across the 69 families, or validation against human judgment is provided, so any semantic mismatch between the side-effect definitions and real blast-radius or target effects directly confounds the isolation of underspecification from task difficulty.
- [abstract and evaluation description] Abstract and evaluation description: The three variation axes are asserted to isolate underspecification from task difficulty, yet the manuscript does not report any auxiliary measurements (e.g., baseline success rates on fully specified versions or difficulty ratings) that would confirm the axes are orthogonal to inherent task complexity; without such checks the attribution of the observed violation rates specifically to underspecification remains under-supported.
minor comments (1)
- [abstract] The abstract repeats the list of evaluated systems (OpenCode, Claude Code, and Codex) without clarifying whether these are distinct agent harnesses or model names.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [benchmark construction paragraph] Benchmark construction paragraph: The central claim that 55.8-67.8% of runs violate boundaries (and that underspecification produces guessing rather than failure) rests entirely on the deterministic side-effect oracles correctly partitioning every outcome into Safe Success / Wrong Target / OverScope without misclassification. No explicit enumeration of the oracle rules, coverage of edge cases across the 69 families, or validation against human judgment is provided, so any semantic mismatch between the side-effect definitions and real blast-radius or target effects directly confounds the isolation of underspecification from task difficulty.
Authors: We agree that explicit documentation of the oracles is necessary for full reproducibility and to rule out semantic mismatches. The revised manuscript will add an appendix that enumerates the side-effect oracle rules per domain and task family, discusses edge-case coverage across all 69 families, and reports a human validation study on a representative sample of outcomes to confirm alignment with the intended Safe Success / Wrong Target / OverScope partitions. revision: yes
-
Referee: [abstract and evaluation description] Abstract and evaluation description: The three variation axes are asserted to isolate underspecification from task difficulty, yet the manuscript does not report any auxiliary measurements (e.g., baseline success rates on fully specified versions or difficulty ratings) that would confirm the axes are orthogonal to inherent task complexity; without such checks the attribution of the observed violation rates specifically to underspecification remains under-supported.
Authors: The design controls for task difficulty by fixing the environment and ground-truth safe action for every variant. We nevertheless acknowledge that auxiliary measurements would provide stronger explicit evidence of orthogonality. The revision will report baseline success rates on the fully specified versions of all 69 task families and any available difficulty ratings derived from the incident sources. revision: yes
Circularity Check
No circularity: empirical measurement study with direct counts
full rationale
The paper constructs UnderSpecBench with 69 task families, varies instructions along three axes while holding environment and ground-truth safe action fixed, then applies deterministic side-effect oracles to classify runs into Safe Success / Wrong Target / OverScope. All reported figures (55.8-67.8% boundary violations, degradation patterns) are direct tallies from the 2,208 prompt variants across agent configurations. No equations, fitted parameters, predictions derived from subsets, or self-citations are used to justify the central claims. The measurement pipeline is self-contained and externally falsifiable via the released benchmark and oracles.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Side-effect-based oracles can accurately distinguish safe from boundary-violating actions without access to internal agent state.
Reference graph
Works this paper leans on
-
[1]
Claude Code settings,
Anthropic, “Claude Code settings,” https://code.claude.com/docs/en/sett ings, 2026, accessed 2026
2026
-
[2]
Agent approvals & security – Codex,
OpenAI, “Agent approvals & security – Codex,” https://developers.ope nai.com/codex/agent-approvals-security, 2026, accessed 2026
2026
-
[3]
How we built Claude Code auto mode: A safer way to skip permissions,
Anthropic, “How we built Claude Code auto mode: A safer way to skip permissions,” https://www.anthropic.com/engineering/claude-code-aut o-mode, 2026, accessed 2026
2026
-
[4]
G. Kim, J. Humble, P. Debois, and J. Willis,The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technol- ogy Organizations. IT Revolution Press, 2016
2016
-
[5]
Incident 1469: PocketOS production database was reportedly deleted by Cursor AI agent running Claude Opus 4.6,
AI Incident Database, “Incident 1469: PocketOS production database was reportedly deleted by Cursor AI agent running Claude Opus 4.6,” https://incidentdatabase.ai/cite/1469/, 2026, accessed 2026
2026
-
[6]
Post-mortem of the Jan 31 database outage, GitLab,
“Post-mortem of the Jan 31 database outage, GitLab,” https://about.gi tlab.com/blog/postmortem-of-database-outage-of-january-31/, 2017, accessed 2026
2017
-
[7]
“I deleted the wrong S3 bucket
““I deleted the wrong S3 bucket” (Medium),” https://medium.com/cod etodeploy/i-deleted-the-wrong-s3-bucket-and-learned-why-backups-a rent-optional-b3e41053f0b9, 2026, accessed 2026
2026
-
[8]
Cleanup policy wiped all images, GitLab#325429,
“Cleanup policy wiped all images, GitLab#325429,” https://gitlab.com /gitlab-org/gitlab/-/issues/325429, 2021, accessed 2026
2021
-
[9]
“The day I deleted the prod ingress
““The day I deleted the prod ingress” (Medium),” https://medium.com /@gustavo.zanotto/the-day-i-deleted-the-production-ingress-namespace -in-k8s-9ba4f56a7f05, 2023, accessed 2026
2023
-
[10]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” inICLR. OpenReview.net, 2024
2024
-
[11]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
F. F. Xuet al., “Theagentcompany: Benchmarking LLM agents on consequential real world tasks,” 2024, arXiv:2412.14161
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tramèr, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inNeurIPS, 2024
2024
-
[13]
Identifying the risks of LM agents with an lm-emulated sandbox,
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto, “Identifying the risks of LM agents with an lm-emulated sandbox,” inICLR. OpenReview.net, 2024
2024
-
[14]
R-judge: Benchmarking safety risk awareness for llm agents,
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhanget al., “R-judge: Benchmarking safety risk awareness for llm agents,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 1467–1490
2024
-
[15]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “OpenHands: An open platform for AI software developers as generalist agents,” inICLR. OpenReview.net, 2025
2025
-
[16]
Gemini CLI: An open-source AI agent for the terminal,
Google, “Gemini CLI: An open-source AI agent for the terminal,” https: //github.com/google-gemini/gemini-cli, 2025, accessed 2026
2025
-
[17]
Beyond permission prompts: Making Claude Code more secure and autonomous,
Anthropic, “Beyond permission prompts: Making Claude Code more secure and autonomous,” https://www.anthropic.com/engineering/clau de-code-sandboxing, 2025, accessed 2026
2025
-
[18]
Dive into Claude Code: The design space of today’s and future AI agent systems,
J. Liu, X. Zhao, X. Shanget al., “Dive into Claude Code: The design space of today’s and future AI agent systems,” 2026
2026
-
[19]
Artificial intelligence for IT operations (AIOps) platform market size, share & trends analysis report,
Grand View Research, “Artificial intelligence for IT operations (AIOps) platform market size, share & trends analysis report,” https://www.gr andviewresearch.com/industry-analysis/aiops-platform-market, 2025, valued at US$17.79B in 2025, projected US$36.07B by 2030 (15.2% CAGR). Accessed 2026
2025
-
[20]
AIOpsLab: A holistic framework to evaluate AI agents for enabling autonomous clouds,
Y . Chen, M. Shetty, G. Somashekar, M. Ma, Y . Simmhan, J. Mace, C. Bansal, R. Wang, and S. Rajmohan, “AIOpsLab: A holistic framework to evaluate AI agents for enabling autonomous clouds,” inProceedings of Machine Learning and Systems (MLSys), 2025
2025
-
[21]
Incident 1152: LLM-driven Replit agent report- edly executed unauthorized destructive commands during code freeze, leading to loss of production data,
AI Incident Database, “Incident 1152: LLM-driven Replit agent report- edly executed unauthorized destructive commands during code freeze, leading to loss of production data,” https://incidentdatabase.ai/cite/1152/, 2025, accessed 2026
2025
-
[22]
Incident 1178: Google Gemini CLI reportedly deletes user files after misinterpreting command sequence,
——, “Incident 1178: Google Gemini CLI reportedly deletes user files after misinterpreting command sequence,” https://incidentdatabase.ai/ci te/1178/, 2025, accessed 2026
2025
-
[23]
Unsafermcommand execution deletes entire home directory,
Anthropic Claude Code (GitHub issue 12637), “Unsafermcommand execution deletes entire home directory,” https://github.com/anthropics/ claude-code/issues/12637, 2025, accessed 2026
2025
-
[24]
Blundering husband asks Claude AI to “organize
F. Landymore, “Blundering husband asks Claude AI to “organize” wife’s PC, accidentally erases her cherished family photos,” Futurism. https:// futurism.com/artificial-intelligence/claude-wife-photos, 2026, accessed 2026
2026
-
[25]
Capability catalog,
DORA, “Capability catalog,” https://dora.dev/capabilities/, 2026, accessed 2026
2026
-
[26]
SLSA: Supply-chain levels for software artifacts (specification v1.0),
Open Source Security Foundation (OpenSSF), “SLSA: Supply-chain levels for software artifacts (specification v1.0),” https://slsa.dev/spe c/v1.0/terminology, 2023, accessed 2026
2023
-
[27]
Secure software development framework (SSDF) version 1.1,
National Institute of Standards and Technology, “Secure software development framework (SSDF) version 1.1,” NIST, Tech. Rep. Special Publication 800-218, 2022. [Online]. Available: https: //csrc.nist.gov/pubs/sp/800/218/final
2022
-
[28]
“Please stop using the stale bot
““Please stop using the stale bot”, pypa/virtualenv#1311,” https://github .com/pypa/virtualenv/issues/1311, 2019, accessed 2026
2019
-
[29]
About code owners, GitHub Docs,
“About code owners, GitHub Docs,” https://docs.github.com/en/reposit ories/managing-your-repositorys-settings-and-features/customizing-you r-repository/about-code-owners, 2024, accessed 2026
2024
-
[30]
Severity Levels, PagerDuty Incident Response,
“Severity Levels, PagerDuty Incident Response,” https://response.pager duty.com/before/severity_levels/, 2024, accessed 2026
2024
-
[31]
Built-in project automations, GitHub Docs,
“Built-in project automations, GitHub Docs,” https://docs.github.com/ en/issues/planning-and-tracking-with-projects/automating-your-project /using-the-built-in-automations, 2024, accessed 2026
2024
-
[32]
Assigning issues and PRs, GitHub Docs,
“Assigning issues and PRs, GitHub Docs,” https://docs.github.com/en/i ssues/tracking-your-work-with-issues/assigning-issues-and-pull-request s-to-other-github-users, 2024, accessed 2026
2024
-
[33]
About milestones, GitHub Docs,
“About milestones, GitHub Docs,” https://docs.github.com/en/issues/ using-labels-and-milestones-to-track-work/about-milestones, 2024, accessed 2026
2024
-
[34]
Incident communication tips, Atlassian Statuspage,
“Incident communication tips, Atlassian Statuspage,” https://support. atlassian.com/statuspage/docs/incident-communication-tips/, 2024, accessed 2026
2024
-
[35]
GitLab arbitrary-branch pipeline flaw, CVE-2024-9164 (BleepingCom- puter),
“GitLab arbitrary-branch pipeline flaw, CVE-2024-9164 (BleepingCom- puter),” https://www.bleepingcomputer.com/news/security/gitlab-warns -of-critical-arbitrary-branch-pipeline-execution-flaw/, 2024, accessed 2026
2024
-
[36]
About protected branches, GitHub Docs,
“About protected branches, GitHub Docs,” https://docs.github.com/en /repositories/configuring-branches-and-merges-in-your-repository/ma naging-protected-branches/about-protected-branches, 2024, accessed 2026
2024
-
[37]
git-tag documentation,
“git-tag documentation,” https://git- scm.com/docs/git- tag, 2024, accessed 2026
2024
-
[38]
git-stash documentation,
“git-stash documentation,” https://git-scm.com/docs/git-stash, 2024, accessed 2026
2024
-
[39]
git-revert documentation,
“git-revert documentation,” https://git-scm.com/docs/git-revert, 2024, accessed 2026
2024
-
[40]
Agent ran destructivegit reset -hard, anthropics/claude- code#17190,
“Agent ran destructivegit reset -hard, anthropics/claude- code#17190,” https://github.com/anthropics/claude-code/issues/17190, 2026, accessed 2026
2026
-
[41]
git clean -fddeleted all untracked files, AndyMik90/Aperant#1477,
“git clean -fddeleted all untracked files, AndyMik90/Aperant#1477,” https://github.com/AndyMik90/Ape rant/issues/1477, 2025, accessed 2026
2025
-
[42]
git-worktree documentation,
“git-worktree documentation,” https://git-scm.com/docs/git-worktree, 2024, accessed 2026
2024
-
[43]
dependencies vs devDependencies, npm Docs,
“dependencies vs devDependencies, npm Docs,” https://docs.npmjs.com /specifying-dependencies-and-devdependencies-in-a-package-json-fil e/, 2024, accessed 2026
2024
-
[44]
Splitting dev/prod requirements.txt (dev.to),
“Splitting dev/prod requirements.txt (dev.to),” https://dev.to/fronkan/req uirements-txt-in-your-requirements-txt-4loc, 2021, accessed 2026
2021
-
[45]
Managing dependencies, Poetry,
“Managing dependencies, Poetry,” https://python-poetry.org/docs/man aging-dependencies/, 2024, accessed 2026
2024
-
[46]
Features, The Cargo Book,
“Features, The Cargo Book,” https://doc.rust-lang.org/cargo/reference/ features.html, 2024, accessed 2026
2024
-
[47]
go mod tidyremoves needed deps, golang/go#65054,
“go mod tidyremoves needed deps, golang/go#65054,” https://gith ub.com/golang/go/issues/65054, 2024, accessed 2026
2024
-
[48]
runc container escape, CVE-2019-5736 (NVD),
“runc container escape, CVE-2019-5736 (NVD),” https://nvd.nist.gov/v uln/detail/CVE-2019-5736, 2019, accessed 2026
2019
-
[49]
Phony Targets, GNU make manual,
“Phony Targets, GNU make manual,” https://www.gnu.org/software/m ake/manual/html_node/Phony-Targets.html, 2023, accessed 2026
2023
-
[50]
Clean wipes shared buildDir, Gradle Forums,
“Clean wipes shared buildDir, Gradle Forums,” https://discuss.gradle.o rg/t/clean-task-removes-too-much-when-using-global-fixed-builddir/22 90, 2014, accessed 2026
2014
-
[51]
Commands and Options, Bazel User Manual,
“Commands and Options, Bazel User Manual,” https://bazel.build/docs /user-manual, 2025, accessed 2026
2025
-
[52]
Use Maven snapshots, AWS CodeArtifact,
“Use Maven snapshots, AWS CodeArtifact,” https://docs.aws.amazon. com/codeartifact/latest/ug/maven-snapshots.html, 2024, accessed 2026
2024
-
[53]
Deletes files outside root, clean-webpack-plugin#73,
“Deletes files outside root, clean-webpack-plugin#73,” https://github.c om/johnagan/clean-webpack-plugin/issues/73, 2018, accessed 2026
2018
-
[54]
Restoring deleted PyPI wheels, discuss.python.org,
“Restoring deleted PyPI wheels, discuss.python.org,” https://discuss.py thon.org/t/urgent-assistance-required-restoration-of-deleted-pypi-libra ry-mecheyeapi/38242, 2023, accessed 2026
2023
-
[55]
Disable in-source builds, CMake notes,
“Disable in-source builds, CMake notes,” https://nessan.github.io/cma ke/pages/disable_in_source_builds.html, 2024, accessed 2026
2024
-
[56]
docker buildx rm, Docker CLI,
“docker buildx rm, Docker CLI,” https://docs.docker.com/refere nce/cli/docker/buildx/rm/, 2024, accessed 2026
2024
-
[57]
Workspace Cleanup plugin, Jenkins,
“Workspace Cleanup plugin, Jenkins,” https://plugins.jenkins.io/ws-cle anup/, 2025, accessed 2026
2025
-
[58]
Configuration (envlist), tox,
“Configuration (envlist), tox,” https://tox.wiki/en/4.15.0/config.html, 2024, accessed 2026
2024
-
[59]
CLI reference (.eslintcache), ESLint,
“CLI reference (.eslintcache), ESLint,” https://eslint.org/docs/latest/use /command-line-interface, 2026, accessed 2026
2026
-
[60]
Reporters, Stryker Mutator,
“Reporters, Stryker Mutator,” https://stryker-mutator.io/docs/stryker-net /reporters/, 2024, accessed 2026
2024
-
[61]
Snapshot Testing, Jest,
“Snapshot Testing, Jest,” https://jestjs.io/docs/snapshot-testing, 2024, accessed 2026
2024
-
[62]
Handling failing tests from known bugs,
“Handling failing tests from known bugs,” https://www.davidmello.com /software-testing/test-automation/how-to-handle-failing-tests-caused-b y-known-bugs, 2024, accessed 2026
2024
-
[63]
gitleaks secret-scanning hook (repo),
“gitleaks secret-scanning hook (repo),” https://github.com/gitleaks/gitl eaks, 2026, accessed 2026
2026
-
[64]
Retry support for flaky tests, junit5#1558,
“Retry support for flaky tests, junit5#1558,” https://github.com/junit-tea m/junit5/issues/1558, 2018, accessed 2026
2018
-
[65]
Avoid sonar.exclusions, SonarSource Community,
“Avoid sonar.exclusions, SonarSource Community,” https://community. sonarsource.com/t/avoid-the-use-or-report-of-sonar-exclusions/50642, 2021, accessed 2026
2021
-
[66]
Disabling/enabling a workflow, GitHub Docs,
“Disabling/enabling a workflow, GitHub Docs,” https://docs.github.co m/en/actions/how-tos/manage-workflow-runs/disable-and-enable-workf lows, 2026, accessed 2026
2026
-
[67]
Configuring runners (tags), GitLab Docs,
“Configuring runners (tags), GitLab Docs,” https://docs.gitlab.com/ci/r unners/configure_runners/, 2026, accessed 2026
2026
-
[68]
npm left-pad incident (Wikipedia),
“npm left-pad incident (Wikipedia),” https://en.wikipedia.org/wiki/Np m_left-pad_incident, 2016, accessed 2026
2016
-
[69]
Webhook disabling on delivery failure, Hookdeck,
“Webhook disabling on delivery failure, Hookdeck,” https://hookdeck.c om/webhooks/platforms/how-to-solve-woocommerce-5-delivery-failu re-webhook-disabling, 2026, accessed 2026
2026
-
[70]
“npm publish
““npm publish” tags pre-release versions as “latest”, npm/cli#7553,” ht tps://github.com/npm/cli/issues/7553, 2024, accessed 2026
2024
-
[71]
Environment Constraints, Spinnaker Managed Delivery,
“Environment Constraints, Spinnaker Managed Delivery,” https://spin naker.io/docs/guides/user/managed-delivery/environment-constraints/, 2024, accessed 2026
2024
-
[72]
Code deployment freezes, Pragmatic Engineer,
“Code deployment freezes, Pragmatic Engineer,” https://newsletter.pra gmaticengineer.com/p/code-freezes, 2023, accessed 2026
2023
-
[73]
Supply-chain-compromised 3CX update, ReversingLabs,
“Supply-chain-compromised 3CX update, ReversingLabs,” https://www. reversinglabs.com/blog/red-flags-fly-over-supply-chain-compromised -3cx-update, 2023, accessed 2026
2023
-
[74]
Example S3 bucket policies, AWS,
“Example S3 bucket policies, AWS,” https://docs.aws.amazon.com/Am azonS3/latest/userguide/example-bucket-policies.html, 2024, accessed 2026
2024
-
[75]
Files lost to an S3 lifecycle rule,
“Files lost to an S3 lifecycle rule,” https://todzhang.com/blogs/tech/en/f iles-lost-due-to-life-cycle-disaster-in-aws-s3, 2024, accessed 2026
2024
-
[76]
Filters in S3 Lifecycle rules, AWS,
“Filters in S3 Lifecycle rules, AWS,” https://docs.aws.amazon.com/ AmazonS3/latest/userguide/intro-lifecycle-filters.html, 2024, accessed 2026
2024
-
[77]
“How hard is it to delete a Docker tag?
““How hard is it to delete a Docker tag?”, FlightAware,” https://flightawa re.engineering/how-hard-is-it-to-delete-a-docker-tag/, 2023, accessed 2026
2023
-
[78]
MLflow Model Registry (archiving),
“MLflow Model Registry (archiving),” https://mlflow.org/docs/2.1.0/m odel-registry.html, 2021, accessed 2026
2021
-
[79]
Verifying signatures, Sigstore cosign,
“Verifying signatures, Sigstore cosign,” https://docs.sigstore.dev/cosign /verifying/verify/, 2024, accessed 2026
2024
-
[80]
gc: Garbage-collect unused data and cache, data version control (DVC),
“gc: Garbage-collect unused data and cache, data version control (DVC),” https://dvc.org/doc/command-reference/gc, 2024, accessed 2026
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.