A Hippocampus for Linear Attention: An Exact Memory for What the Recurrent State Forgets
Pith reviewed 2026-07-03 13:43 UTC · model grok-4.3
The pith
Linear attention gains an exact hippocampal cache that stores what its recurrent state overwrites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
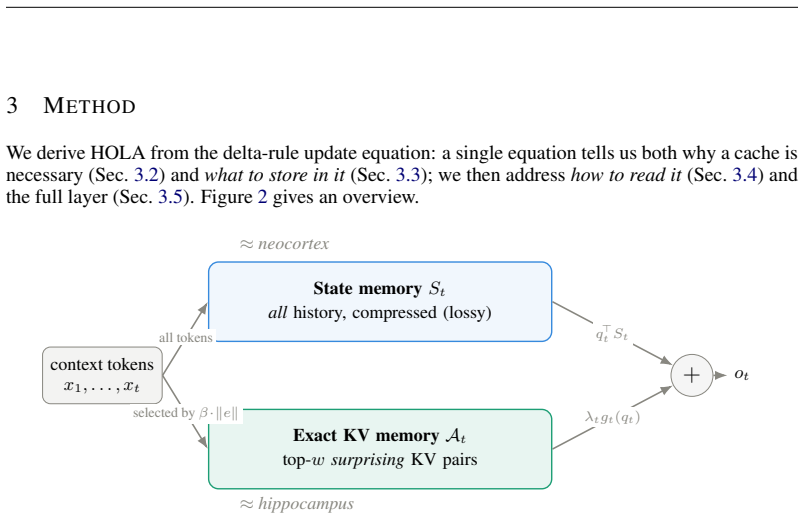
HOLA keeps the delta-rule state as a compressive memory and adds a bounded exact KV cache, forming a semiparametric test-time memory. The cache writes without a learned eviction module, keeping tokens with large beta * ||e||, the prediction residual actually committed to the state; a decoupled RMSNorm-gamma cache read then turns these exact KV pairs into sharp retrieval rather than soft averaging.
What carries the argument
The hippocampal complement: a bounded exact KV cache that writes high-residual tokens via the non-learned rule beta * ||e|| and reads them via decoupled RMSNorm-gamma.
If this is right
- Wikitext perplexity drops from 27.32 to 22.92, below the 26.88 of a matched full-attention Transformer++.
- LAMBADA perplexity improves from 30.95 to 30.26.
- Linear in-context retrieval accuracy reaches the best reported level among linear models.
- Needle-in-a-haystack recall on RULER stays robust out to 32k tokens, sixteen times the training length.
Where Pith is reading between the lines
- The same residual-driven cache could be added to other linear recurrent architectures such as state-space models to separate compressible patterns from specific facts.
- If the cache bound is kept small relative to the number of distinct associations at test time, retrieval accuracy would still degrade once the cache fills.
- The non-learned write rule implies that prediction-residual magnitude alone is often a sufficient signal for deciding which associations need exact storage.
Load-bearing premise
The non-learned cache-write rule based on large prediction residuals plus the decoupled RMSNorm-gamma read will reliably capture and surface the associations that the recurrent state forgets without a learned eviction policy or new failure modes at longer contexts.
What would settle it
A controlled experiment in which needle-in-a-haystack recall collapses once the number of competing facts exceeds the fixed cache size, even when residuals remain large, would falsify the claim that the write-and-read mechanism reliably recovers forgotten associations.
Figures

read the original abstract
Linear-attention and state-space language models compress the prefix into a fixed-size recurrent state, yielding O(1) memory at the cost of a lossy exact memory: when many key--value associations compete, earlier facts are overwritten and needle recall degrades. Inspired by Complementary Learning Systems, we give linear attention a hippocampal complement. HOLA (Hippocampal Linear Attention) keeps the usual delta-rule state as a compressive memory and adds a bounded exact KV cache, forming a semiparametric test-time memory: the state models linearly compressible structure, while the cache stores associations that should not be forced through that state. The cache writes without a learned eviction module, keeping tokens with large beta * ||e||, the prediction residual actually committed to the state; a decoupled RMSNorm-gamma cache read then turns these exact KV pairs into sharp retrieval rather than soft averaging. At 340M parameters trained on 15B SlimPajama tokens, HOLA lowers Wikitext perplexity from 27.32 to 22.92 (-16.1%), below a full-attention Transformer++ (26.88), and improves LAMBADA perplexity from 30.95 to 30.26. It also achieves the best linear in-context retrieval and remains much more robust than GDN or a matched HOLA+recency cache on RULER needle-in-a-haystack recall out to 32k tokens (16x its training length).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HOLA, a semiparametric extension to linear attention that augments the standard delta-rule recurrent state with a bounded exact KV cache. Tokens are written to the cache when beta * ||e|| is large (where e is the prediction residual committed by the state), and retrieved via a decoupled RMSNorm-gamma mechanism for sharp, non-averaged access. At 340M parameters trained on 15B SlimPajama tokens, the model reports Wikitext perplexity reduction from 27.32 to 22.92, LAMBADA improvement from 30.95 to 30.26, superior linear in-context retrieval, and improved RULER needle recall out to 32k tokens relative to GDN and recency-cache baselines.
Significance. If the empirical claims hold under fuller validation, the result would be significant: it offers a concrete, non-learned mechanism to mitigate overwriting in fixed-size linear states without requiring a full attention matrix or learned eviction policy. The concrete benchmark deltas and the 16x extrapolation on RULER are notable strengths; the approach directly addresses a known limitation of linear attention while preserving O(1) inference cost for the recurrent component.
major comments (3)
- [§3.2–3.3] §3.2–3.3: The cache-write rule (tokens with large beta * ||e||) and decoupled RMSNorm-gamma read are presented as fixed, non-learned components, yet no derivation, correlation analysis, or ablation demonstrates why residual magnitude preferentially identifies associations the delta-rule state overwrites. This is load-bearing for the central claim that the cache reliably supplies exactly what the recurrent state forgets.
- [Experiments / §4] Experiments (reported numbers in abstract and §4): The headline results (Wikitext 27.32→22.92, LAMBADA 30.95→30.26, RULER gains) are given without error bars, standard deviations across seeds, or ablation tables on cache_bound, beta threshold, or cache size. This absence makes it impossible to assess whether the reported margins are stable or sensitive to the two free hyperparameters.
- [§4 / RULER] RULER evaluation (abstract and §4): While improved recall to 32k is claimed, there is no reported analysis of cache occupancy, eviction frequency, or interference patterns at lengths 16× training context; without this, it remains unclear whether the bounded cache introduces new failure modes that offset the claimed robustness.
minor comments (2)
- [§3.2] Notation: the symbol beta is introduced without an explicit equation defining its scaling relative to the delta-rule update; a one-line definition would improve reproducibility.
- [§4] The manuscript would benefit from a short table listing all free parameters (including cache_bound) and their chosen values for the 340M run.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the detailed, constructive comments. We address each major point below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§3.2–3.3] The cache-write rule (tokens with large beta * ||e||) and decoupled RMSNorm-gamma read are presented as fixed, non-learned components, yet no derivation, correlation analysis, or ablation demonstrates why residual magnitude preferentially identifies associations the delta-rule state overwrites. This is load-bearing for the central claim that the cache reliably supplies exactly what the recurrent state forgets.
Authors: The mechanism is motivated by the Complementary Learning Systems framework, positing that the delta-rule state captures compressible structure while the residual identifies non-compressible associations prone to overwrite. The manuscript supports this via consistent gains on perplexity, LAMBADA, and RULER recall. We agree a dedicated correlation analysis and ablation against random/recency baselines would strengthen the claim and will add both in §3 and an appendix. revision: yes
-
Referee: [Experiments / §4] The headline results (Wikitext 27.32→22.92, LAMBADA 30.95→30.26, RULER gains) are given without error bars, standard deviations across seeds, or ablation tables on cache_bound, beta threshold, or cache size. This absence makes it impossible to assess whether the reported margins are stable or sensitive to the two free hyperparameters.
Authors: The main results are single-run due to compute scale. We will add a hyperparameter sensitivity table for cache size and beta threshold in the revision and explicitly note the single-seed limitation; full multi-seed error bars would require additional training runs beyond current resources. revision: partial
-
Referee: [§4 / RULER] While improved recall to 32k is claimed, there is no reported analysis of cache occupancy, eviction frequency, or interference patterns at lengths 16× training context; without this, it remains unclear whether the bounded cache introduces new failure modes that offset the claimed robustness.
Authors: We will add cache occupancy, eviction frequency, and interference analysis at 16k–32k lengths (including visualizations) to the RULER section and appendix to demonstrate that the bounded cache does not introduce offsetting failure modes. revision: yes
Circularity Check
No circularity: empirical results on held-out data with no self-referential derivation
full rationale
The paper reports measured perplexity and recall improvements on Wikitext, LAMBADA, and RULER benchmarks after training on SlimPajama. The cache-write rule (beta * ||e||) and RMSNorm-gamma read are fixed design choices whose performance is evaluated externally rather than derived from parameters fitted to the target metrics. No equations reduce a claimed prediction to the inputs by construction, and no self-citation chain is invoked to justify the central mechanism. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- beta
- cache_bound
axioms (1)
- domain assumption The recurrent state is updated by the standard delta rule of linear attention.
Reference graph
Works this paper leans on
-
[1]
Zoology: Measuring and improving recall in efficient language models.arXiv:2312.04927,
Simran Arora, Sabri Eyuboglu, et al. Zoology: Measuring and improving recall in efficient language models.arXiv:2312.04927,
-
[2]
arXiv:2402.18668. Sebastian Borgeaud et al. Improving language models by retrieving from trillions of tokens. In ICML,
-
[3]
Improving language models by retrieving from trillions of tokens
arXiv:2112.04426. Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InICML,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv:2405.21060. Soham De et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv:2402.19427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Native Hybrid Attention for Efficient Sequence Modeling
Jusen Du, Jiaxi Hu, Tao Zhang, Weigao Sun, and Yu Cheng. Native hybrid attention for efficient sequence modeling.arXiv:2510.07019,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Artificial hip- pocampus networks for efficient long-context modeling.arXiv:2510.07318,
Yunhao Fang, Weihao Yu, Shu Zhong, Qinghao Ye, Xuehan Xiong, and Lai Wei. Artificial hip- pocampus networks for efficient long-context modeling.arXiv:2510.07318,
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. RULER: What’s the real context size of your long-context language models? arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis
arXiv:2006.16236. Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. InICLR,
-
[12]
arXiv preprint arXiv:1911.00172 , year=
arXiv:1911.00172. Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, et al. Kimi Linear: An expressive, efficient attention architecture.arXiv:2510.26692,
-
[13]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber et al. Jamba: A hybrid transformer-mamba language model.arXiv:2403.19887,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv:1711.05101. James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are complemen- tary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419–457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Landmark attention: Random-access infinite context length for transformers.arXiv:2305.16300,
Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers.arXiv:2305.16300,
-
[16]
Qwen Team. Qwen3 technical report.arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Hopfield Networks is All You Need
arXiv:2008.02217. Liliang Ren et al. Samba: Simple hybrid state space models for efficient unlimited context language modeling.arXiv:2406.07522,
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[18]
arXiv:2102.11174. Daria Soboleva et al. SlimPajama: A 627b token cleaned and deduplicated version of RedPajama. https://www.cerebras.net/blog/slimpajama,
-
[19]
Preconditioned DeltaNet: Curvature-aware Sequence Modeling for Linear Recurrences
Neehal Tumma, Noel Loo, and Daniela Rus. Preconditioned DeltaNet: Curvature-aware sequence modeling for linear recurrences.arXiv:2604.21100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Bailin Wang, Chang Lan, Chong Wang, and Ruoming Pang. RATTENTION: Towards the minimal sliding window size in local-global attention models.arXiv:2506.15545,
-
[21]
arXiv preprint arXiv:2203.08913 , year=
arXiv:2203.08913. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InICLR,
-
[22]
Efficient Streaming Language Models with Attention Sinks
arXiv:2309.17453. Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv:2412.06464, 2024a. Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. InICML, 2024b. arXiv:2312.06635. Songlin Yang, Bailin Wang, Yu Zhang, et ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv:2102.02557. Yu Zhang, Songlin Yang, Ruijie Zhu, Yue Zhang, Leyang Cui, Yiqiao Wang, Bolun Wang, Freda Shi, Bailin Wang, Wei Bi, Peng Zhou, and Guohong Fu. Gated slot attention for efficient linear- time sequence modeling.arXiv:2409.07146,
-
[24]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
arXiv:2306.14048. A SCALE CONFIGURATIONS Table 6 lists the architecture, corpus size, and context length for the scaling comparison in Table
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The 46M row uses a smaller 12-layer,d model=512architecture trained on FineWeb-Edu for 0.5B tokens at ctx 4096; this is the scale used for the component studies in Tables 4–5
Scaled model layers corpus train tokens ctx 46M 512 12 FineWeb-Edu 0.5B 4096 170M 1024 12 SlimPajama 6.22B 2048 340M 1024 24 SlimPajama 15.0B 2048 For 170M and 340M, the architecture family follows the GDN recipe:4heads×head-dim256, expand_v=1,hidden_ratio=4, conv 4, tied embeddings, vocabulary32000, Mistral tokenizer, and AdamW with peak lr4×10 −4. The 4...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.