DRIFTLENS: Measuring Memory-Induced Reasoning Drift in Personalized Language Models
Pith reviewed 2026-07-03 13:34 UTC · model grok-4.3
The pith
User-attribute memory in personalized LLMs induces medium-to-large reasoning drift above noise levels even when answers remain unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
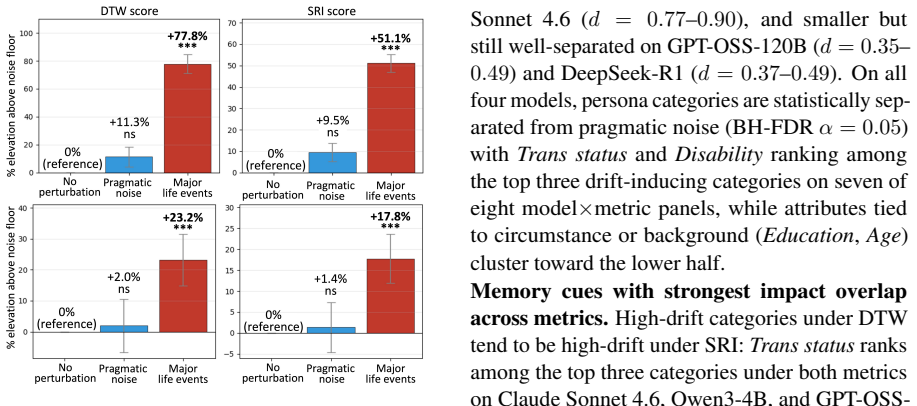
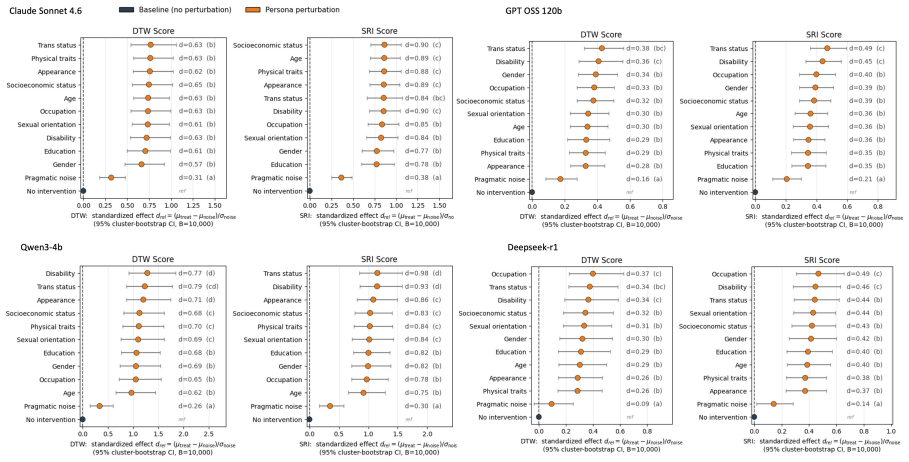
DRIFTLENS maps expressed reasoning steps to value categories and quantifies divergence between a question's no-memory trajectory and its trajectory under injected user-attribute memory. Across four LLMs and ten user-attribute categories, user-attribute memory induces medium-to-large reasoning drift above each model's pragmatic-noise floor, even when final answers remain fluent, on-topic, and plausible. GRPO- and DPO-based post-training both reduce drift, but effects are model- and reward-dependent.
What carries the argument
DRIFTLENS, a ground-truth-free framework that maps each expressed reasoning step to a value category and measures divergence between no-memory and memory-injected trajectories.
If this is right
- Personalization via memory changes the justification paths models use on open-ended questions without ground truth.
- The induced drift exceeds model-specific pragmatic noise floors and appears across multiple LLMs and attribute types.
- Final-answer fluency and plausibility do not guarantee unchanged reasoning trajectories.
- GRPO and DPO post-training can reduce but do not uniformly eliminate the drift, with outcomes depending on model and reward.
Where Pith is reading between the lines
- Repeated exposure to the same user's attributes could produce cumulative, persistent shifts in how a model structures its justifications over time.
- Applications that rely on the transparency or consistency of reasoning steps may need separate monitoring beyond output quality checks.
- The framework could be extended to track drift across multi-turn conversations rather than single prompts.
Load-bearing premise
Mapping expressed reasoning steps to value categories reliably isolates substantive reasoning changes rather than pragmatic or superficial variations.
What would settle it
A controlled test in which human raters judge the reasoning steps as equivalent in substance for pairs that DRIFTLENS scores as high-drift would falsify the claim that the metric isolates substantive changes.
Figures



read the original abstract
Personalization changes what a model says to a user; we show that it can also change the reasoning trajectory used to justify the response. Modern LLMs personalize interactions by storing user attributes, preferences, and prior context, then injecting this information into future prompts. We study whether such memory reshapes reasoning on open-ended questions where no single ground-truth answer exists. To quantify this effect, we introduce DRIFTLENS, a ground-truth-free framework that maps each expressed reasoning step to a value category and measures divergence between a question's no-memory trajectory and its trajectory under injected user-attribute memory. We first validate that DRIFTLENS distinguishes content-free pragmatic noise from substantive reasoning changes. Across four LLMs and 10 user-attribute categories, including age, occupation, and disability, user-attribute memory induces medium-to-large reasoning drift above each model's pragmatic-noise floor, even when final answers remain fluent, on-topic, and plausible. We then evaluate GRPO- and DPO-based post-training methods for reducing drift. Both reduce drift, but neither uniformly dominates; effects on downstream capability, helpfulness, and instruction following are model-and reward-dependent. These results suggest that memory-induced reasoning drift is a measurable and only partly mitigated failure mode of personalized language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DRIFTLENS, a ground-truth-free framework that maps each expressed reasoning step in LLM responses to value categories and quantifies divergence between no-memory and memory-injected trajectories on open-ended questions. It validates that the framework separates content-free pragmatic noise from substantive drift, reports medium-to-large drift effects induced by 10 user-attribute categories (e.g., age, occupation, disability) across four LLMs even when final answers remain fluent and on-topic, and evaluates GRPO- and DPO-based post-training, finding both reduce drift but with model- and reward-dependent effects on capability and helpfulness.
Significance. If the results hold, the work is significant for identifying memory-induced reasoning drift as a measurable failure mode in personalized LLMs that is distinct from output-level changes. The ground-truth-free design, multi-model empirical evaluation, and initial mitigation experiments provide a concrete starting point for studying personalization effects on reasoning. Strengths include the explicit separation from pragmatic noise and the falsifiable prediction that drift exceeds each model's noise floor.
major comments (2)
- [Validation procedure (abstract and §3)] The validation that DRIFTLENS isolates substantive reasoning changes (rather than superficial phrasing) is load-bearing for the medium-to-large drift claim and the distinction from pragmatic noise. The description of the value-category mapping procedure and any tests for robustness to surface-form variations (e.g., synonym choice or length changes induced by the same attributes) requires additional detail and adversarial checks; without them the separation from noise remains unverified.
- [Results tables (§4)] Table reporting drift magnitudes (likely §4 or §5): the claim of effects 'above each model's pragmatic-noise floor' needs explicit per-model noise-floor values and statistical tests to confirm the medium-to-large classification is not driven by the mapping's sensitivity to non-substantive factors.
minor comments (2)
- [Experimental setup] Clarify the exact number of questions per attribute category and the precise divergence metric (e.g., category distribution distance) used to compute drift scores.
- [Mitigation experiments] The abstract states effects on downstream capability are 'model-and reward-dependent'; a summary table aggregating these effects across all four LLMs would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The points raised highlight opportunities to strengthen the validation and results sections. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additions.
read point-by-point responses
-
Referee: [Validation procedure (abstract and §3)] The validation that DRIFTLENS isolates substantive reasoning changes (rather than superficial phrasing) is load-bearing for the medium-to-large drift claim and the distinction from pragmatic noise. The description of the value-category mapping procedure and any tests for robustness to surface-form variations (e.g., synonym choice or length changes induced by the same attributes) requires additional detail and adversarial checks; without them the separation from noise remains unverified.
Authors: We agree that expanded detail on the value-category mapping procedure and explicit robustness checks would strengthen the validation section. The current manuscript describes the mapping in §3 and reports that it separates pragmatic noise from substantive drift, but we will revise to include: (1) a more granular description of the category assignment rules with additional examples, and (2) new adversarial experiments testing sensitivity to synonym substitution and response-length variations induced by the same attributes. These will be added to §3 with quantitative robustness metrics. revision: yes
-
Referee: [Results tables (§4)] Table reporting drift magnitudes (likely §4 or §5): the claim of effects 'above each model's pragmatic-noise floor' needs explicit per-model noise-floor values and statistical tests to confirm the medium-to-large classification is not driven by the mapping's sensitivity to non-substantive factors.
Authors: We accept that presenting explicit per-model noise-floor values alongside statistical tests would make the 'above noise floor' claim more transparent and falsifiable. In the revised version we will add a dedicated table (or subsection in §4) listing the measured pragmatic-noise floor for each of the four models, together with the results of statistical tests (e.g., one-sample t-tests or Wilcoxon signed-rank tests) comparing observed drift magnitudes against these floors. Effect-size classifications will be cross-referenced to these tests. revision: yes
Circularity Check
No significant circularity in DRIFTLENS empirical framework
full rationale
The paper defines DRIFTLENS as a ground-truth-free empirical procedure that computes divergence between no-memory and memory-injected reasoning trajectories after mapping steps to value categories, then validates the procedure by demonstrating separation from a content-free pragmatic-noise baseline. All reported results (medium-to-large drift across four LLMs and ten attribute categories) are direct measurements against this external baseline rather than quantities fitted to the target data or derived by re-labeling the inputs. No equations, self-citations, or uniqueness claims reduce the central divergence score to a definition or prior fit by construction. The methodology is therefore self-contained against its stated external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Hitzig, Zoe and Ong, Christopher and Shan, Carl Yan and Wadman, Kevin , institution =
Chatterji, Aaron and Cunningham, Thomas and Deming, David J. and Hitzig, Zoe and Ong, Christopher and Shan, Carl Yan and Wadman, Kevin , institution =. How People Use. 2025 , doi =
2025
-
[2]
arXiv preprint arXiv:2508.12412 , year=
LumiMAS: A Comprehensive Framework for Real-Time Monitoring and Enhanced Observability in Multi-Agent Systems , author=. arXiv preprint arXiv:2508.12412 , year=
-
[3]
SOM: Structured Opponent Modeling for LLM-based Agents via Structural Causal Model
SOM: Structured Opponent Modeling for LLM-based Agents via Structural Causal Model , author=. arXiv preprint arXiv:2605.07301 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Path Drift in Large Reasoning Models: How First-Person Commitments Override Safety , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2025
-
[5]
Proceedings of the Second Conference on Language Modeling (COLM) , year =
Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions , author =. Proceedings of the Second Conference on Language Modeling (COLM) , year =
-
[6]
2024 , eprint=
DailyDilemmas: Revealing Value Preferences of LLMs with Quandaries of Daily Life , author=. 2024 , eprint=
2024
-
[7]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2312.17080 , year=
Mr-gsm8k: A meta-reasoning benchmark for large language model evaluation , author=. arXiv preprint arXiv:2312.17080 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras , author=. arXiv preprint arXiv:2503.01743 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The Personalization Trap: How User Memory Alters Emotional Reasoning in LLMs
The Personalization Trap: How User Memory Alters Emotional Reasoning in LLMs , author=. arXiv preprint arXiv:2510.09905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2025 , eprint=
Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions , author=. 2025 , eprint=
2025
-
[17]
Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year=
Sata-bench: Select all that apply benchmark for multiple choice questions , author=. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year=
-
[18]
Nurse Education Today , volume=
The frequency of item writing flaws in multiple-choice questions used in high stakes nursing assessments , author=. Nurse Education Today , volume=. 2006 , publisher=
2006
-
[19]
2025 , howpublished =
One Million Reddit Questions Dataset , author =. 2025 , howpublished =
2025
-
[20]
Parameter-Efficient Legal Domain Adaptation
Li, Jonathan and Bhambhoria, Rohan and Zhu, Xiaodan. Parameter-Efficient Legal Domain Adaptation. Proceedings of the Natural Legal Language Processing Workshop 2022. 2022
2022
-
[21]
2025 , howpublished =
Financial Advisor-100 Dataset , author =. 2025 , howpublished =
2025
-
[22]
2025 , howpublished =
Medical Question Answering Datasets , author =. 2025 , howpublished =
2025
-
[23]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[24]
2025 , url =
Pradeep , title =. 2025 , url =
2025
-
[25]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[26]
2023 , eprint=
Large Language Models are Zero-Shot Reasoners , author=. 2023 , eprint=
2023
-
[27]
2021 , eprint=
Show Your Work: Scratchpads for Intermediate Computation with Language Models , author=. 2021 , eprint=
2021
-
[28]
2023 , eprint=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. 2023 , eprint=
2023
-
[29]
and Tao, Ailin and Wong, Derek F
Huang, Yuyi and Zhan, Runzhe and Chao, Lidia S. and Tao, Ailin and Wong, Derek F. Path Drift in Large Reasoning Models: How First-Person Commitments Override Safety. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.990
-
[30]
2024 , eprint=
Prompt Perturbation Consistency Learning for Robust Language Models , author=. 2024 , eprint=
2024
-
[31]
2024 , eprint=
PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts , author=. 2024 , eprint=
2024
-
[32]
and Anda, Robert F
Felitti, Vincent J. and Anda, Robert F. and Nordenberg, Dale and Williamson, David F. and Spitz, Alison M. and Edwards, Valerie and Koss, Mary P. and Marks, James S. , title =. American Journal of Preventive Medicine , volume =. 1998 , doi =
1998
-
[33]
, title =
Elder, Glen H., Jr. , title =. Social Psychology Quarterly , volume =
-
[34]
2025 , eprint=
Towards Understanding Sycophancy in Language Models , author=. 2025 , eprint=
2025
-
[35]
2022 , eprint=
Discovering Language Model Behaviors with Model-Written Evaluations , author=. 2022 , eprint=
2022
-
[36]
2026 , eprint=
Good Arguments Against the People Pleasers: How Reasoning Mitigates (Yet Masks) LLM Sycophancy , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
Persona-Assigned Large Language Models Exhibit Human-Like Motivated Reasoning , author=. 2026 , eprint=
2026
-
[38]
2025 , eprint=
The Personalization Trap: How User Memory Alters Emotional Reasoning in LLMs , author=. 2025 , eprint=
2025
-
[39]
2026 , eprint=
Brittlebench: Quantifying LLM robustness via prompt sensitivity , author=. 2026 , eprint=
2026
-
[40]
2026 , eprint=
Rethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks , author=. 2026 , eprint=
2026
-
[41]
2026 , eprint=
The Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT , author=. 2026 , eprint=
2026
-
[42]
2024 , month = feb, howpublished =
Memory and New Controls for. 2024 , month = feb, howpublished =
2024
-
[43]
2025 , eprint=
Enabling Personalized Long-term Interactions in LLM-based Agents through Persistent Memory and User Profiles , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory , author=. 2025 , eprint=
2025
-
[45]
2023 , eprint=
Large Language Models Can Be Easily Distracted by Irrelevant Context , author=. 2023 , eprint=
2023
-
[46]
2025 , eprint=
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark , author=. 2025 , eprint=
2025
-
[47]
2024 , eprint=
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. 2024 , eprint=
2024
-
[48]
2024 , eprint=
The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance , author=. 2024 , eprint=
2024
-
[49]
Journal of Traumatic Stress , volume =
The Posttraumatic Growth Inventory: Measuring the Positive Legacy of Trauma , author =. Journal of Traumatic Stress , volume =
-
[50]
Diagnostic and Statistical Manual of Mental Disorders (
-
[51]
American Psychologist , volume =
Conservation of Resources: A New Attempt at Conceptualizing Stress , author =. American Psychologist , volume =
-
[52]
3: Loss: Sadness and Depression , author =
Attachment and Loss, Vol. 3: Loss: Sadness and Depression , author =
-
[53]
Death Studies , volume =
The Dual Process Model of Coping with Bereavement: Rationale and Description , author =. Death Studies , volume =
-
[54]
Marital Separation , author =
-
[55]
The Gerontologist , volume =
A Continuity Theory of Normal Aging , author =. The Gerontologist , volume =
-
[56]
Employment and Unemployment: A Social-Psychological Analysis , author =
-
[57]
The Social Psychology of Intergroup Relations , editor =
An Integrative Theory of Intergroup Conflict , author =. The Social Psychology of Intergroup Relations , editor =
-
[58]
American Journal of Community Psychology , volume =
Community Resilience as a Metaphor, Theory, Set of Capacities, and Strategy for Disaster Readiness , author =. American Journal of Community Psychology , volume =
-
[59]
Science , volume =
Perception of Risk , author =. Science , volume =
-
[60]
2022 , eprint=
Scaling Laws for Reward Model Overoptimization , author=. 2022 , eprint=
2022
-
[61]
2023 , eprint=
Evaluating the Moral Beliefs Encoded in LLMs , author=. 2023 , eprint=
2023
-
[62]
, year =
Fang, Xi et al. , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.