Representation Distribution Matching for One-Step Visual Generation
Pith reviewed 2026-07-03 15:15 UTC · model grok-4.3
The pith
Matching generated and real feature distributions across fourteen encoders trains the strongest one-step image generator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By matching the distributions of generated images and real images in the feature spaces of a balanced set of fourteen frozen pretrained encoders using a properly estimated MMD loss with generated batches larger than 2048, improved RDM produces a one-step generator that reaches a Sliced-Wasserstein distance of 1.30 over the fourteen encoders on ImageNet and is preferred by a human-preference proxy on 71.2 percent of comparisons against the previous best one-step method.
What carries the argument
Representation Distribution Matching (RDM), the training paradigm that aligns the feature distribution of a one-step generator's outputs with the feature distribution of real images under frozen pretrained encoders.
If this is right
- The classical maximum mean discrepancy objective becomes effective for one-step generation once estimated with the right procedure.
- The size of the generated batch is the key operative variable and reaches an optimum above 2048 samples.
- Any single encoder representation can be gamed, so matching must occur across a balanced battery of encoders.
- The same recipe converts a four-step model into a one-step model that improves both automated and preference-based metrics.
Where Pith is reading between the lines
- The need for large generated batches may push training infrastructure toward higher memory or distributed setups for distribution-matching methods.
- The multi-encoder matching idea could be tested on video or audio generation tasks where single-representation gaming is also a risk.
- Post-training existing multi-step models to one-step versions could become a standard efficiency step if the recipe generalizes beyond the tested cases.
Load-bearing premise
A Sliced-Wasserstein distance computed over fourteen encoders reliably tracks human perceptual quality and cannot be gamed by the generator.
What would settle it
A one-step generator that scores worse than 1.30 on the fourteen-encoder Sliced-Wasserstein distance yet receives higher human preference scores than the reported improved RDM on a matched sample comparison would falsify the evaluation claim.
Figures

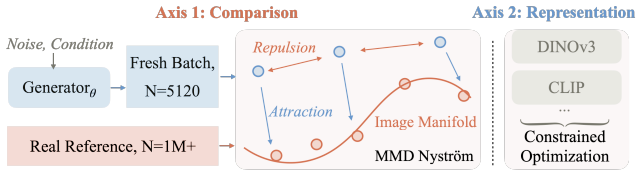
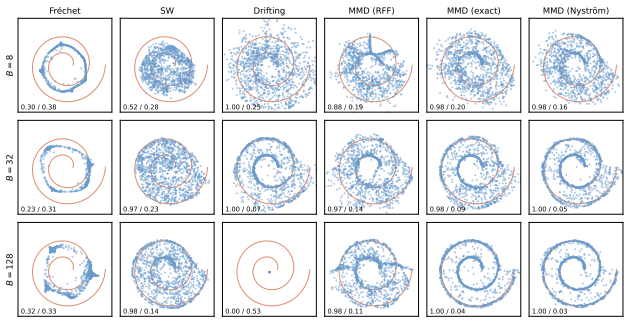





read the original abstract
We elucidate the design space of Representation Distribution Matching (RDM), our name for the paradigm that trains a one-step image generator by matching generated and reference feature distributions under frozen pretrained encoders. We identify two design axes, how the distributions are compared and the representations they are compared in, and controlled studies along them yield three findings. First, the classical MMD, which could not train convincing generators a decade ago, becomes a strong and scalable objective once estimated right. Second, the generated batch is then the operative variable, with an optimum above 2048, far beyond customary batch sizes. Third, any single representation can be gamed, driven below the real score while images stay visibly fake, so we match against a balanced battery of encoders and evaluate with SW_r14, a Sliced-Wasserstein distance over 14 encoders that is independent of the training loss and resists gaming. Combining the preferred choices yields improved RDM (iRDM): it sets the one-step state of the art on ImageNet at SW_r14 1.30, corroborated by PickScore, a human-preference proxy our objective never optimizes, which prefers it over the prior best one-step generator on 71.2% of matched samples. The same recipe post-trains the four-step FLUX.2 [klein] into a one-step generator, surpassing the four-step version on GenEval, 0.826 to 0.794, and on PickScore, 22.76 to 22.58, in 90 H200 GPU-hours. Project page: https://alan-lanfeng.github.io/rdm/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Representation Distribution Matching (RDM) as a paradigm for training one-step image generators via matching generated and real feature distributions under frozen pretrained encoders. Controlled studies identify MMD (properly estimated), large batch sizes (>2048), and a multi-encoder battery as key; their combination yields iRDM, which reports SOTA one-step ImageNet performance at SW_r14 = 1.30 with 71.2% PickScore preference over prior best, and distills FLUX.2 to a one-step model outperforming its four-step version on GenEval (0.826 vs 0.794) and PickScore (22.76 vs 22.58) after 90 H200 GPU-hours.
Significance. If the evaluation protocol holds, the work offers a scalable, non-diffusion training recipe for high-quality one-step generation and a practical distillation route for existing multi-step models. The emphasis on batch size and multi-representation matching, together with the explicit non-optimization of PickScore, supplies falsifiable quantitative claims that could influence efficient generative modeling.
major comments (2)
- [Abstract] Abstract: the central SOTA claim rests on SW_r14 being 'independent of the training loss and resists gaming.' The manuscript asserts this property for the 14-encoder evaluation set but does not enumerate the encoders used in the training battery versus those in SW_r14, nor does it report any overlap analysis or ablation that would confirm the sets are disjoint. This detail is load-bearing for interpreting the reported 1.30 SW_r14 and 71.2% PickScore preference as evidence of genuine progress rather than correlated metric improvement.
- [Abstract] Abstract (and presumably §4 experiments): the controlled studies claim that 'any single representation can be gamed' while a balanced battery cannot, yet no quantitative demonstration is supplied showing that the chosen battery actually prevents the per-encoder gaming behavior described. Without such evidence or an explicit list of the 14 evaluation encoders, the gaming-resistance argument remains unverified and directly affects the reliability of all reported gains.
minor comments (2)
- The abstract references 'controlled studies along [two design axes]' but does not indicate where in the manuscript the full experimental protocol, data splits, or encoder lists appear; adding a short methods overview paragraph would improve readability.
- Project page is mentioned but no link to code or exact hyper-parameters for the MMD estimator and batch-size experiments is provided in the text; reproducibility would benefit from explicit pointers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying these points about the evaluation protocol. We address each major comment below and will incorporate the requested clarifications and ablations into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA claim rests on SW_r14 being 'independent of the training loss and resists gaming.' The manuscript asserts this property for the 14-encoder evaluation set but does not enumerate the encoders used in the training battery versus those in SW_r14, nor does it report any overlap analysis or ablation that would confirm the sets are disjoint. This detail is load-bearing for interpreting the reported 1.30 SW_r14 and 71.2% PickScore preference as evidence of genuine progress rather than correlated metric improvement.
Authors: We agree that an explicit enumeration of the training battery versus the SW_r14 evaluation encoders, together with an overlap analysis, is necessary to substantiate the independence claim. The training battery uses a distinct collection of encoders chosen to avoid overlap with the 14 evaluation encoders; we will add a table listing both sets and a short analysis confirming they are disjoint. These additions will appear in the revised manuscript and do not change the reported numerical results. revision: yes
-
Referee: [Abstract] Abstract (and presumably §4 experiments): the controlled studies claim that 'any single representation can be gamed' while a balanced battery cannot, yet no quantitative demonstration is supplied showing that the chosen battery actually prevents the per-encoder gaming behavior described. Without such evidence or an explicit list of the 14 evaluation encoders, the gaming-resistance argument remains unverified and directly affects the reliability of all reported gains.
Authors: The controlled studies in §4 establish that individual encoders can be gamed, but we acknowledge the absence of a direct quantitative check that the multi-encoder battery resists such gaming. We will add (i) the explicit list of the 14 evaluation encoders and (ii) a quantitative ablation (e.g., per-encoder scores under attempted gaming on the full battery) demonstrating that the balanced set maintains performance across encoders. These elements will be included in the revision. revision: yes
Circularity Check
No significant circularity; evaluation metric explicitly independent of training objective
full rationale
The paper's core contribution is an empirical recipe for one-step generation via MMD-based distribution matching on a battery of frozen encoders, with batch-size scaling. The headline SOTA claim rests on SW_r14 (Sliced-Wasserstein over 14 encoders) and PickScore, both stated to be independent of the training loss and never optimized during training. No equations, fitted parameters, or self-citations reduce the reported improvements to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems , year=
-
[2]
International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , year=
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , author=. Advances in Neural Information Processing Systems , year=
-
[4]
, booktitle=
Deshpande, Ishan and Zhang, Ziyu and Schwing, Alexander G. , booktitle=. Generative Modeling Using the Sliced
-
[5]
Wu, Jiqing and Huang, Zhiwu and Acharya, Dinesh and Li, Wen and Thoma, Janine and Paudel, Danda Pani and Van Gool, Luc , booktitle=. Sliced
-
[6]
Advances in Neural Information Processing Systems , year=
Random Features for Large-Scale Kernel Machines , author=. Advances in Neural Information Processing Systems , year=
-
[7]
2025 , note=
Back to Basics: Let Denoising Generative Models Denoise , author=. 2025 , note=
2025
-
[8]
2026 , note=
Generative Modeling via Drifting , author=. 2026 , note=
2026
-
[9]
2026 , note=
Representation Fr\'echet Loss for Visual Generation , author=. 2026 , note=
2026
-
[10]
2026 , note=
One-step Latent-free Image Generation with Pixel Mean Flows , author=. 2026 , note=
2026
-
[11]
Advances in Neural Information Processing Systems , year=
Mean Flows for One-step Generative Modeling , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=
Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup , author=. Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=. 2021 , publisher=. doi:10.18653/v1/2021.repl4nlp-1.31 , url=
-
[13]
Rethinking
Jayasumana, Sadeep and Ramalingam, Srikumar and Veit, Andreas and Glasner, Daniel and Chakrabarti, Ayan and Kumar, Sanjiv , booktitle=. Rethinking
-
[14]
Advances in Neural Information Processing Systems , volume=
Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Journal of Machine Learning Research , volume=
A Kernel Two-Sample Test , author=. Journal of Machine Learning Research , volume=
-
[16]
Journal of Machine Learning Research , volume=
Hilbert Space Embeddings and Metrics on Probability Measures , author=. Journal of Machine Learning Research , volume=
-
[17]
Journal of Machine Learning Research , volume=
Schrab, Antonin and Kim, Ilmun and Albert, M. Journal of Machine Learning Research , volume=
-
[18]
Malladi, Sadhika and Lyu, Kaifeng and Panigrahi, Abhishek and Arora, Sanjeev , booktitle=. On the
-
[19]
Chatalic, Antoine and Schreuder, Nicolas and Rosasco, Lorenzo and Rudi, Alessandro , booktitle=. Nystr
-
[20]
Yang, Tianbao and Li, Yu-Feng and Mahdavi, Mehrdad and Jin, Rong and Zhou, Zhi-Hua , booktitle=. Nystr
-
[21]
Falahati, Ali and Creager, Elliot and Kamath, Gautam and Mohapatra, Shubhankar , year=
-
[22]
International Conference on Machine Learning , year=
Generative Moment Matching Networks , author=. International Conference on Machine Learning , year=
-
[23]
Advances in Neural Information Processing Systems , year=
Li, Chun-Liang and Chang, Wei-Cheng and Cheng, Yu and Yang, Yiming and P. Advances in Neural Information Processing Systems , year=
-
[24]
Improved Techniques for Training
Salimans, Tim and Goodfellow, Ian and Zaremba, Wojciech and Cheung, Vicki and Radford, Alec and Chen, Xi , booktitle=. Improved Techniques for Training
-
[25]
One-Step Generative Modeling via
Han, Jiaqi and Li, Puheng and Guo, Qiushan and Xu, Renyuan and Ermon, Stefano and Cand. One-Step Generative Modeling via. 2026 , note=
2026
-
[26]
Ghosh, Dhruba and Hajishirzi, Hannaneh and Schmidt, Ludwig , booktitle=
-
[27]
2026 , howpublished=
2026
-
[28]
2024 , howpublished=
2024
-
[29]
Advances in Neural Information Processing Systems , year=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , year=
-
[30]
`Improving Ratings': Audit in the
Strathern, Marilyn , journal=. `Improving Ratings': Audit in the
-
[31]
Advances in Neural Information Processing Systems , year=
Generative Adversarial Nets , author=. Advances in Neural Information Processing Systems , year=
-
[32]
Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence , pages=
Training Generative Neural Networks via Maximum Mean Discrepancy Optimization , author=. Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence , pages=
-
[33]
Demystifying
Bi. Demystifying. International Conference on Learning Representations , year=
-
[34]
Foundations and Trends in Machine Learning , volume=
Kernel Mean Embedding of Distributions: A Review and Beyond , author=. Foundations and Trends in Machine Learning , volume=
-
[35]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Scalable Diffusion Models with Transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[38]
International Conference on Learning Representations , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations , year=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
One-step Diffusion with Distribution Matching Distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[40]
Advances in Neural Information Processing Systems , year=
Improved Distribution Matching Distillation for Fast Image Synthesis , author=. Advances in Neural Information Processing Systems , year=
-
[41]
International Conference on Machine Learning , year=
Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation , author=. International Conference on Machine Learning , year=
-
[42]
Luo, Weijian and Hu, Tianyang and Zhang, Shifeng and Sun, Jiacheng and Li, Zhenguo and Zhang, Zhihua , booktitle=
-
[43]
European Conference on Computer Vision , year=
Adversarial Diffusion Distillation , author=. European Conference on Computer Vision , year=
-
[44]
Advances in Neural Information Processing Systems , year=
Multistep Distillation of Diffusion Models via Moment Matching , author=. Advances in Neural Information Processing Systems , year=
-
[45]
International Conference on Machine Learning , year=
Consistency Models , author=. International Conference on Machine Learning , year=
-
[46]
International Conference on Learning Representations , year=
Improved Techniques for Training Consistency Models , author=. International Conference on Learning Representations , year=
-
[47]
International Conference on Learning Representations , year=
Consistency Models Made Easy , author=. International Conference on Learning Representations , year=
-
[48]
International Conference on Learning Representations , year=
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models , author=. International Conference on Learning Representations , year=
-
[49]
International Conference on Learning Representations , year=
One Step Diffusion via Shortcut Models , author=. International Conference on Learning Representations , year=
-
[50]
International Conference on Machine Learning , year=
Inductive Moment Matching , author=. International Conference on Machine Learning , year=
-
[51]
International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. International Conference on Learning Representations , year=
-
[52]
European Conference on Computer Vision , year=
Perceptual Losses for Real-Time Style Transfer and Super-Resolution , author=. European Conference on Computer Vision , year=
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[54]
Fu, Stephanie and Tamir, Netanel and Sundaram, Shobhita and Chai, Lucy and Zhang, Richard and Dekel, Tali and Isola, Phillip , booktitle=
-
[55]
International Conference on Learning Representations , year=
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author=. International Conference on Learning Representations , year=
-
[56]
Projected
Sauer, Axel and Chitta, Kashyap and M. Projected. Advances in Neural Information Processing Systems , year=
-
[57]
Ensembling Off-the-shelf Models for
Kumari, Nupur and Zhang, Richard and Shechtman, Eli and Zhu, Jun-Yan , booktitle=. Ensembling Off-the-shelf Models for
-
[58]
Advances in Neural Information Processing Systems , year=
Improved Precision and Recall Metric for Assessing Generative Models , author=. Advances in Neural Information Processing Systems , year=
-
[59]
The Role of
Kynk. The Role of. International Conference on Learning Representations , year=
-
[60]
On Aliased Resizing and Surprising Subtleties in
Parmar, Gaurav and Zhang, Richard and Zhu, Jun-Yan , booktitle=. On Aliased Resizing and Surprising Subtleties in
-
[61]
International Conference on Machine Learning , year=
Scaling Laws for Reward Model Overoptimization , author=. International Conference on Machine Learning , year=
-
[62]
Advances in Neural Information Processing Systems , year=
Defining and Characterizing Reward Gaming , author=. Advances in Neural Information Processing Systems , year=
-
[63]
International Conference on Learning Representations , year=
Reward Model Ensembles Help Mitigate Overoptimization , author=. International Conference on Learning Representations , year=
-
[64]
Responsive Safety in Reinforcement Learning by
Stooke, Adam and Achiam, Joshua and Abbeel, Pieter , booktitle=. Responsive Safety in Reinforcement Learning by
-
[65]
Xu, Jiazheng and Liu, Xiao and Wu, Yuchen and Tong, Yuxuan and Li, Qinkai and Ding, Ming and Tang, Jie and Dong, Yuxiao , booktitle=
-
[66]
Kirstain, Yuval and Polyak, Adam and Singer, Uriel and Matiana, Shahbuland and Penna, Joe and Levy, Omer , booktitle=
-
[67]
International Conference on Learning Representations , year=
Training Diffusion Models with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Diffusion Model Alignment Using Direct Preference Optimization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[69]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
Rethinking the Inception Architecture for Computer Vision , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[70]
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , booktitle=. A
-
[71]
Transactions on Machine Learning Research , year=
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year=
-
[72]
Transactions on Machine Learning Research , year=
Oriane Sim. Transactions on Machine Learning Research , year=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Masked Autoencoders Are Scalable Vision Learners , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[74]
International Conference on Machine Learning , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning , year=
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Sigmoid Loss for Language Image Pre-Training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[76]
Tschannen, Michael and Gritsenko, Alexey and Wang, Xiao and Naeem, Muhammad Ferjad and Alabdulmohsin, Ibrahim and Parthasarathy, Nikhil and Evans, Talfan and Beyer, Lucas and Xia, Ye and Mustafa, Basil and H. arXiv preprint arXiv:2502.14786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Advances in Neural Information Processing Systems , year=
Perception Encoder: The Best Visual Embeddings Are Not at the Output of the Network , author=. Advances in Neural Information Processing Systems , year=
-
[78]
Ranzinger, Mike and Heinrich, Greg and Kautz, Jan and Molchanov, Pavlo , booktitle=
-
[79]
Heinrich, Greg and Ranzinger, Mike and Yin, Hongxu and Lu, Yao and Kautz, Jan and Tao, Andrew and Catanzaro, Bryan and Molchanov, Pavlo , booktitle=
-
[80]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Scaling Language-Free Visual Representation Learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.