HULAT2 at MER-TRANS 2026: Governed Multi-Agent Simplification for Spanish Easy-to-Read Generation
Pith reviewed 2026-07-03 14:32 UTC · model grok-4.3
The pith
Signal-guided multi-agent routing outperforms linear regeneration for Spanish Easy-to-Read generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the Spanish track of MER-TRANS 2026, the signal-guided multi-agent workflow achieved the highest SARI score of 44.0543 among the team's submissions and outperformed the linear regeneration baseline at 38.5136, while addition of a lexical-support layer produced a lower score of 43.1049.
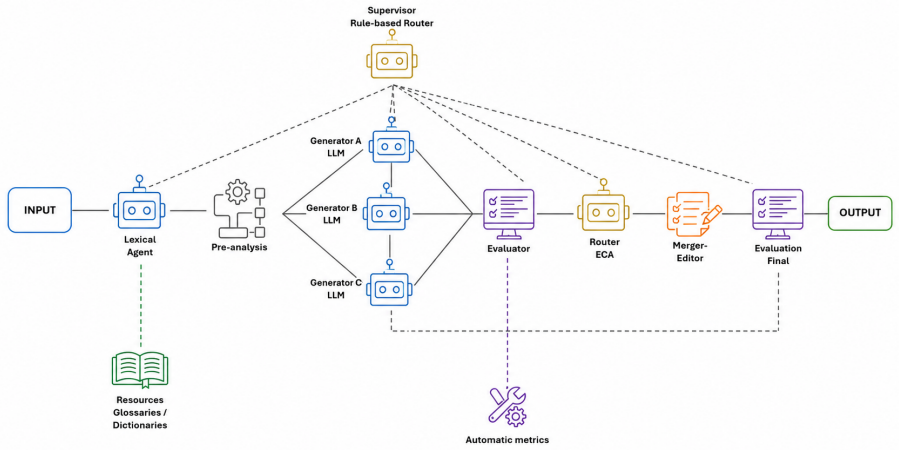
What carries the argument
Event-Condition-Action routing driven by internal quality signals for semantic fidelity, readability, lexical simplicity, syntactic clarity and factual consistency.
If this is right
- Signal-guided multi-agent routing yields higher SARI than linear regeneration in this Easy-to-Read setting.
- An added lexical-support layer based on glossaries does not raise reference-based scores.
- Traceable decisions from the routing allow controlled editing during generation.
Where Pith is reading between the lines
- Segment-level and document-level breakdowns could show whether the SARI gains correspond to improved readability for target readers.
- The same routing logic could be applied to other languages in the shared task to test cross-lingual consistency.
- Human adequacy ratings would be needed to check whether higher automatic scores reflect better factual consistency and user suitability.
Load-bearing premise
The five internal quality signals serve as reliable proxies for the official SARI and BERTScore metrics.
What would settle it
A measured correlation near zero between the internal signals and official SARI scores on the same test segments would show that the routing decisions do not track the leaderboard metric.
Figures
read the original abstract
This paper describes the participation of HULAT2-UC3M in the Spanish track of MER-TRANS 2026, a shared task on multilingual Easy-to-Read translation. Three fully automatic Spanish runs were submitted. RUN1 and RUN2 used a LangGraph-based multi-agent workflow combining Gemini 2.5 Flash and RigoChat-7B-v2, parallel generation strategies, internal quality signals, Event-Condition-Action routing, controlled editing and traceable decisions. RUN1 used the base workflow, while RUN2 activated an additional lexical-support layer based on a glossary and lexical resources. RUN3 was a RigoChat-based generate-evaluate-regenerate baseline with prompt engineering and LoRA-based adaptation. The official leaderboard reports BLEU-Orig, BLEU-Gold, SARI and BERTScore. During development, additional internal signals were also inspected, including semantic fidelity, readability, lexical simplicity, syntactic clarity and factual consistency. According to official SARI, RUN1 was the best HULAT2 run, with 44.0543 points, followed by RUN2 with 43.1049 and RUN3 with 38.5136. These results indicate that, in this task setting, signal-guided multi-agent routing outperformed the linear regeneration baseline. They also show that adding lexical support did not automatically improve reference-based scores. Further segment-level and document-level analysis are required to assess readability, factual consistency and user-oriented adequacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports HULAT2's participation in the Spanish track of the MER-TRANS 2026 shared task on Easy-to-Read translation. It describes three runs: RUN1 and RUN2 implement a LangGraph multi-agent workflow using Gemini 2.5 Flash and RigoChat-7B-v2 with parallel generation, internal quality signals (semantic fidelity, readability, lexical simplicity, syntactic clarity, factual consistency), Event-Condition-Action routing, and controlled editing; RUN2 adds a lexical-support glossary layer. RUN3 is a linear generate-evaluate-regenerate baseline using only RigoChat-7B-v2 with LoRA adaptation. Official leaderboard results are reported: RUN1 achieves the highest SARI (44.0543), followed by RUN2 (43.1049) and RUN3 (38.5136). The authors conclude that signal-guided multi-agent routing outperformed the linear baseline and that lexical support did not improve reference-based scores.
Significance. The work contributes a detailed system description and official shared-task scores for a governed multi-agent approach to Spanish text simplification. If the SARI advantage can be isolated to the routing mechanism, it would support the value of internal quality signals and traceable multi-agent control in simplification pipelines. The explicit comparison of multiple runs and the use of official metrics are strengths. However, the absence of controlled ablations limits the ability to draw firm conclusions about the routing component.
major comments (2)
- [Results] Results: The SARI difference between RUN1 (44.0543) and RUN3 (38.5136) is presented as evidence that signal-guided multi-agent routing outperformed the linear regeneration baseline, yet RUN1 combines Gemini 2.5 Flash with RigoChat-7B-v2 while RUN3 uses only RigoChat-7B-v2 with LoRA; no ablation holding the underlying LLMs fixed is reported, so the performance delta cannot be attributed to the Event-Condition-Action routing, parallel generation, or internal signals rather than model capability.
- [Methods] Methods: The Event-Condition-Action routing decisions depend on internal quality signals whose correlation with the official SARI and BERTScore metrics is not validated or quantified anywhere in the manuscript, leaving open whether these signals are reliable proxies for the leaderboard outcomes.
minor comments (2)
- [Abstract] Abstract and Results: No error bars, segment-level breakdowns, or statistical tests are provided for the reported score differences, which weakens the strength of the outperformance claim.
- [Conclusion] The manuscript states that 'further segment-level and document-level analysis are required' but does not include any such analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on result attribution and signal validation. We respond point by point below.
read point-by-point responses
-
Referee: [Results] Results: The SARI difference between RUN1 (44.0543) and RUN3 (38.5136) is presented as evidence that signal-guided multi-agent routing outperformed the linear regeneration baseline, yet RUN1 combines Gemini 2.5 Flash with RigoChat-7B-v2 while RUN3 uses only RigoChat-7B-v2 with LoRA; no ablation holding the underlying LLMs fixed is reported, so the performance delta cannot be attributed to the Event-Condition-Action routing, parallel generation, or internal signals rather than model capability.
Authors: We agree that the SARI difference cannot be attributed solely to the routing, parallel generation, or internal signals, as RUN1 and RUN3 employ different underlying models. The manuscript will be revised to clarify this limitation and rephrase the conclusion to state that the multi-agent workflow with mixed models achieved the highest score among our submissions, without claiming isolation of the routing effect. revision: yes
-
Referee: [Methods] Methods: The Event-Condition-Action routing decisions depend on internal quality signals whose correlation with the official SARI and BERTScore metrics is not validated or quantified anywhere in the manuscript, leaving open whether these signals are reliable proxies for the leaderboard outcomes.
Authors: The manuscript describes the internal signals and their use in routing but provides no quantitative correlation with official metrics. We will revise to explicitly note this as a limitation and add a brief discussion of how the signals were inspected during development, without claiming they are validated proxies. revision: yes
Circularity Check
No circularity: purely empirical shared-task reporting
full rationale
The paper reports participation in the MER-TRANS 2026 shared task by describing three runs (RUN1/RUN2 multi-agent workflows vs RUN3 linear baseline) and citing official leaderboard scores (SARI 44.0543 vs 38.5136). No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear. The central claim rests on external competition metrics rather than any internal reduction to inputs or ansatzes. This is self-contained empirical reporting against an external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Organization for Standardization, ISO 21801-1:2020 Cognitive accessibility – Part 1: General guidelines, https://www.iso.org/standard/71711.html, 2020
2020
-
[2]
International Organization for Standardization, ISO 24495-1:2023 Plain language – Part 1: Govern- ing principles and guidelines, https://www.iso.org/standard/78907.html, 2023
2023
-
[3]
Lectura Fácil
Asociación Española de Normalización, UNE 153101:2018 EX. Lectura Fácil. Pautas y recomenda- ciones para la elaboración de documentos, https://www.une.org/, 2018
2018
-
[4]
Nomura, G
M. Nomura, G. S. Nielsen, B. Tronbacke, Guidelines for easy-to-read materials, https://www.ifla. org/wp-content/uploads/2019/05/assets/hq/publications/professional-report/120.pdf, 2010
2019
-
[5]
Inclusion Europe, Information for all: European standards for making information easy to read and understand, https://www.inclusion-europe.eu/easy-to-read-standards-guidelines/, 2009
2009
-
[6]
H. Saggion, Automatic Text Simplification, Synthesis Lectures on Human Language Technologies, Springer Cham, 2017. URL: https://link.springer.com/book/10.1007/978-3-031-02166-4. doi: 10. 1007/978-3-031-02166-4
-
[7]
S. Nisioi, S. Štajner, S. P. Ponzetto, L. P. Dinu, Exploring neural text simplification models, in: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Vancouver, Canada, 2017, pp. 85–91. URL: https: //aclanthology.org/P17-2014/. doi:10.18653/v1/P17-2014
-
[8]
P. Martínez, A. Ramos, L. Moreno, Exploring large language models to generate easy to read content, Frontiers in Computer Science 6 (2024) 1394705. URL: https://doi.org/10.3389/fcomp.2024.1394705. doi:10.3389/fcomp.2024.1394705
-
[9]
Jan Melechovsky, Abhinaba Roy, and Dorien Herremans
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, BLEU: A method for automatic evaluation of machine translation, in: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 2002, pp. 311–318. URL: https://aclanthology.org/P02-1040/. doi:10.3115/1073083.1073135
-
[10]
W. Xu, C. Napoles, E. Pavlick, Q. Chen, C. Callison-Burch, Optimizing statistical machine transla- tion for text simplification, Transactions of the Association for Computational Linguistics 4 (2016) 401–415. URL: https://aclanthology.org/Q16-1029/. doi:10.1162/tacl_a_00107
-
[11]
Zhang, V
T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi, BERTScore: Evaluating text generation with BERT, in: International Conference on Learning Representations, 2020. URL: https://openreview. net/forum?id=SkeHuCVFDr
2020
-
[12]
F. Alva-Manchego, C. Scarton, L. Specia, The (Un)Suitability of automatic evaluation metrics for text simplification, Computational Linguistics 47 (2021) 861–889. doi:10.1162/coli_a_00418
-
[13]
M. Maddela, Y. Dou, D. Heineman, W. Xu, LENS: A learnable evaluation metric for text sim- plification, in: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Toronto, Canada, 2023, pp. 16383–16408. URL: https://aclanthology.org/2023.acl-long.905/. doi:10.18653/v1/2023.acl-long.905
-
[14]
M. Maddela, F. Alva-Manchego, Adapting sentence-level automatic metrics for document-level simplification evaluation, in: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, As- sociation for Computational Linguistics, Albuquerque, New Mexico, 2025, pp. 64...
-
[15]
Cripwell, J
L. Cripwell, J. Legrand, C. Gardent, Evaluating document simplification: On the importance of separately assessing simplicity and meaning preservation, in: Proceedings of the 3rd Workshop on Tools and Resources for People with READing Difficulties (READI) @ LREC-COLING 2024, ELRA and ICCL, Torino, Italia, 2024, pp. 1–14. URL: https://aclanthology.org/2024...
2024
-
[16]
S. Agrawal, M. Carpuat, Do text simplification systems preserve meaning? a human evaluation via reading comprehension, Transactions of the Association for Computational Linguistics 12 (2024) 432–448. URL: https://aclanthology.org/2024.tacl-1.24/. doi:10.1162/tacl_a_00653
-
[17]
Carrer, A
L. Carrer, A. Säuberli, M. Kappus, S. Ebling, Towards holistic human evaluation of automatic text simplification, in: Proceedings of the Fourth Workshop on Human Evaluation of NLP Systems (HumEval) @ LREC-COLING 2024, ELRA and ICCL, Torino, Italia, 2024, pp. 71–80. URL: https://aclanthology.org/2024.humeval-1.7/
2024
-
[18]
H. Saggion, S. Štajner, D. Ferrés, K. C. Sheang, M. Shardlow, K. North, M. Zampieri, Findings of the TSAR-2022 shared task on multilingual lexical simplification, in: Proceedings of the Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2022, pp. 271–283....
-
[19]
Štajner, H
S. Štajner, H. Saggion, M. Shardlow, F. Alva-Manchego (Eds.), Proceedings of the Second Workshop on Text Simplification, Accessibility and Readability, INCOMA Ltd., Shoumen, Bulgaria, Varna, Bulgaria, 2023. URL: https://aclanthology.org/2023.tsar-1.0/
2023
-
[20]
M. Shardlow, H. Saggion, F. Alva-Manchego, M. Zampieri, K. North, S. Štajner, R. Stodden (Eds.), Proceedings of the Third Workshop on Text Simplification, Accessibility and Readabil- ity (TSAR 2024), Association for Computational Linguistics, Miami, Florida, USA, 2024. URL: https://aclanthology.org/2024.tsar-1.0/. doi:10.18653/v1/2024.tsar-1.0
-
[21]
M. Shardlow, F. Alva-Manchego, K. North, R. Stodden, H. Saggion, N. Khallaf, A. Hayakawa (Eds.), Proceedings of the Fourth Workshop on Text Simplification, Accessibility and Readability (TSAR 2025), Association for Computational Linguistics, Suzhou, China, 2025. URL: https://aclanthology. org/2025.tsar-1.0/. doi:10.18653/v1/2025.tsar-1.0
-
[22]
F. Alva-Manchego, R. Stodden, J. M. Imperial, A. Barayan, K. North, H. Tayyar Madabushi, Findings of the TSAR 2025 shared task on readability-controlled text simplification, in: Proceedings of the Fourth Workshop on Text Simplification, Accessibility and Readability (TSAR 2025), Association for Computational Linguistics, Suzhou, China, 2025, pp. 116–130. ...
-
[23]
Wilkens, R
R. Wilkens, R. Cardon, A. Todirascu, N. Gala (Eds.), Proceedings of the 3rd Workshop on Tools and Resources for People with READing Difficulties (READI) @ LREC-COLING 2024, ELRA and ICCL, Torino, Italia, 2024. URL: https://aclanthology.org/2024.readi-1.0/
2024
-
[24]
B. Botella-Gil, I. Espinosa-Zaragoza, A. Bonet-Jover, M. Madina, L. Molino Piñar, P. Moreda, I. Gonzalez-Dios, M. T. Martín-Valdivia, L. A. Ureña-López, Overview of clears at iberlef 2025: Challenge for plain language and easy-to-read adaptation for spanish texts, Procesamiento del Lenguaje Natural (2025) 393–400. doi:10.26342/2025-75-28
-
[25]
Saggion, M
H. Saggion, M. Tareh, N. Khallaf, D. Adanza, S. Bott, N. Pérez-Rojas, A. Rascón-Alcaina, S. Szasz, Overview of MER-TRANS at IberLEF 2026: First shared task on multilingual easy-to-read transla- tion, Procesamiento del Lenguaje Natural 77 (2026)
2026
-
[26]
Bonet-Jover, J
A. Bonet-Jover, J. Á. González-Barba, L. Chiruzzo, Overview of IberLEF 2026: Natural language processing challenges for spanish and other iberian languages, in: Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2026), co-located with the 42nd Conference of the Spanish Society for Natural Language Processing (SEPLN 2026), CEUR-WS.org, 2026
2026
-
[27]
S. Bott, V. Riegler, H. Saggion, A. Rascón Alcaina, N. Khallaf, A multilingual human annotated corpus of original and easy-to-read texts to support access to democratic participatory processes, in: Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), European Language Resources Association (ELRA), Palma, Mallorca, Spain, ...
-
[28]
Khallaf, S
N. Khallaf, S. Sharoff, Automatic difficulty classification of Arabic sentences, in: N. Habash, H. Bouamor, H. Hajj, W. Magdy, W. Zaghouani, F. Bougares, N. Tomeh, I. Abu Farha, S. Touileb (Eds.), Proceedings of the Sixth Arabic Natural Language Processing Workshop, Association for Computational Linguistics, Kyiv, Ukraine (Virtual), 2021, pp. 105–114. URL...
2021
-
[29]
MER-TRANS Organizers, MER-TRANS 2026: Multilingual easy-to-read translation shared task, https://lastus-taln-upf.github.io/mertrans-iberlef-2026/, 2026
2026
-
[30]
LaSTUS-TALN-UPF, MER-TRANS Evaluator 2026: Evaluator for shared-task submissions, https: //github.com/LaSTUS-TALN-UPF/mertrans-evaluator-2026, 2026
2026
-
[31]
HULAT-UC3M, Bilingual Simplification Metrics: A unified evaluation framework for text simplifi- cation (ES/EN), https://github.com/hulat-group/bilingual_simplification_metrics, 2026
2026
-
[32]
L. Campillos-Llanos, A. R. Terroba Reinares, S. Zakhir Puig, A. Valverde-Mateos, A. Capllonch- Carrión, Building a comparable corpus and a benchmark for spanish medical text simplification, Procesamiento del Lenguaje Natural (2022) 189–196. doi:10.26342/2022-69-16
-
[33]
L. Moreno, P. Martínez, A human-in/on-the-loop framework for accessible text generation, in: Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), European Language Resources Association (ELRA), Palma, Mallorca, Spain, 2026, pp. 7236–7247. URL: https://lrec.elra.info/lrec2026-main-574. doi:10.63317/2gtngp2nmx63
-
[34]
URL: https://docs.langchain.com/oss/python/langgraph/ overview
LangChain, LangGraph overview, 2026. URL: https://docs.langchain.com/oss/python/langgraph/ overview
2026
-
[35]
URL: https://ai.google.dev/gemini-api/docs/ models/gemini-2.5-flash
Google AI for Developers, Gemini 2.5 flash, 2026. URL: https://ai.google.dev/gemini-api/docs/ models/gemini-2.5-flash
2026
-
[36]
G. Santamaría Gómez, G. García Subies, P. Gutiérrez Ruiz, M. González Valero, N. Fuertes, H. Montoro Zamorano, C. Muñoz Sanz, L. Rosado Plaza, N. Aldama García, D. Betancur Sánchez, K. Sushkova, M. Guerrero Nieto, Á. Barbero Jiménez, RigoChat 2: An adapted language model to spanish using a bounded dataset and reduced hardware, 2025. URL: https://arxiv.org...
-
[37]
L. Moreno, P. Martínez, AIGov-Access: AI Governance for Accessibility-Oriented Text Adaptation — MER-TRANS 2026 Profile, 2026. URL: https://doi.org/10.5281/zenodo.20855013. doi: 10.5281/ zenodo.20855013
-
[38]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations,
-
[39]
URL: https://openreview.net/forum?id=nZeVKeeFYf9
-
[40]
D. Beauchemin, H. Saggion, R. Khoury, MeaningBERT: Assessing meaning preservation between sentences, Frontiers in Artificial Intelligence 6 (2023). URL: https://www.frontiersin.org/articles/ 10.3389/frai.2023.1223924. doi:10.3389/frai.2023.1223924
-
[41]
Fernández Huerta, Medidas sencillas de lecturabilidad, Consigna 214 (1959) 29–32
J. Fernández Huerta, Medidas sencillas de lecturabilidad, Consigna 214 (1959) 29–32. A. Public Resources Used for Calibration and Lexical Support The following public resources were used during system calibration, prompt refinement or glossary construction: • Plena Inclusión España, The Spanish Constitution in Easy-to-Read Format, Easy-to-Read publication...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.