FlintKV: A Fast Durable Storage Engine for Modern Databases
Pith reviewed 2026-07-03 05:37 UTC · model grok-4.3
The pith
FlintKV delivers durable linearizability and full production KV API support on NVM with up to 75% throughput gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
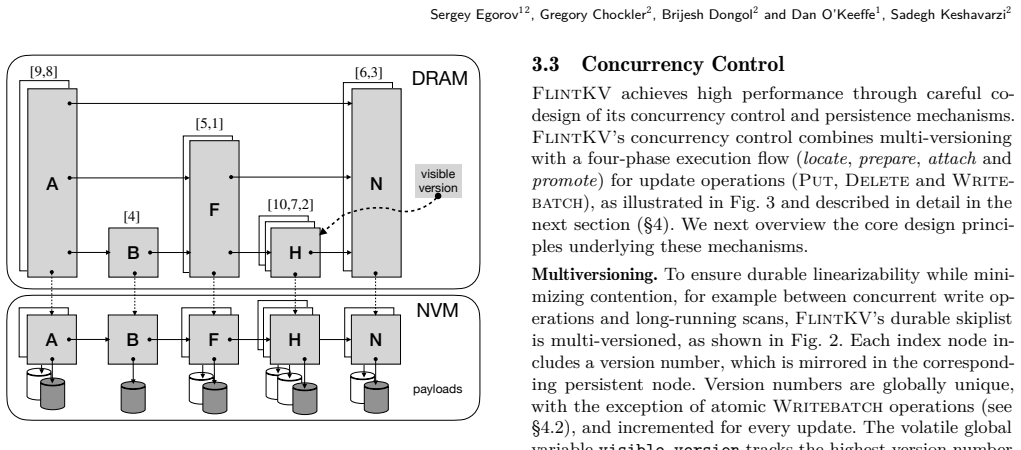
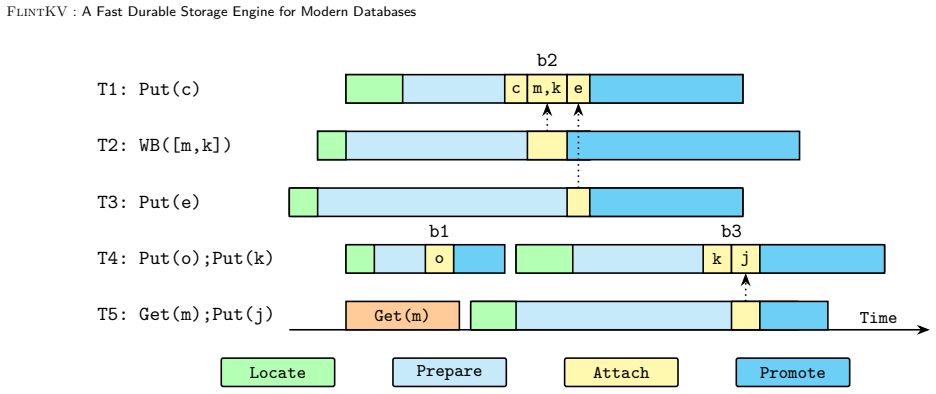
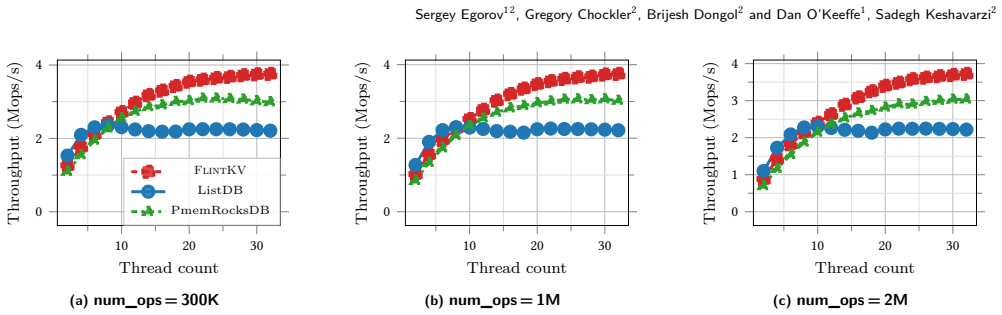
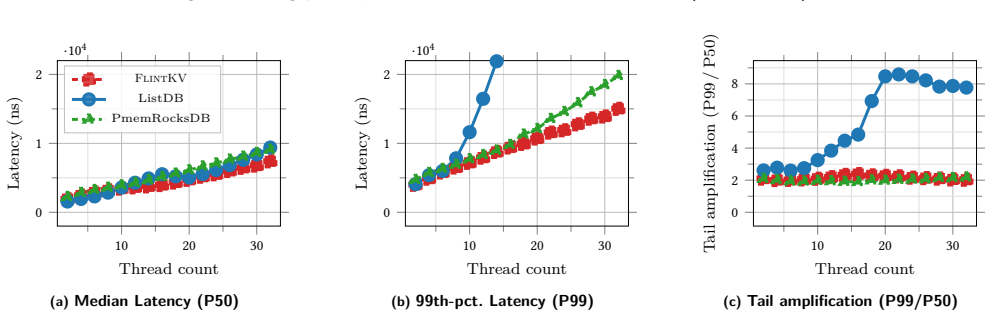
FlintKV is a skiplist-based storage engine for non-volatile memory that supports the complete interface of production key-value stores, including atomic batch writes and snapshot-consistent iteration, while guaranteeing durable linearizability. Its central mechanism is a novel flat-combining concurrency control algorithm that uses multi-versioning and carefully co-designed persistence mechanisms. The engine can operate standalone or supply its durable skiplist to existing NVM stores, and empirical measurements show up to 75% higher end-to-end throughput than prior work.
What carries the argument
A flat-combining concurrency control algorithm that leverages multi-versioning and co-designed persistence mechanisms on a skiplist data structure to coordinate operations while preserving durability and consistency guarantees.
If this is right
- FlintKV can be deployed as a standalone engine or its durable skiplist component integrated into other NVM-based stores.
- Atomic batch writes and snapshot-consistent iterators become available with durable linearizability.
- End-to-end throughput for database workloads can increase by up to 75% relative to earlier NVM key-value engines.
- The engine supplies the interface features required to implement transactions and concurrency control on NVM hardware.
Where Pith is reading between the lines
- Existing NVM stores could adopt the durable skiplist to gain full database API support without complete redesign.
- Transaction systems built on NVM might achieve higher performance by relying on these co-designed persistence mechanisms.
- Further measurements with mixed read-write ratios and varying snapshot frequencies could expose additional scaling behavior.
Load-bearing premise
The flat-combining algorithm with multi-versioning and persistence mechanisms incurs no substantial hidden synchronization or durability overheads once full database concurrency control is applied.
What would settle it
A measurement under high-concurrency transactional workloads in which FlintKV fails to exceed prior NVM stores in throughput by a large margin or violates durability linearizability on any operation sequence.
Figures

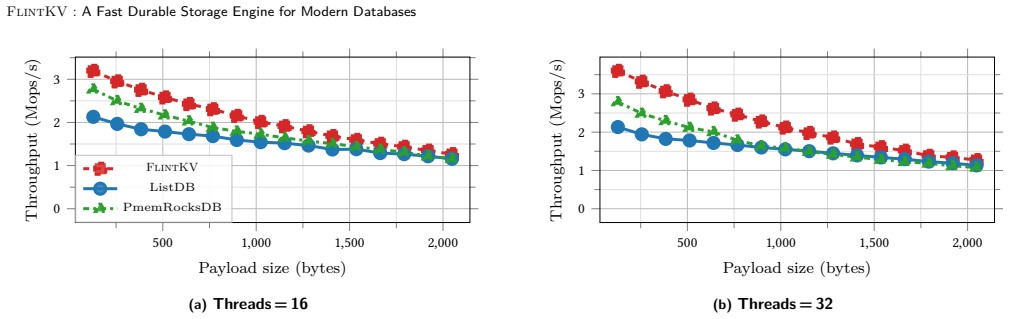
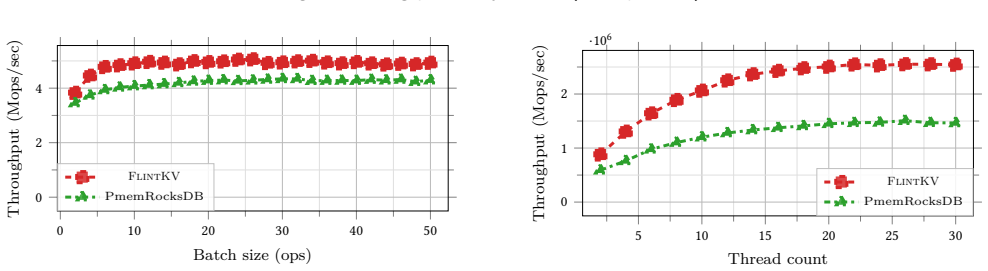
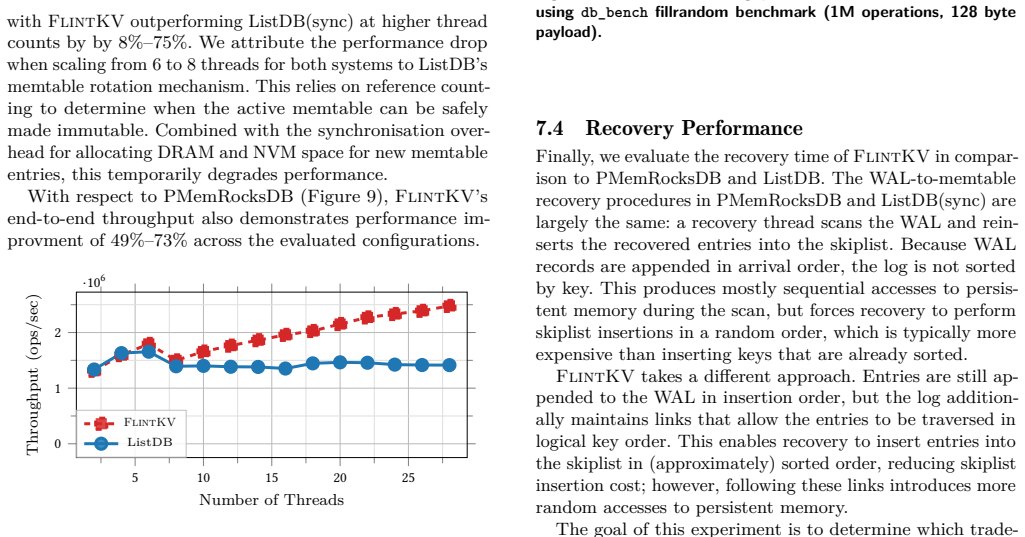
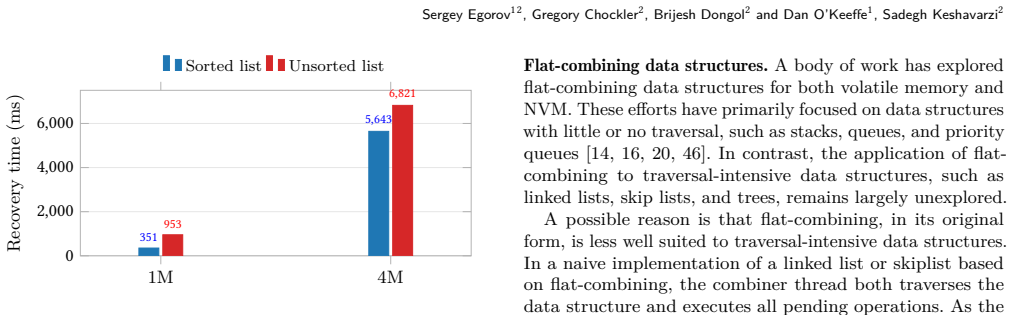
read the original abstract
Byte-addressable non-volatile memory (NVM) offers an opportunity to rethink storage engine architectures. While recent NVM key-value stores achieve high throughput for ingestion and point lookups, they omit or under-specify the support for the richer interface guarantees required by modern databases. Production key-value engines (e.g., RocksDB) provide point-in-time snapshots, consistent iterators, and atomic batches-features essential for implementing transactions and concurrency control. We present FlintKV, an NVM-optimized skiplist-based storage engine that natively supports the full API of production key-value stores. FlintKV supports both atomic batch writes and snapshot-consistent iteration efficiently while guaranteeing durable linearizability. FlintKV can be deployed standalone or its durable skiplist can be integrated into existing NVM stores to enhance their capabilities. Central to FlintKV is a novel flat-combining based concurrency control algorithm that leverages multi-versioning and carefully co-designed persistence mechanisms to ensure high performance and scalability. Our empirical evaluation shows that FlintKV can achieve up to a 75% improvement in end-to-end throughput over prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FlintKV, an NVM-optimized skiplist-based key-value storage engine designed to support the full production KV interface including atomic batch writes, snapshot-consistent iterators, and durable linearizability. It introduces a flat-combining concurrency control algorithm combined with multi-versioning and co-designed persistence mechanisms. The central claim is that this design enables up to 75% higher end-to-end throughput compared to prior work while maintaining the required guarantees, and that the durable skiplist can be used standalone or integrated into existing NVM stores.
Significance. If the performance and correctness claims hold under full concurrent workloads that exercise atomic batches and snapshot iteration, the work would be significant for bridging the gap between high-throughput NVM microbenchmarks and the richer API requirements of modern database storage engines.
major comments (1)
- [Evaluation] Evaluation section: The headline claim of up to 75% end-to-end throughput improvement is presented without any description of the workloads (point lookups vs. concurrent snapshot iteration vs. multi-writer atomic batches), measurement methodology, number of threads, error bars, or confirmation that the full API was exercised. This directly undermines assessment of whether the flat-combining + multi-versioning + persistence co-design actually avoids hidden synchronization or durability overheads under database-style access patterns.
minor comments (1)
- [Abstract] The abstract states support for 'durable linearizability' but does not clarify the precise consistency model or how it is proven for the skiplist operations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comment on the evaluation section below.
read point-by-point responses
-
Referee: The headline claim of up to 75% end-to-end throughput improvement is presented without any description of the workloads (point lookups vs. concurrent snapshot iteration vs. multi-writer atomic batches), measurement methodology, number of threads, error bars, or confirmation that the full API was exercised. This directly undermines assessment of whether the flat-combining + multi-versioning + persistence co-design actually avoids hidden synchronization or durability overheads under database-style access patterns.
Authors: We agree that the Evaluation section requires additional detail to substantiate the headline performance claim and to allow assessment of the design under full API workloads. In the revised manuscript we will expand the section to explicitly describe: (1) the workloads exercised, including point lookups, concurrent snapshot iteration, and multi-writer atomic batches; (2) the measurement methodology; (3) the thread counts used in each experiment; (4) error bars on all throughput figures; and (5) confirmation that the complete production API (atomic batches and snapshot-consistent iterators) was exercised. These additions will directly address the concern about potential hidden synchronization or durability overheads. revision: yes
Circularity Check
No circularity: empirical systems paper with no equations or fitted predictions
full rationale
The paper is a systems/engineering contribution whose central claims rest on empirical throughput measurements rather than any derivation chain, first-principles predictions, or fitted parameters. No equations, self-definitional constructs, or load-bearing self-citations appear in the supplied text; the 75% improvement figure is presented as an observed experimental outcome, not a quantity derived from the algorithm description itself. The concurrency-control algorithm is described at a high level without reduction to prior self-citations or ansatzes that would create circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RocksDB: A High Performance Embedded Database for Key-Value Data
2024. RocksDB: A High Performance Embedded Database for Key-Value Data. https://rocksdb.org. Official documentation. Accessed 2026
2024
-
[2]
RocksDB Wiki: Basic Operations (Snapshots)
2026. RocksDB Wiki: Basic Operations (Snapshots). https:// github.com/facebook/rocksdb/wiki/Basic-Operations. Accessed: 2026-04-20
2026
-
[3]
RocksDB Wiki: Snapshot
2026. RocksDB Wiki: Snapshot. https://github.com/facebook/ rocksdb/wiki/Snapshot. Accessed: 2026-04-20
2026
-
[4]
1999.Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions
Atul Adya. 1999.Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions. Ph.D. MIT, Cambridge, MA, USA. Also as Technical Report MIT/LCS/TR-786
1999
-
[5]
Joy Arulraj, Justin Levandoski, Umar Farooq Minhas, and Per- Ake Larson. 2018. Bztree: a high-performance latch-free range index for non-volatile memory.Proc. VLDB Endow.11, 5 (Jan. 2018), 553–565. https://doi.org/10.1145/3187009.3164147
-
[6]
Lawrence Benson, Hendrik Makait, and Tilmann Rabl. 2021. Viper: an efficient hybrid PMem-DRAM key-value store.Proc. VLDB Endow.14, 9 (May 2021), 1544–1556. https://doi.org/ 10.14778/3461535.3461543
-
[7]
Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O’Neil, and Patrick O’Neil. 1995. A critique of ANSI SQL isolation levels.SIGMOD Rec.24, 2 (May 1995), 1–10. https://doi.org/ 10.1145/568271.223785
-
[8]
Guy E Blelloch and Yuanhao Wei. 2024. Verlib: Concurrent ver- sioned pointers. InProceedings of the 29th ACM SIGPLAN An- nual Symposium on Principles and Practice of Parallel Pro- gramming. 200–214. FlintKV: A Fast Durable Storage Engine for Modern Databases
2024
-
[9]
Miao Cai, Junru Shen, Yifan Yuan, Zhihao Qu, and Baoliu Ye
-
[10]
https: //doi.org/10.14778/3636218.3636228
BonsaiKV: Towards Fast, Scalable, and Persistent Key- Value Stores with Tiered, Heterogeneous Memory System.Pro- ceedings of the VLDB Endowment17 (03 2024), 726–739. https: //doi.org/10.14778/3636218.3636228
-
[11]
Qichen Chen, Hyojeong Lee, Yoonhee Kim, Heon Young Yeom, and Yongseok Son. 2019. Design and implementation of skiplist- based key-value store on non-volatile memory.Cluster Computing 22, 2 (2019), 361–371
2019
-
[12]
Shimin Chen and Qin Jin. 2015. Persistent B+-trees in non- volatile main memory.Proc. VLDB Endow.8, 7 (Feb. 2015), 786–797. https://doi.org/10.14778/2752939.2752947
-
[13]
Youmin Chen, Youyou Lu, Fan Yang, Qing Wang, Yang Wang, and Jiwu Shu. 2020. FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persistent Memory. InProceed- ings of the Twenty-Fifth International Conference on Architec- tural Support for Programming Languages and Operating Sys- tems(Lausanne, Switzerland)(ASPLOS ’20). Association for Comp...
-
[14]
Sakib Chowdhury and Wojciech Golab. 2021. A scalable recover- able skip list for persistent memory. InProceedings of the 33rd ACM Symposium on Parallelism in Algorithms and Architec- tures. 426–428
2021
-
[15]
Sergey Egorov, Gregory Chockler, Brijesh Dongol, and Dan O’Keeffe. 2025. Fast durably linearizable data structures for free. InProceedings of the 7th Workshop on Advanced tools, program- ming languages, and PLatforms for Implementing and Evaluat- ing algorithms for Distributed systems. 40–48
2025
-
[16]
Chockler, Brijesh Dongol, Dan O’Keeffe, and Sadegh Keshavarzi
Sergey Egorov, Gregory V. Chockler, Brijesh Dongol, Dan O’Keeffe, and Sadegh Keshavarzi. 2024. Mangosteen: Fast Trans- parent Durability for Linearizable Applications using NVM. In Proceedings of the 2024 USENIX Annual Technical Confer- ence, USENIX ATC 2024, Santa Clara, CA, USA, July 10-12, 2024, Saurabh Bagchi and Yiying Zhang (Eds.). USENIX As- sociat...
2024
-
[17]
Panagiota Fatourou, Nikolaos D Kallimanis, and Eleftherios Kos- mas. 2022. The performance power of software combining in per- sistence. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 337–352
2022
-
[18]
Michal Friedman, Naama Ben-David, Yuanhao Wei, Guy E. Blel- loch, and Erez Petrank. 2020. NVTraverse: in NVRAM data structures, the destination is more important than the journey. InPLDI, Alastair F. Donaldson and Emina Torlak (Eds.). ACM, 377–392. https://doi.org/10.1145/3385412.3386031
-
[19]
Sanjay Ghemawat and Jeff Dean. 2024. LevelDB: A Fast Key- Value Storage Library. https://github.com/google/leveldb. Open source implementation with atomic batch writes, snapshots, and iterators. Accessed 2026
2024
-
[20]
Kewen He, Yujie An, Yijing Luo, Xiaoguang Liu, and Gang Wang
-
[21]
Storage19, 2, Article 19 (March 2023), 26 pages
FlatLSM: Write-Optimized LSM-Tree for PM-Based KV Stores.ACM Trans. Storage19, 2, Article 19 (March 2023), 26 pages. https://doi.org/10.1145/3579855
-
[22]
Danny Hendler, Itai Incze, Nir Shavit, and Moran Tzafrir. 2010. Flat combining and the synchronization-parallelism tradeoff. In SPAA 2010: Proceedings of the 22nd Annual ACM Sympo- sium on Parallelism in Algorithms and Architectures, Thira, Santorini, Greece, June 13-15, 2010, Friedhelm Meyer auf der Heide and Cynthia A. Phillips (Eds.). ACM, 355–364. htt...
- [23]
-
[24]
Dongxu Huang, Qi Liu, Qiu Cui, Zhaoguo Chen, Xiaoyu Liu, Feng Tian, Yu Zhou, Song Zhang, and Alvin Cheung. 2020. TiDB: A Raft-based HTAP Database.Proceedings of the VLDB Endow- ment13, 12 (2020), 3072–3084. https://www.vldb.org/pvldb/ vol13/p3072-huang.pdf
2020
-
[25]
Deukyeon Hwang, Wook-Hee Kim, Youjip Won, and Beomseok Nam. 2018. Endurable transient inconsistency in byte-addressable persistent B+-tree. InProceedings of the 16th USENIX Con- ference on File and Storage Technologies(Oakland, CA, USA) (F AST’18). USENIX Association, USA, 187–200
2018
-
[26]
Intel Corporation. 2022. pmem-rocksdb: A version of RocksDB that uses persistent memory. https://github.com/pmem/pmem- rocksdb. Accessed: [Your Access Date Here]. GitHub repository, archived
2022
-
[27]
Joseph Izraelevitz, Hammurabi Mendes, and Michael L. Scott
-
[28]
InDISC (LNCS), Cyril Gavoille and David Ilcinkas (Eds.), Vol
Linearizability of Persistent Memory Objects Under a Full- System-Crash Failure Model. InDISC (LNCS), Cyril Gavoille and David Ilcinkas (Eds.), Vol. 9888. Springer, 313–327. https: //doi.org/10.1007/978-3-662-53426-7_23
-
[29]
Noh, and Young-Ri Choi
Olzhas Kaiyrakhmet, Songyi Lee, Beomseok Nam, Sam H. Noh, and Young-Ri Choi. 2019. SLM-DB: single-level key-value store with persistent memory. InProceedings of the 17th USENIX Conference on File and Storage Technologies(Boston, MA, USA) (F AST’19). USENIX Association, USA, 191–204
2019
-
[30]
Sudarsun Kannan, Nitish Bhat, Ada Gavrilovska, Andrea Arpaci- Dusseau, and Remzi Arpaci-Dusseau. 2018. Redesigning LSMs for nonvolatile memory with NoveLSM. InProceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (Boston, MA, USA)(USENIX ATC ’18). USENIX Association, USA, 993–1005
2018
-
[31]
Artem Khyzha, Hagit Attiya, Alexey Gotsman, and Noam Rinet- zky. 2018. Safe privatization in transactional memory. InProceed- ings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming(Vienna, Austria)(PPoPP ’18). Association for Computing Machinery, New York, NY, USA, 233–245. https://doi.org/10.1145/3178487.3178505
-
[32]
Artem Khyzha and Ori Lahav. 2021. Taming x86-TSO persistency. Proc. ACM Program. Lang.5, POPL (2021), 1–29. https: //doi.org/10.1145/3434328
-
[33]
Dongui Kim, Chanyeol Park, Sang-Won Lee, and Beomseok Nam
-
[34]
InProceedings of the 21st International Middleware Conference
BoLT: Barrier-optimized LSM-tree. InProceedings of the 21st International Middleware Conference. 119–133
-
[35]
Wonbae Kim, Chanyeol Park, Dongui Kim, Hyeongjun Park, Young ri Choi, Alan Sussman, and Beomseok Nam. 2022. ListDB: Union of Write-Ahead Logs and Persistent SkipLists for Incre- mental Checkpointing on Persistent Memory. In16th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 22). USENIX Association, Carlsbad, CA, 161–177. https://w...
2022
-
[36]
Madhava Krishnan, Xinwei Fu, Sanidhya Kashyap, and Changwoo Min
Wook-Hee Kim, R. Madhava Krishnan, Xinwei Fu, Sanidhya Kashyap, and Changwoo Min. 2021. PACTree: A High Perfor- mance Persistent Range Index Using PAC Guidelines. InPro- ceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles(Virtual Event, Germany)(SOSP ’21). Asso- ciation for Computing Machinery, New York, NY, USA, 424–439. https://doi...
-
[37]
Tadeusz Kobus, Maciej Kokociński, and Paweł T Wojciechowski
-
[38]
InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming
Jiffy: A lock-free skip list with batch updates and snapshots. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 400–415
-
[39]
Cockroach Labs. 2024. Pebble: A LevelDB/RocksDB Inspired Key-Value Store. https://github.com/cockroachdb/pebble. Pro- duction key-value store with support for indexed batches, snap- shots, and iterators. Accessed 2026
2024
-
[40]
Cockroach Labs. 2025. CockroachDB Architecture: Storage Layer. https://www.cockroachlabs.com/docs/stable/architecture/ storage-layer.html. Accessed 2026
2025
-
[41]
Zhenxin Li, Bing Jiao, Shuibing He, and Weikuan Yu. 2022. Phast: Hierarchical concurrent log-free skip list for persistent memory. IEEE Transactions on Parallel and Distributed Systems33, 12 (2022), 3929–3941
2022
-
[42]
Jihang Liu, Shimin Chen, and Lujun Wang. 2020. LB+Trees: optimizing persistent index performance on 3DXPoint memory. Proc. VLDB Endow.13, 7 (March 2020), 1078–1090. https: //doi.org/10.14778/3384345.3384355
-
[43]
Sihang Liu, Korakit Seemakhupt, Yizhou Wei, Thomas Wenisch, Aasheesh Kolli, and Samira Khan. 2020. Cross-failure bug de- tection in persistent memory programs. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 1187–1202
2020
-
[44]
Sihang Liu, Yizhou Wei, Jishen Zhao, Aasheesh Kolli, and Samira Khan. 2019. PMTest: A fast and flexible testing framework for persistent memory programs. InProceedings of the Twenty- Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 411–425
2019
-
[45]
Baotong Lu, Xiangpeng Hao, Tianzheng Wang, and Eric Lo
-
[46]
VLDB Endow.13, 8 (April 2020), 1147–1161
Dash: scalable hashing on persistent memory.Proc. VLDB Endow.13, 8 (April 2020), 1147–1161. https://doi.org/10.14778/ 3389133.3389134 Sergey Egorov12, Gregory Chockler2, Brijesh Dongol2 and Dan O’Keeffe1, Sadegh Keshavarzi2
-
[47]
Ziyi Lu, Qiang Cao, Hong Jiang, Yuxing Chen, Jie Yao, and Anqun Pan. 2024. FluidKV: Seamlessly Bridging the Gap be- tween Indexing Performance and Memory-Footprint on Ultra- Fast Storage.Proc. VLDB Endow.17, 6 (Feb. 2024), 1377–1390. https://doi.org/10.14778/3648160.3648177
-
[48]
Yoshinori Matsunobu, Siying Dong, and Herman Lee. 2020. My- Rocks: LSM-tree database storage engine serving Facebook’s so- cial graph.Proc. VLDB Endow.13, 12 (Aug. 2020), 3217–3230. https://doi.org/10.14778/3415478.3415546
-
[49]
Ismail Oukid, Johan Lasperas, Anisoara Nica, Thomas Willhalm, and Wolfgang Lehner. 2016. FPTree: A Hybrid SCM-DRAM Per- sistent and Concurrent B-Tree for Storage Class Memory. InPro- ceedings of the 2016 International Conference on Management of Data(San Francisco, California, USA)(SIGMOD ’16). Asso- ciation for Computing Machinery, New York, NY, USA, 371...
-
[50]
PingCAP. 2025. TiDB Storage: Key-Value Architecture and RocksDB. https://docs.pingcap.com/tidb/stable/tidb-storage. Accessed 2026
2025
-
[51]
Azalea Raad, John Wickerson, Gil Neiger, and Viktor Vafeiadis
-
[52]
Persistency semantics of the Intel-x86 architecture.Proc. ACM Program. Lang.4, POPL (2020), 11:1–11:31. https://doi. org/10.1145/3371079
-
[53]
Matan Rusanovsky, Hagit Attiya, Ohad Ben-Baruch, Tom Gerby, Danny Hendler, and Pedro Ramalhete. 2021. Flat-Combining- Based Persistent Data Structures for Non-volatile Memory. In Stabilization, Safety, and Security of Distributed Systems - 23rd International Symposium, SSS 2021, Virtual Event, November 17-20, 2021, Proceedings (Lecture Notes in Computer S...
-
[54]
Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieskamp, Jack Szeto, Andy Pavlo, Michael Fernando, Jérôme Mazouni, Isaac Rabkin, Rae Ong, Ying Wen, Yasmin Riddick, Amelia Gaffney, Peter Mattis, Ben Creeger, and Ben Ng. 2020. CockroachDB: The Resilient Geo-Distributed SQL Database. InProceedings of the 2020 ACM SIGMOD...
-
[55]
Qing Wang, Youyou Lu, Junru Li, Minhui Xie, and Jiwu Shu
-
[56]
Nap: Persistent Memory Indexes for NUMA Architectures. ACM Trans. Storage18, 1, Article 2 (Jan. 2022), 35 pages. https: //doi.org/10.1145/3507922
-
[57]
Fei Xia, Dejun Jiang, Jin Xiong, and Ninghui Sun. 2017. HiKV: a hybrid index key-value store for DRAM-NVM memory systems. In Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference(Santa Clara, CA, USA)(USENIX ATC ’17). USENIX Association, USA, 349–362
2017
-
[58]
Renzhi Xiao, Dan Feng, Yuchong Hu, Fang Wang, Xueliang Wei, Xiaomin Zou, and Mengya Lei. 2021. Write-optimized and con- sistent skiplists for non-volatile memory.IEEE Access9 (2021), 69850–69859
2021
-
[59]
Jun Yang, Qingsong Wei, Cheng Chen, Chundong Wang, Khai Leong Yong, and Bingsheng He. 2015. NV-Tree: reducing consistency cost for NVM-based single level systems. InProceed- ings of the 13th USENIX Conference on File and Storage Tech- nologies(Santa Clara, CA)(F AST’15). USENIX Association, USA, 167–181
2015
-
[60]
Ting Yao, Yiwen Zhang, Jiguang Wan, Qiu Cui, Liu Tang, Hong Jiang, Changsheng Xie, and Xubin He. 2020. MatrixKV: reduc- ing write stalls and write amplification in LSM-tree based KV stores with a matrix container in NVM. InProceedings of the 2020 USENIX Conference on Usenix Annual Technical Confer- ence (USENIX ATC’20). USENIX Association, USA, Article 2,...
2020
-
[61]
Wenhui Zhang, Xingsheng Zhao, Song Jiang, and Hong Jiang
-
[62]
ChameleonDB: a key-value store for optane persistent memory. InProceedings of the Sixteenth European Conference on Computer Systems(Online Event, United Kingdom)(EuroSys ’21). Association for Computing Machinery, New York, NY, USA, 194–209. https://doi.org/10.1145/3447786.3456237 A LISTDB CRASH-CONSISTENCY BUG In summary, to add an entry to thedurable sta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.