ReContext: Recursive Evidence Replay as LLM Harness for Long-Context Reasoning
Pith reviewed 2026-07-03 12:54 UTC · model grok-4.3
The pith
RECONTEXT improves long-context reasoning in LLMs by recursively replaying model-selected evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
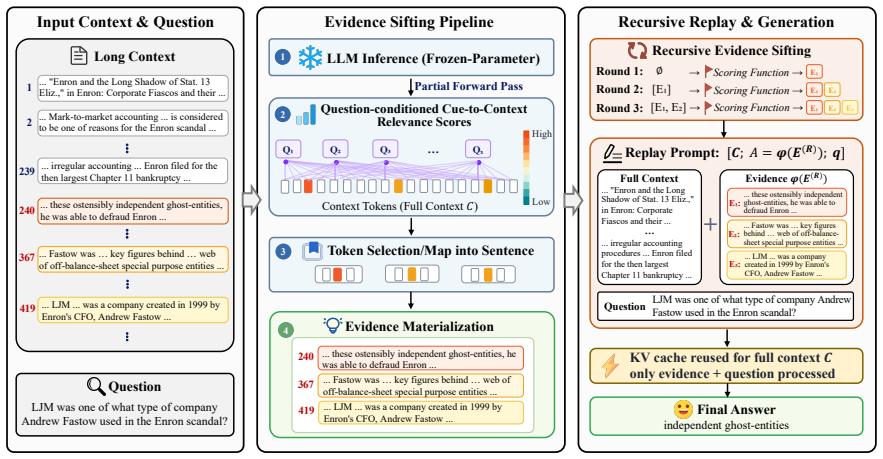
RECONTEXT uses model-internal relevance signals to construct a query-conditioned evidence pool and replays it before final generation while preserving the full original context. This recursive selection process separates evidence organization from answer generation without training, external memory, or context pruning. A theoretical analysis based on associative memory characterizes the context as a memory store, the question as a retrieval cue, attention as cue-trace association, and replay as trace reactivation.
What carries the argument
Recursive Evidence Replay, which iteratively selects relevant evidence via internal signals and replays the resulting pool to reactivate traces before answering.
Load-bearing premise
Model-internal relevance signals reliably identify useful evidence for replay without introducing systematic bias or noise that would degrade final answer quality.
What would settle it
If ablating the replay step or running the full method on the eight 128K datasets yields no improvement or worse performance than standard inference across the three tested models, the central claim would be falsified.
Figures




read the original abstract
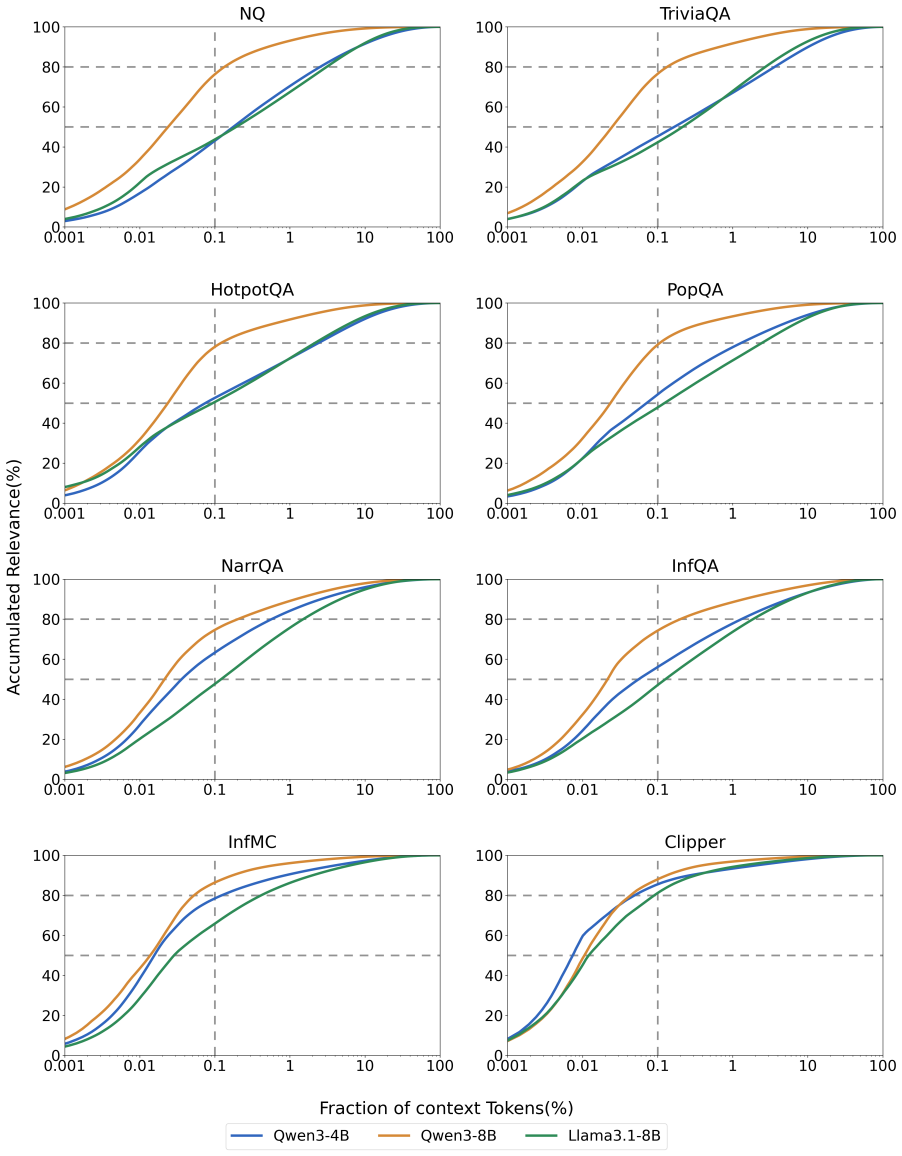
Understanding and reasoning over long contexts has become a key requirement for deploying large language models (LLMs) in realistic applications. Although recent LLMs support increasingly long context windows, they often fail to use relevant evidence that is already present in the input, revealing a gap between context access and effective context utilization. In this work, we propose Recursive Evidence Replay as LLM Harness for Long-Context Reasoning (RECONTEXT), a training-free inference method for improving long-context reasoning. RECONTEXT uses model-internal relevance signals to construct a query-conditioned evidence pool and replays it before final generation while preserving the full original context. This recursive selection process separates evidence organization from answer generation without training, external memory, or context pruning. We also provide a theoretical analysis based on associative memory, which characterizes the context as a memory store, the question as a retrieval cue, attention as cue-trace association, and replay as trace reactivation. Experiments on eight long-context datasets with 128K context length show that RECONTEXT consistently improves evidence utilization across Qwen3-4B, Qwen3-8B, and Llama3-8B, achieving the best average rank on all three backbones. Code is available at https://github.com/Yanjun-Zhao/ReContext.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RECONTEXT, a training-free inference-time technique that extracts model-internal relevance signals (e.g., attention) to build a query-conditioned evidence pool, then recursively replays selected evidence before final generation while retaining the full original 128K context. It supplies an associative-memory theoretical framing (context as memory store, question as cue, attention as association, replay as reactivation) and reports that the method yields the best average rank across eight long-context datasets on Qwen3-4B, Qwen3-8B, and Llama3-8B backbones.
Significance. If the reported rank gains prove robust and causally attributable to improved evidence utilization rather than prompt artifacts, RECONTEXT would supply a simple, zero-training harness that separates evidence organization from answer generation. The public code release is a clear strength that enables direct reproduction and extension.
major comments (2)
- [Experimental results] Experimental results (implicitly §4): the central claim that RECONTEXT improves evidence utilization rests on end-task rank improvements, yet the manuscript supplies no oracle comparison, human judgment of selected evidence quality, or ablation that replaces model-internal signals with random or position-based selection. Without such a check, gains could arise from formatting or length effects rather than better trace reactivation, directly undermining the weakest assumption identified in the stress test.
- [Theoretical analysis] Theoretical analysis section: the associative-memory framing is presented qualitatively but contains no derived quantitative prediction (e.g., expected reactivation probability or bound on noise amplification) that could be falsified by the experiments. This leaves the framing as post-hoc interpretation rather than a load-bearing justification for why recursive replay should outperform single-pass attention.
minor comments (2)
- [Abstract and Experiments] The abstract states consistent gains but the main text should explicitly report per-dataset scores, standard deviations across seeds, and statistical tests to allow readers to assess whether the best-average-rank result is driven by a few datasets.
- [Method] Implementation details on how relevance signals are extracted (specific layers, heads, aggregation method) are needed for reproducibility even with the linked code.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental results] Experimental results (implicitly §4): the central claim that RECONTEXT improves evidence utilization rests on end-task rank improvements, yet the manuscript supplies no oracle comparison, human judgment of selected evidence quality, or ablation that replaces model-internal signals with random or position-based selection. Without such a check, gains could arise from formatting or length effects rather than better trace reactivation, directly undermining the weakest assumption identified in the stress test.
Authors: We agree that the current evidence would be strengthened by explicit controls isolating the role of model-internal signals. In the revised version we will add ablations that replace the attention-derived evidence pool with (i) random selection of the same number of tokens and (ii) position-based selection (e.g., first or last k tokens). These will be run on the same eight datasets and three backbones and reported alongside the main results. We will also note the practical difficulty of obtaining a true oracle evidence set for these tasks. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section: the associative-memory framing is presented qualitatively but contains no derived quantitative prediction (e.g., expected reactivation probability or bound on noise amplification) that could be falsified by the experiments. This leaves the framing as post-hoc interpretation rather than a load-bearing justification for why recursive replay should outperform single-pass attention.
Authors: The associative-memory framing is offered as an interpretive lens that motivates the separation of evidence organization from answer generation and the use of recursive replay. We do not claim it yields falsifiable quantitative predictions in the present manuscript; the empirical results (consistent rank gains across models and datasets) serve as the primary support. We are prepared to expand the discussion section to articulate more explicit links between the reactivation hypothesis and observed behavior, but we maintain that a qualitative framing is appropriate for a training-free inference technique. revision: no
Circularity Check
No circularity; empirical inference-time method with independent benchmarks
full rationale
The paper frames RECONTEXT as a training-free method that uses model-internal relevance signals to build and replay an evidence pool while preserving full context. No equations, derivations, or fitted parameters are presented that reduce the performance claims to quantities defined by the method itself. The associative-memory framing is presented as interpretive characterization rather than a load-bearing mathematical reduction. Experiments report results on eight external long-context datasets across three model backbones, providing independent evaluation that does not collapse to self-defined inputs. No self-citation chains or uniqueness theorems are invoked to force the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
YaRN: Efficient Context Window Extension of Large Language Models
Yarn: Efficient context window extension of large language models , author=. arXiv preprint arXiv:2309.00071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2024 , eprint=
Sparse-VQ Transformer: An FFN-Free Framework with Vector Quantization for Enhanced Time Series Forecasting , author=. 2024 , eprint=
2024
-
[3]
2025 , eprint=
Does Vector Quantization Fail in Spatio-Temporal Forecasting? Exploring a Differentiable Sparse Soft-Vector Quantization Approach , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
RiskPO: Risk-based Policy Optimization via Verifiable Reward for LLM Post-Training , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
FZOO: Fast Zeroth-Order Optimizer for Fine-Tuning Large Language Models towards Adam-Scale Speed , author=. 2025 , eprint=
2025
-
[6]
2026 , eprint=
Agentic Reasoning for Large Language Models , author=. 2026 , eprint=
2026
-
[7]
2025 , eprint=
Second-Order Fine-Tuning without Pain for LLMs:A Hessian Informed Zeroth-Order Optimizer , author=. 2025 , eprint=
2025
-
[8]
2024 , eprint=
Less is more: Embracing sparsity and interpolation with Esiformer for time series forecasting , author=. 2024 , eprint=
2024
-
[9]
2026 , eprint=
Code as Agent Harness , author=. 2026 , eprint=
2026
-
[10]
2023 , eprint=
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time , author=. 2023 , eprint=
2023
-
[11]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[12]
2025 , eprint=
Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference , author=. 2025 , eprint=
2025
-
[13]
2026 , eprint=
Mem-Gallery: Benchmarking Multimodal Long-Term Conversational Memory for MLLM Agents , author=. 2026 , eprint=
2026
-
[14]
2025 , eprint=
Modern Methods in Associative Memory , author=. 2025 , eprint=
2025
-
[15]
2021 , eprint=
Hopfield Networks is All You Need , author=. 2021 , eprint=
2021
-
[16]
2024 , eprint=
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference , author=. 2024 , eprint=
2024
-
[17]
2025 , eprint=
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
SnapKV: LLM Knows What You are Looking for Before Generation , author=. 2024 , eprint=
2024
-
[19]
2023 , eprint=
H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. 2023 , eprint=
2023
-
[20]
2024 , eprint=
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression , author=. 2024 , eprint=
2024
-
[21]
2023 , eprint=
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models , author=. 2023 , eprint=
2023
-
[22]
2023 , eprint=
Compressing Context to Enhance Inference Efficiency of Large Language Models , author=. 2023 , eprint=
2023
-
[23]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[24]
2023 , eprint=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
2023
-
[25]
2025 , eprint=
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
Bench: Extending Long Context Evaluation Beyond 100K Tokens , author=. 2024 , eprint=
2024
-
[28]
2023 , eprint=
L-Eval: Instituting Standardized Evaluation for Long Context Language Models , author=. 2023 , eprint=
2023
-
[29]
2023 , eprint=
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding , author=. 2023 , eprint=
2023
-
[30]
2024 , eprint=
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. 2024 , eprint=
2024
-
[31]
2024 , eprint=
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens , author=. 2024 , eprint=
2024
-
[32]
2024 , eprint=
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models , author=. 2024 , eprint=
2024
-
[33]
2023 , eprint=
LongNet: Scaling Transformers to 1,000,000,000 Tokens , author=. 2023 , eprint=
2023
-
[34]
2025 , eprint=
CLIPPER: Compression Enables Long-Context Synthetic Data Generation , author=. 2025 , eprint=
2025
-
[35]
2026 , eprint=
DySCO: Dynamic Attention-Scaling Decoding for Long-Context Language Models , author=. 2026 , eprint=
2026
-
[36]
2025 , eprint=
A-MEM: Agentic Memory for LLM Agents , author=. 2025 , eprint=
2025
-
[37]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
DAC: A Dynamic Attention-aware Approach for Task-Agnostic Prompt Compression , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , url=
2025
-
[38]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
SelfElicit: Your language model secretly knows where is the relevant evidence , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , organization=
2025
-
[39]
2026 , eprint=
PaperMind: Benchmarking Agentic Reasoning and Critique over Scientific Papers in Multimodal LLMs , author=. 2026 , eprint=
2026
-
[40]
2025 , eprint=
SABER: Switchable and Balanced Training for Efficient LLM Reasoning , author=. 2025 , eprint=
2025
-
[41]
Zhao, Yanjun and Ma, Ziqing` and Zhou, Tian and Ye, Mengni and Sun, Liang and Qian, Yi , title =. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management , pages =. 2023 , isbn =. doi:10.1145/3583780.3615136 , abstract =
-
[42]
Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[43]
Advances in Neural Information Processing Systems , volume=
Big Bird: Transformers for Longer Sequences , author=. Advances in Neural Information Processing Systems , volume=. 2020 , url=
2020
-
[44]
Proceedings of the 39th International Conference on Machine Learning , pages=
Improving Language Models by Retrieving from Trillions of Tokens , author=. Proceedings of the 39th International Conference on Machine Learning , pages=. 2022 , url=
2022
-
[45]
Proceedings of the National Academy of Sciences , volume=
Neural Networks and Physical Systems with Emergent Collective Computational Abilities , author=. Proceedings of the National Academy of Sciences , volume=. 1982 , doi=
1982
-
[46]
Advances in Neural Information Processing Systems , volume=
Dense Associative Memory for Pattern Recognition , author=. Advances in Neural Information Processing Systems , volume=. 2016 , url=
2016
-
[47]
International Conference on Learning Representations , year=
Memory Networks , author=. International Conference on Learning Representations , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
End-To-End Memory Networks , author=. Advances in Neural Information Processing Systems , volume=. 2015 , url=
2015
-
[49]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
Key-Value Memory Networks for Directly Reading Documents , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=. 2016 , publisher=
2016
-
[50]
Advances in Neural Information Processing Systems , volume=
Attention Approximates Sparse Distributed Memory , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[51]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=. 2021 , publisher=
2021
-
[52]
International Conference on Learning Representations , volume=
Understanding factual recall in transformers via associative memories , author=. International Conference on Learning Representations , volume=
-
[53]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.