Step-TP: A Grounded, Step-Level Dataset with Chain-of-Thought Reasoning for LLM-Guided Tensor Program Optimization
Pith reviewed 2026-06-29 23:14 UTC · model grok-4.3
The pith
Step-TP supplies step-level chain-of-thought supervision so language models can learn reliable single-step tensor program transformations instead of copying final outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
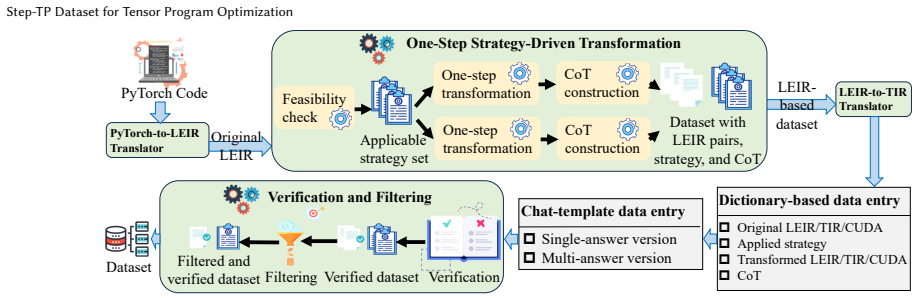
Step-TP forms a closed reasoning loop over intermediate program states, enabling reliable multi-step optimization rather than outcome imitation, through a token-efficient verifiable IR, atomic composable strategies, structured CoT supervision with explicit IR-to-IR transitions, and strategy filtering.
What carries the argument
The closed reasoning loop that couples atomic optimization strategies with structured CoT traces and deterministic IR-to-IR state transitions.
If this is right
- Models trained on Step-TP can generate interpretable single-step decisions that compose into longer trajectories.
- The token-efficient IR reduces context length while remaining verifiable against TVM TIR.
- Strategy filtering prevents the model from learning to skip hard steps while still covering diverse optimization paths.
- The dataset supports iterative refinement because each step is paired with an explicit state change and reasoning trace.
Where Pith is reading between the lines
- If the loop works, it may generalize to other compiler or hardware-mapping tasks that currently rely on end-to-end imitation.
- The same atomic-strategy design could be applied to search spaces in scheduling or memory layout where combinatorial explosion is the main barrier.
- Testing whether the filtered dataset still covers rare but high-value transformations would be a direct next measurement.
Load-bearing premise
Atomic and composable optimization strategies paired with the chosen IR and filtering will produce training signals that let models make reliable single-step decisions without exploiting shortcuts or losing coverage.
What would settle it
An LLM trained on Step-TP is evaluated on held-out optimization trajectories; if it consistently fails to reach competitive performance on programs that require more than three steps or exhibits the same shortcut patterns seen in outcome-imitation baselines, the claim is falsified.
Figures



read the original abstract
Despite the strong reasoning capabilities of large language models (LLMs), optimizing the execution efficiency of tensor programs remains challenging due to the need for precise, composable transformation decisions. Recent LLM-guided approaches frame tensor program optimization as an iterative decision process, but existing datasets provide only end-to-end optimized program pairs using token-inefficient representations, lacking verifiable step-level supervision and interpretability. As a result, LLMs struggle to make reliable single-step decisions in large combinatorial optimization spaces. We introduce Step-TP, a post-training dataset for tensor program optimization that provides grounded, atomic, step-level supervision with structured chain-of-thought (CoT) reasoning. Step-TP forms a closed reasoning loop over intermediate program states, enabling reliable multi-step optimization rather than outcome imitation. Its design is guided by four principles: (i) a token-efficient, verifiable intermediate representation (IR) that deterministically lowers to TVM TIR; (ii) atomic and composable optimization strategies that decompose complex trajectories into interpretable single-step decisions; (iii) structured CoT supervision coupled with explicit IR-to-IR state transitions; and (iv) strategy filtering to balance coverage while preventing shortcut exploitation. The dataset and implementation are available at a GitHub link, https://github.com/LIUMENGFAN-gif/StepTP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Step-TP, a post-training dataset for tensor program optimization. It supplies grounded, atomic, step-level supervision with structured chain-of-thought reasoning over intermediate program states. The dataset is constructed according to four design principles: a token-efficient verifiable IR that deterministically lowers to TVM TIR, atomic and composable optimization strategies, explicit IR-to-IR state transitions paired with CoT, and strategy filtering to balance coverage while avoiding shortcut exploitation. The central claim is that this construction forms a closed reasoning loop enabling reliable multi-step LLM-guided optimization rather than end-to-end outcome imitation.
Significance. If the described construction is sound and the released implementation functions as stated, Step-TP would constitute a useful addition to the resources available for LLM-guided program optimization. It directly targets the gap between existing end-to-end program-pair datasets and the need for interpretable, verifiable step-level signals in a combinatorial domain. The public release of both the dataset and the implementation code is a concrete strength for reproducibility.
major comments (2)
- [Abstract / design principles] Abstract (design principles section): the claim that the chosen IR 'deterministically lowers to TVM TIR' and thereby supplies 'verifiable supervision' is load-bearing for the entire contribution, yet the manuscript provides no verification, error rates, sample lowering traces, or correctness checks on the lowering procedure. Without such evidence the 'verifiable' property remains an untested assertion.
- [Abstract / design principles] Abstract (design principles section): the assertion that 'strategy filtering' simultaneously achieves coverage and prevents shortcut exploitation is central to the claim of reliable single-step decisions, but no coverage metrics, filtering statistics, or concrete examples of filtered versus retained trajectories are supplied to substantiate the balance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments identifying two areas where the manuscript lacks supporting evidence for central claims. We agree with both points and will revise the paper to supply the requested verification, metrics, and examples. This addresses the major revision recommendation.
read point-by-point responses
-
Referee: [Abstract / design principles] Abstract (design principles section): the claim that the chosen IR 'deterministically lowers to TVM TIR' and thereby supplies 'verifiable supervision' is load-bearing for the entire contribution, yet the manuscript provides no verification, error rates, sample lowering traces, or correctness checks on the lowering procedure. Without such evidence the 'verifiable' property remains an untested assertion.
Authors: We agree that the manuscript currently provides no explicit verification of the lowering procedure, error rates, or sample traces. This is a substantive gap given the centrality of the 'verifiable supervision' claim. In the revised version we will add: (1) sample IR-to-TVM-TIR lowering traces, (2) quantitative error rates from validation runs on held-out programs, and (3) a description of the automated correctness checks performed during dataset generation. revision: yes
-
Referee: [Abstract / design principles] Abstract (design principles section): the assertion that 'strategy filtering' simultaneously achieves coverage and prevents shortcut exploitation is central to the claim of reliable single-step decisions, but no coverage metrics, filtering statistics, or concrete examples of filtered versus retained trajectories are supplied to substantiate the balance.
Authors: We acknowledge the absence of coverage metrics, filtering statistics, and concrete examples in the current manuscript. The revision will incorporate: (1) coverage metrics showing strategy distribution before and after filtering, (2) filtering statistics (e.g., fraction of trajectories removed and primary removal criteria), and (3) side-by-side examples of filtered versus retained trajectories to illustrate how the procedure balances coverage against shortcut prevention. revision: yes
Circularity Check
No significant circularity; dataset construction paper with no derivations or self-referential predictions
full rationale
The paper introduces a new dataset (Step-TP) for LLM-guided tensor program optimization, guided by four explicit design principles for IR, atomic strategies, CoT supervision, and filtering. No mathematical derivations, equations, fitted parameters, or predictions are present in the abstract or described contribution. The central claim is the creation and release of step-level training data rather than any result that reduces to prior fitted values or self-citations by construction. This matches the default expectation for non-circular dataset papers; the reader's assessment of score 1.0 is consistent with minor self-citation tolerance but no load-bearing circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al
-
[2]
In12th USENIX symposium on operating systems design and implementation (OSDI 16)
{TensorFlow}: a system for {Large-Scale} machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16). 265–283
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Riyadh Baghdadi, Jessica Ray, Malek Ben Romdhane, Emanuele Del Sozzo, Ab- durrahman Akkas, Yunming Zhang, Patricia Suriana, Shoaib Kamil, and Saman Amarasinghe. 2019. Tiramisu: A polyhedral compiler for expressing fast and portable code. In2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 193–205
2019
-
[5]
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti
- [6]
-
[7]
Tyler A Chang and Benjamin K Bergen. 2024. Language model behavior: A comprehensive survey.Computational Linguistics50, 1 (2024), 293–350
2024
-
[8]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). 578–594
2018
-
[9]
Tianqi Chen, Lianmin Zheng, Eddie Yan, Ziheng Jiang, Thierry Moreau, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. Learning to optimize tensor programs.Advances in Neural Information Processing Systems31 (2018)
2018
- [10]
- [11]
-
[12]
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
- [14]
-
[15]
Jingzhi Fang, Yanyan Shen, Yue Wang, and Lei Chen. 2021. ETO: Accelerating optimization of DNN operators by high-performance tensor program reuse. Proceedings of the VLDB Endowment15, 2 (2021), 183–195
2021
-
[16]
Pratik Fegade, Tianqi Chen, Phillip B Gibbons, and Todd C Mowry. 2024. AC- RoBat: Optimizing auto-batching of dynamic deep learning at compile time. Proceedings of Machine Learning and Systems6 (2024), 14–30
2024
-
[17]
Siyuan Feng, Bohan Hou, Hongyi Jin, Wuwei Lin, Junru Shao, Ruihang Lai, Zihao Ye, Lianmin Zheng, Cody Hao Yu, Yong Yu, et al. 2023. Tensorir: An abstraction for automatic tensorized program optimization. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 804–817. Mengf...
2023
- [18]
-
[19]
Hanpeng Hu, Junwei Su, Juntao Zhao, Yanghua Peng, Yibo Zhu, Haibin Lin, and Chuan Wu. 2024. CDMPP: A device-model agnostic framework for latency pre- diction of tensor programs. InProceedings of the Nineteenth European Conference on Computer Systems. 1054–1074
2024
-
[20]
Zhihao Jia, Oded Padon, James Thomas, Todd Warszawski, Matei Zaharia, and Alex Aiken. 2019. TASO: optimizing deep learning computation with automatic generation of graph substitutions. InProceedings of the 27th ACM Symposium on Operating Systems Principles. 47–62
2019
-
[21]
Zhihao Jia, James Thomas, Todd Warszawski, Mingyu Gao, Matei Zaharia, and Alex Aiken. 2019. Optimizing DNN computation with relaxed graph substitutions. Proceedings of Machine Learning and Systems1 (2019), 27–39
2019
-
[22]
Hyeonjin Kim, Sungwoo Ahn, Yunho Oh, Bogil Kim, Won Woo Ro, and William J Song. 2020. Duplo: Lifting redundant memory accesses of deep neural networks for gpu tensor cores. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 725–737
2020
- [23]
-
[24]
Ao Li, Bojian Zheng, Gennady Pekhimenko, and Fan Long. 2022. Automatic horizontal fusion for GPU kernels. In2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 14–27
2022
- [25]
- [26]
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mengfan Liu, Wei Wang, and Chuan Wu. 2025. Optimizing distributed deploy- ment of mixture-of-experts model inference in serverless computing. InIeee infocom 2025-ieee conference on computer communications. IEEE, 1–10
2025
-
[29]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
- [30]
-
[31]
Maxim Milakov and Natalia Gimelshein. 2018. Online normalizer calculation for softmax.arXiv preprint arXiv:1805.02867(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs write efficient GPU kernels?, 2025.URL https://arxiv. or g/abs/2502.10517(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Mangpo Phothilimthana, Sami Abu-El-Haija, Kaidi Cao, Bahare Fatemi, Michael Burrows, Charith Mendis, and Bryan Perozzi. 2023. Tpugraphs: A performance prediction dataset on large tensor computational graphs.Advances in Neural Information Processing Systems36 (2023), 70355–70375
2023
-
[34]
Guicheng Qi, Junwei Su, Liqi Yang, Tao Li, Tingwen Xie, Yerui Sun, Yuchen Xie, and Chuan Wu. 2026. HetAuto: Cross-Cluster Auto-Parallelism for Heteroge- neous Distributed Training. InProceedings of the 21st European Conference on Computer Systems. 759–779
2026
- [35]
- [36]
-
[37]
Annabelle Sujun Tang, Christopher Priebe, Rohan Mahapatra, Lianhui Qin, and Hadi Esmaeilzadeh. 2025. REASONING COMPILER: LLM-Guided Optimizations for Efficient Model Serving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[38]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Pro- gramming Languages. 10–19
2019
-
[39]
Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. 2018. Tensor comprehensions: Framework-agnostic high-performance machine learning abstractions.arXiv preprint arXiv:1802.04730(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Vasily Volkov and James W Demmel. 2008. Benchmarking GPUs to tune dense linear algebra. InSC’08: Proceedings of the 2008 ACM/IEEE conference on Super- computing. IEEE, 1–11
2008
-
[41]
Haojie Wang, Jidong Zhai, Mingyu Gao, Zixuan Ma, Shizhi Tang, Liyan Zheng, Yuanzhi Li, Kaiyuan Rong, Yuanyong Chen, and Zhihao Jia. 2021. {PET}: Opti- mizing tensor programs with partially equivalent transformations and automated corrections. In15th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 21). 37–54
2021
- [42]
-
[43]
Lei Wang, Lingxiao Ma, Shijie Cao, Quanlu Zhang, Jilong Xue, Yining Shi, Ningxin Zheng, Ziming Miao, Fan Yang, Ting Cao, et al. 2024. Ladder: Enabling efficient {Low-Precision} deep learning computing through hardware-aware tensor transformation. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 307–323
2024
- [44]
-
[45]
Jiin Woo, Shaowei Zhu, Allen Nie, Zhen Jia, Yida Wang, and Youngsuk Park
- [46]
-
[47]
Mengdi Wu, Xinhao Cheng, Shengyu Liu, Chunan Shi, Jianan Ji, Man Kit Ao, Praveen Velliengiri, Xupeng Miao, Oded Padon, and Zhihao Jia. 2025. Mirage: A {Multi-Level} superoptimizer for tensor programs. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). 21–38
2025
-
[48]
Haofeng Xu, Junwei Su, Yukun Tian, Lansong Diao, Zhengping Qian, and Chuan Wu. 2026. GAC: Stabilizing Asynchronous RL Training for LLMs via Gradient Alignment Control.arXiv preprint arXiv:2603.01501(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Zi Yang, Lei Qiu, Fang Lyu, Ming Zhong, Zhilei Chai, Haojie Zhou, Huimin Cui, and Xiaobing Feng. [n. d.]. IR-OptSet: An Optimization-Sensitive Dataset for Advancing LLM-Based IR Optimizer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[50]
Yi Zhai, Sijia Yang, Keyu Pan, Renwei Zhang, Shuo Liu, Chao Liu, Zichun Ye, Jianmin Ji, Jie Zhao, Yu Zhang, et al. 2024. Enabling Tensor Language Model to Assist in Generating {High-Performance} Tensor Programs for Deep Learning. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 289–305
2024
-
[51]
Yi Zhai, Yu Zhang, Shuo Liu, Xiaomeng Chu, Jie Peng, Jianmin Ji, and Yanyong Zhang. 2023. Tlp: A deep learning-based cost model for tensor program tuning. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 833–845
2023
-
[52]
Jie Zhao, Xiong Gao, Ruijie Xia, Zhaochuang Zhang, Deshi Chen, Lei Chen, Renwei Zhang, Zhen Geng, Bin Cheng, and Xuefeng Jin. 2022. Apollo: Automatic partition-based operator fusion through layer by layer optimization.Proceedings of Machine Learning and Systems4 (2022), 1–19
2022
-
[53]
Jie Zhao, Bojie Li, Wang Nie, Zhen Geng, Renwei Zhang, Xiong Gao, Bin Cheng, Chen Wu, Yun Cheng, Zheng Li, et al. 2021. AKG: automatic kernel generation for neural processing units using polyhedral transformations. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. 1233–1248
2021
-
[54]
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, et al. 2020. Ansor: Generating {High-Performance} tensor programs for deep learning. In14th USENIX symposium on operating systems design and implementation (OSDI 20). 863–879
2020
-
[55]
Lianmin Zheng, Ruochen Liu, Junru Shao, Tianqi Chen, Joseph E Gonzalez, Ion Stoica, and Ameer Haj Ali. 2021. Tenset: A large-scale program performance dataset for learned tensor compilers. InThirty-fifth Conference on Neural Infor- mation Processing Systems Datasets and Benchmarks Track (Round 1)
2021
-
[56]
Liyan Zheng, Haojie Wang, Jidong Zhai, Muyan Hu, Zixuan Ma, Tuowei Wang, Shuhong Huang, Xupeng Miao, Shizhi Tang, Kezhao Huang, et al. 2023. {EINNET}: Optimizing tensor programs with{Derivation-Based}transforma- tions. In17th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 23). 739–755
2023
-
[57]
Size Zheng, Siyuan Chen, Siyuan Gao, Liancheng Jia, Guangyu Sun, Runsheng Wang, and Yun Liang. 2023. Tileflow: A framework for modeling fusion dataflow via tree-based analysis. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 1271–1288
2023
-
[58]
Yuchen Zhong, Junwei Su, Chuan Wu, and Minjie Wang. 2025. Heta: Distributed Training of Heterogeneous Graph Neural Networks.Proceedings of the VLDB Endowment18, 9 (2025), 2790–2803
2025
-
[59]
Hongyu Zhu, Ruofan Wu, Yijia Diao, Shanbin Ke, Haoyu Li, Chen Zhang, Jilong Xue, Lingxiao Ma, Yuqing Xia, Wei Cui, et al. 2022. {ROLLER}: Fast and efficient tensor compilation for deep learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 233–248. Step-TP Dataset for Tensor Program Optimization A Intermediate represen...
2022
-
[60]
For each new optimization, you MUST build it ON TOP OF these existing changes, namely ON TOP OF the current IR
Before you suggest each new transformation, you MUST iden- tify what has been changed in the current IR compared to the root IR. For each new optimization, you MUST build it ON TOP OF these existing changes, namely ON TOP OF the current IR. The strategies MUST be used on the current IR! You MUST compare your modi- fied parts in each transformed IR with th...
1930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.