Scaling Laws for Grid-Based Approximate Nearest Neighbor Search in High Dimensions
Pith reviewed 2026-07-03 21:35 UTC · model grok-4.3
The pith
Multiprobe grid search maintains constant dimensional scaling on GloVe while other ANN methods degrade.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
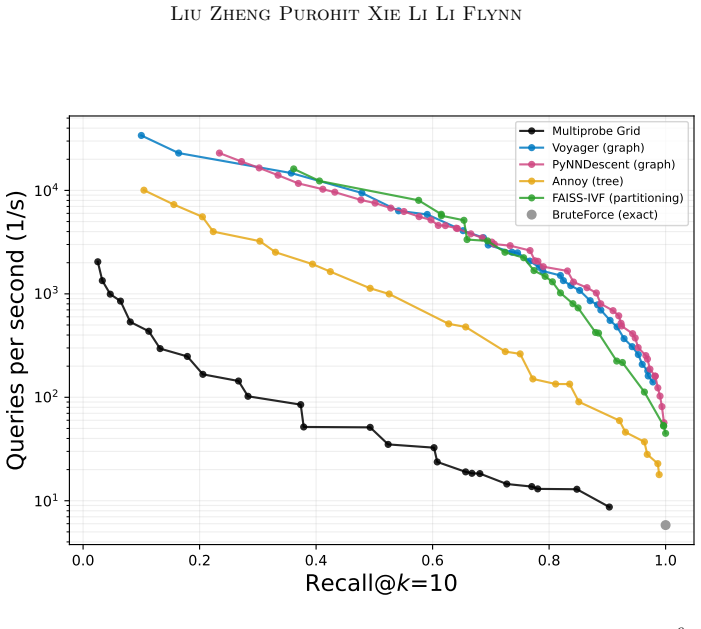
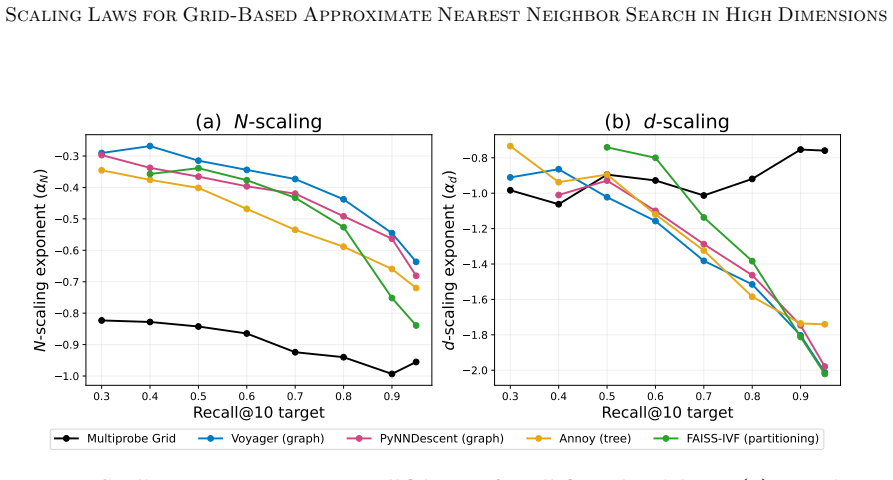
On the GloVe embedding family, multiprobe grid search maintains an approximately constant dimensional scaling exponent while other graph-, tree-, and partitioning-based methods exhibit degrading throughput. The advantage comes with near-linear query scaling in N, but also with lower indexing cost than competing ANN methods. The results suggest grid-based methods may be competitive in rebuild-heavy or high-dimensional settings where indexing cost and dimensional robustness dictate performance.
What carries the argument
multiprobe grid algorithm
If this is right
- Grid methods remain competitive when indexing cost or frequent rebuilds dominate the workload.
- Near-linear scaling in N makes the approach viable for growing datasets.
- ANN scaling behavior can inform cost models for transformer architectures that treat self-attention as an ANN operation.
Where Pith is reading between the lines
- If the constant dimensional exponent generalizes beyond GloVe, grid methods could become default choices for embedding spaces whose dimensionality continues to increase.
- The explicit link to self-attention suggests testing whether a grid-based attention variant would inherit the same scaling advantages.
- Direct head-to-head rebuild-cost measurements on non-GloVe data would clarify whether the indexing advantage survives outside the reported setting.
Load-bearing premise
The multiprobe grid implementation and the specific GloVe subsets used are representative of the general behavior of grid-based ANN versus competing methods across high-dimensional regimes.
What would settle it
If multiprobe grid search on a different high-dimensional embedding family shows the same degrading throughput exponent as graph and tree methods, the reported dimensional robustness would not hold.
Figures
read the original abstract
Grid-based approaches to approximate nearest neighbor (ANN) search have been absent from modern scaling analyses. We present a systematic characterization of a multiprobe grid algorithm with respect to dataset size $N$ and dimensionality $d$. Our experiments reveal a previously unreported $d$-scaling crossover on the GloVe embedding family, in which multiprobe grid search maintains an approximately constant dimensional scaling exponent while other graph-, tree-, and partitioning-based methods exhibit degrading throughput. The advantage comes with near-linear query scaling in $N$, but also with lower indexing cost than competing ANN methods. Our results suggest that grid-based methods such as multiprobe grid may be competitive in rebuild-heavy or high-dimensional settings where indexing cost and dimensional robustness dictate performance. More broadly, recent work has formalized self-attention as an ANN operation. Thus, the $N$- and $d$-scaling properties of ANN algorithms may guide cost analysis of efficient transformer architectures. Code is available at: https://github.com/weiz345/MultiProbeANN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical scaling study of a multiprobe grid algorithm for approximate nearest neighbor (ANN) search. It characterizes query throughput and indexing cost as functions of dataset size N and dimensionality d on the GloVe embedding family, reporting that multiprobe grid maintains an approximately constant d-scaling exponent while graph-, tree-, and partitioning-based methods show degradation. The grid approach exhibits near-linear scaling in N together with lower indexing cost; the authors suggest applicability to rebuild-heavy or high-d regimes and note a possible connection to cost modeling of self-attention in transformers. Reproducible code is provided.
Significance. If the reported d-scaling crossover is borne out by the experiments, the work supplies a concrete empirical observation that grid-based ANN can exhibit dimensional robustness not shared by the dominant contemporary families. The explicit release of code is a clear strength that supports verification and extension. The suggested link to transformer architectures is plausible but remains high-level.
minor comments (3)
- [Abstract] Abstract: the statement that multiprobe grid 'maintains an approximately constant dimensional scaling exponent' would be strengthened by reporting the fitted exponent value and its uncertainty (or at least the range of d examined).
- The manuscript would benefit from an explicit table or figure panel that tabulates the measured N- and d-scaling exponents (with confidence intervals) for all compared methods on each GloVe subset.
- Clarify the precise multiprobe parameters (number of probes, grid resolution) and the exact GloVe subset sizes used for each scaling curve; these details are load-bearing for reproducing the reported crossover.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our empirical scaling study and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; purely empirical scaling study
full rationale
The paper is an empirical scaling study that reports experimental measurements of query throughput versus N and d on the GloVe embedding family for multiprobe grid search versus other ANN methods. No derivations, first-principles results, fitted parameters presented as predictions, or self-citation load-bearing steps are present in the abstract or described claims. The central observation (constant d-scaling exponent for grid search) is a direct experimental finding, not reduced to any input by construction, and the work supplies code for reproduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fast attention mechanisms: a tale of parallelism , shorttitle =
Liu, Jingwen and Yu, Hantao and Sanford, Clayton and Andoni, Alexandr and Hsu, Daniel , month = sep, year =. Fast attention mechanisms: a tale of parallelism , shorttitle =. doi:10.48550/arXiv.2509.09001 , abstract =
-
[2]
Scaling Laws for Neural Language Models
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B. and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , month = jan, year =. Scaling. doi:10.48550/arXiv.2001.08361 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[3]
Nearest-neighbor methods in learning and vision: theory and practice , isbn =
-
[4]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Efficient and. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2020 , pages =. doi:10.1109/TPAMI.2018.2889473 , abstract =
-
[5]
Approximate nearest neighbors: towards removing the curse of dimensionality , copyright =
Indyk, Piotr and Motwani, Rajeev , year =. Approximate nearest neighbors: towards removing the curse of dimensionality , copyright =. Proceedings of the thirtieth annual. doi:10.1145/276698.276876 , abstract =
-
[6]
Journal of the ACM , author =
An. Journal of the ACM , author =. 1998 , pages =
1998
-
[7]
Communications of the ACM , author =
Multidimensional binary search trees used for associative searching , volume =. Communications of the ACM , author =. 1975 , pages =. doi:10.1145/361002.361007 , abstract =
-
[8]
Silpa-Anan, Chanop and Hartley, Richard , month = jun, year =. Optimised. 2008. doi:10.1109/CVPR.2008.4587638 , abstract =
-
[9]
Jafari, Omid and Nagarkar, Parth , year =. Experimental. doi:10.1007/978-3-030-69377-0_6 , abstract =
-
[10]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Product. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2011 , pages =. doi:10.1109/TPAMI.2010.57 , abstract =
-
[11]
Proceedings of the 25th VLDB Conference , author =
Similarity. Proceedings of the 25th VLDB Conference , author =
-
[12]
Datar, Mayur and Immorlica, Nicole and Indyk, Piotr and Mirrokni, Vahab S. , month = jun, year =. Locality-sensitive hashing scheme based on p-stable distributions , isbn =. Proceedings of the twentieth annual symposium on. doi:10.1145/997817.997857 , abstract =
-
[13]
Pennington, Jeffrey and Socher, Richard and Manning, Christopher , year =. Glove:. Proceedings of the 2014. doi:10.3115/v1/D14-1162 , abstract =
-
[14]
2026 , note =
facebookresearch/faiss , copyright =. 2026 , note =
2026
-
[15]
lmcinnes/pynndescent , copyright =
McInnes, Leland , month = apr, year =. lmcinnes/pynndescent , copyright =
-
[16]
2026 , note =
spotify/annoy , copyright =. 2026 , note =
2026
-
[17]
2026 , note =
spotify/voyager , copyright =. 2026 , note =
2026
-
[18]
Reproducibility protocol for
Aumüller, Martin and Bernhardsson, Erik and Faithfull, Alexander , year =. Reproducibility protocol for
-
[19]
Proceedings of the 1st Workshop on Vector Databases at International Conference on Machine Learning , author =
Scaling. Proceedings of the 1st Workshop on Vector Databases at International Conference on Machine Learning , author =
-
[20]
The Thirteenth International Conference on Learning Representations , author =
-
[21]
Information Systems , author =. 2020 , pages =. doi:10.1016/j.is.2019.02.006 , abstract =
-
[22]
Proceedings of the thirteenth annual symposium on Computational Geometry (SoCG 1997) , author =
Approximate. Proceedings of the thirteenth annual symposium on Computational Geometry (SoCG 1997) , author =. doi:https://doi.org/10.1145/262839.263001 , language =
-
[23]
Unifying Convolution and Attention via Convolutional Nearest Neighbors
Kang, Mingi and Neto, Jeová Farias Sales Rocha , month = nov, year =. Attention. doi:10.48550/arXiv.2511.14137 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.14137
-
[24]
Iff, Patrick and Bruegger, Paul and Chrapek, Marcin and Kochergin, David and Besta, Maciej and Hoefler, Torsten , month = apr, year =. Benchmarking. doi:10.48550/arXiv.2507.21989 , abstract =
-
[25]
Xiao, Wentao and Zhan, Yueyang and Xi, Rui and Hou, Mengshu and Liao, Jianming , month = jul, year =. Enhancing. doi:10.48550/arXiv.2407.07871 , abstract =
-
[26]
Advances in
Jayaram Subramanya, Suhas and Devvrit, Fnu and Simhadri, Harsha Vardhan and Krishnawamy, Ravishankar and Kadekodi, Rohan , year =. Advances in
-
[27]
Cooper, Morgan Roy and Busch, Mike , month = feb, year =. Capacity-. Journal of Imaging , publisher =. doi:10.3390/jimaging12020055 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.