When Agents Do Not Stop: Uncovering Infinite Agentic Loops in LLM Agents
Pith reviewed 2026-07-03 09:12 UTC · model grok-4.3
The pith
Infinite agentic loops arise in LLM agents when feedback paths lack effective bounds, and static analysis can detect them in real projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Infinite Agentic Loops are not ordinary programming loops but arise from the interaction between agent logic, framework semantics, runtime observations, and termination mechanisms. IAL-Scan abstracts heterogeneous agent code into a framework-independent Agent IR, builds an Agentic Loop Dependence Graph to recover explicit and framework-induced feedback paths, and checks whether these paths can repeatedly reach costly or state-growing operations without an effective bound. Evaluated on 6,549 LLM agent repositories, the tool reports 74 potential findings, 68 of which manual review confirms as IAL failures across 47 projects at 91.9 percent precision.
What carries the argument
The Agentic Loop Dependence Graph, which recovers both explicit and framework-induced feedback paths and checks them for repeated reachability to costly operations.
If this is right
- Agents containing such loops can turn a single user request into unbounded model and tool executions.
- Cost exhaustion, context-length growth, and repeated external actions become direct consequences of missing bounds.
- Static detection before deployment can surface these issues across large collections of agent repositories.
- Framework designers gain a concrete target for adding termination checks that the analysis can verify.
Where Pith is reading between the lines
- The same pattern of unbounded feedback could appear in non-LLM autonomous systems that combine planning with external actions.
- Runtime instrumentation that logs actual iteration counts could serve as an independent check on the static flags.
- Agent frameworks might benefit from built-in default bounds on iteration depth that the analysis could then validate.
Load-bearing premise
The static abstractions in the tool accurately represent the runtime feedback paths that actually occur, and the manual review of flagged cases correctly separates true infinite loops from bounded iterations.
What would settle it
Selecting one of the 47 projects flagged by the tool, executing its agent on the original task, and observing whether execution actually continues without bound or eventually terminates would confirm or refute the reported failures.
Figures

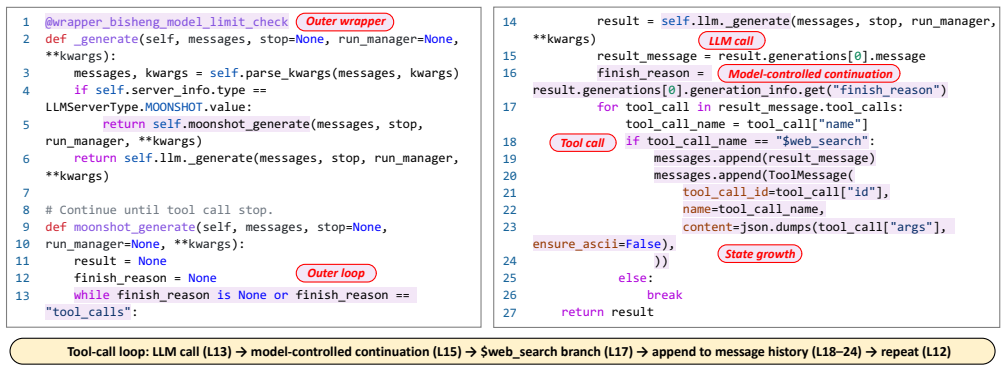
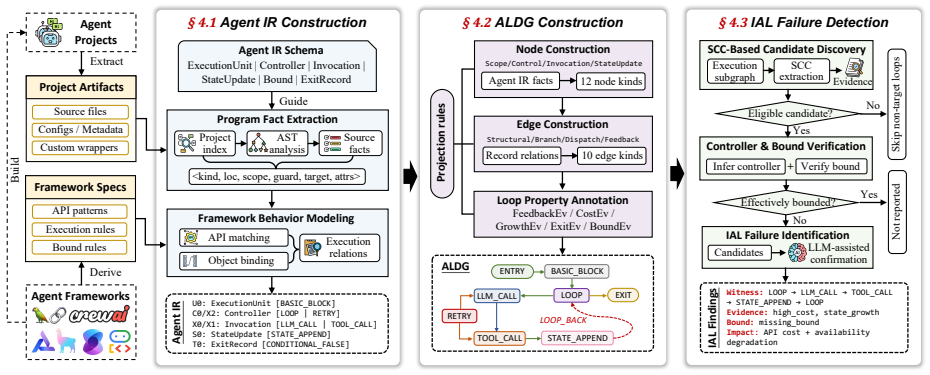

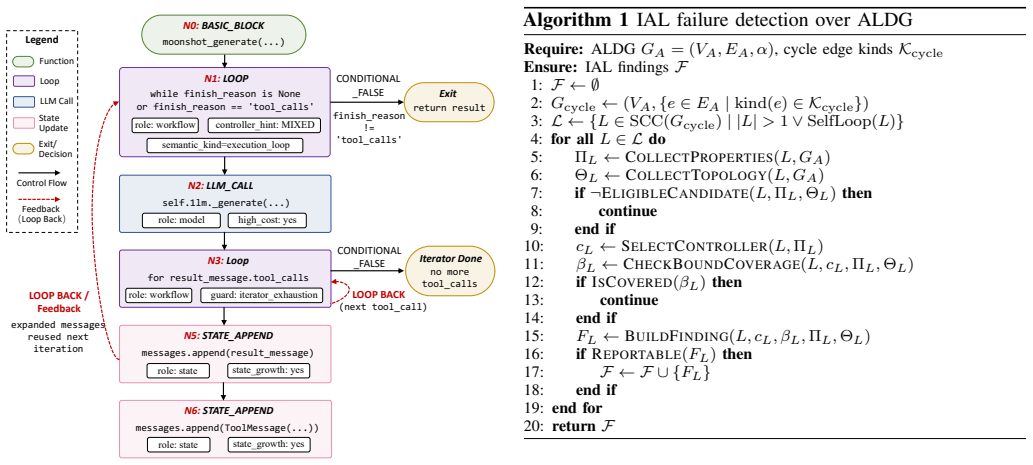
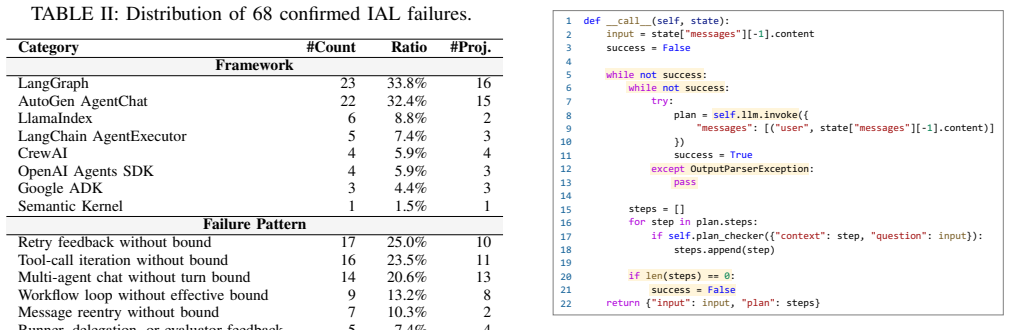

read the original abstract
LLM agents increasingly rely on iterative execution to solve tasks through planning, tool use, state updates, and agent collaboration. While this design enables flexible automation, it also creates a new class of failures: an agent may repeatedly execute model calls, tools, workflow transitions, or agent handoffs when the feedback path is not effectively bounded. We call this problem Infinite Agentic Loops (IALs). IALs are not ordinary programming loops; they arise from the interaction between agent logic, framework semantics, runtime observations, and termination mechanisms. Such failures can amplify a single request into long running model and tool execution, causing cost exhaustion, model denial of service, context growth, and repeated external side effects. We propose IAL-Scan, a static analysis tool for detecting IAL failures in real-world LLM agent projects. IAL-Scan abstracts heterogeneous agent code into a framework independent Agent IR, builds an Agentic Loop Dependence Graph (ALDG) to recover explicit and framework induced feedback paths, and checks whether these paths can repeatedly reach costly or state growing operations without an effective bound. We evaluate IAL-Scan on 6,549 LLM agent repositories. It reports 74 potential findings, among which manual review confirms 68 IAL failures across 47 projects, achieving 91.9% precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies Infinite Agentic Loops (IALs) as failures in LLM agents where iterative execution involving planning, tool use, state updates, and collaboration leads to unbounded feedback paths, causing cost exhaustion and other issues. It proposes IAL-Scan, which abstracts agent code into a framework-independent Agent IR, builds an Agentic Loop Dependence Graph (ALDG) to recover explicit and framework-induced paths, and checks for repeated reachability of costly operations without an effective bound. Evaluation on 6,549 repositories yields 74 findings, with manual review confirming 68 IAL failures across 47 projects at 91.9% precision.
Significance. If the static analysis and manual validation hold, the work provides a practical tool for detecting a previously under-studied failure mode in LLM agents and demonstrates its prevalence at scale across thousands of repositories. The framework-independent IR and ALDG approach addresses heterogeneity in agent implementations, which is a notable strength for real-world applicability.
major comments (2)
- [Abstract] Abstract and Evaluation section: The central empirical claim of 91.9% precision rests on manual review confirming 68 of 74 findings, yet no details are supplied on review methodology, confirmation criteria for distinguishing IALs from benign iterations, inter-rater agreement, or false-negative assessment. This leaves the reported precision and existence claim only partially supported.
- [Approach] Approach section (Agent IR and ALDG construction): The claim that ALDG recovers both explicit and framework-induced feedback paths and correctly identifies absence of an 'effective bound' is load-bearing for all reported findings. Because LLM agent behavior is runtime-dependent and non-deterministic, the paper must supply concrete definitions of bound recognition and validation (e.g., case studies or dynamic cross-checks) that the static abstractions do not systematically over- or under-approximate framework semantics.
minor comments (1)
- [Abstract] The abstract states the scale of the corpus (6,549 repositories) but does not indicate selection criteria or filtering steps; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation section: The central empirical claim of 91.9% precision rests on manual review confirming 68 of 74 findings, yet no details are supplied on review methodology, confirmation criteria for distinguishing IALs from benign iterations, inter-rater agreement, or false-negative assessment. This leaves the reported precision and existence claim only partially supported.
Authors: We agree that additional details on the manual review are required to fully support the precision claim. In the revised manuscript we will add a dedicated subsection in the Evaluation section describing: (1) the confirmation criteria (presence of an unbounded feedback path in the ALDG that can repeatedly reach costly operations without a terminating condition), (2) how benign iterations were distinguished (explicit bounds such as iteration caps, success flags, or external termination signals present in the IR), and (3) the inspection process applied to the 74 findings. The review was performed by the author team; therefore inter-rater agreement statistics are not available. A systematic false-negative assessment is not feasible without an exhaustive ground-truth oracle for all 6,549 repositories. revision: partial
-
Referee: [Approach] Approach section (Agent IR and ALDG construction): The claim that ALDG recovers both explicit and framework-induced feedback paths and correctly identifies absence of an 'effective bound' is load-bearing for all reported findings. Because LLM agent behavior is runtime-dependent and non-deterministic, the paper must supply concrete definitions of bound recognition and validation (e.g., case studies or dynamic cross-checks) that the static abstractions do not systematically over- or under-approximate framework semantics.
Authors: We will strengthen the Approach section with explicit definitions: an effective bound is present when the ALDG contains a path from a loop entry to a termination node (e.g., a success predicate, maximum-step counter, or framework-provided exit signal) that prevents repeated execution of costly operations. Framework-induced paths are recovered from documented semantics of each supported framework and are conservatively over-approximated. In the revision we will include case studies drawn from the 68 confirmed findings that illustrate the detected patterns and the missing bound. Full dynamic cross-validation is limited by LLM non-determinism and environment variability, but we will add illustrative runtime observations for a subset of findings where execution traces could be obtained. revision: yes
- Inter-rater agreement metrics for the manual validation (review performed by author team only)
- Comprehensive false-negative assessment (requires exhaustive labeled oracle across thousands of repositories)
Circularity Check
Empirical tool-building study with no circular derivations
full rationale
The paper describes construction of IAL-Scan (Agent IR + ALDG) and its application to 6549 repositories followed by manual review, yielding 68 confirmed IALs. No equations, fitted parameters, or predictions appear; the work contains no self-definitional steps, no renaming of known results as new derivations, and no load-bearing self-citations that reduce claims to prior author work by construction. The evaluation is externally falsifiable via the reported repositories and review process.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards practically-secure tools for AI agents,
J. Adam, Y . Lu, D. Raghavan, M. Schwarzkopf, and N. Vasilakis, “Towards practically-secure tools for AI agents,” inProceedings of the Sixth European Workshop on Machine Learning and Systems, EuroMLSys 2026, Edinburgh, Scotland, UK, April 27-30, 2026. ACM, 2026, pp. 215–224. [Online]. Available: https://doi.org/10.1145/3805621.3807645
-
[2]
CrewAI Documentation: Customizing agents,
CrewAI, “CrewAI Documentation: Customizing agents,” https://docs. crewai.com/en/learn/customizing-agents, 2026
2026
-
[3]
crewAIInc/crewAI: Framework for orchestrating role-playing autonomous AI agents,
——, “crewAIInc/crewAI: Framework for orchestrating role-playing autonomous AI agents,” https://github.com/crewAIInc/crewAI, 2026
2026
-
[4]
allow delegation=True leading to infinite loop,
CrewAI GitHub Community, “allow delegation=True leading to infinite loop,” https://github.com/crewAIInc/crewAI/issues/330, 2024
2024
-
[5]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram `er, “AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December...
2024
-
[6]
CodeQL: Semantic code analysis engine,
GitHub, “CodeQL: Semantic code analysis engine,” https://codeql.github. com/, 2026
2026
-
[7]
On the (In)Security of LLM app stores,
X. Hou, Y . Zhao, and H. Wang, “On the (In)Security of LLM app stores,” inIEEE Symposium on Security and Privacy, SP 2025, San Francisco, CA, USA, May 12-15, 2025, M. Blanton, W. Enck, and C. Nita-Rotaru, Eds. IEEE, 2025, pp. 317–335. [Online]. Available: https://doi.org/10.1109/SP61157.2025.00117
-
[8]
AgentExecutor reference,
LangChain, “AgentExecutor reference,” https://reference.langchain.com/ python/langchain-classic/agents/agent/AgentExecutor, 2026
2026
-
[9]
LangChain: Observe, evaluate, and deploy reliable AI agents,
——, “LangChain: Observe, evaluate, and deploy reliable AI agents,” https://www.langchain.com/, 2026
2026
-
[10]
LangChain Reference: AgentExecutor max iterations,
——, “LangChain Reference: AgentExecutor max iterations,” https://reference.langchain.com/python/langchain-classic/agents/agent/ AgentExecutor/max iterations, 2026
2026
-
[11]
LangGraph Documentation: GRAPH RECURSION LIMIT,
——, “LangGraph Documentation: GRAPH RECURSION LIMIT,” https://docs.langchain.com/oss/python/langgraph/errors/GRAPH RECURSION LIMIT, 2026
2026
-
[12]
LangGraph overview,
——, “LangGraph overview,” https://docs.langchain.com/oss/python/ langgraph/overview, 2026
2026
-
[13]
LangGraph Reference: GraphRecursionError,
——, “LangGraph Reference: GraphRecursionError,” https://reference. langchain.com/python/langgraph/errors/GraphRecursionError, 2026
2026
-
[14]
Agent infinite looping until recursion limit error is hit,
LangGraph GitHub Community, “Agent infinite looping until recursion limit error is hit,” https://github.com/langchain-ai/langgraph/issues/6731, 2026
2026
-
[15]
Towards Security-Auditable LLM Agents: A Unified Graph Representation
C. Li, L. Zhang, J. Zhai, S. Feng, X. Yang, H. Wang, S. Dou, Y . Ji, Y . Hu, Y . Wu, Y . Liu, and D. Zou, “Towards security-auditable LLM agents: A unified graph representation,”CoRR, vol. abs/2605.06812,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Towards Security-Auditable LLM Agents: A Unified Graph Representation
[Online]. Available: https://doi.org/10.48550/arXiv.2605.06812
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.06812
-
[17]
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Y . Li, H. Wen, W. Wang, X. Li, Y . Yuan, G. Liu, J. Liu, W. Xu, X. Wang, Y . Sun, R. Kong, Y . Wang, H. Geng, J. Luan, X. Jin, Z. Ye, G. Xiong, F. Zhang, X. Li, M. Xu, Z. Li, P. Li, Y . Liu, Y . Zhang, and Y . Liu, “Personal LLM agents: Insights and survey about the capability, efficiency and security,”CoRR, vol. abs/2401.05459, 2024. [Online]. Available...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.05459 2024
-
[18]
IRIS: LLM-Assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “IRIS: LLM-Assisted static analysis for detecting security vulnerabilities,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=9LdJDU7E91
2025
-
[19]
Z. Liang, Q. Xie, J. He, B. Xue, W. Wang, Y . Cai, F. Luo, B. Zhang, H. Hu, and K. Wu, “Argus: Reorchestrating static analysis via a multi-agent ensemble for full-chain security vulnerability detection,”CoRR, vol. abs/2604.06633, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2604.06633
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.06633 2026
-
[20]
AgentRaft: Automated detection of data over-exposure in LLM agents,
Y . Lin, J. Wu, Y . Nan, X. Wang, X. Zhang, and Z. Zheng, “AgentRaft: Automated detection of data over-exposure in LLM agents,”CoRR, vol. abs/2603.07557, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.07557
-
[21]
Termination conditions in AutoGen AgentChat,
Microsoft, “Termination conditions in AutoGen AgentChat,” https: //microsoft.github.io/autogen/stable/user-guide/agentchat-user-guide/ tutorial/termination.html, 2026
2026
-
[22]
AutoGen update,
Microsoft AutoGen, “AutoGen update,” https://github.com/microsoft/ autogen/discussions/7066, 2025
2025
-
[23]
AgentSCOPE: Evaluating contextual privacy across agentic workflows,
I. C. Ngong, K. Murugesan, S. Kadhe, J. D. Weisz, A. Dhurandhar, and K. N. Ramamurthy, “AgentSCOPE: Evaluating contextual privacy across agentic workflows,”CoRR, vol. abs/2603.04902, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.04902
-
[24]
OpenAI agents SDK for python,
OpenAI, “OpenAI agents SDK for python,” https://github.com/openai/ openai-agents-python, 2026
2026
-
[25]
OpenAI Agents SDK: Runner reference,
——, “OpenAI Agents SDK: Runner reference,” https://openai.github.io/ openai-agents-python/ref/run/, 2026
2026
-
[26]
OpenAI Agents SDK: Running agents,
——, “OpenAI Agents SDK: Running agents,” https://openai.github.io/ openai-agents-python/running agents/, 2026
2026
-
[27]
Runner reference: OpenAI agents SDK,
——, “Runner reference: OpenAI agents SDK,” https://openai.github.io/ openai-agents-python/ref/run/, 2026
2026
-
[28]
Running agents: The agent loop,
——, “Running agents: The agent loop,” https://developers.openai.com/ api/docs/guides/agents/running-agents, 2026
2026
-
[29]
Detecting infinite loops in LangGraph multi-agent systems,
Reddit r/LangChain Community, “Detecting infinite loops in LangGraph multi-agent systems,” https://www.reddit.com/r/LangChain/comments/ 1r2mdz1/detecting infinite loops in langgraph multiagent/, 2026
2026
-
[30]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,...
2023
-
[31]
Semgrep: Lightweight static analysis for many languages,
Semgrep, “Semgrep: Lightweight static analysis for many languages,” https://github.com/semgrep/semgrep, 2026
2026
-
[32]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. H...
2023
-
[33]
Available: http://papers.nips.cc/paper files/paper/2023/ hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html
[Online]. Available: http://papers.nips.cc/paper files/paper/2023/ hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html
2023
-
[34]
QLCoder: A query synthesizer for static analysis of security vulnerabilities,
C. Wang, Z. Li, S. Dutta, and M. Naik, “QLCoder: A query synthesizer for static analysis of security vulnerabilities,”CoRR, vol. abs/2511.08462,
-
[35]
QLCoder: A query synthesizer for static analysis of security vulnerabilities,
[Online]. Available: https://doi.org/10.48550/arXiv.2511.08462
-
[36]
A survey on large language model based autonomous agents.Frontiers Comput
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, W. X. Zhao, Z. Wei, and J. Wen, “A survey on large language model based autonomous agents,”Frontiers Comput. Sci., vol. 18, no. 6, p. 186345, 2024. [Online]. Available: https://doi.org/10.1007/s11704-024-40231-1
-
[37]
Y . Wang, Y . Pan, Z. Su, Y . Deng, Q. Zhao, L. Du, T. H. Luan, J. Kang, and D. Niyato, “Large model-based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,”IEEE Commun. Surv. Tutorials, vol. 28, pp. 1906–1949, 2026. [Online]. Available: https://doi.org/10.1109/COMST.2025.3576176
-
[38]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi-agent conversation,”arXiv preprint arXiv:2308.08155, 2023. [Online]. Available: https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Agentproof: Static verification of agent workflow graphs,
M. Xavier, V . M. A, M. Jolly, and M. Xavier, “Agentproof: Static verification of agent workflow graphs,”CoRR, vol. abs/2603.20356,
-
[40]
Agentproof: Static verification of agent workflow graphs,
[Online]. Available: https://doi.org/10.48550/arXiv.2603.20356
-
[41]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[42]
ReAct: Synergizing reasoning and acting in language models,
——, “ReAct: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[43]
Agent audit: A security analysis system for LLM agent applications,
H. Zhang, Y . Nian, and Y . Zhao, “Agent audit: A security analysis system for LLM agent applications,”CoRR, vol. abs/2603.22853, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.22853
-
[44]
Agent security bench (ASB): formalizing and benchmarking attacks and defenses in LLM-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): formalizing and benchmarking attacks and defenses in LLM-based agents,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net...
2025
-
[45]
LLM app store analysis: A vision and roadmap,
Y . Zhao, X. Hou, S. Wang, and H. Wang, “LLM app store analysis: A vision and roadmap,”CoRR, vol. abs/2404.12737, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2404.12737
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.