DrawMotion: Generating 3D Human Motions by Freehand Drawing
Pith reviewed 2026-05-21 05:12 UTC · model grok-4.3
The pith
DrawMotion generates 3D human motions from both text descriptions and freehand drawings for semantic and spatial control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DrawMotion is a diffusion-based framework for generating 3D human motions conditioned on text and hand-drawing inputs. It develops an algorithm to automatically generate hand-drawn stickman sketches from dataset motions in various formats, proposes a Multi-Condition Module integrated into the diffusion process to handle combinations of conditions, and applies training-free guidance to align outputs with user intentions while maintaining motion quality.
What carries the argument
The Multi-Condition Module (MCM), which fuses text and drawing conditions into the diffusion model's features to enable flexible control and continuous-space updates for guidance.
If this is right
- Users gain spatial precision in generated motions without needing detailed text descriptions.
- The approach cuts the time required to produce intended motions by roughly 46.7 percent.
- Motions can be generated from any mix of available conditions without retraining for each combination.
- The system preserves motion fidelity while allowing adjustments through guidance.
Where Pith is reading between the lines
- Similar sketching interfaces might improve control in related generation tasks like image or video synthesis.
- Integrating this with real-time drawing tools could enable interactive motion design sessions.
- Extending the stick figure representation to include more body details could capture even finer intent.
Load-bearing premise
Hand-drawn stickman sketches generated automatically from motion datasets accurately reflect the spatial details that real users intend to convey in their drawings.
What would settle it
Compare generated motions against user-drawn sketches in a blind test and measure if key spatial features like joint angles and movement paths match within a small error margin.
Figures







read the original abstract
Text-to-motion generation, which translates textual descriptions into human motions, faces the challenge that users often struggle to precisely convey their intended motions through text alone. To address this issue, this paper introduces DrawMotion, an efficient diffusion-based framework designed for multi-condition scenarios. DrawMotion generates motions based on both a conventional text condition and a novel hand-drawing condition, which provide semantic and spatial control over the generated motions, respectively. Specifically, we tackle the fine-grained motion generation task from three perspectives: 1) freehand drawing condition. To accurately capture users' intended motions without requiring tedious textual input, we develop an algorithm to automatically generate hand-drawn stickman sketches across different dataset formats; 2) multi-condition fusion. We propose a Multi-Condition Module (MCM) that is integrated into the diffusion process, enabling the model to exploit all possible condition combinations while reducing computational complexity compared to conventional approaches; and 3) training-free guidance. Notably, the MCM in DrawMotion ensures that its intermediate features lie in a continuous space, allowing classifier-guidance gradients to update the features and thereby aligning the generated motions with user intentions while preserving fidelity. Quantitative experiments and user studies demonstrate that the freehand drawing approach reduces user time by approximately 46.7% when generating motions aligned with their imagination. The code, demos, and relevant data are publicly available at https://github.com/InvertedForest/DrawMotion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
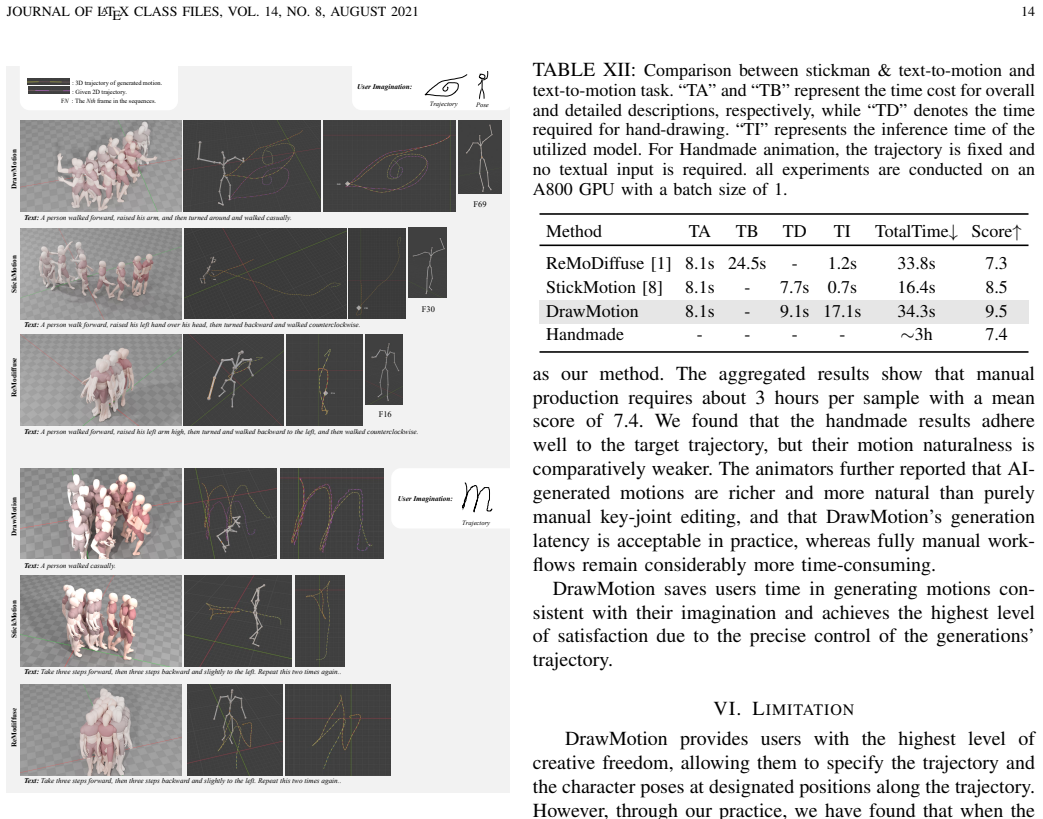
Summary. The paper introduces DrawMotion, a diffusion-based framework for 3D human motion generation that combines conventional text conditioning for semantic control with a novel hand-drawing condition for spatial control. Key technical elements include an algorithm that automatically converts dataset motions into hand-drawn stickman sketches, a Multi-Condition Module (MCM) integrated into the diffusion process to handle arbitrary condition combinations, and training-free classifier guidance that operates on the continuous feature space produced by the MCM. Quantitative experiments and user studies are reported to support a 46.7% reduction in user time for producing motions aligned with user intent, with code and demos released publicly.
Significance. If the central claims hold, the work provides a practical and intuitive extension to text-to-motion generation by incorporating freehand sketches as an additional spatial prior. This could meaningfully improve controllability in applications such as animation and virtual reality. The public release of code, demos, and data is a clear strength that aids reproducibility and follow-up research. The approach builds on established diffusion techniques rather than introducing entirely new paradigms.
major comments (2)
- [§3] §3 (freehand drawing condition): The training pipeline relies on automatically generated stickman sketches derived from dataset motions, yet no ablation or out-of-distribution test evaluates performance when real user drawings—with their inherent variability in stroke thickness, proportions, and joint angles—are supplied at inference time. Because the MCM and training-free guidance depend on continuous feature-space alignment, this domain gap directly threatens the claimed reliability of spatial control.
- [User-study evaluation] User-study evaluation: The reported 46.7% time savings is presented as evidence of practical utility, but the study description does not report quantitative metrics (e.g., Fréchet Motion Distance or joint-angle error) comparing motions generated from real freehand sketches versus the synthetic training distribution, leaving the alignment claim only partially supported.
minor comments (2)
- [Abstract] The abstract states that the MCM 'reduces computational complexity compared to conventional approaches' without naming the baselines or providing FLOPs/latency numbers; a brief comparison table would clarify this advantage.
- [§4] Notation for the MCM feature concatenation and guidance gradient computation could be made more explicit, especially for readers who may not immediately see how the continuous-space property enables classifier guidance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, offering clarifications based on the manuscript and outlining planned revisions to strengthen the evaluation.
read point-by-point responses
-
Referee: [§3] §3 (freehand drawing condition): The training pipeline relies on automatically generated stickman sketches derived from dataset motions, yet no ablation or out-of-distribution test evaluates performance when real user drawings—with their inherent variability in stroke thickness, proportions, and joint angles—are supplied at inference time. Because the MCM and training-free guidance depend on continuous feature-space alignment, this domain gap directly threatens the claimed reliability of spatial control.
Authors: We appreciate this observation regarding the training distribution. The automatic sketch generation algorithm was developed specifically to create paired training data that matches the motion datasets across formats, ensuring the model learns consistent spatial mappings. The user studies in the paper did involve participants supplying their own freehand drawings at inference time, with the 46.7% time reduction reflecting real usage. The MCM's continuous feature space and training-free guidance are designed to support such inputs by allowing gradient-based alignment without retraining. To directly address the domain gap concern, the revised manuscript will include an out-of-distribution ablation using a collected set of real user drawings with natural variability, reporting metrics such as Fréchet Motion Distance to quantify robustness. revision: yes
-
Referee: [User-study evaluation] User-study evaluation: The reported 46.7% time savings is presented as evidence of practical utility, but the study description does not report quantitative metrics (e.g., Fréchet Motion Distance or joint-angle error) comparing motions generated from real freehand sketches versus the synthetic training distribution, leaving the alignment claim only partially supported.
Authors: We agree that the current user-study presentation focuses on time efficiency and subjective alignment rather than explicit quantitative motion-quality metrics for real versus synthetic inputs. This leaves room for stronger substantiation of the spatial control claims. In the revised manuscript, we will expand the evaluation section to include direct comparisons using metrics such as Fréchet Motion Distance and average joint-angle error between motions produced from real freehand sketches and those from the synthetic training distribution, while retaining the time-savings results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces DrawMotion as a diffusion-based framework that augments standard text-to-motion generation with a hand-drawing condition via an auto-generated stickman sketch algorithm, a Multi-Condition Module (MCM) for fusion, and training-free classifier guidance. These additions are presented as engineering extensions rather than derivations that reduce to their own inputs by construction; the hand-drawing training data is produced by a separate algorithm applied to existing motion datasets, and performance is asserted through quantitative metrics and user studies measuring time savings. No equations, self-citations, or fitted parameters are shown in the provided text to create a self-definitional loop or to rename a fitted quantity as an independent prediction. The central claims therefore remain self-contained against external benchmarks such as standard diffusion models and empirical validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
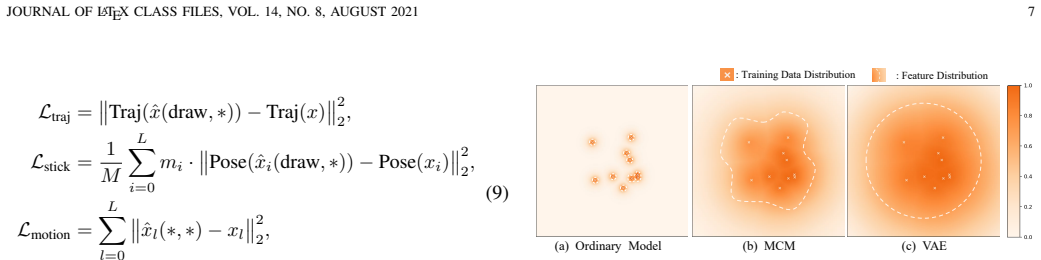
We propose a Multi-Condition Module (MCM) ... training-free guidance method (IFG) ... Mahalanobis distance ... MD clipping
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stickman Generation Algorithm (SGA) ... automatically produces stickman sketches ... candidate loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Remodiffuse: Retrieval-augmented motion diffusion model,
M. Zhang, X. Guo, L. Pan, Z. Cai, F. Hong, H. Li, L. Yang, and Z. Liu, “Remodiffuse: Retrieval-augmented motion diffusion model,” inICCV, 2023, pp. 364–373
work page 2023
-
[2]
Motiongpt: Finetuned llms are general-purpose motion generators,
Y . Zhang, D. Huang, B. Liu, S. Tang, Y . Lu, L. Chen, L. Bai, Q. Chu, N. Yu, and W. Ouyang, “Motiongpt: Finetuned llms are general-purpose motion generators,” inAAAI, vol. 38, no. 7, 2024, pp. 7368–7376
work page 2024
-
[3]
Motionclip: Exposing human motion generation to clip space,
G. Tevet, B. Gordon, A. Hertz, A. H. Bermano, and D. Cohen-Or, “Motionclip: Exposing human motion generation to clip space,” in ECCV. Springer, 2022, pp. 358–374
work page 2022
-
[4]
Flame: Free-form language-based motion synthesis & editing,
J. Kim, J. Kim, and S. Choi, “Flame: Free-form language-based motion synthesis & editing,” inAAAI, vol. 37, no. 7, 2023, pp. 8255–8263
work page 2023
-
[5]
Finemogen: Fine-grained spatio-temporal motion generation and editing,
M. Zhang, H. Li, Z. Cai, J. Ren, L. Yang, and Z. Liu, “Finemogen: Fine-grained spatio-temporal motion generation and editing,”NeurIPS, vol. 36, 2024
work page 2024
-
[6]
M. Zhang, Z. Cai, L. Pan, F. Hong, X. Guo, L. Yang, and Z. Liu, “Motiondiffuse: Text-driven human motion generation with diffusion model,”arXiv preprint arXiv:2208.15001, 2022
-
[7]
Iterative motion editing with natural language,
P. Goel, K.-C. Wang, C. K. Liu, and K. Fatahalian, “Iterative motion editing with natural language,” inSIGGRAPH, 2024, pp. 1–9
work page 2024
-
[8]
Stickmotion: Generating 3d human motions by drawing a stick- man,
T. Wang, Z. Wu, Q. He, J. Chu, L. Qian, Y . Cheng, J. Xing, J. Zhao, and L. Jin, “Stickmotion: Generating 3d human motions by drawing a stick- man,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 370–12 379
work page 2025
-
[9]
Re-imagen: Retrieval- augmented text-to-image generator,
W. Chen, H. Hu, C. Saharia, and W. W. Cohen, “Re-imagen: Retrieval- augmented text-to-image generator,”arXiv preprint arXiv:2209.14491, 2022
- [10]
-
[11]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inICML. PMLR, 2015, pp. 2256–2265
work page 2015
-
[12]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” NeurIPS, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[13]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”NeurIPS, vol. 34, pp. 8780–8794, 2021
work page 2021
-
[14]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
work page 2020
-
[15]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applica- tions, 2021
work page 2021
-
[16]
A survey on generative diffusion models,
H. Cao, C. Tan, Z. Gao, Y . Xu, G. Chen, P.-A. Heng, and S. Z. Li, “A survey on generative diffusion models,”TKDE, 2024
work page 2024
-
[17]
Back to mlp: A simple baseline for human motion prediction,
W. Guo, Y . Du, X. Shen, V . Lepetit, X. Alameda-Pineda, and F. Moreno- Noguer, “Back to mlp: A simple baseline for human motion prediction,” inWACV, 2023, pp. 4809–4819
work page 2023
-
[18]
Humanmac: Masked motion completion for human motion prediction,
L.-H. Chen, J. Zhang, Y . Li, Y . Pang, X. Xia, and T. Liu, “Humanmac: Masked motion completion for human motion prediction,” inICCV, 2023, pp. 9544–9555
work page 2023
-
[19]
Incorporating physics principles for precise human motion prediction,
Y . Zhang, J. O. Kephart, and Q. Ji, “Incorporating physics principles for precise human motion prediction,” inWACV, 2024, pp. 6164–6174
work page 2024
-
[20]
T. Ma, Y . Nie, C. Long, Q. Zhang, and G. Li, “Progressively generating better initial guesses towards next stages for high-quality human motion prediction,” inCVPR, 2022, pp. 6437–6446
work page 2022
-
[21]
Gcnext: Towards the unity of graph convolutions for human motion prediction,
X. Wang, Q. Cui, C. Chen, and M. Liu, “Gcnext: Towards the unity of graph convolutions for human motion prediction,” inAAAI, vol. 38, no. 6, 2024, pp. 5642–5650
work page 2024
-
[22]
Action2motion: Conditioned generation of 3d human motions,
C. Guo, X. Zuo, S. Wang, S. Zou, Q. Sun, A. Deng, M. Gong, and L. Cheng, “Action2motion: Conditioned generation of 3d human motions,” inACM MM, 2020, pp. 2021–2029
work page 2020
-
[23]
Structure-aware human- action generation,
P. Yu, Y . Zhao, C. Li, J. Yuan, and C. Chen, “Structure-aware human- action generation,” inECCV. Springer, 2020, pp. 18–34
work page 2020
-
[24]
Generative adversarial graph convolutional networks for human action synthesis,
B. Degardin, J. Neves, V . Lopes, J. Brito, E. Yaghoubi, and H. Proenc ¸a, “Generative adversarial graph convolutional networks for human action synthesis,” inWACV, 2022, pp. 1150–1159
work page 2022
-
[25]
Action-conditioned 3d human motion synthesis with transformer vae,
M. Petrovich, M. J. Black, and G. Varol, “Action-conditioned 3d human motion synthesis with transformer vae,” inICCV, 2021, pp. 10 985– 10 995
work page 2021
-
[26]
Action-conditioned on-demand motion generation,
Q. Lu, Y . Zhang, M. Lu, and V . Roychowdhury, “Action-conditioned on-demand motion generation,” inACM MM, 2022, pp. 2249–2257
work page 2022
-
[27]
Implicit neural representations for variable length human motion generation,
P. Cervantes, Y . Sekikawa, I. Sato, and K. Shinoda, “Implicit neural representations for variable length human motion generation,” inECCV. Springer, 2022, pp. 356–372
work page 2022
-
[28]
Dancemeld: Unrav- eling dance phrases with hierarchical latent codes for music-to-dance synthesis,
X. Gao, L. Hu, P. Zhang, B. Zhang, and L. Bo, “Dancemeld: Unrav- eling dance phrases with hierarchical latent codes for music-to-dance synthesis,”arXiv preprint arXiv:2401.10242, 2023
-
[29]
Dance revolution: Long-term dance generation with music via curriculum learning,
R. Huang, H. Hu, W. Wu, K. Sawada, M. Zhang, and D. Jiang, “Dance revolution: Long-term dance generation with music via curriculum learning,”arXiv preprint arXiv:2006.06119, 2020
-
[30]
Danceformer: Music con- ditioned 3d dance generation with parametric motion transformer,
B. Li, Y . Zhao, S. Zhelun, and L. Sheng, “Danceformer: Music con- ditioned 3d dance generation with parametric motion transformer,” in AAAI, vol. 36, no. 2, 2022, pp. 1272–1279
work page 2022
-
[31]
Edge: Editable dance generation from music,
J. Tseng, R. Castellon, and K. Liu, “Edge: Editable dance generation from music,” inCVPR, 2023, pp. 448–458
work page 2023
-
[32]
Gesturediffuclip: Gesture diffusion model with clip latents,
T. Ao, Z. Zhang, and L. Liu, “Gesturediffuclip: Gesture diffusion model with clip latents,”TOG, vol. 42, no. 4, pp. 1–18, 2023
work page 2023
-
[33]
Zeroeggs: Zero-shot example-based gesture generation from speech,
S. Ghorbani, Y . Ferstl, D. Holden, N. F. Troje, and M.-A. Carbonneau, “Zeroeggs: Zero-shot example-based gesture generation from speech,” inComputer Graphics Forum, vol. 42, no. 1. Wiley Online Library, 2023, pp. 206–216
work page 2023
-
[34]
Analyzing input and output representations for speech-driven gesture generation,
T. Kucherenko, D. Hasegawa, G. E. Henter, N. Kaneko, and H. Kjell- str¨om, “Analyzing input and output representations for speech-driven gesture generation,” inProceedings of the 19th ACM International Conference on Intelligent Virtual Agents, 2019, pp. 97–104
work page 2019
-
[35]
Speech gesture generation from the trimodal context of text, audio, and speaker identity,
Y . Yoon, B. Cha, J.-H. Lee, M. Jang, J. Lee, J. Kim, and G. Lee, “Speech gesture generation from the trimodal context of text, audio, and speaker identity,”TOG, vol. 39, no. 6, pp. 1–16, 2020
work page 2020
-
[36]
Language2pose: Natural language grounded pose forecasting,
C. Ahuja and L.-P. Morency, “Language2pose: Natural language grounded pose forecasting,” in3DV. IEEE, 2019, pp. 719–728
work page 2019
-
[37]
Syn- thesis of compositional animations from textual descriptions,
A. Ghosh, N. Cheema, C. Oguz, C. Theobalt, and P. Slusallek, “Syn- thesis of compositional animations from textual descriptions,” inICCV, 2021, pp. 1396–1406
work page 2021
-
[38]
Generating diverse and natural 3d human motions from text,
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng, “Generating diverse and natural 3d human motions from text,” inCVPR, 2022, pp. 5152–5161
work page 2022
-
[39]
Anyskill: Learn- ing open-vocabulary physical skill for interactive agents,
J. Cui, T. Liu, N. Liu, Y . Yang, Y . Zhu, and S. Huang, “Anyskill: Learn- ing open-vocabulary physical skill for interactive agents,” inCVPR, 2024, pp. 852–862
work page 2024
-
[40]
Momask: Generative masked modeling of 3d human motions,
C. Guo, Y . Mu, M. G. Javed, S. Wang, and L. Cheng, “Momask: Generative masked modeling of 3d human motions,” inCVPR, 2024, pp. 1900–1910
work page 2024
-
[41]
Diffusion-based generation, optimization, and planning in 3d scenes,
S. Huang, Z. Wang, P. Li, B. Jia, T. Liu, Y . Zhu, W. Liang, and S.- C. Zhu, “Diffusion-based generation, optimization, and planning in 3d scenes,” inCVPR, 2023, pp. 16 750–16 761
work page 2023
-
[42]
Populating 3d scenes by learning human-scene interaction,
M. Hassan, P. Ghosh, J. Tesch, D. Tzionas, and M. J. Black, “Populating 3d scenes by learning human-scene interaction,” inCVPR, 2021, pp. 14 708–14 718
work page 2021
-
[43]
Mammos: Mapping multiple human motion with scene understanding and natural interactions,
D. Lim, C. Jeong, and Y . M. Kim, “Mammos: Mapping multiple human motion with scene understanding and natural interactions,” inICCV, 2023, pp. 4278–4287
work page 2023
-
[44]
Revisit human-scene interaction via space occupancy,
X. Liu, H. Hou, Y . Yang, Y .-L. Li, and C. Lu, “Revisit human-scene interaction via space occupancy,”arXiv preprint arXiv:2312.02700, 2023
-
[45]
arXiv preprint arXiv:2309.07918 (2023)
Z. Xiao, T. Wang, J. Wang, J. Cao, W. Zhang, B. Dai, D. Lin, and J. Pang, “Unified human-scene interaction via prompted chain-of- contacts,”arXiv preprint arXiv:2309.07918, 2023
-
[46]
Cg-hoi: Contact-guided 3d human-object inter- action generation,
C. Diller and A. Dai, “Cg-hoi: Contact-guided 3d human-object inter- action generation,” inCVPR, 2024, pp. 19 888–19 901
work page 2024
-
[47]
Interdiff: Generating 3d human-object interactions with physics-informed diffusion,
S. Xu, Z. Li, Y .-X. Wang, and L.-Y . Gui, “Interdiff: Generating 3d human-object interactions with physics-informed diffusion,” inICCV, 2023, pp. 14 928–14 940
work page 2023
-
[48]
Interactgan: Learning to generate human-object interaction,
C. Gao, S. Liu, D. Zhu, Q. Liu, J. Cao, H. He, R. He, and S. Yan, “Interactgan: Learning to generate human-object interaction,” inACM MM, 2020, pp. 165–173. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 16
work page 2020
-
[49]
Handdiffuse: Generative controllers for two-hand interactions via diffusion models,
P. Lin, S. Xu, H. Yang, Y . Liu, X. Chen, J. Wang, J. Yu, and L. Xu, “Handdiffuse: Generative controllers for two-hand interactions via diffusion models,”arXiv preprint arXiv:2312.04867, 2023
-
[50]
Digital life project: Autonomous 3d characters with social intelligence,
Z. Cai, J. Jiang, Z. Qing, X. Guo, M. Zhang, Z. Lin, H. Mei, C. Wei, R. Wang, W. Yinet al., “Digital life project: Autonomous 3d characters with social intelligence,” inCVPR, 2024, pp. 582–592
work page 2024
-
[51]
Bipartite graph diffusion model for human interaction generation,
B. Chopin, H. Tang, and M. Daoudi, “Bipartite graph diffusion model for human interaction generation,” inWACV, 2024, pp. 5333–5342
work page 2024
-
[52]
Remos: Reactive 3d motion synthesis for two-person interactions,
A. Ghosh, R. Dabral, V . Golyanik, C. Theobalt, and P. Slusallek, “Remos: Reactive 3d motion synthesis for two-person interactions,” arXiv preprint arXiv:2311.17057, 2023
-
[53]
Intergen: Diffusion- based multi-human motion generation under complex interactions,
H. Liang, W. Zhang, W. Li, J. Yu, and L. Xu, “Intergen: Diffusion- based multi-human motion generation under complex interactions,” International Journal of Computer Vision, pp. 1–21, 2024
work page 2024
-
[54]
Role-aware interaction generation from textual description,
M. Tanaka and K. Fujiwara, “Role-aware interaction generation from textual description,” inICCV, 2023, pp. 15 999–16 009
work page 2023
-
[55]
Guided motion diffusion for controllable human motion synthesis,
K. Karunratanakul, K. Preechakul, S. Suwajanakorn, and S. Tang, “Guided motion diffusion for controllable human motion synthesis,” 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 2151–2162, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:258833752
work page 2023
-
[56]
Human motion diffusion as a generative prior,
Y . Shafir, G. Tevet, R. Kapon, and A. H. Bermano, “Human motion diffusion as a generative prior,”ArXiv, vol. abs/2303.01418,
-
[57]
Available: https://api.semanticscholar.org/CorpusID: 257279944
[Online]. Available: https://api.semanticscholar.org/CorpusID: 257279944
-
[58]
Flexible motion in-betweening with diffusion models,
S. Cohan, G. Tevet, D. Reda, X. B. Peng, and M. van de Panne, “Flexible motion in-betweening with diffusion models,”ACM SIGGRAPH 2024 Conference Papers, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:269922160
work page 2024
-
[59]
Omnicontrol: Control any joint at any time for human motion generation,
Y . Xie, V . Jampani, L. Zhong, D. Sun, and H. Jiang, “Omnicontrol: Control any joint at any time for human motion generation,”ArXiv, vol. abs/2310.08580, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:263909429
-
[60]
Adding conditional control to text- to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text- to-image diffusion models,”2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 3813–3824, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:256827727
work page 2023
-
[61]
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano, “Human motion diffusion model,” 2022. [Online]. Available: https://arxiv.org/abs/2209.14916
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
Optimizing diffusion noise can serve as universal motion priors,
K. Karunratanakul, K. Preechakul, E. Aksan, T. Beeler, S. Suwajanakorn, and S. Tang, “Optimizing diffusion noise can serve as universal motion priors,”2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1334–1345, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:266362434
work page 2024
-
[63]
The kit motion-language dataset,
M. Plappert, C. Mandery, and T. Asfour, “The kit motion-language dataset,”Big data, vol. 4, no. 4, pp. 236–252, 2016
work page 2016
-
[64]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”ArXiv, vol. abs/2010.02502, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:222140788
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[65]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML. PMLR, 2021, pp. 8748–8763
work page 2021
-
[66]
Efficient attention: Attention with linear complexities,
Z. Shen, M. Zhang, H. Zhao, S. Yi, and H. Li, “Efficient attention: Attention with linear complexities,” inWACV, 2021, pp. 3531–3539
work page 2021
-
[67]
Probabilistic and semantic descriptions of image manifolds and their applications,
P. Tu, Z. Yang, R. Hartley, Z. Xu, J. Zhang, D. Campbell, J. Singh, and T. Wang, “Probabilistic and semantic descriptions of image manifolds and their applications,”ArXiv, vol. abs/2307.02881, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259360837
-
[68]
Reducing the dimensionality of data with neural networks,
G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,”science, vol. 313, no. 5786, pp. 504–507, 2006
work page 2006
-
[69]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[70]
Prevalence of neural collapse during the terminal phase of deep learning training,
V . Papyan, X. Han, and D. L. Donoho, “Prevalence of neural collapse during the terminal phase of deep learning training,”Proceedings of the National Academy of Sciences of the United States of America, vol. 117, pp. 24 652 – 24 663, 2020
work page 2020
-
[71]
Feature learning in deep classifiers through intermediate neural collapse,
A. Rangamani, M. Lindegaard, T. Galanti, and T. A. Poggio, “Feature learning in deep classifiers through intermediate neural collapse,” in International Conference on Machine Learning, 2023
work page 2023
-
[72]
The prevalence of neural collapse in neural multivariate regression,
G. Andriopoulos, Z. Dong, L. Guo, Z. Zhao, and K. Ross, “The prevalence of neural collapse in neural multivariate regression,”ArXiv, vol. abs/2409.04180, 2024
-
[73]
On the generalized distance in statistics,
P. C. Mahalanobis, “On the generalized distance in statistics,”
-
[74]
Available: https://api.semanticscholar.org/CorpusID: 117765088
[Online]. Available: https://api.semanticscholar.org/CorpusID: 117765088
-
[75]
Generating human motion from textual descriptions with discrete representations,
J. Zhang, Y . Zhang, X. Cun, Y . Zhang, H. Zhao, H. Lu, X. Shen, and Y . Shan, “Generating human motion from textual descriptions with discrete representations,” inCVPR, 2023, pp. 14 730–14 740. Tao Wangis currently pursuing a doctorate at Beijing University of Posts and Telecommunica- tions (BUPT), Beijing, China. His major research areas include human p...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.