A Tale of Two Cities: Pessimism and Opportunism in Offline Dynamic Pricing
Pith reviewed 2026-05-23 17:35 UTC · model grok-4.3
The pith
When historical pricing data leaves some prices unobserved, including the optimum, a monotonicity-based partial identification framework produces pessimistic and opportunistic policies with finite-sample regret bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the monotonicity of demand supplies enough structure to partially identify the value of unobserved prices, allowing the construction of two dynamic policies—one pessimistic and one opportunistic—whose finite-sample regret can be bounded even in a sequential no-coverage environment, with the bounds recovering the standard rate whenever the optimal price is observed.
What carries the argument
Nonparametric partial identification framework that exploits monotonicity of demand in price to bound the value of unobserved prices.
If this is right
- The pessimistic policy delivers a revenue guarantee that protects against the worst possible completion of the unobserved prices.
- The opportunistic policy delivers a regret bound that limits the loss relative to the best feasible policy even when the optimum is missing.
- Both bounds recover the usual offline rate when the optimal price is covered and add a quantifiable extra term when it is not.
- Efficient algorithms exist that implement the two policies and outperform standard offline RL baselines in no-coverage regimes.
Where Pith is reading between the lines
- The explicit mapping from a firm’s risk posture to policy choice could be applied to other sequential decision settings that face partial data coverage.
- Replacing monotonicity with other shape restrictions on demand would produce analogous frameworks for different economic environments.
- The same bounding technique might be used to derive policies in offline inventory or assortment problems where certain actions are missing from historical data.
Load-bearing premise
Demand is monotonically decreasing in price.
What would settle it
A data set in which the observed demand function is not monotonically decreasing and the derived policies produce regret larger than the stated bounds.
Figures

read the original abstract
We study offline dynamic pricing when historical data provide incomplete coverage of the price space such that some candidate prices, including the optimal one, may be entirely unobserved. This setting is common in practice and is especially difficult in dynamic environments. Existing offline reinforcement learning methods typically rely on full or partial coverage and can therefore perform poorly in such settings. We develop a nonparametric partial identification framework for offline dynamic pricing that exploits the monotonicity of demand in price to bound the value of unobserved prices. Within this framework, we formulate two dynamic decision rules: a pessimistic policy that maximizes worst-case revenue and an opportunistic policy that minimizes worst-case regret. These rules are tailored to a sequential no-coverage environment and are not direct extensions of existing pessimistic offline RL or static opportunistic approaches. We establish finite-sample regret bounds for both policies, recovering the standard rate when the optimal price is covered and quantifying the additional cost when it is not. We also develop efficient algorithms and show, through simulations and an airline ticket application, that our methods outperform standard offline RL baselines in no-coverage settings. Managerially, the framework provides a practical mapping from a firm's risk posture to its pricing policy: firms seeking revenue stability and downside protection should prefer the pessimistic policy, whereas firms willing to bear measured risk for potential gains from underexplored prices should prefer the opportunistic policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a nonparametric partial identification framework for offline dynamic pricing under incomplete price coverage. Exploiting demand monotonicity to produce interval bounds on unobserved prices, it defines a pessimistic policy (maximizing worst-case revenue) and an opportunistic policy (minimizing worst-case regret). Finite-sample regret bounds are derived for both, recovering the standard rate when the optimal price is covered and quantifying the extra cost otherwise; efficient algorithms are provided and the methods are tested on simulations plus an airline-ticket application, where they outperform standard offline RL baselines.
Significance. If the regret bounds hold, the work supplies the first finite-sample guarantees for dynamic pricing in sequential no-coverage regimes and gives a direct mapping from a firm’s risk posture to policy choice. The nonparametric use of monotonicity, the clean split between covered and uncovered cases, and the reproducible simulation results constitute concrete strengths.
major comments (2)
- [§4] §4 (regret analysis): the finite-sample bound for the opportunistic policy when the optimum is uncovered is stated to be O(√(T log T) + extra term); the extra term’s dependence on the width of the partial-identification interval must be shown explicitly (e.g., via the length of the demand interval at the unobserved price) to confirm it is not an artifact of the proof technique.
- [§3.2] §3.2 (policy definitions): the opportunistic policy minimizes worst-case regret over the identified set; it is not immediate that this coincides with the static opportunistic rule of the literature, yet the text claims the rules are “not direct extensions.” An explicit side-by-side derivation or counter-example showing the difference in the dynamic recursion is needed.
minor comments (2)
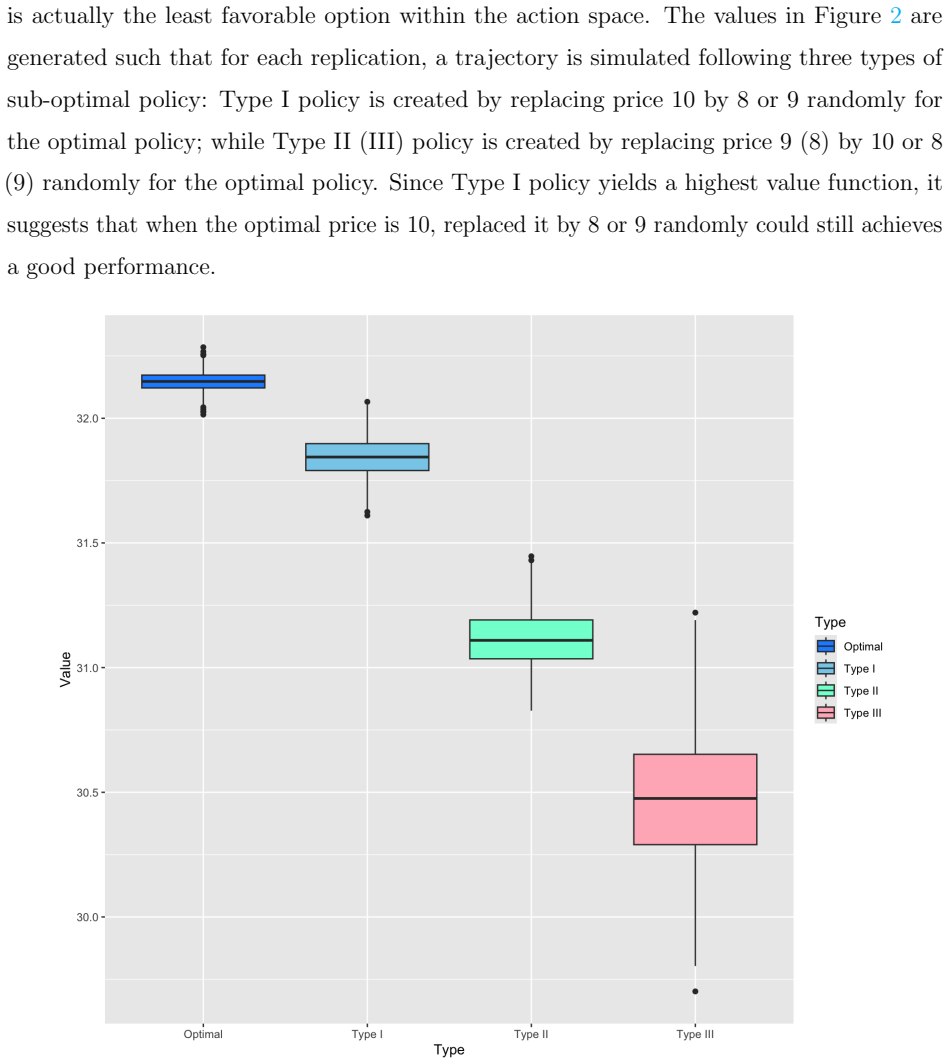
- [§5] The simulation section should report the precise data-exclusion rule used to create the no-coverage regime and the number of Monte-Carlo replications.
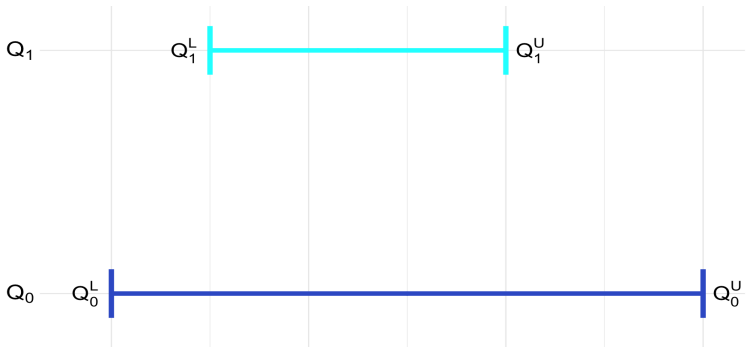
- [§2] Notation for the identified demand interval (e.g., [D̲(p), D̄(p)]) should be introduced once and used consistently; several passages still write “bounds on demand” without the interval symbols.
Simulated Author's Rebuttal
We thank the referee for the careful reading, the positive assessment of the contribution, and the recommendation for minor revision. We address each major comment below and will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (regret analysis): the finite-sample bound for the opportunistic policy when the optimum is uncovered is stated to be O(√(T log T) + extra term); the extra term’s dependence on the width of the partial-identification interval must be shown explicitly (e.g., via the length of the demand interval at the unobserved price) to confirm it is not an artifact of the proof technique.
Authors: We agree that an explicit dependence would strengthen the result. Re-inspecting the proof of Theorem 4.2, the extra term arises directly from the diameter of the demand interval at the unobserved price (via the partial-identification bounds on the value function). In the revision we will add a short corollary that isolates this dependence, expressing the additive term as a function of the interval length at the optimal price. This confirms the term is intrinsic to the partial-identification setting rather than an artifact. revision: yes
-
Referee: [§3.2] §3.2 (policy definitions): the opportunistic policy minimizes worst-case regret over the identified set; it is not immediate that this coincides with the static opportunistic rule of the literature, yet the text claims the rules are “not direct extensions.” An explicit side-by-side derivation or counter-example showing the difference in the dynamic recursion is needed.
Authors: We will supply the requested comparison. The dynamic opportunistic policy differs from the static rule because the identified set and the worst-case regret are updated recursively across periods; the static rule treats each period independently. In the revision we will add an appendix subsection containing (i) a side-by-side derivation of the two Bellman operators and (ii) a two-period counter-example in which the dynamic policy selects a different first-period action than the static rule when coverage is incomplete. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper develops a nonparametric partial-identification framework that invokes the standard monotonicity of demand in price to produce interval bounds on unobserved prices; the pessimistic and opportunistic policies are then defined directly on those intervals, and finite-sample regret bounds are obtained by case analysis on coverage of the optimal price. No equation or claim reduces by construction to a fitted parameter, self-citation, or renamed input; the monotonicity assumption is external and the regret derivation splits cleanly into covered/uncovered regimes without circular dependence on the policies themselves. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Demand is monotonic (non-increasing) in price
Reference graph
Works this paper leans on
-
[1]
Antos, A., Szepesv \'a ri, C., and Munos, R. (2008). Learning near-optimal policies with bellman-residual minimization based fitted policy iteration and a single sample path. Machine Learning , 71:89--129
work page 2008
-
[2]
Ban, G.-Y. (2020). Confidence intervals for data-driven inventory policies with demand censoring. Operations Research , 68(2):309--326
work page 2020
-
[3]
Ban, G.-Y. and Keskin, N. B. (2021). Personalized dynamic pricing with machine learning: High-dimensional features and heterogeneous elasticity. Management Science , 67(9):5549--5568
work page 2021
-
[4]
Bastani, H., Simchi-Levi, D., and Zhu, R. (2022). Meta dynamic pricing: Transfer learning across experiments. Management Science , 68(3):1865--1881
work page 2022
-
[5]
Bellman, R. (1957). A markovian decision process. Journal of Mathematics and Mechanics , 6(5):679--684
work page 1957
-
[6]
Bitran, G. and Caldentey, R. (2003). An overview of pricing models for revenue management. Manufacturing & Service Operations Management , 5(3):203--229
work page 2003
-
[7]
Broder, J. and Rusmevichientong, P. (2012). Dynamic pricing under a general parametric choice model. Operations Research , 60(4):965--980
work page 2012
-
[8]
Bu, J., Simchi-Levi, D., and Wang, L. (2023). Offline pricing and demand learning with censored data. Management Science , 69(2):885--903
work page 2023
- [9]
-
[10]
Chen, B., Chao, X., and Shi, C. (2021). Nonparametric learning algorithms for joint pricing and inventory control with lost sales and censored demand. Mathematics of Operations Research , 46(2):726--756
work page 2021
-
[11]
Chen, X. and Pouzo, D. (2012). Estimation of nonparametric conditional moment models with possibly nonsmooth generalized residuals. Econometrica , 80(1):277--321
work page 2012
- [12]
-
[13]
Christensen, T., Moon, H. R., and Schorfheide, F. (2022). Optimal discrete decisions when payoffs are partially identified. arXiv preprint arXiv:2204.11748
-
[14]
Cui, Y. (2021). Individualized Decision - Making Under Partial Identification : Three Perspectives , Two Optimality Results , and One Paradox . Harvard Data Science Review , 3(3)
work page 2021
-
[15]
Den Boer, A. V. (2014). Dynamic pricing with multiple products and partially specified demand distribution. Mathematics of operations research , 39(3):863--888
work page 2014
-
[16]
Den Boer, A. V. (2015). Dynamic pricing and learning: historical origins, current research, and new directions. Surveys in operations research and management science , 20(1):1--18
work page 2015
-
[17]
Elmachtoub, A. N. and Hamilton, M. L. (2021). The power of opaque products in pricing. Management Science , 67(8):4686--4702
work page 2021
-
[18]
Elmaghraby, W. and Keskinocak, P. (2003). Dynamic pricing in the presence of inventory considerations: Research overview, current practices, and future directions. Management science , 49(10):1287--1309
work page 2003
-
[19]
Farahmand, A.-m., Szepesv \'a ri, C., and Munos, R. (2010). Error propagation for approximate policy and value iteration. Advances in neural information processing systems , 23
work page 2010
-
[20]
Fujimoto, S., Meger, D., and Precup, D. (2019). Off-policy deep reinforcement learning without exploration. In International conference on machine learning , pages 2052--2062. PMLR
work page 2019
-
[21]
Gallego, G. and Van Ryzin, G. (1994). Optimal dynamic pricing of inventories with stochastic demand over finite horizons. Management science , 40(8):999--1020
work page 1994
-
[22]
Huh, W. T. and Rusmevichientong, P. (2009). A nonparametric asymptotic analysis of inventory planning with censored demand. Mathematics of Operations Research , 34(1):103--123
work page 2009
-
[23]
Javanmard, A. and Nazerzadeh, H. (2019). Dynamic pricing in high-dimensions. Journal of Machine Learning Research , 20(9):1--49
work page 2019
-
[24]
Jia, H., Shi, C., and Shen, S. (2024). Online learning and pricing for service systems with reusable resources. Operations Research , 72(3):1203--1241
work page 2024
-
[25]
Jin, Y., Yang, Z., and Wang, Z. (2021). Is pessimism provably efficient for offline rl? In International Conference on Machine Learning , pages 5084--5096. PMLR
work page 2021
-
[26]
Keskin, N. B. and Zeevi, A. (2014). Dynamic pricing with an unknown demand model: Asymptotically optimal semi-myopic policies. Operations research , 62(5):1142--1167
work page 2014
- [27]
-
[28]
Kosorok, M. R. and Moodie, E. E. M. (2015). Adaptive treatment strategies in practice: planning trials and analyzing data for personalized medicine . Society for Industrial and Applied Mathematics, Philadelphia, PA
work page 2015
-
[29]
Levi, R., Roundy, R. O., and Shmoys, D. B. (2007). Provably near-optimal sampling-based policies for stochastic inventory control models. Mathematics of Operations Research , 32(4):821--839
work page 2007
-
[30]
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[31]
Liao, P., Qi, Z., Wan, R., Klasnja, P., and Murphy, S. A. (2022). Batch policy learning in average reward markov decision processes. Annals of statistics , 50(6):3364
work page 2022
-
[32]
Lin, K. Y. (2006). Dynamic pricing with real-time demand learning. European Journal of Operational Research , 174(1):522--538
work page 2006
-
[33]
Ma, W., Simchi-Levi, D., and Zhao, J. (2021). Dynamic pricing (and assortment) under a static calendar. Management Science , 67(4):2292--2313
work page 2021
-
[34]
Manski, C. F. (2005). Social choice with partial knowledge of treatment response , volume 1. Princeton University Press
work page 2005
-
[35]
Manski, C. F. (2007). Minimax-regret treatment choice with missing outcome data. Journal of Econometrics , 139(1):105--115
work page 2007
-
[36]
Masten, M. A. (2023). Minimax-regret treatment rules with many treatments. The Japanese Economic Review , 74(4):501--537
work page 2023
-
[37]
Munos, R. and Szepesv \'a ri, C. (2008). Finite-time bounds for fitted value iteration. Journal of Machine Learning Research , 9(5)
work page 2008
-
[38]
Murphy, S. A. (2003). Optimal dynamic treatment regimes. Journal of the Royal Statistical Society: Series B , 65(2):331--355
work page 2003
-
[39]
Nambiar, M., Simchi-Levi, D., and Wang, H. (2019). Dynamic learning and pricing with model misspecification. Management Science , 65(11):4980--5000
work page 2019
-
[40]
Puterman, M. L. (2014). Markov decision processes: discrete stochastic dynamic programming . John Wiley & Sons
work page 2014
-
[41]
Qi, Z., Tang, J., Fang, E., and Shi, C. (2022). Offline personalized pricing with censored demand. In Technical Report . [Sl]: SSRN
work page 2022
-
[42]
Qin, H., Simchi-Levi, D., and Wang, L. (2022). Data-driven approximation schemes for joint pricing and inventory control models. Management Science , 68(9):6591--6609
work page 2022
-
[43]
Robins, J. M. (2004). Optimal structural nested models for optimal sequential decisions. In Lin, D. Y. and Heagerty, P., editors, Proceedings of the Second Seattle Symposium in Biostatistics , pages 189--326, New York. Springer
work page 2004
-
[44]
Savage, L. J. (1951). The theory of statistical decision. Journal of the American Statistical association , 46(253):55--67
work page 1951
-
[45]
Shi, C., Qi, Z., Wang, J., and Zhou, F. (2023). Value enhancement of reinforcement learning via efficient and robust trust region optimization. Journal of the American Statistical Association , pages 1--15
work page 2023
-
[46]
Silver, D., Huang, A., et al. (2016). Mastering the game of go with deep neural networks and tree search. nature , 529(7587):484--489
work page 2016
-
[47]
Stoye, J. (2009). Minimax regret treatment choice with finite samples. Journal of Econometrics , 151(1):70--81
work page 2009
-
[48]
Stoye, J. (2012). Minimax regret treatment choice with covariates or with limited validity of experiments. Journal of Econometrics , 166(1):138--156
work page 2012
-
[49]
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learning: An introduction . MIT press
work page 2018
-
[50]
Y., Levine, S., Finn, C., and Ma, T
Yu, T., Thomas, G., Yu, L., Ermon, S., Zou, J. Y., Levine, S., Finn, C., and Ma, T. (2020). Mopo: Model-based offline policy optimization. Advances in Neural Information Processing Systems , 33:14129--14142
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.