Fusing Transferred Priors and Physics-based Decomposition for Underwater Image Enhancement
Pith reviewed 2026-06-27 03:58 UTC · model grok-4.3
The pith
Underwater image enhancement works without paired labels by splitting the problem into physics steps and supervising each with priors transferred from other vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
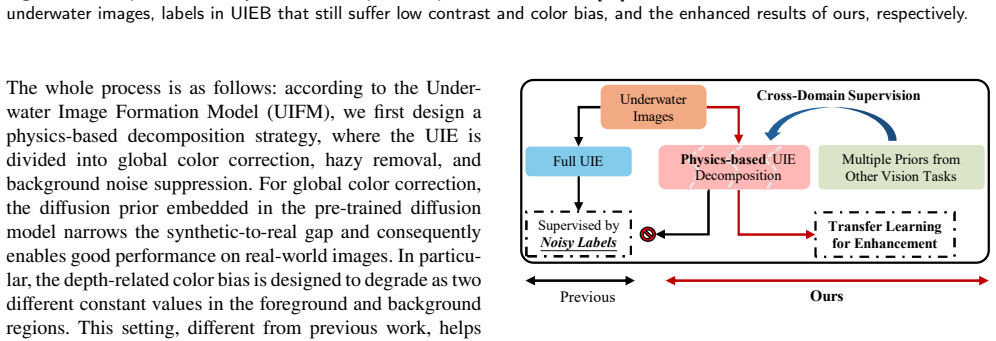
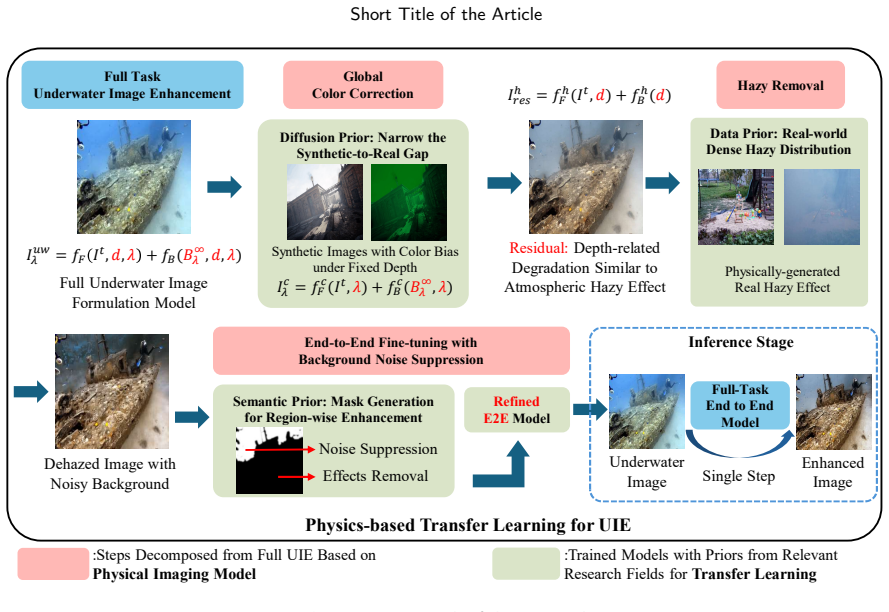
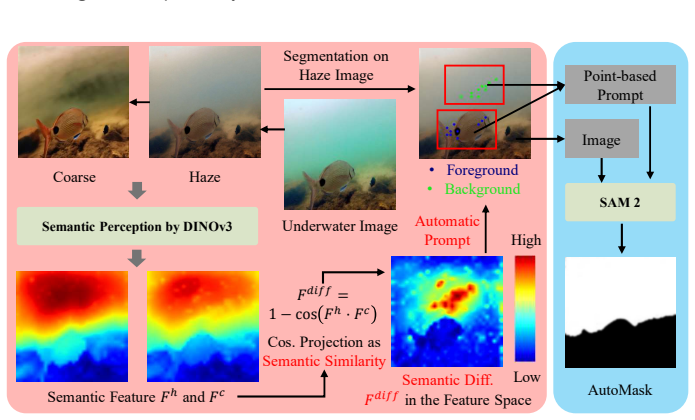
The central claim is that dividing underwater image enhancement into global color correction, haze removal, and background noise suppression, then solving each step with cross-domain priors transferred from other vision tasks, produces a label-free method that reaches state-of-the-art results on the UIE task and improves downstream vision performance.
What carries the argument
Physics-aligned decomposition of underwater degradation into global color correction, haze removal, and background noise suppression, supervised at each stage by transferred priors from other vision tasks.
If this is right
- The method achieves state-of-the-art quantitative and qualitative performance on standard UIE benchmarks.
- Enhanced images improve accuracy on downstream tasks such as object detection or segmentation compared with benchmark UIE methods.
- The approach requires no paired underwater labels during training.
- The physics decomposition supplies theoretical soundness to the overall pipeline.
Where Pith is reading between the lines
- The same decomposition-plus-transfer pattern could be tested on other media-specific degradations where physical models exist but paired data do not.
- Success would imply that many restoration problems currently limited by label noise could be reframed as sequences of simpler, cross-supervised sub-tasks.
- If the priors transfer reliably, the method may reduce the need for large domain-specific datasets in underwater and similar imaging settings.
Load-bearing premise
The three physical steps capture the dominant underwater degradations and priors from other domains supply useful supervision without needing any domain-specific adaptation or fine-tuning.
What would settle it
Quantitative comparison on a dataset of real underwater images that also possess corresponding clean reference images captured under controlled conditions, measuring whether the method's output metrics exceed those of label-dependent baselines.
Figures
















read the original abstract
The underwater images are captured within diverse water-medium conditions, leading to complex degradation, including color bias, low contrast, and blur effect. Recently, learning-based methods have demonstrated their potential for underwater image enhancement (UIE). However, most of the previous work focus on the training strategy or network design to make the enhanced result aligned well with the labels in datasets, ignoring that the labels are selected from the enhanced results of previous UIE methods and these pseudo-labels are noisy. Consequently, the performance of their models is not satisfactory to a certain extent. However, collecting the true labels of the underwater images is challenging. In this work, we propose a transfer learning-based UIE that does not require underwater images to have paired noisy or true labels for learning. Instead, the UIE task is first divided into global color correction, haze removal, and background noise suppression following the underwater physics. Then multiple types of prior from other vision tasks are leveraged as cross-domain supervision in each step. In this way, a novel UIE is available via transfer learning, and the physics-aligned UIE decomposition provides theoretical soundness. Qualitative and quantitative experiments demonstrate that our proposal based on physics and priors fusion achieves SOTA performance in the UIE task and effectively boosts downstream vision tasks, significantly outperforming benchmark methods. Project repo: https://github.com/Haru2022/P2-UIE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a transfer learning approach for underwater image enhancement (UIE) that decomposes the task into three steps—global color correction, haze removal, and background noise suppression—based on underwater physics, and uses priors transferred from other vision tasks as supervision for each step without requiring paired underwater labels. It claims this yields theoretically sound results and achieves SOTA performance on UIE and downstream tasks.
Significance. If the decomposition accurately models the physics and the priors transfer effectively, the method could provide a label-free alternative to supervised UIE methods that rely on noisy pseudo-labels, potentially improving generalization and performance in real underwater scenarios.
major comments (2)
- [Abstract] Abstract: The assertion that the decomposition into global color correction, haze removal, and background noise suppression accurately captures the dominant physical effects and provides theoretical soundness is not supported by explicit comparison to the standard Jaffe-McGlamery underwater image formation model, which couples color attenuation, scattering, and transmission in a single equation; this risks unmodeled cross-effects (e.g., color-dependent scattering) that independent cross-domain priors would not correct.
- [Method] Method description: The paper must show that the composition of the three modules reconstructs the full degradation operator; without this verification, the transfer-learning argument that priors can supervise each step independently collapses, undermining attribution of any SOTA gains to the physics-prior fusion.
minor comments (1)
- [Abstract] Abstract: The claim of SOTA performance via qualitative and quantitative experiments is stated without any numerical results, specific baselines, dataset names, or metrics, which reduces the ability to evaluate the central claim from the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments regarding the theoretical grounding of our physics-based decomposition. We respond to each major comment below and will revise the manuscript accordingly to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the decomposition into global color correction, haze removal, and background noise suppression accurately captures the dominant physical effects and provides theoretical soundness is not supported by explicit comparison to the standard Jaffe-McGlamery underwater image formation model, which couples color attenuation, scattering, and transmission in a single equation; this risks unmodeled cross-effects (e.g., color-dependent scattering) that independent cross-domain priors would not correct.
Authors: We agree that the current abstract and manuscript lack an explicit side-by-side comparison to the Jaffe-McGlamery model. Our decomposition separates the dominant effects (wavelength-dependent absorption for color bias, scattering for haze, and additive noise) to enable independent cross-domain prior supervision, which is a practical approximation used in much of the UIE literature. To directly address the risk of unmodeled cross-effects, we will add a new subsection in the revised manuscript that compares our decomposition to the standard model, discusses potential interactions such as color-dependent scattering, and notes the approximation's limitations. revision: yes
-
Referee: [Method] Method description: The paper must show that the composition of the three modules reconstructs the full degradation operator; without this verification, the transfer-learning argument that priors can supervise each step independently collapses, undermining attribution of any SOTA gains to the physics-prior fusion.
Authors: The current manuscript motivates the three-module decomposition from underwater physics but does not include a formal verification that their composition exactly inverts the full degradation operator. The independent prior supervision is presented as valid because each module targets a separable physical component. We will revise the method section to include verification of the composition, for example by applying the modules to synthetically degraded images generated from a forward model and measuring reconstruction fidelity, thereby supporting the attribution of gains to the physics-prior approach. revision: yes
Circularity Check
No circularity: decomposition and priors are external to fitted data
full rationale
The paper asserts a physics-based decomposition of UIE into global color correction, haze removal, and background noise suppression, then applies cross-domain priors as supervision without paired underwater labels. No equations, derivations, or fitted parameters are shown that reduce any output to quantities defined from the same data or self-citations. The method is presented as relying on external priors and standard underwater physics references, with no load-bearing self-citation chains or self-definitional steps visible in the abstract or description. This is the common case of a self-contained proposal whose central claims rest on independent assumptions rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dense-haze:A benchmarkforimagedehazingwithdense-hazeandhaze-freeimages, in: 2019 IEEE international conference on image processing (ICIP), IEEE
Ancuti,C.O.,Ancuti,C.,Sbert,M.,Timofte,R.,2019. Dense-haze:A benchmarkforimagedehazingwithdense-hazeandhaze-freeimages, in: 2019 IEEE international conference on image processing (ICIP), IEEE. pp. 1014–1018
2019
-
[2]
A computational approach to edge detection
Canny, J., 2009. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence , 679–698
2009
-
[3]
Cao, J., Zeng, Z., Zhang, X., Zhang, H., Fan, C., Jiang, G., Lin, W.,
-
[4]
Pattern Recognition 162, 111395
Unveilingtheunderwaterworld:Clipperceptionmodel-guided underwater image enhancement. Pattern Recognition 162, 111395
-
[5]
Underwater image enhancement by wavelengthcompensationanddehazing
Chiang, J.Y., Chen, Y.C., 2011. Underwater image enhancement by wavelengthcompensationanddehazing. IEEEtransactionsonimage processing 21, 1756–1769
2011
-
[6]
Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators
Cong, R., Yang, W., Zhang, W., Li, C., Guo, C.L., Huang, Q., Kwong, S., 2023. Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators. IEEE Transactions on Image Processing 32, 4472–4485. First Author et al.:Preprint submitted to ElsevierPage 18 of 20 Short Title of the Article
2023
-
[7]
Cong, Z., Zhou, Y., Wu, L., Tian, L., Chen, Z., Guan, M., He, L.,
-
[8]
InformationFusion,103732
Pgf-net: Fusing a physical imaging model with self-attention forrobustunderwaterfeaturedetection. InformationFusion,103732
-
[9]
Underwater depth estimation and image restoration based on single images
Drews,P.L.,Nascimento,E.R.,Botelho,S.S.,Campos,M.F.M.,2016. Underwater depth estimation and image restoration based on single images. IEEE computer graphics and applications 36, 24–35
2016
-
[10]
Fine-tuning image-conditional diffusion models is easier than you think, in: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE
Garcia, G.M., Abou Zeid, K., Schmidt, C., De Geus, D., Hermans, A., Leibe, B., 2025. Fine-tuning image-conditional diffusion models is easier than you think, in: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE. pp. 753–762
2025
-
[11]
A survey on under- water computer vision
González-Sabbagh, S.P., Robles-Kelly, A., 2023. A survey on under- water computer vision. ACM Computing Surveys 55, 1–39
2023
-
[12]
Underwater ranker: Learn which is better and how to be better, in: Proceedings of the AAAI conference on artificial intelligence, pp
Guo, C., Wu, R., Jin, X., Han, L., Zhang, W., Chai, Z., Li, C., 2023. Underwater ranker: Learn which is better and how to be better, in: Proceedings of the AAAI conference on artificial intelligence, pp. 702–709
2023
-
[13]
Uw-gan: Single-image depth estimation and image enhancement for underwater images
Hambarde, P., Murala, S., Dhall, A., 2021. Uw-gan: Single-image depth estimation and image enhancement for underwater images. IEEE Transactions on Instrumentation and Measurement 70, 1–12
2021
-
[14]
Denoising diffusion probabilistic models
Ho, J., Jain, A., Abbeel, P., 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33, 6840–6851
2020
-
[15]
Underwater sequential images enhancement via diffusion and physics priors fusion
Hu, H., Bin, Y., Wen, C.y., Wang, B., 2025. Underwater sequential images enhancement via diffusion and physics priors fusion. Infor- mation Fusion , 103365
2025
-
[16]
Contrastivesemi- supervised learning for underwater image restoration via reliable bank, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Huang,S.,Wang,K.,Liu,H.,Chen,J.,Li,Y.,2023. Contrastivesemi- supervised learning for underwater image restoration via reliable bank, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18145–18155
2023
-
[17]
Fastunderwaterimageenhance- mentforimprovedvisualperception
Islam,M.J.,Xia,Y.,Sattar,J.,2020. Fastunderwaterimageenhance- mentforimprovedvisualperception. IEEERoboticsandAutomation Letters 5, 3227–3234
2020
-
[18]
Computer modeling and the design of optimal underwater imaging systems
Jaffe, J.S., 1990. Computer modeling and the design of optimal underwater imaging systems. IEEE Journal of Oceanic Engineering 15, 101–111
1990
-
[19]
Image enhancement via associated perturbation removal and texture reconstructionlearning
Jiang, K., Wang, R., Xiao, Y., Jiang, J., Xu, X., Lu, T., 2024. Image enhancement via associated perturbation removal and texture reconstructionlearning. IEEE/CAAJournalofAutomaticaSinica11, 2253–2269
2024
-
[20]
Jiang, K., Wang, Z., Wang, Z., Chen, C., Yi, P., Lu, T., Lin, C.W.,
-
[21]
1078–1086
Degrade is upgrade: Learning degradation for low-light image enhancement, in: Proceedings of the AAAI conference on artificial intelligence, pp. 1078–1086
-
[22]
5148–5157
Ke,J.,Wang,Q.,Wang,Y.,Milanfar,P.,Yang,F.,2021.Musiq:Multi- scale image quality transformer, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 5148–5157
2021
-
[23]
Rad:Region-awarediffusionmodels for image inpainting, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp
Kim,S.,Suh,S.,Lee,M.,2025. Rad:Region-awarediffusionmodels for image inpainting, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 2439–2448
2025
-
[24]
Underwater scene prior inspired deep underwater image and video enhancement
Li, C., Anwar, S., Porikli, F., 2020. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognition 98, 107038
2020
-
[25]
An underwater image enhancement benchmark dataset and beyond
Li,C.,Guo,C.,Ren,W.,Cong,R.,Hou,J.,Kwong,S.,Tao,D.,2019. An underwater image enhancement benchmark dataset and beyond. IEEE transactions on image processing 29, 4376–4389
2019
-
[26]
Underwater image captioning via attention mechanism based fusion of visual and textual information
Li, L., Li, H., Ren, P., 2025a. Underwater image captioning via attention mechanism based fusion of visual and textual information. Information Fusion , 103269
-
[27]
S2g-gcn: A plot classi- fication network integrating spectrum-to-graph modeling and graph convolutional network for compact hfswr
Li, X., Sun, W., Ji, Y., Huang, W., 2025b. S2g-gcn: A plot classi- fication network integrating spectrum-to-graph modeling and graph convolutional network for compact hfswr. IEEE Geoscience and Remote Sensing Letters
-
[28]
A visual-textual mutual guidance fusion network for remote sensing visual question answering
Liu,H.,Chen,L.,Lu,X.,Wang,H.,Bai,L.,Wang,M.,Ren,P.,2026. A visual-textual mutual guidance fusion network for remote sensing visual question answering. Pattern Recognition 176, 113258
2026
-
[29]
Underwater imageenhancementwithcascadedcontrastivelearning
Liu, Y., Jiang, Q., Wang, X., Luo, T., Zhou, J., 2024. Underwater imageenhancementwithcascadedcontrastivelearning. IEEETrans- actions on Multimedia
2024
-
[30]
From synthetic to real: Image dehazing collaborating with unlabeled real data, in: Proceedings of the 29th ACM international conference on multimedia, pp
Liu, Y., Zhu, L., Pei, S., Fu, H., Qin, J., Zhang, Q., Wan, L., Feng, W., 2021. From synthetic to real: Image dehazing collaborating with unlabeled real data, in: Proceedings of the 29th ACM international conference on multimedia, pp. 50–58
2021
-
[31]
Distinctive image features from scale-invariant keypoints
Lowe, D.G., 2004. Distinctive image features from scale-invariant keypoints. International journal of computer vision 60, 91–110
2004
-
[32]
Visual-instructed degradation diffusion for all-in-one imagerestoration,in:ProceedingsoftheComputerVisionandPattern Recognition Conference, pp
Luo,W.,Qin,H.,Chen,Z.,Wang,L.,Zheng,D.,Li,Y.,Liu,Y.,Li,B., Hu, W., 2025. Visual-instructed degradation diffusion for all-in-one imagerestoration,in:ProceedingsoftheComputerVisionandPattern Recognition Conference, pp. 12764–12777
2025
-
[33]
A computer model for underwater camera systems, in: Ocean Optics VI, SPIE
McGlamery, B., 1980. A computer model for underwater camera systems, in: Ocean Optics VI, SPIE. pp. 221–231
1980
-
[34]
Dpf-net: Physical imaging model embedded data-driven underwater image enhance- ment
Mei, H., Li, K., Liu, S., Ma, C., Jiang, Q., 2025. Dpf-net: Physical imaging model embedded data-driven underwater image enhance- ment. ISPRS Journal of Photogrammetry and Remote Sensing 228, 679–693
2025
-
[35]
Bi-level inter- modality modulation for unsupervised visible-infrared person re- identification
Peng, J., Liu, J., Zuo, X., Tao, Z., Wang, H., 2026. Bi-level inter- modality modulation for unsupervised visible-infrared person re- identification. IEEE Transactions on Information Forensics and Security
2026
-
[36]
Adaptive dual-domain learning for under- water image enhancement, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp
Peng, L., Bian, L., 2025. Adaptive dual-domain learning for under- water image enhancement, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 6461–6469
2025
-
[37]
U-shapetransformerforunderwater image enhancement
Peng,L.,Zhu,C.,Bian,L.,2023. U-shapetransformerforunderwater image enhancement. IEEE Transactions on Image Processing 32, 3066–3079
2023
-
[38]
Ce-vae: Capsule enhanced variational autoencoderforunderwaterimageenhancement,in:2025IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE
Pucci, R., Martinel, N., 2025. Ce-vae: Capsule enhanced variational autoencoderforunderwaterimageenhancement,in:2025IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE. pp. 2113–2123
2025
-
[39]
Underwaterimageco-enhancementwithcorrelationfeaturematching and joint learning
Qi,Q.,Zhang,Y.,Tian,F.,Wu,Q.J.,Li,K.,Luan,X.,Song,D.,2021. Underwaterimageco-enhancementwithcorrelationfeaturematching and joint learning. IEEE Transactions on Circuits and Systems for Video Technology 32, 1133–1147
2021
-
[40]
Sam 2: Segment anything in images and videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al., 2024. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714
Pith/arXiv arXiv 2024
-
[41]
High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Rombach,R.,Blattmann,A.,Lorenz,D.,Esser,P.,Ommer,B.,2022. High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695
2022
-
[42]
Recoveryof underwatervisibility and structure by polarization analysis
Schechner,Y.Y., Karpel,N.,2005. Recoveryof underwatervisibility and structure by polarization analysis. IEEE Journal of oceanic engineering 30, 570–587
2005
-
[43]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.,
- [44]
-
[45]
The replica dataset: A digital replica of indoor spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al., 2019. The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797
Pith/arXiv arXiv 2019
-
[46]
Varghese, N., Kumar, A., Rajagopalan, A., 2023. Self-supervised monocular underwater depth recovery, image restoration, and a real- sea video dataset, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12248–12258
2023
-
[47]
Tensorized parameter-free multi-view spectral clustering based on fair representation learning
Wang, H., Chen, Y., Yao, M., Liu, Q., Jiang, G., Fu, X., 2026a. Tensorized parameter-free multi-view spectral clustering based on fair representation learning. IEEE Transactions on Multimedia
-
[48]
Tensorized fine-grained incompletemultiviewclusteringviaintrinsicstructurerecovery.IEEE Transactions on Systems, Man, and Cybernetics: Systems
Wang, H., Cui, L., Yao, M., Fu, X., 2026b. Tensorized fine-grained incompletemultiviewclusteringviaintrinsicstructurerecovery.IEEE Transactions on Systems, Man, and Cybernetics: Systems
-
[49]
Watercycledif- fusion: Visual-textual fusion empowered underwater image enhance- ment
Wang, H., Zhang, W., Xu, Y., Li, H., Ren, P., 2025. Watercycledif- fusion: Visual-textual fusion empowered underwater image enhance- ment. Information Fusion , 103693
2025
-
[50]
Tartanair: A dataset to push the limitsofvisualslam,in:2020IEEE/RSJInternationalConferenceon Intelligent Robots and Systems (IROS), IEEE
Wang, W., Zhu, D., Wang, X., Hu, Y., Qiu, Y., Wang, C., Hu, Y., Kapoor, A., Scherer, S., 2020. Tartanair: A dataset to push the limitsofvisualslam,in:2020IEEE/RSJInternationalConferenceon Intelligent Robots and Systems (IROS), IEEE. pp. 4909–4916. First Author et al.:Preprint submitted to ElsevierPage 19 of 20 Short Title of the Article
2020
-
[51]
Multi-axis feature diversity enhancement for remote sensing video super-resolution
Xiao, Y., Yuan, Q., Jiang, K., Chen, Y., Wang, S., Lin, C.W., 2025. Multi-axis feature diversity enhancement for remote sensing video super-resolution. IEEE Transactions on Image Processing
2025
-
[52]
Ediffsr: An efficient diffusion probabilistic model for remote sensing image super-resolution
Xiao,Y.,Yuan,Q.,Jiang,K.,He,J.,Jin,X.,Zhang,L.,2023. Ediffsr: An efficient diffusion probabilistic model for remote sensing image super-resolution. IEEE Transactions on Geoscience and Remote Sensing 62, 1–14
2023
-
[53]
Xie, Y., Kong, L., Chen, K., Zheng, Z., Yu, X., Yu, Z., Zheng, B., 2024.Uveb:Alarge-scalebenchmarkandbaselinetowardsreal-world underwater video enhancement, in: Proceedings of the IEEE/CVF ConferenceonComputerVisionandPatternRecognition,pp.22358– 22367
2024
-
[54]
Saliency detection via graph-based manifold ranking, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Yang, C., Zhang, L., Lu, H., Ruan, X., Yang, M.H., 2013. Saliency detection via graph-based manifold ranking, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3166–3173
2013
-
[55]
Ying,Z.,Niu,H.,Gupta,P.,Mahajan,D.,Ghadiyaram,D.,Bovik,A.,
-
[56]
3575–3585
From patches to pictures (paq-2-piq): Mapping the perceptual spaceofpicturequality,in:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition, pp. 3575–3585
-
[57]
Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement
Zhang, W., Zhuang, P., Sun, H.H., Li, G., Kwong, S., Li, C., 2022. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Transactions on Image Pro- cessing 31, 3997–4010
2022
-
[58]
Zhao, C., Cai, W., Dong, C., Hu, C., 2024. Wavelet-based fourier in- formation interaction with frequency diffusion adjustment for under- waterimagerestoration,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pp. 8281–8291
2024
-
[59]
A novel underwater target tracking method in uasns via collaborative deep reinforcement learning
Zheng, L., Liu, M., Zhang, S., Dong, S., 2025. A novel underwater target tracking method in uasns via collaborative deep reinforcement learning. Information Fusion , 103797
2025
-
[60]
International Journal of Computer Vision 132, 4132–4156
Zhou, J., Sun, J., Li, C., Jiang, Q., Zhou, M., Lam, K.M., Zhang, W., Fu,X.,2024.Hclr-net:hybridcontrastivelearningregularizationwith locally randomized perturbation for underwater image enhancement. International Journal of Computer Vision 132, 4132–4156
2024
-
[61]
Underwater image enhancement with hyper-laplacian reflectance priors
Zhuang, P., Wu, J., Porikli, F., Li, C., 2022. Underwater image enhancement with hyper-laplacian reflectance priors. IEEE Trans- actions on Image Processing 31, 5442–5455. First Author et al.:Preprint submitted to ElsevierPage 20 of 20
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.