Fast & Faithful Function Vectors
Pith reviewed 2026-06-28 06:44 UTC · model grok-4.3
The pith
Layer-wise Relevance Propagation for head selection makes function vectors more efficient and accurate, and distributed steering outperforms aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
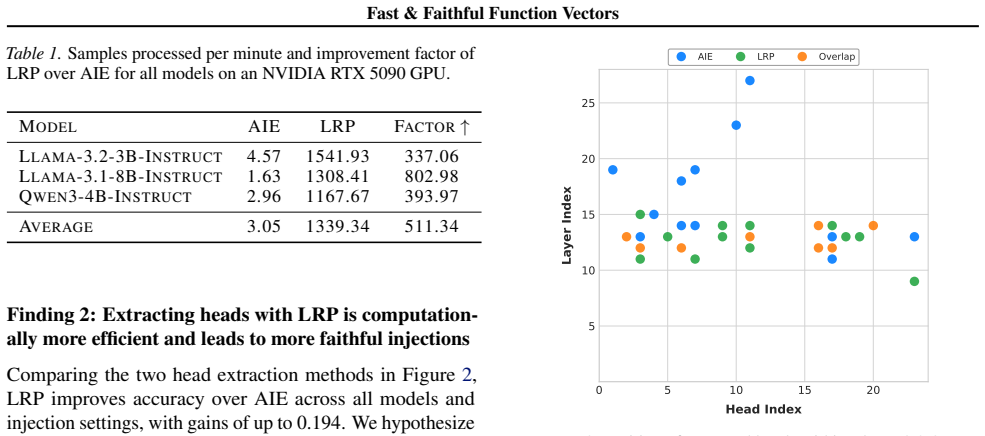
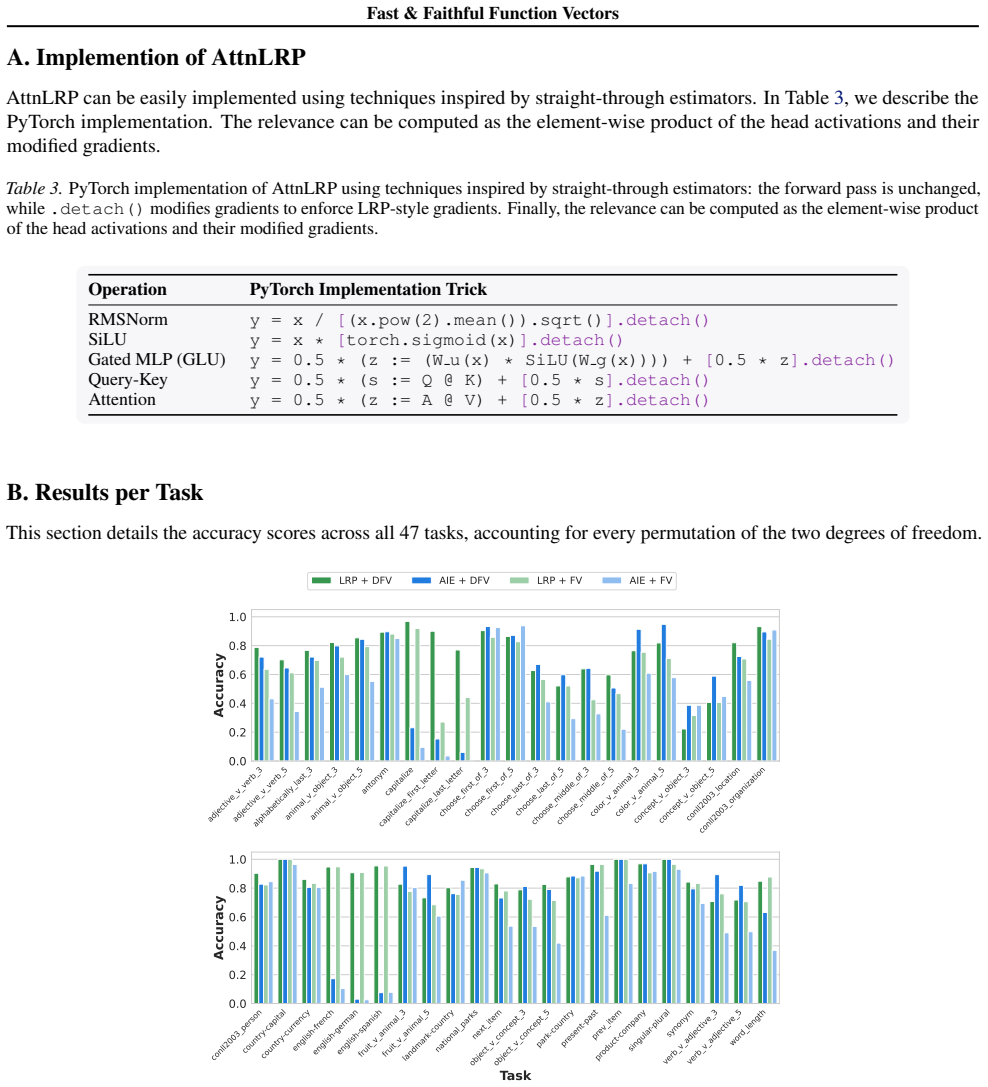
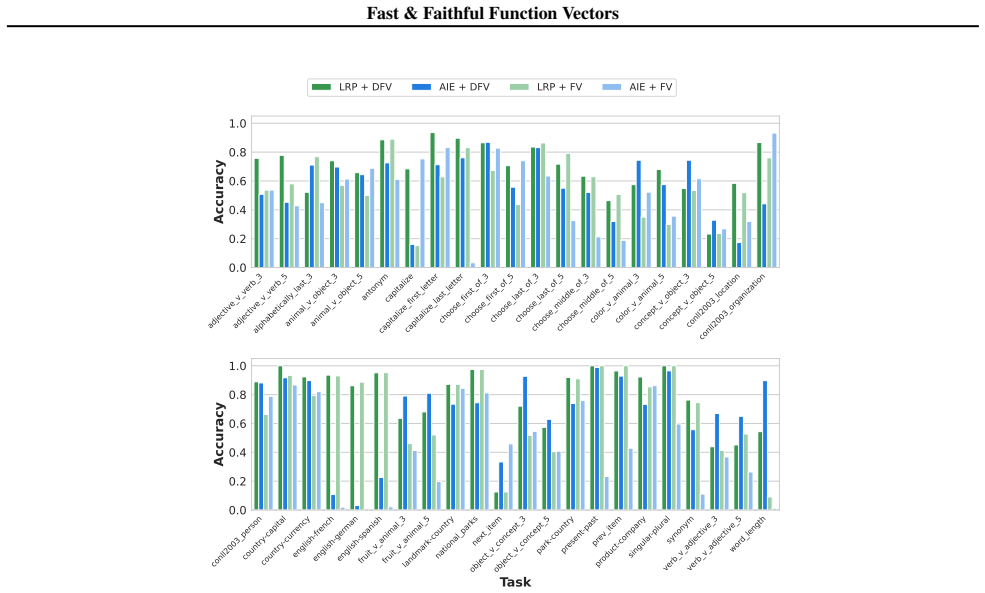
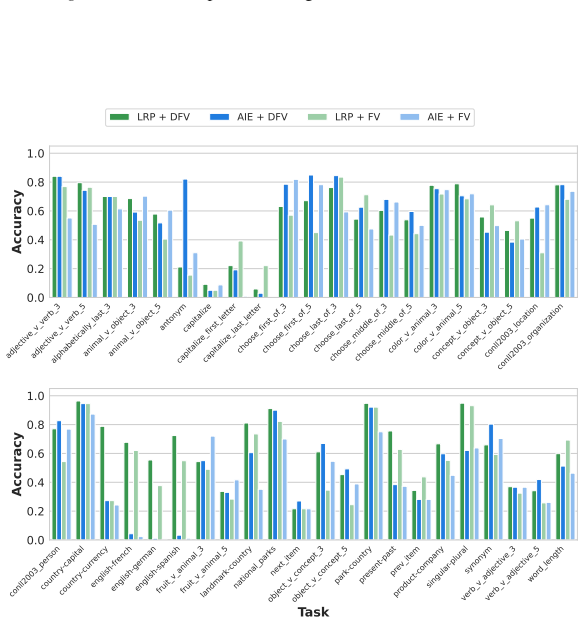
For head selection, using gradient-based attributions with Layer-wise Relevance Propagation (LRP) substantially improves efficiency as well as accuracy. For FV steering, applying it in a distributed manner yields a higher accuracy compared to simple aggregation.
What carries the argument
Function vectors as in-context task representations, modified by LRP-based attention head selection and distributed application of the steering signal.
If this is right
- Function vectors can be extracted with fewer heads while retaining or improving steering performance.
- Distributed steering produces stronger task control than vector addition across the same heads.
- The same attribution method can be reused to rank heads for other in-context tasks.
- Efficiency gains allow function-vector methods to run on longer contexts or larger models without proportional cost increase.
Where Pith is reading between the lines
- The same LRP ranking might identify useful heads even when the underlying model changes architecture or training data.
- Distributed steering could be combined with other attribution techniques to further reduce the number of active heads needed.
- If the efficiency improvement scales, function vectors might become practical for real-time steering in deployed chat systems.
Load-bearing premise
The measured gains in speed and accuracy arise from the LRP head selection and distributed steering rather than from differences in model size, task choice, or other unstated experimental details.
What would settle it
A controlled rerun of the head-selection and steering experiments that keeps every other variable fixed and finds no efficiency or accuracy lift from LRP or distributed application would falsify the central claims.
Figures


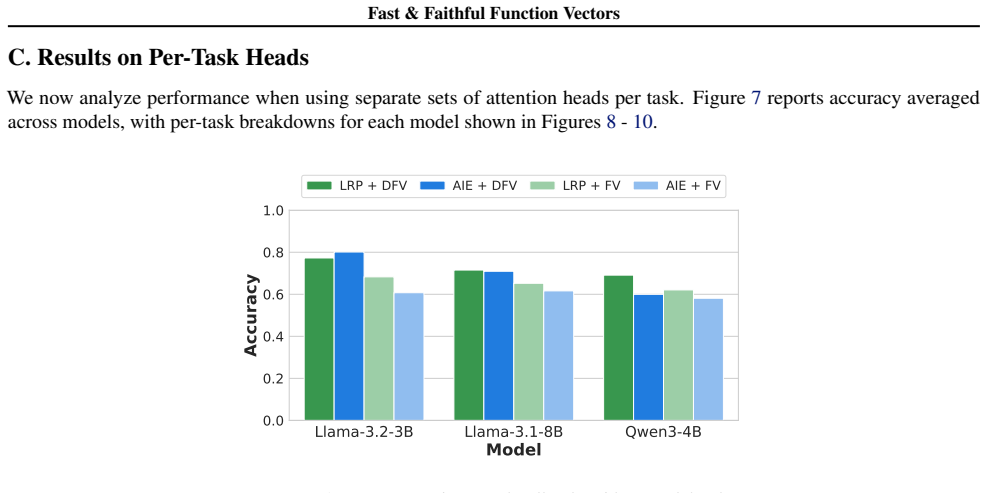

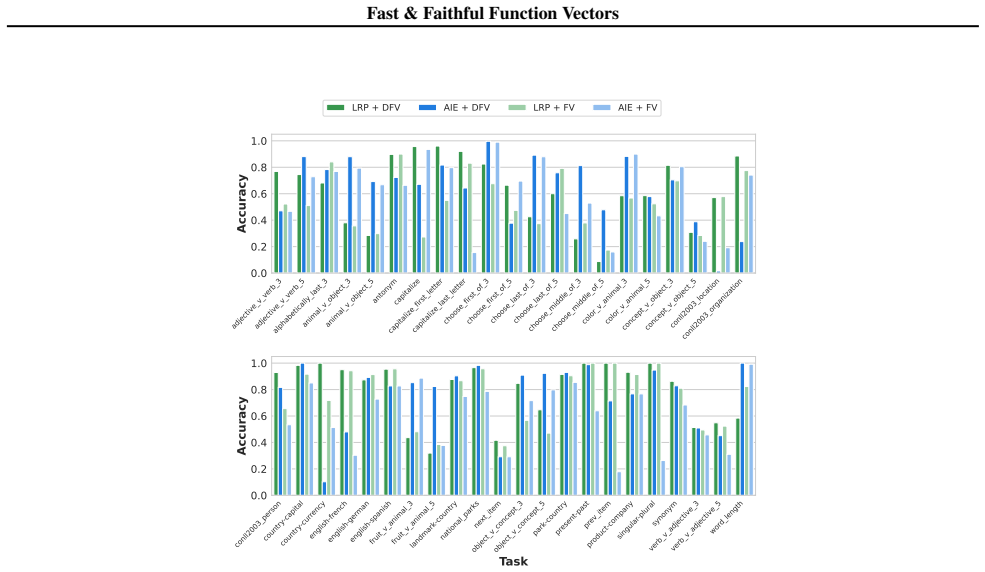

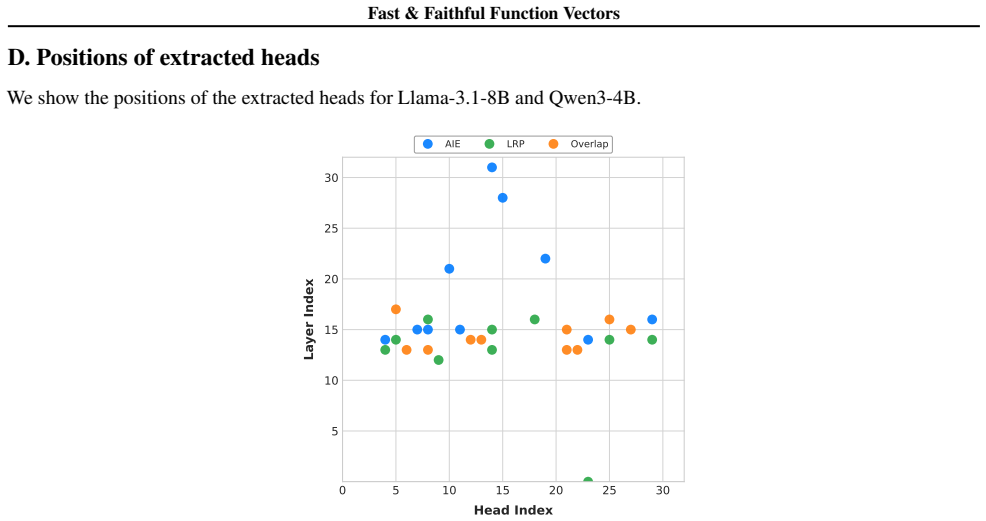
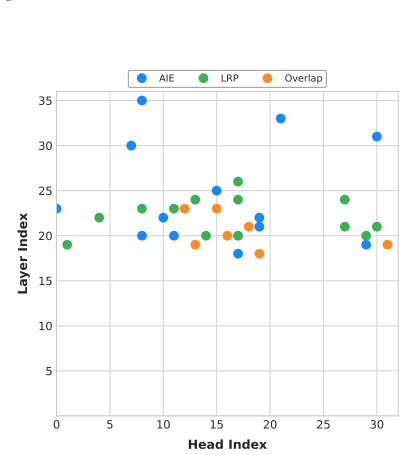
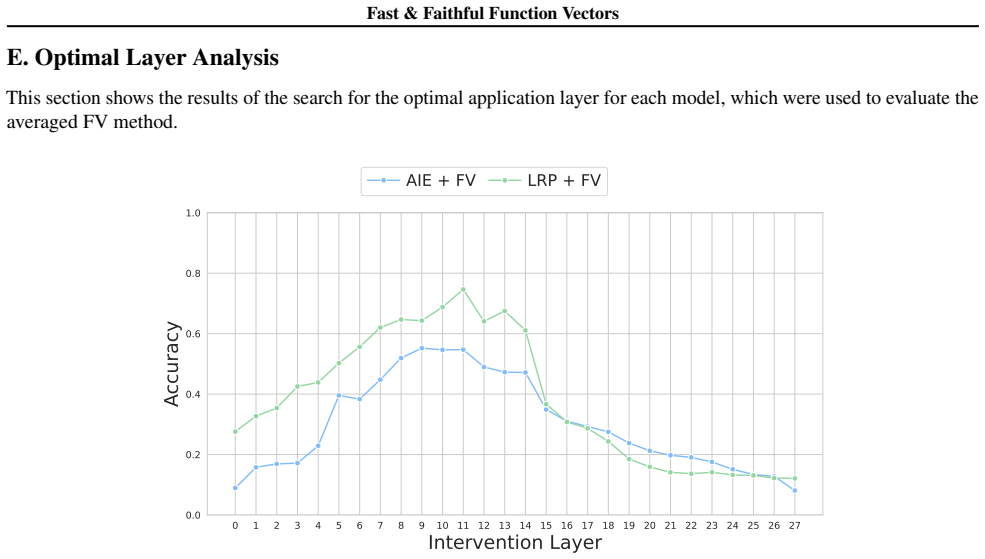
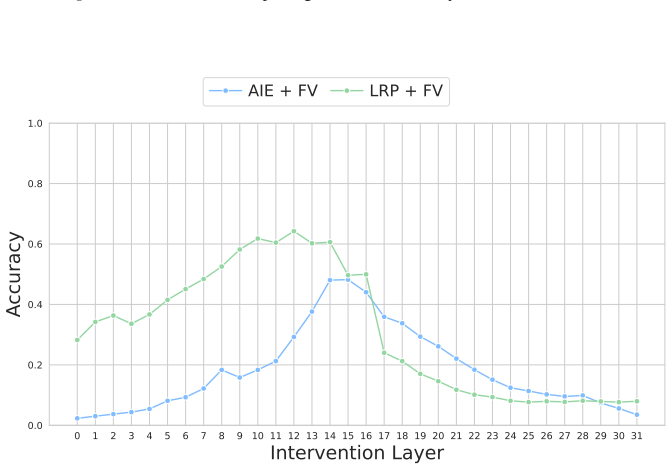

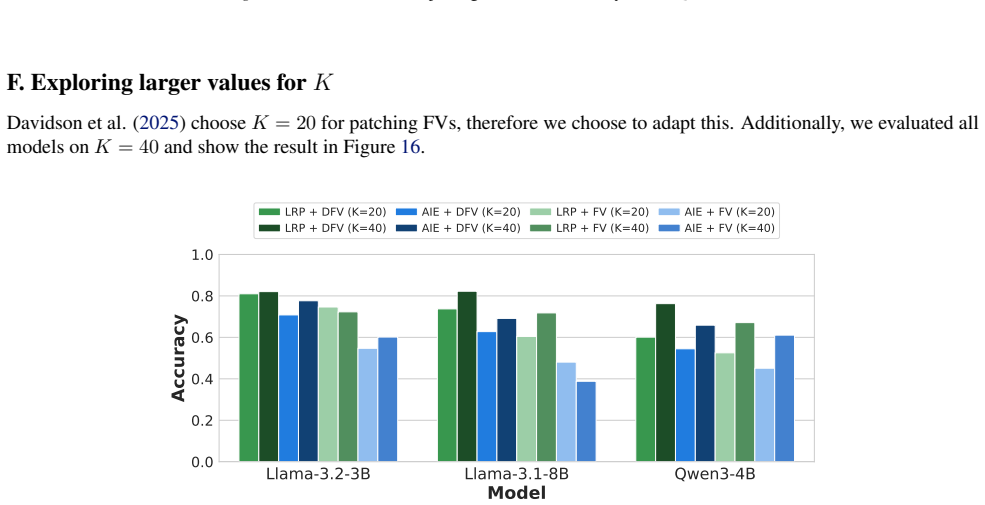
read the original abstract
Function vectors (FVs) are task representations elicited during in-context learning that can be used to steer Large Language Models (LLMs). However, design choices in their formulation remain underexplored. In this work, we study the impact of varying FV definitions for instructions along two degrees of freedom: attention head selection and steering. For head selection, using gradient-based attributions with Layer-wise Relevance Propagation (LRP) substantially improves efficiency as well as accuracy. For FV steering, applying it in a distributed manner yields a higher accuracy compared to simple aggregation. Our code is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on function vectors (FVs) for steering large language models during in-context learning. It varies FV definitions along two axes—attention head selection (using gradient-based attributions via Layer-wise Relevance Propagation) and steering application (distributed vs. simple aggregation)—and claims that LRP head selection improves both efficiency and accuracy while distributed steering improves accuracy over aggregation. Public code is provided.
Significance. If the reported gains are shown to be robustly attributable to the LRP and distributed-steering choices (rather than unisolated experimental variables), the work would provide practical guidance for more efficient and accurate FV steering and strengthen the empirical toolkit for analyzing in-context learning. Public code is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claims that LRP head selection 'substantially improves efficiency as well as accuracy' and that distributed steering 'yields a higher accuracy' are asserted without any numerical results, baselines, datasets, error bars, or statistical tests, so the magnitude and reliability of the improvements cannot be evaluated from the provided text.
- [Experimental sections] Experimental sections (head-selection and steering results): the central attribution of gains to LRP attributions and distributed application requires explicit controls or ablations for model scale, task distribution, prompt formatting, and aggregation hyperparameters. No such matched controls or tables isolating these factors are described, so the causal link to the design choices does not follow.
minor comments (1)
- [Abstract] Abstract: consider including at least summary metrics or improvement ranges to make the high-level claims more informative to readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that LRP head selection 'substantially improves efficiency as well as accuracy' and that distributed steering 'yields a higher accuracy' are asserted without any numerical results, baselines, datasets, error bars, or statistical tests, so the magnitude and reliability of the improvements cannot be evaluated from the provided text.
Authors: Abstracts are space-constrained and conventionally summarize findings at a high level. The manuscript body reports concrete numerical gains, baselines from prior FV work, multiple datasets, error bars over multiple runs, and statistical comparisons. We will revise the abstract to incorporate key quantitative results (e.g., accuracy deltas and efficiency metrics) while remaining within length limits. revision: partial
-
Referee: [Experimental sections] Experimental sections (head-selection and steering results): the central attribution of gains to LRP attributions and distributed application requires explicit controls or ablations for model scale, task distribution, prompt formatting, and aggregation hyperparameters. No such matched controls or tables isolating these factors are described, so the causal link to the design choices does not follow.
Authors: All reported comparisons hold model scale, task distribution, and prompt formatting fixed while varying only the head-selection method or the steering application (distributed vs. aggregation). Tables directly contrast LRP against random and gradient baselines under identical conditions. We nevertheless agree that dedicated ablations on aggregation hyperparameters would further isolate their contribution and will add a supplementary table or section with these controls. revision: yes
Circularity Check
No circularity: empirical comparison of existing FV techniques with no derivations or self-referential reductions
full rationale
The paper is framed as an empirical study of design choices in function vectors (head selection via LRP attributions, distributed vs. aggregated steering). No equations, derivations, fitted parameters, or predictions are described that could reduce to inputs by construction. Central claims rest on experimental comparisons rather than self-definition, self-citation chains, or renamed known results. This matches the default non-circular outcome for empirical work without load-bearing mathematical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2014 , organization=
Deep inside convolutional networks: visualising image classification models and saliency maps , author=. 2014 , organization=
2014
-
[2]
Proceedings of the 39th International Conference on Machine Learning , pages =
Ali, Ameen and Schnake, Thomas and Eberle, Oliver and Montavon, Gr. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[3]
Advances in neural information processing systems , volume=
Understanding and improving layer normalization , author=. Advances in neural information processing systems , volume=
-
[4]
2024 , editor =
Achtibat, Reduan and Hatefi, Sayed Mohammad Vakilzadeh and Dreyer, Maximilian and Jain, Aakriti and Wiegand, Thomas and Lapuschkin, Sebastian and Samek, Wojciech , booktitle =. 2024 , editor =
2024
-
[5]
PloS one , volume=
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation , author=. PloS one , volume=. 2015 , publisher=
2015
-
[6]
arXiv preprint arXiv:2502.15886 , year=
A close look at decomposition-based XAI-methods for transformer language models , author=. arXiv preprint arXiv:2502.15886 , year=
-
[7]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[8]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[9]
The Eleventh International Conference on Learning Representations , year=
What learning algorithm is in-context learning? Investigations with linear models , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
Proceedings of the 40th International Conference on Machine Learning , pages =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[11]
Do different prompting methods yield a common task representation in language models? , volume =
Davidson, Guy and Gureckis, Todd and Lake, Brenden and Williams, Adina , editor =. Do different prompting methods yield a common task representation in language models? , volume =. Advances in neural information processing systems , publisher =
-
[12]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[13]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[14]
International conference on learning representations , author =
Function vectors in large language models , volume =. International conference on learning representations , author =
-
[15]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[16]
Forty-second International Conference on Machine Learning , year=
Which Attention Heads Matter for In-Context Learning? , author=. Forty-second International Conference on Machine Learning , year=
-
[17]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[18]
In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems
Reynolds, Laria and McDonell, Kyle , title =. Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =. 2021 , isbn =. doi:10.1145/3411763.3451760 , abstract =
-
[19]
2025 , eprint=
The broader spectrum of in-context learning , author=. 2025 , eprint=
2025
-
[20]
Deep RNN s Encode Soft Hierarchical Syntax
Blevins, Terra and Levy, Omer and Zettlemoyer, Luke. Deep RNN s Encode Soft Hierarchical Syntax. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2003
-
[21]
What do Neural Machine Translation Models Learn about Morphology?
Belinkov, Yonatan and Durrani, Nadir and Dalvi, Fahim and Sajjad, Hassan and Glass, James. What do Neural Machine Translation Models Learn about Morphology?. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1080
-
[22]
The emergence of number and syntax units in LSTM language models
Lakretz, Yair and Kruszewski, German and Desbordes, Theo and Hupkes, Dieuwke and Dehaene, Stanislas and Baroni, Marco. The emergence of number and syntax units in LSTM language models. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Pa...
-
[23]
A Primer in BERT ology: What We Know About How BERT Works
Rogers, Anna and Kovaleva, Olga and Rumshisky, Anna. A Primer in BERT ology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00349
-
[24]
Liu, Matt Gardner, Yonatan Belinkov, Matthew E
Liu, Nelson F. and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E. and Smith, Noah A. Linguistic Knowledge and Transferability of Contextual Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi...
-
[25]
International Conference on Learning Representations , year=
What do you learn from context? Probing for sentence structure in contextualized word representations , author=. International Conference on Learning Representations , year=
-
[26]
Language Models as Knowledge Bases?
Petroni, Fabio and Rockt. Language Models as Knowledge Bases?. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1250
-
[27]
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
Roberts, Adam and Raffel, Colin and Shazeer, Noam. How Much Knowledge Can You Pack Into the Parameters of a Language Model?. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.437
-
[28]
Linguistic Regularities in Continuous Space Word Representations
Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey. Linguistic Regularities in Continuous Space Word Representations. Proceedings of the 2013 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013
2013
-
[29]
Csord \'a s, R \'o bert and Potts, Christopher and Manning, Christopher D and Geiger, Atticus. Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.17
-
[30]
Language Models Implement Simple W ord2 V ec-style Vector Arithmetic
Merullo, Jack and Eickhoff, Carsten and Pavlick, Ellie. Language Models Implement Simple W ord2 V ec-style Vector Arithmetic. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.281
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[33]
1941 , publisher =
The Library of Babel , author =. 1941 , publisher =
1941
-
[34]
2024 , eprint=
LLMs as Function Approximators: Terminology, Taxonomy, and Questions for Evaluation , author=. 2024 , eprint=
2024
-
[35]
François Chollet , title =
-
[36]
In-Context Learning Creates Task Vectors
Hendel, Roee and Geva, Mor and Globerson, Amir. In-Context Learning Creates Task Vectors. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.624
-
[37]
arXiv preprint arXiv:2508.21258 , year=
RelP: Faithful and Efficient Circuit Discovery in Language Models via Relevance Patching , author=. arXiv preprint arXiv:2508.21258 , year=
-
[38]
Attribution Patching Outperforms Automated Circuit Discovery
Syed, Aaquib and Rager, Can and Conmy, Arthur. Attribution Patching Outperforms Automated Circuit Discovery. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.25
-
[39]
arXiv preprint arXiv:2601.22594 , year=
Language Model Circuits Are Sparse in the Neuron Basis , author=. arXiv preprint arXiv:2601.22594 , year=
-
[40]
Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , pages =
Pearl, Judea , title =. Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , pages =. 2001 , isbn =
2001
-
[41]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[42]
Voita, Elena and Talbot, David and Moiseev, Fedor and Sennrich, Rico and Titov, Ivan. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1580
-
[43]
Are Sixteen Heads Really Better than One? , url =
Michel, Paul and Levy, Omer and Neubig, Graham , booktitle =. Are Sixteen Heads Really Better than One? , url =
-
[44]
The Fourteenth International Conference on Learning Representations , year=
Task Vectors, Learned Not Extracted: Performance Gains and Mechanistic Insights , author=. The Fourteenth International Conference on Learning Representations , year=
-
[45]
2026 , eprint=
What do Language Models Learn and When? The Implicit Curriculum Hypothesis , author=. 2026 , eprint=
2026
-
[46]
Causal Abstractions of Neural Networks , url =
Geiger, Atticus and Lu, Hanson and Icard, Thomas and Potts, Christopher , booktitle =. Causal Abstractions of Neural Networks , url =
-
[47]
2026 , eprint=
From Weights to Activations: Is Steering the Next Frontier of Adaptation? , author=. 2026 , eprint=
2026
-
[48]
Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003 , pages=
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition , author=. Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003 , pages=
2003
-
[49]
International Conference on Learning Representations , year=
Word translation without parallel data , author=. International Conference on Learning Representations , year=
-
[50]
Distinguishing Antonyms and Synonyms in a Pattern-based Neural Network
Nguyen, Kim Anh and Schulte im Walde, Sabine and Vu, Ngoc Thang. Distinguishing Antonyms and Synonyms in a Pattern-based Neural Network. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. 2017
2017
-
[51]
International conference on learning representations , author =
Linearity of relation decoding in transformer language models , volume =. International conference on learning representations , author =
-
[52]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=. 2017 , url=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.