ECHO: Explainable Co-editing with Human-in-the-loop Operations for Presentation Refinement
Pith reviewed 2026-06-30 22:46 UTC · model grok-4.3
The pith
ECHO turns black-box AI slide generation into controllable local edits by turning user intent into explainable plans that users confirm before execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ECHO enables precise local edits to presentation slides via a natural language plus visual selection paradigm that uses multimodal intent grounding, explainable operation plans, and dynamic memory to convert implicit requests into a Plan-Confirm-Execute workflow, raising Target Hit@1 from 0 percent in baselines to 55-85 percent depending on the base model while delivering 100 percent MD5-consistent undo and lowering NASA-TLX workload by 20.8 percent.
What carries the argument
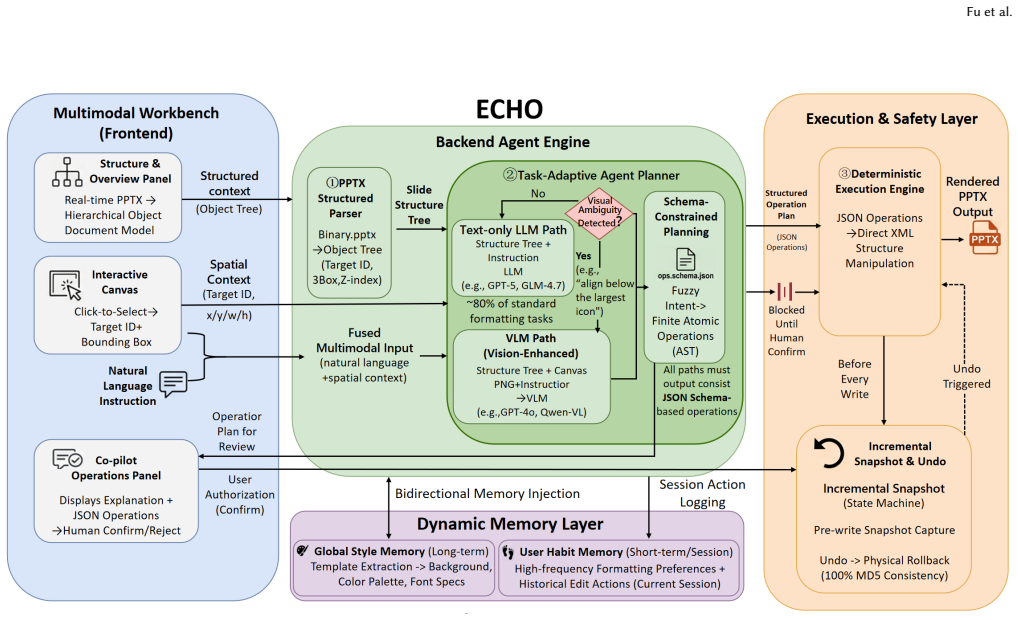
The Plan-Confirm-Execute loop with multimodal intent grounding and dynamic memory mechanisms, which converts user inputs into verifiable, human-reviewable operation plans before any file change.
If this is right
- Precise local edits replace full-slide regeneration for common refinement needs.
- Vision-language models resolve spatial ambiguities that text-only models miss.
- Undo operations maintain exact file identity across all edits.
- Human control allocation shifts dynamically as users move between different cognitive tasks.
Where Pith is reading between the lines
- The same intent-grounding loop could extend to other document types where layout consistency matters, such as reports or posters.
- Over repeated sessions the explainable plans might train users to phrase requests more effectively.
- The CoEdit-Eval framework offers a reusable testbed for comparing refinement systems on intent mapping and spatial accuracy.
Load-bearing premise
The zero-accuracy baselines represent typical current AI performance for slide refinement tasks and the small participant groups in the studies reflect how typical users would behave on other presentations.
What would settle it
A new baseline model that achieves above 50 percent Target Hit@1 on the same set of refinement tasks without a Plan-Confirm-Execute structure, or a follow-up study with at least 50 participants that finds no significant NASA-TLX reduction.
Figures


read the original abstract
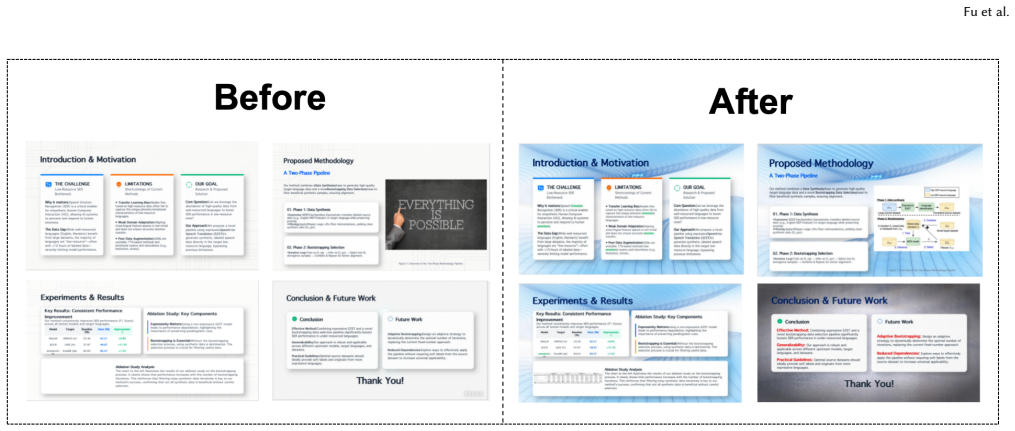
Authoring and refining presentation slides is a highly time-consuming core task in academic and business domains. While generative AI tools have lowered the barrier for creating initial drafts, their "black-box, one-way generation" paradigm severely deprives users of fine-grained control. Through a formative study (N=10), we identified "trial-and-error anxiety" and "inconsistent cross-page formatting" as primary bottlenecks in human-AI co-creation. Consequently, we present ECHO, an interactive system based on multimodal intent grounding and explainable operation plans. ECHO enables precise local edits via a "natural language + visual selection" paradigm, utilizing a decoupled "Plan-Confirm-Execute" loop and dynamic memory mechanisms to transform implicit AI intents into highly controllable layout co-creation. To systematically evaluate document refinement, we propose the CoEdit-Eval framework. Objective evaluations across multiple foundation models (e.g., GPT-5, GLM-4.7) demonstrate that while baselines uniformly fail in intent mapping (0% accuracy) and spatial grounding (0% Hit@1), the ECHO architecture boosts Target Hit@1 to 55%--85% depending on the base model. Furthermore, integrating Vision-Language Models (VLMs) effectively resolves spatial ambiguities -- achieving significant win rates in LLM blind evaluations -- and our Undo mechanism guarantees 100% physical file consistency (MD5 hash). Finally, a controlled study with 14 participants shows that ECHO significantly reduces cognitive workload (NASA-TLX scores dropped by 20.8%, from 82.6 to 65.4) and reveals the dynamic evolution of human control allocation across different cognitive tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ECHO, an interactive system for human-AI co-editing of presentation slides using multimodal intent grounding, explainable operation plans, and a decoupled Plan-Confirm-Execute loop with dynamic memory. It introduces the CoEdit-Eval framework. Objective evaluations report that baseline models (e.g., GPT-5, GLM-4.7) achieve 0% intent-mapping accuracy and 0% spatial Hit@1, while ECHO boosts Target Hit@1 to 55%-85% depending on the base model; VLMs resolve spatial ambiguities with significant win rates in blind evaluations; the Undo mechanism guarantees 100% physical file consistency via MD5 hash; and a controlled study with 14 participants shows NASA-TLX scores dropping 20.8% (82.6 to 65.4) with insights on evolving human control allocation.
Significance. If the performance gains are shown to stem from the architecture rather than input-format differences, the work could advance controllable generative interfaces for document refinement by mitigating trial-and-error anxiety and cross-page inconsistencies. The explicit 100% MD5 consistency guarantee and the Plan-Confirm-Execute loop with memory are verifiable strengths. The user study provides concrete evidence of workload reduction, which is a useful contribution to HCI evaluation of co-creation tools.
major comments (2)
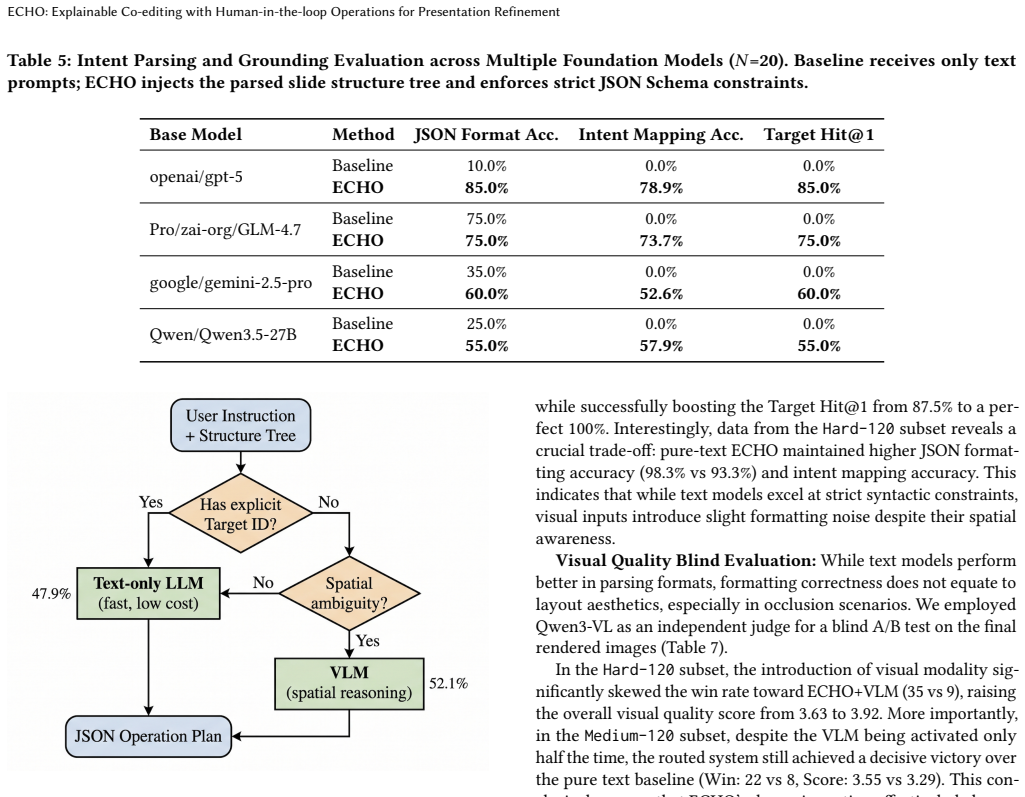
- [Objective evaluations across multiple foundation models] Objective evaluations paragraph: the central claim that ECHO boosts Target Hit@1 from 0% (baselines) to 55%-85% is load-bearing, yet the manuscript provides no details on the exact prompts, input modalities (e.g., whether the visual-selection channel or structured operation-plan format was supplied to GPT-5/GLM-4.7), or adaptation steps used for the baselines. Without an ablation that supplies identical multimodal inputs and memory mechanisms to the base models, the gap may be interface-driven rather than architectural, directly undermining the assertion that the ECHO architecture is required.
- [controlled study with 14 participants] controlled study with 14 participants paragraph: the NASA-TLX reduction (82.6 to 65.4) is load-bearing for the workload claim, but the text reports no statistical tests, participant selection criteria, task randomization details, or power analysis, leaving the reliability and generalizability of the 20.8% drop unverifiable.
minor comments (1)
- [Abstract and Evaluation sections] The abstract and evaluation sections use terms such as 'Target Hit@1' and 'CoEdit-Eval' without an early definition or reference to their precise computation; adding a short formal definition or pointer to the framework section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, committing to revisions that add the requested details without altering the core claims.
read point-by-point responses
-
Referee: [Objective evaluations across multiple foundation models] Objective evaluations paragraph: the central claim that ECHO boosts Target Hit@1 from 0% (baselines) to 55%-85% is load-bearing, yet the manuscript provides no details on the exact prompts, input modalities (e.g., whether the visual-selection channel or structured operation-plan format was supplied to GPT-5/GLM-4.7), or adaptation steps used for the baselines. Without an ablation that supplies identical multimodal inputs and memory mechanisms to the base models, the gap may be interface-driven rather than architectural, directly undermining the assertion that the ECHO architecture is required.
Authors: We acknowledge that the current manuscript does not include the exact baseline prompts or a full description of input modalities supplied to GPT-5 and GLM-4.7. The baselines received the raw natural-language user queries (and visual selections when present) through standard API calls, without the structured operation-plan format or the Plan-Confirm-Execute loop. These structured elements are core to the ECHO architecture and are not native to the base models. We will revise the objective evaluations section to document the precise baseline prompts and input formats used, and we will add explicit discussion clarifying how the architecture (rather than input format alone) enables the reported gains. revision: yes
-
Referee: [controlled study with 14 participants] controlled study with 14 participants paragraph: the NASA-TLX reduction (82.6 to 65.4) is load-bearing for the workload claim, but the text reports no statistical tests, participant selection criteria, task randomization details, or power analysis, leaving the reliability and generalizability of the 20.8% drop unverifiable.
Authors: We agree that the user-study reporting is incomplete. The manuscript states the NASA-TLX reduction and claims significance but does not provide the supporting statistical tests, selection criteria, randomization protocol, or power analysis. We will expand the controlled study section in the revision to include these methodological details and any available statistical results so that the workload findings are fully verifiable. revision: yes
Circularity Check
No significant circularity; empirical claims are direct measurements
full rationale
The paper reports empirical results from the CoEdit-Eval framework, user studies (N=10, N=14), and MD5 consistency checks without any equations, fitted parameters, or derivations. Performance figures (0% baselines, 55-85% Hit@1, 20.8% NASA-TLX drop) are presented as observed outcomes under stated conditions rather than quantities defined in terms of ECHO's own outputs or reduced by self-citation. No load-bearing self-citations, ansatzes, or uniqueness theorems appear in the provided text. The evaluation setup compares the full ECHO system to unmodified baselines, which is a standard (if potentially debatable) experimental design and does not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption NASA-TLX scores and Hit@1 accuracy are appropriate and sufficient measures of cognitive workload and intent-mapping success
- domain assumption The 0% baseline performance reflects current state-of-the-art rather than implementation choices
invented entities (1)
-
ECHO system architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sajid Ali, Tamer Abuhmed, Shaker El-Sappagh, Khan Muhammad, Jose M Alonso- Moral, Roberto Confalonieri, Riccardo Guidotti, Javier Del Ser, Natalia Díaz- Rodríguez, and Francisco Herrera. 2023. Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Information fusion99 (2023), 101805
2023
-
[2]
Sambaran Bandyopadhyay, Himanshu Maheshwari, Anandhavelu Natarajan, and Apoorv Saxena. 2024. Enhancing presentation slide generation by llms with a multi-staged end-to-end approach. InProceedings of the 17th International Natural Language Generation Conference. 222–229
2024
-
[3]
Samuelle Bourgault, Li-Yi Wei, Jennifer Jacobs, and Rubaiat Habib Kazi. 2025. Narrative motion blocks: combining direct manipulation and natural language interactions for animation creation. InProceedings of the 2025 ACM Designing Interactive Systems Conference. 1366–1386
2025
-
[4]
Virginia Braun and Victoria Clarke. 2019. Reflecting on reflexive thematic analysis.Qualitative Research in Sport, Exercise and Health11, 4 (2019), 589–597. arXiv:https://doi.org/10.1080/2159676X.2019.1628806 doi:10.1080/2159676X.2019. 1628806
-
[5]
Zijian Ding. 2024. Advancing GUI for generative AI: Charting the design space of human-AI interactions through task creativity and complexity. InCompanion Proceedings of the 29th International Conference on Intelligent User Interfaces. 140–143
2024
-
[6]
Lakshita Dodeja, Pradyumna Tambwekar, Erin Hedlund-Botti, and Matthew Gombolay. 2024. Towards the design of user-centric strategy recommendation systems for collaborative Human–AI tasks.International journal of human- computer studies184 (2024), 103216
2024
-
[7]
Bruno Dumas, Denis Lalanne, and Sharon Oviatt. 2009. Multimodal interfaces: A survey of principles, models and frameworks. InHuman machine interaction: Research results of the mmi program. Springer, 3–26
2009
-
[8]
Tsu-Jui Fu, William Yang Wang, Daniel McDuff, and Yale Song. 2022. Doc2ppt: Automatic presentation slides generation from scientific documents. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 36. 634–642
2022
-
[9]
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, et al. 2025. Autopresent: Designing structured visuals from scratch. InProceedings of the Computer Vision and Pattern Recognition Conference. 2902–2911
2025
-
[10]
Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, and Jaegul Choo. 2025. Talk to your slides: Language-driven agents for efficient slide editing. arXiv preprint arXiv:2505.11604(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Ishani Mondal, S Shwetha, Anandhavelu Natarajan, Aparna Garimella, Sambaran Bandyopadhyay, and Jordan Boyd-Graber. 2024. Presentations by the humans and for the humans: Harnessing llms for generating persona-aware slides from documents. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1:...
2024
- [13]
-
[14]
Caterina Moruzzi and Solange Margarido. 2024. A user-centered framework for human-ai co-creativity. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–9
2024
-
[15]
Changhoon Oh, Jungwoo Song, Jinhan Choi, Seonghyeon Kim, Sungwoo Lee, and Bongwon Suh. 2018. I lead, you help but only with enough details: Understanding user experience of co-creation with artificial intelligence. InProceedings of the 2018 CHI conference on human factors in computing systems. 1–13
2018
-
[16]
Yi-Hao Peng, Jason Wu, Jeffrey Bigham, and Amy Pavel. 2022. Diffscriber: Describing visual design changes to support mixed-ability collaborative presen- tation authoring. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–13
2022
-
[17]
Marissa Radensky, Simra Shahid, Raymond Fok, Pao Siangliulue, Tom Hope, and Daniel S Weld. 2024. Scideator: Human-llm scientific idea generation grounded in research-paper facet recombination.arXiv preprint arXiv:2409.14634(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Nikhil Singh, Guillermo Bernal, Daria Savchenko, and Elena L Glassman. 2023. Where to hide a stolen elephant: Leaps in creative writing with multimodal machine intelligence.ACM Transactions on Computer-Human Interaction30, 5 (2023), 1–57
2023
- [19]
-
[20]
Radu-Daniel Vatavu. 2024. AI as modality in human augmentation: Toward new forms of multimodal interaction with AI-Embodied modalities. InProceedings of the 26th International Conference on Multimodal Interaction. 591–595
2024
-
[21]
Sicheng Yang, Yukai Huang, Weitong Cai, Shitong Sun, You He, Jiankang Deng, Hang Zhang, Jifei Song, and Zhensong Zhang. 2026. Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 17921–17929
2026
-
[22]
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. 2025. Ufo: A ui-focused agent for windows os interaction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2025
-
[23]
Hanlei Zhang, Qianrui Zhou, Hua Xu, Jianhua Su, Roberto Evans, and Kai Gao
-
[24]
Multimodal classification and out-of-distribution detection for multimodal intent understanding.IEEE Transactions on Multimedia(2025)
2025
-
[25]
Runhua Zhang, Yang Ouyang, Leixian Shen, Yuying Tang, Xiaojuan Ma, Huamin Qu, and Xian Xu. 2025. PaperBridge: Crafting Research Narratives through Human-AI Co-Exploration. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–21
2025
-
[26]
Shuning Zhang, Hui Wang, and Xin Yi. 2025. Exploring collaboration patterns and strategies in human-ai co-creation through the lens of agency: A scoping review of the top-tier hci literature.Proceedings of the ACM on Human-Computer Interaction9, 7 (2025), 1–43
2025
-
[27]
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. 2025. Pptagent: Generating and evaluating presentations beyond text-to-slides. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 14413–14429
2025
- [28]
-
[29]
Jiayi Zhou, Renzhong Li, Junxiu Tang, Tan Tang, Haotian Li, Weiwei Cui, and Yingcai Wu. 2024. Understanding nonlinear collaboration between human and AI agents: A co-design framework for creative design. InProceedings of the 2024 CHI conference on human factors in computing systems. 1–16
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.