Distill Once, Adapt Life-Long: Exploring Dataset Distillation for Continual Test-Time Adaptation
Pith reviewed 2026-07-01 07:06 UTC · model grok-4.3
The pith
Distilled synthetic anchors let continual test-time adaptation stay stable over repeated shifts without storing source data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DO-ALL performs dataset distillation prior to deployment to generate a small set of synthetic distilled anchors summarizing the source distribution. During online adaptation, each target sample is matched to its most semantically aligned anchor, enabling stable source replay, representation alignment, and manifold-smoothing regularization within various CTTA frameworks. This enables long-term adaptation without access to the original source dataset, mitigating compounding self-training errors and catastrophic forgetting.
What carries the argument
Matching each target sample to its closest distilled synthetic anchor to supply stable references for replay, alignment, and regularization.
If this is right
- Existing CTTA algorithms integrate the anchor matching step with no major redesign.
- Long-term accuracy holds higher across CIFAR100-C, ImageNet-C, and CCC under repeated shifts.
- Adaptation continues online and label-free while never storing the original source examples.
- Self-training errors and forgetting are reduced by the external stable signals from the anchors.
Where Pith is reading between the lines
- The same distillation step could support other online adaptation settings where source data cannot be retained for privacy reasons.
- Distillation objectives could be tuned specifically to preserve long-horizon matching stability rather than single-step accuracy.
- The anchor-matching idea might transfer to continual learning pipelines that also face storage or licensing limits.
Load-bearing premise
The distilled anchors provide a faithful, stable summary of the source distribution that can be matched to target samples without introducing new compounding errors during long-term adaptation.
What would settle it
A long sequence of domain shifts on one of the paper's benchmarks where accuracy of the DO-ALL version eventually falls to the same level as the plain source-free baseline.
Figures
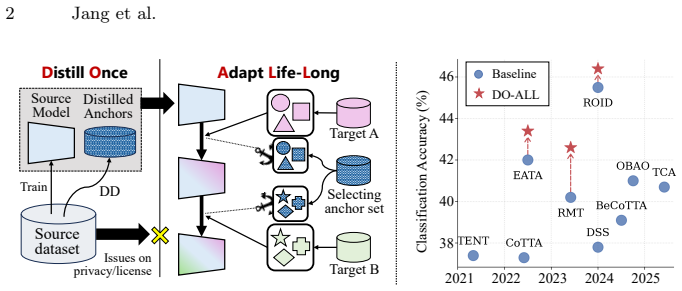
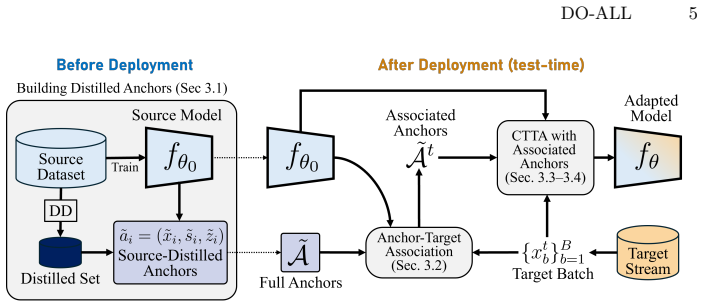
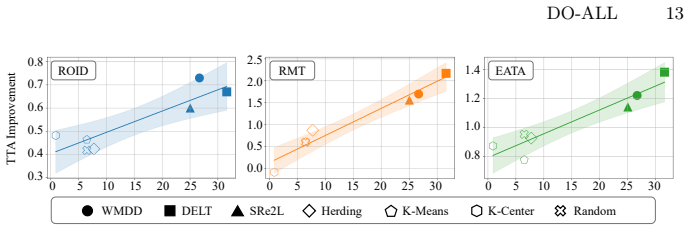
read the original abstract
Continual Test-Time Adaptation (CTTA) aims to maintain model performance under evolving target domains by adapting online without labeled data. However, practical deployments often cannot retain the source dataset due to privacy or licensing constraints, and purely source-free CTTA methods tend to become unstable under long-term distribution shift, suffering from compounding self-training errors and catastrophic forgetting. We introduce DO-ALL (Distill Once, Adapt Life-Long), a plug-and-play framework that revisits source information in a compact and privacy-conscious form via Dataset Distillation (DD). Before deployment, DO-ALL performs DD to produce a small set of synthetic distilled anchors that summarize the source distribution. During adaptation, each target sample is matched with its most semantically aligned anchor, which provides a stable reference for various CTTA via source replay, representation alignment, and manifold-smoothing regularization. DO-ALL can be seamlessly integrated into existing CTTA algorithms, consistently improving long-term robustness across CIFAR100-C, ImageNet-C, and the CCC benchmark. This demonstrates the potential of leveraging DD to enable stable and continuous adaptation without retaining raw source data. The code is available at https://github.com/blue-531/DOALL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DO-ALL (Distill Once, Adapt Life-Long), a plug-and-play framework for Continual Test-Time Adaptation (CTTA). It performs dataset distillation once before deployment to produce a small set of synthetic anchors summarizing the source distribution. During adaptation, each target sample is matched to its most semantically aligned anchor to enable source replay, representation alignment, and manifold-smoothing regularization. The approach is presented as integrable into existing CTTA methods without retaining raw source data, with the claim of consistent improvements in long-term robustness on CIFAR100-C, ImageNet-C, and the CCC benchmark. Code is provided at https://github.com/blue-531/DOALL.
Significance. If the empirical results hold, this work is significant because it offers a compact, privacy-preserving mechanism to stabilize long-term CTTA by revisiting source information via distilled anchors, addressing compounding errors and catastrophic forgetting in source-free settings. The public code release is a clear strength supporting reproducibility of the pipeline.
major comments (1)
- [Abstract] Abstract: the central claim that DO-ALL 'consistently improving long-term robustness across CIFAR100-C, ImageNet-C, and the CCC benchmark' is asserted without any quantitative results, ablation details, error bars, or baseline comparisons. This is load-bearing for the empirical contribution and must be substantiated with full experimental evidence.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of DO-ALL's significance and the code release. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DO-ALL 'consistently improving long-term robustness across CIFAR100-C, ImageNet-C, and the CCC benchmark' is asserted without any quantitative results, ablation details, error bars, or baseline comparisons. This is load-bearing for the empirical contribution and must be substantiated with full experimental evidence.
Authors: We agree that the abstract, as a concise summary, should include concrete quantitative support for the central claim rather than relying solely on the detailed results in the body. In the revised version we will augment the abstract with key performance numbers (e.g., average accuracy gains on each benchmark relative to the strongest baselines) while retaining the word limit. The full experimental evidence—including tables with error bars, baseline comparisons, and ablations—is already provided in Sections 4 and 5; the revision will simply make the abstract self-contained on this point. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces DO-ALL as a plug-and-play empirical framework that applies dataset distillation once to generate synthetic anchors, then integrates them into existing CTTA methods for replay/alignment/regularization. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or method description. The central claim is supported by external benchmark results (CIFAR100-C, ImageNet-C, CCC) rather than any internal reduction to inputs by construction. This is a standard engineering contribution with independent empirical validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- number and selection of distilled anchors
axioms (1)
- domain assumption Dataset distillation produces anchors that can be reliably matched to target samples to provide stable references for adaptation.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.03263 (2024)
Adachi, K., Yamaguchi, S., Kumagai, A., Hamagami, T.: Test-time adaptation for regression by subspace alignment. arXiv preprint arXiv:2410.03263 (2024)
-
[2]
In: 2023 IEEE International Conference on Image Processing (ICIP)
Adachi, K., Yamaguchi, S., Kumagai, A.: Covariance-aware feature alignment with pre-computed source statistics for test-time adaptation to multiple image corrup- tions. In: 2023 IEEE International Conference on Image Processing (ICIP). pp. 800–804. IEEE (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Boudiaf, M., Mueller, R., Ben Ayed, I., Bertinetto, L.: Parameter-free online test- time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 8344–8353 (2022)
2022
-
[4]
arXiv preprint arXiv:2511.16674 (2025)
Cazenavette, G., Torralba, A., Sitzmann, V.: Dataset distillation for pre-trained self-supervised vision models. arXiv preprint arXiv:2511.16674 (2025)
-
[5]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Cazenavette, G., Wang, T., Torralba, A., Efros, A.A., Zhu, J.Y.: Dataset distilla- tion by matching training trajectories. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 4750–4759 (2022)
2022
-
[6]
Transactions on Machine Learning Research (2023)
Chakrabarty, G., Sreenivas, M., Biswas, S.: Santa: Source anchoring network and target alignment for continual test time adaptation. Transactions on Machine Learning Research (2023)
2023
-
[7]
In: European Con- ference on Computer Vision
Choi, S., Yang, S., Choi, S., Yun, S.: Improving test-time adaptation via shift- agnostic weight regularization and nearest source prototypes. In: European Con- ference on Computer Vision. pp. 440–458. Springer (2022)
2022
-
[8]
Advances in Neural Information Processing Systems35, 810–822 (2022)
Cui, J., Wang, R., Si, S., Hsieh, C.J.: Dc-bench: Dataset condensation benchmark. Advances in Neural Information Processing Systems35, 810–822 (2022)
2022
-
[9]
In: International Conference on Machine Learning
Cui, J., Wang, R., Si, S., Hsieh, C.J.: Scaling up dataset distillation to imagenet- 1k with constant memory. In: International Conference on Machine Learning. pp. 6565–6590. PMLR (2023)
2023
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cui, X., Qin, Y., Zhou, W., Li, H., Li, H.: Optical: Leveraging optimal transport for contribution allocation in dataset distillation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15245–15254 (2025)
2025
-
[11]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[12]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deng, W., Li, W., Ding, T., Wang, L., Zhang, H., Huang, K., Huo, J., Gao, Y.: Ex- ploiting inter-sample and inter-feature relations in dataset distillation. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17057–17066 (2024) 16 Jang et al
2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Döbler, M., Marsden, R.A., Yang, B.: Robust mean teacher for continual and gradual test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7704–7714 (2023)
2023
-
[14]
Dong, T., Zhao, B., Lyu, L.: Privacy for free: How does dataset condensation help privacy? In: International Conference on Machine Learning. pp. 5378–5396. PMLR (2022)
2022
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Du, J., Jiang, Y., Tan, V.Y., Zhou, J.T., Li, H.: Minimizing the accumulated trajectory error to improve dataset distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3749–3758 (2023)
2023
-
[16]
Advances in Neural Information Processing Systems36, 67487–67504 (2023)
Du, J., Shi, Q., Zhou, J.T.: Sequential subset matching for dataset distillation. Advances in Neural Information Processing Systems36, 67487–67504 (2023)
2023
-
[17]
arXiv preprint arXiv:2310.05773 (2023)
Guo, Z., Wang, K., Cazenavette, G., Li, H., Zhang, K., You, Y.: Towards loss- less dataset distillation via difficulty-aligned trajectory matching. arXiv preprint arXiv:2310.05773 (2023)
-
[18]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[19]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Hendrycks,D.,Dietterich,T.:Benchmarkingneuralnetworkrobustnesstocommon corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[20]
Advances in Neural Infor- mation Processing Systems37, 74211–74232 (2024)
Jang, H.K., Kim, J., Kweon, H., Yoon, K.J.: Talos: Enhancing semantic scene completion via test-time adaptation on the line of sight. Advances in Neural Infor- mation Processing Systems37, 74211–74232 (2024)
2024
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jeong, J., Kwon, H., Kim, M., Yoon, K.J.: Multimodal distribution matching for vision-language dataset distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23072–23082 (2026)
2026
-
[22]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Jung, S., Lee, J., Kim, N., Shaban, A., Boots, B., Choo, J.: Cafa: Class-aware feature alignment for test-time adaptation. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 19060–19071 (2023)
2023
-
[23]
Kang, J., Kim, N., Kwon, D., Ok, J., Kwak, S.: Leveraging proxy of training data for test-time adaptation (2023)
2023
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, H., Jang, H.K., Yoon, K.J.: Test-time training for lidar semantic segmenta- tion under corruption via geometric inlier discrimination. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24206– 24216 (2026)
2026
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kim, J., Kwon, H., Kweon, H., Jeong, W., Yoon, K.J.: Dc-tta: Divide-and-conquer framework for test-time adaptation of interactive segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23279–23289 (2025)
2025
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, J., Kwon, H., Kweon, H., Yoon, K.J.: Bootstrapping video semantic segmen- tation model via distillation-assisted test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10766– 10777 (2026)
2026
-
[27]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[28]
arXiv preprint arXiv:2402.08712 (2024)
Lee,D.,Yoon,J.,Hwang,S.J.:Becotta:Input-dependentonlineblendingofexperts for continual test-time adaptation. arXiv preprint arXiv:2402.08712 (2024)
-
[29]
In: International Conference on Machine Learning
Lee, S., Chun, S., Jung, S., Yun, S., Yoon, S.: Dataset condensation with con- trastive signals. In: International Conference on Machine Learning. pp. 12352– 12364. PMLR (2022) DO-ALL 17
2022
-
[30]
arXiv preprint arXiv:2406.18561 (2024)
Lee, Y., Chung, H.W.: Selmatch: Effectively scaling up dataset distillation via selection-based initialization and partial updates by trajectory matching. arXiv preprint arXiv:2406.18561 (2024)
-
[31]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(1), 17–32 (2023)
Lei, S., Tao, D.: A comprehensive survey of dataset distillation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(1), 17–32 (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Li, H., Zhou, Y., Gu, X., Li, B., Wang, W.: Diversity-enhanced distribution align- ment for dataset distillation. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 3747–3756 (2025)
2025
-
[33]
arXiv preprint arXiv:2505.24623 (2025)
Li, W., Li, G., Maeda, K., Ogawa, T., Haseyama, M.: Hyperbolic dataset distilla- tion. arXiv preprint arXiv:2505.24623 (2025)
-
[34]
Revisiting Batch Normalization For Practical Domain Adaptation
Li, Y., Wang, N., Shi, J., Liu, J., Hou, X.: Revisiting batch normalization for practical domain adaptation. arXiv preprint arXiv:1603.04779 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
arXiv preprint arXiv:2505.13300 (2025)
Li, Z., Zhong, X., Khaki, S., Liang, Z., Zhou, Y., Shi, M., Wang, Z., Zhao, X., Zhao, W., Qin, Z., et al.: Dd-ranking: Rethinking the evaluation of dataset distillation. arXiv preprint arXiv:2505.13300 (2025)
-
[36]
In: International conference on machine learning
Liang, J., Hu, D., Feng, J.: Do we really need to access the source data? source hy- pothesis transfer for unsupervised domain adaptation. In: International conference on machine learning. pp. 6028–6039. PMLR (2020)
2020
-
[37]
arXiv preprint arXiv:2302.05155 (2023)
Lim, H., Kim, B., Choo, J., Choi, S.: Ttn: A domain-shift aware batch normaliza- tion in test-time adaptation. arXiv preprint arXiv:2302.05155 (2023)
-
[38]
In: ICLR (2026)
Lim, T., Hwang, J.W., Lee, K.: When and where to reset matters for long-term test-time adaptation. In: ICLR (2026)
2026
-
[39]
In: European Conference on Computer Vision
Liu, D., Gu, J., Cao, H., Trinitis, C., Schulz, M.: Dataset distillation by automatic training trajectories. In: European Conference on Computer Vision. pp. 334–351. Springer (2024)
2024
-
[40]
arXiv preprint arXiv:2311.18531 (2023)
Liu, H., Li, Y., Xing, T., Dalal, V., Li, L., He, J., Wang, H.: Dataset distillation via the wasserstein metric. arXiv preprint arXiv:2311.18531 (2023)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, J., Xu, R., Yang, S., Zhang, R., Zhang, Q., Chen, Z., Guo, Y., Zhang, S.: Continual-mae: Adaptive distribution masked autoencoders for continual test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28653–28663 (2024)
2024
-
[42]
IEEE Transactions on Image Processing (2025)
Ma, Z., Cao, A., Yang, F., Gong, Y., Wei, X.: Curriculum dataset distillation. IEEE Transactions on Image Processing (2025)
2025
-
[43]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Marsden, R.A., Döbler, M., Yang, B.: Universal test-time adaptation through weight ensembling, diversity weighting, and prior correction. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 2555– 2565 (2024)
2024
-
[44]
arXiv preprint arXiv:2011.00050 (2020)
Nguyen, T., Chen, Z., Lee, J.: Dataset meta-learning from kernel ridge-regression. arXiv preprint arXiv:2011.00050 (2020)
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ni, C., Lyu, F., Tan, J., Hu, F., Yao, R., Zhou, T.: Maintaining consistent inter- class topology in continual test-time adaptation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15319–15328 (2025)
2025
-
[46]
In: International conference on machine learning
Niu, S., Wu, J., Zhang, Y., Chen, Y., Zheng, S., Zhao, P., Tan, M.: Efficient test- time model adaptation without forgetting. In: International conference on machine learning. pp. 16888–16905. PMLR (2022)
2022
-
[47]
arXiv preprint arXiv:2302.12400 , year =
Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., Tan, M.: Towards sta- ble test-time adaptation in dynamic wild world. arXiv preprint arXiv:2302.12400 (2023)
-
[48]
Advances in Neural Information Processing Systems36, 39915–39935 (2023) 18 Jang et al
Press, O., Schneider, S., Kümmerer, M., Bethge, M.: Rdumb: A simple approach that questions our progress in continual test-time adaptation. Advances in Neural Information Processing Systems36, 39915–39935 (2023) 18 Jang et al
2023
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Sajedi, A., Khaki, S., Amjadian, E., Liu, L.Z., Lawryshyn, Y.A., Plataniotis, K.N.: Datadam: Efficient dataset distillation with attention matching. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17097–17107 (2023)
2023
-
[50]
Advances in neural information processing systems37, 99161–99201 (2024)
Shao, S., Zhou, Z., Chen, H., Shen, Z.: Elucidating the design space of dataset condensation. Advances in neural information processing systems37, 99161–99201 (2024)
2024
-
[51]
In: Proceedings of the Computer Vision and Pat- tern Recognition Conference
Shen, Z., Sherif, A., Yin, Z., Shao, S.: Delt: A simple diversity-driven earlylate training for dataset distillation. In: Proceedings of the Computer Vision and Pat- tern Recognition Conference. pp. 4797–4806 (2025)
2025
-
[52]
In: International Conference on Artificial In- telligence and Statistics
Shin, S., Bae, H., Shin, D., Joo, W., Moon, I.C.: Loss-curvature matching for dataset selection and condensation. In: International Conference on Artificial In- telligence and Statistics. pp. 8606–8628. PMLR (2023)
2023
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Song, J., Lee, J., Kweon, I.S., Choi, S.: Ecotta: Memory-efficient continual test- time adaptation via self-distilled regularization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11920–11929 (2023)
2023
-
[54]
In: 2023 International Joint Conference on Neural Networks (IJCNN)
Song, R., Liu, D., Chen, D.Z., Festag, A., Trinitis, C., Schulz, M., Knoll, A.: Feder- ated learning via decentralized dataset distillation in resource-constrained edge en- vironments. In: 2023 International Joint Conference on Neural Networks (IJCNN). pp. 1–10. IEEE (2023)
2023
-
[55]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Su, Z., Guo, J., Yao, K., Yang, X., Wang, Q., Huang, K.: Unraveling batch normal- ization for realistic test-time adaptation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 15136–15144 (2024)
2024
-
[56]
In: ICLR 2024 Workshop on Data-centric Machine Learning Research (DMLR) (2024)
Sun, P., Shi, B., Shang, X., Lin, T.: Information compensation: A fix for any-scale dataset distillation. In: ICLR 2024 Workshop on Data-centric Machine Learning Research (DMLR) (2024)
2024
-
[57]
Tent: Fully Test-time Adaptation by Entropy Minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, K., Zhao, B., Peng, X., Zhu, Z., Yang, S., Wang, S., Huang, G., Bilen, H., Wang, X., You, Y.: Cafe: Learning to condense dataset by aligning features. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12196–12205 (2022)
2022
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Q., Fink, O., Van Gool, L., Dai, D.: Continual test-time domain adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7201–7211 (2022)
2022
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, S., Yang, Y., Liu, Z., Sun, C., Hu, X., He, C., Zhang, L.: Dataset distillation with neural characteristic function: A minmax perspective. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 25570–25580 (2025)
2025
-
[61]
Wang, T., Zhu, J.Y., Torralba, A., Efros, A.A.: Dataset distillation. arXiv preprint arXiv:1811.10959 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Wang, Y., Hong, J., Cheraghian, A., Rahman, S., Ahmedt-Aristizabal, D., Peters- son, L., Harandi, M.: Continual test-time domain adaptation via dynamic sample selection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1701–1710 (2024)
2024
-
[63]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xie,S.,Girshick,R.,Dollár,P.,Tu,Z.,He,K.:Aggregatedresidualtransformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1492–1500 (2017)
2017
-
[64]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiong, Y., Wang, R., Cheng, M., Yu, F., Hsieh, C.J.: Feddm: Iterative distribution matching for communication-efficient federated learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16323– 16332 (2023) DO-ALL 19
2023
-
[65]
Advances in Neural Information Processing Systems36, 67625–67642 (2023)
Yang, E., Shen, L., Wang, Z., Liu, T., Guo, G.: An efficient dataset condensation plugin and its application to continual learning. Advances in Neural Information Processing Systems36, 67625–67642 (2023)
2023
-
[66]
In: European Conference on Computer Vision
Yang, S., Cheng, S., Hong, M., Fan, H., Wei, X., Liu, S.: Neural spectral decompo- sition for dataset distillation. In: European Conference on Computer Vision. pp. 275–290. Springer (2024)
2024
-
[67]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, X., Chen, X., Li, M., Wei, K., Deng, C.: A versatile framework for contin- ual test-time domain adaptation: Balancing discriminability and generalizability. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23731–23740 (2024)
2024
-
[68]
Advances in Neural Information Processing Systems36, 73582–73603 (2023)
Yin, Z., Xing, E., Shen, Z.: Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. Advances in Neural Information Processing Systems36, 73582–73603 (2023)
2023
-
[69]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Yuan, L., Xie, B., Li, S.: Robust test-time adaptation in dynamic scenarios. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 15922–15932 (2023)
2023
-
[70]
Zhang, H., Li, S., Lin, F., Wang, W., Qian, Z., and Ge, S
Zhang,H.,Li,S.,Lin,F.,Wang,W.,Qian,Z.,Ge,S.:Dance:Dual-viewdistribution alignment for dataset condensation. arXiv preprint arXiv:2406.01063 (2024)
-
[71]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, H., Li, S., Wang, P., Zeng, D., Ge, S.: M3d: Dataset condensation by minimizing maximum mean discrepancy. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 9314–9322 (2024)
2024
-
[72]
mixup: Beyond Empirical Risk Minimization
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[73]
Advances in neural information processing systems35, 38629–38642 (2022)
Zhang, M., Levine, S., Finn, C.: Memo: Test time robustness via adaptation and augmentation. Advances in neural information processing systems35, 38629–38642 (2022)
2022
-
[74]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
Zhang, X., Du, J., Liu, P., Zhou, J.T.: Breaking class barriers: Efficient dataset distillation via inter-class feature compensator. In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
2025
-
[75]
In: International Conference on Machine Learning
Zhao, B., Bilen, H.: Dataset condensation with differentiable siamese augmenta- tion. In: International Conference on Machine Learning. pp. 12674–12685. PMLR (2021)
2021
-
[76]
In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Zhao, B., Bilen, H.: Dataset condensation with distribution matching. In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6514–6523 (2023)
2023
-
[77]
Dataset condensation with gradientmatching
Zhao, B., Mopuri, K.R., Bilen, H.: Dataset condensation with gradient matching. arXiv preprint arXiv:2006.05929 (2020)
-
[78]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao, G., Li, G., Qin, Y., Yu, Y.: Improved distribution matching for dataset condensation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7856–7865 (2023)
2023
-
[79]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Zhong, W., Tang, H., Zheng, Q., Xu, M., Hu, Y., Guan, W.: Towards stable and storage-efficient dataset distillation: Matching convexified trajectory. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 25581–25589 (2025)
2025
-
[80]
Advances in Neural Information Processing Systems35, 9813–9827 (2022)
Zhou, Y., Nezhadarya, E., Ba, J.: Dataset distillation using neural feature regres- sion. Advances in Neural Information Processing Systems35, 9813–9827 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.