Moebius: Serving Mixture-of-Expert Models with Seamless Runtime Parallelism Switch
Pith reviewed 2026-06-26 04:02 UTC · model grok-4.3
The pith
Moebius switches MoE models between tensor and expert parallelism at runtime by moving only changed ownership slices of identical weights and KV cache.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
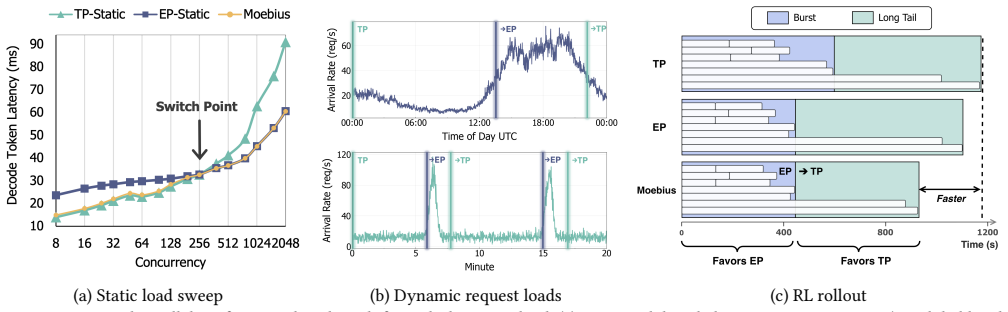
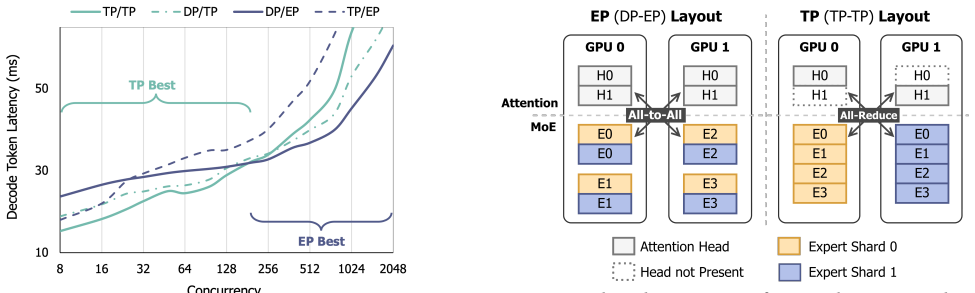
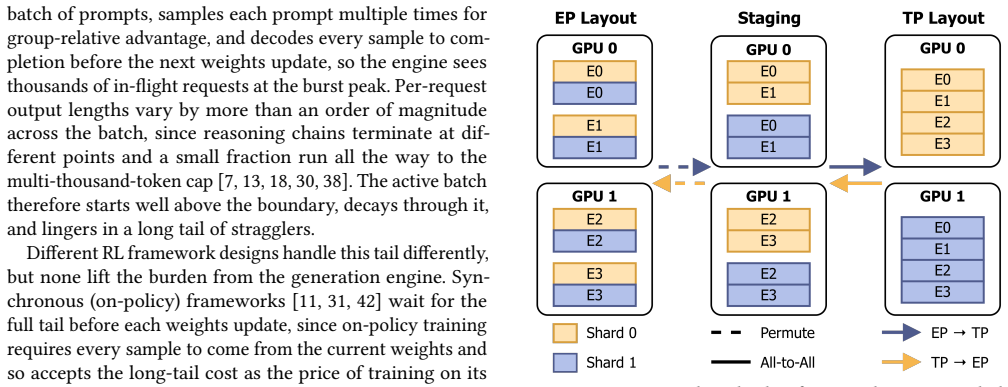
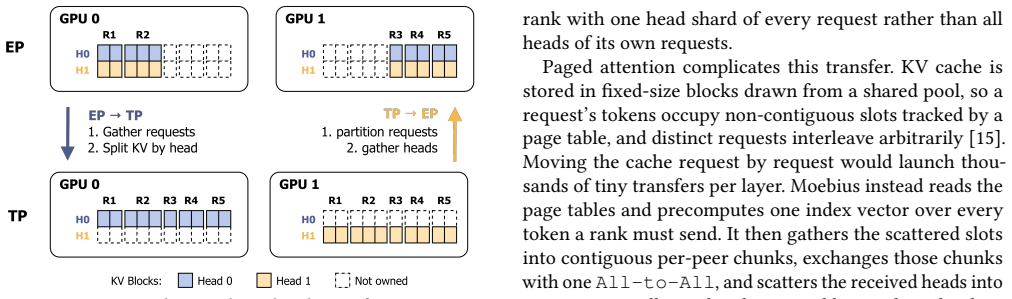
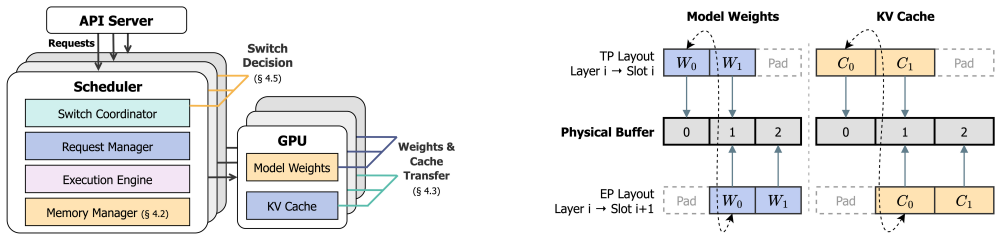
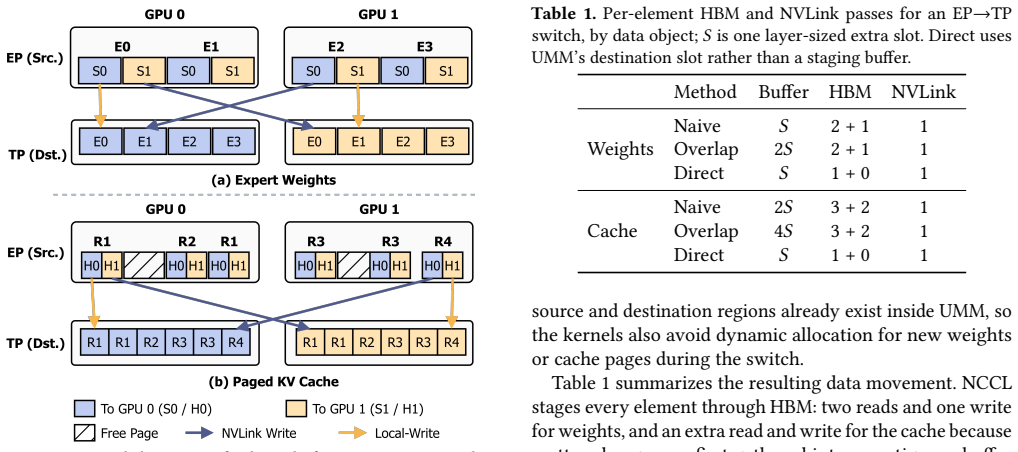
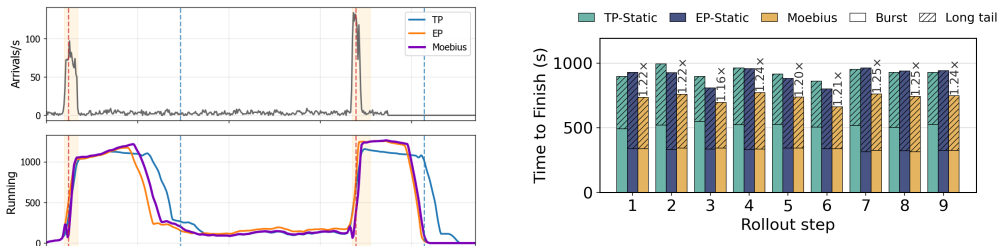
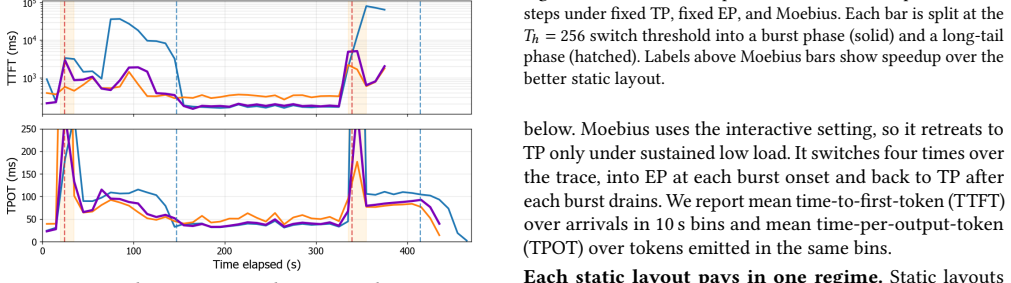
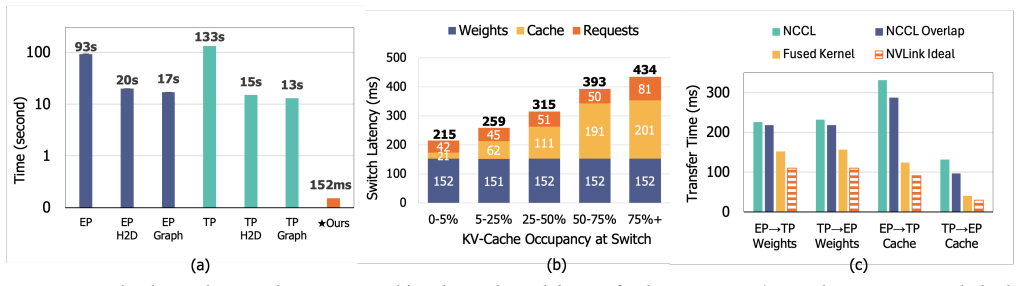
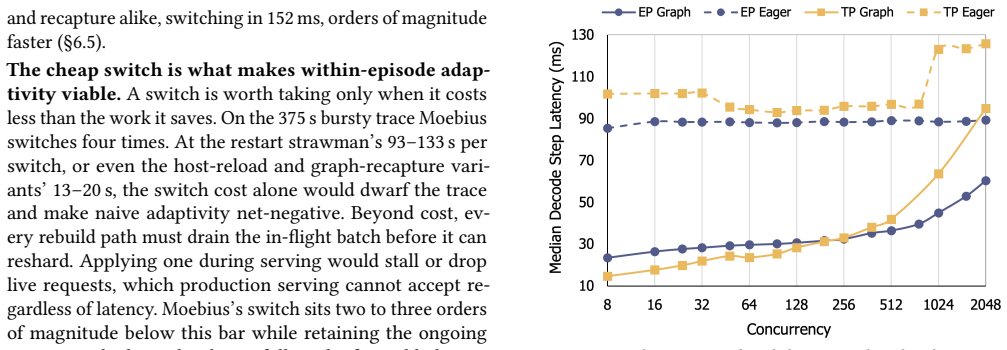
EP and TP compute the same function over byte-identical expert weights and KV cache, so a switch changes only which rank owns each slice. Moving those slices via fused GPU-to-GPU kernels completes in 215-434 ms between decode steps without dropping in-flight requests. Moebius preserves each parallelism's runtime resident and reshards the single copy of weights and cache at fixed addresses.
What carries the argument
Fused GPU-to-GPU transfer kernels that move only owner-changed slices of expert weights and KV cache while holding both parallelism layouts resident at fixed addresses.
If this is right
- Matches the better static parallelism at every operating point on the measured workload.
- Delivers 1.16-1.25x end-to-end speedup on RL rollouts across all steps.
- Completes each switch in 215-434 ms without request drops or engine restarts.
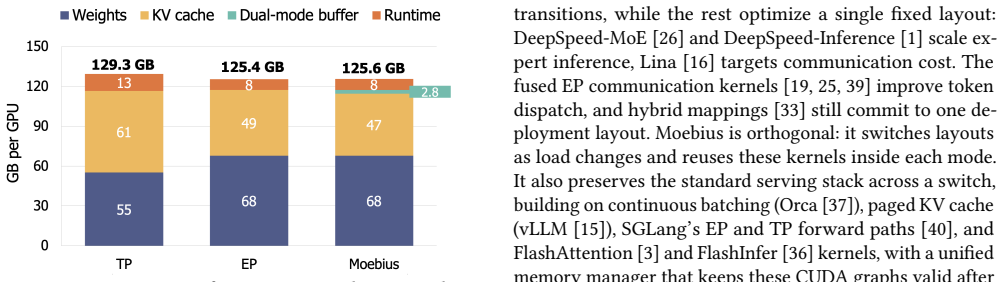
- Holds both layouts resident with 2.4 percent memory overhead.
Where Pith is reading between the lines
- The same ownership-slice movement idea could apply to other model parallelism strategies that share identical underlying state.
- Serving systems could use workload arrival-rate signals to trigger switches automatically rather than rely on static configuration.
- The technique reduces the cost of over-provisioning for peak concurrency by allowing the same GPUs to adapt across load regimes.
Load-bearing premise
EP and TP produce identical outputs from the exact same weights and KV cache, so a switch reduces only to data movement.
What would settle it
A measurement showing that outputs or request completions after a switch differ from those produced by a static layout on the same inputs and weights.
Figures
read the original abstract
Mixture-of-Experts (MoE) architectures scale large language models (LLMs) to hundreds of billions of parameters. Serving a single MoE model requires multiple GPUs operating in parallel, typically through tensor parallelism (TP) or expert parallelism (EP). The optimal choice depends on the number of in-flight requests: TP is faster at low concurrency, whereas EP wins at high concurrency. Production workloads cross this boundary continually: online serving sees bursty arrivals that subside into quiet periods, and reinforcement-learning rollouts begin as a high-concurrency burst that decays into a long tail of stragglers. Pinning either layout therefore forfeits performance when the workload crosses to the other side. We present Moebius, a serving system that switches between EP and TP at runtime without restarting the engine or dropping in-flight requests. Our key insight is that EP and TP are two layouts of one model, not two models: they compute the same function over byte-identical expert weights and KV cache, so a switch changes only which rank owns each slice. Moving those owner-changed slices is the sole irreducible cost, and modern high-bandwidth GPU interconnects make it fast enough to do between decode steps without draining in-flight requests. Moebius preserves each parallelism's runtime resident, and reshards the single copy of expert weights and KV cache at fixed addresses with fused GPU-to-GPU transfer kernels. On 8x H200 GPUs serving Qwen3-235B-A22B, Moebius matches the better static parallelism at every operating point, and beats it on RL rollouts by 1.16-1.25x across steps. Each switch completes in 215-434 ms, and Moebius holds both layouts resident with only 2.4% memory overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Moebius, a serving system for Mixture-of-Experts (MoE) LLMs that supports runtime switching between expert parallelism (EP) and tensor parallelism (TP) without engine restart or request drops. EP and TP are treated as alternative layouts of identical expert weights and KV cache, so a switch reduces to moving owner-changed slices via fused GPU-to-GPU kernels that complete between decode steps. Both layouts remain resident with resharing at fixed addresses. On 8x H200 GPUs with Qwen3-235B-A22B, Moebius matches the better static parallelism at all points and improves RL rollouts by 1.16-1.25x, with switches in 215-434 ms and 2.4% memory overhead.
Significance. If the measurements hold, the result is significant for production MoE serving and RL workloads whose concurrency varies over time, as it removes the need to pin a suboptimal static layout. Credit is given for grounding the approach in the standard equivalence of EP/TP layouts (no invented entities or fitted parameters) and for the practical use of fused kernels to achieve sub-second switches while preserving both configurations resident.
major comments (1)
- [Abstract] Abstract: the performance numbers (1.16-1.25x on RL rollouts, 215-434 ms switches, 2.4% overhead) are stated without reference to the evaluation section, table, or figure that reports the experimental setup, baselines, number of trials, or error bars. This directly affects assessment of the central claim that Moebius matches or exceeds static parallelism across operating points.
minor comments (2)
- The abstract would be clearer if it briefly stated the model parameter count and GPU count in the opening sentence rather than only in the final sentence.
- Notation for the two layouts (EP vs. TP) is used without an early definition or diagram showing the owner slices that must move on a switch.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Moebius's significance for production MoE serving and RL workloads. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance numbers (1.16-1.25x on RL rollouts, 215-434 ms switches, 2.4% overhead) are stated without reference to the evaluation section, table, or figure that reports the experimental setup, baselines, number of trials, or error bars. This directly affects assessment of the central claim that Moebius matches or exceeds static parallelism across operating points.
Authors: We agree that the abstract would be improved by explicit references to the supporting evaluation details. In the revised manuscript we will update the abstract to cite the evaluation section, the specific tables and figures that report the experimental setup, baselines, number of trials, and any error bars or variability measures. This is a straightforward textual change that does not affect the technical claims or results. revision: yes
Circularity Check
No significant circularity; claims rest on implementation and measurements
full rationale
The paper describes a runtime system for switching between EP and TP layouts in MoE serving. The key insight—that EP and TP are alternative layouts of identical weights and KV cache, reducing the switch to slice movement—is a direct consequence of the standard definitions of tensor and expert parallelism, not a self-referential derivation or fitted parameter. All performance numbers (switch times, overheads, speedups) are presented as empirical measurements on 8x H200 GPUs rather than predictions derived from the paper's own inputs. No equations, self-citation chains, or ansatzes appear in the provided text that would reduce any central claim to its own construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed-Inference: En- abling Efficient Inference of Transformer Models at Unprecedented Scale. InProceedings of the International Conference for High Perfor- mance Computing, Network...
2022
-
[2]
Haoyu Chen, Xue Li, Kun Qian, Yu Guan, Jin Zhao, and Xin Wang. 2026. Amoeba: Runtime Tensor Parallel Transformation for LLM Inference Services.arXiv preprint arXiv:2509.19729(2026)
Pith/arXiv arXiv 2026
-
[3]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[4]
InProceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS)
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InProceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS)
-
[5]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
Pith/arXiv arXiv 2025
-
[6]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. 2025. AReaL: A Large-Scale Asynchronous Rein- forcement Learning System for Language Reasoning. InProceedings of the Advances in Neural Information Processing Systems 38 (NeurIPS)
2025
-
[7]
Shouwei Gao, Junqi Yin, Feiyi Wang, and Wenqian Dong. 2026. Flying Serving: On-the-Fly Parallelism Switching for Large Language Model Serving. InProceedings of the 40th ACM International Conference on Supercomputing (ICS)
2026
-
[8]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2026. RollPacker: Taming Long-Tail Rollouts for RL Post-Training with Tail Batching. InProceedings of the 23rd USENIX Symposium on Networked Systems Design and Implemen- tation (NSDI)
2026
-
[9]
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, and Bin Cui. 2024. Enabling Parallelism Hot Switching for Efficient Training of Large Lan- guage Models. InProceedings of the 30th ACM Symposium on Operating Systems Principles (SOSP)
2024
-
[10]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhu- osheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2026. DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning. InProceed- ings of the 14th International Co...
2026
-
[11]
Mert Hidayetoglu, Aurick Qiao, Michael Wyatt, Jeff Rasley, Yuxiong He, and Samyam Rajbhandari. 2026. Shift Parallelism: Low-Latency, High-Throughput LLM Inference for Dynamic Workloads. InProceed- ings of the 31st International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2026
-
[12]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Wenkai Fang, Xianyu, Yu Cao, Haotian Xu, and Yiming Liu. 2025. OpenRLHF: A Ray-based Easy-to-use, Scalable and High-performance RLHF Framework. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstr...
2025
-
[13]
Qinghao Hu, Shang Yang, Junxian Guo, Xiaozhe Yao, Yujun Lin, Yuxian Gu, Han Cai, Chuang Gan, Ana Klimovic, and Song Han. 2026. Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2026
-
[14]
Tianhao Hu, Xiangcheng Liu, Youshao Xiao, Yang Zheng, Xuan Huang, Jinrui Ding, Yufei Zhang, Tao Liang, Hongyu Zang, Quan Chen, Yue- qing Sun, Wenjie Shi, Chao Zhang, Wei Wang, Qi Gu, Yerui Sun, Yucheng Xie, and Xunliang Cai. 2026. DORA: A Scalable Asynchro- nous Reinforcement Learning System for Language Model Training. arXiv preprint arXiv:2604.26256(2026)
Pith/arXiv arXiv 2026
-
[15]
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, HoYuen Chau, Peng Cheng, Fan Yang, Mao Yang, and Yongqiang Xiong. 2023. Tutel: Adaptive Mixture-of-Experts at Scale. InProceedings of the 6th Conference on Machine Learning and Systems (MLSys)
2023
-
[16]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
-
[18]
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. 2023. Accelerating Distributed MoE Training and Inference with Lina. In Proceedings of the 2023 USENIX Annual Technical Conference (USENIX ATC)
2023
-
[19]
Haoran Lin, Xianzhi Yu, Kang Zhao, Han Bao, Zongyuan Zhan, Ting Hu, Wulong Liu, Zekun Yin, Xin Li, and Weiguo Liu. 2025. HAP: Hybrid Adaptive Parallelism for Efficient Mixture-of-Experts Inference.arXiv preprint arXiv:2508.19373(2025)
arXiv 2025
-
[20]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. 2025. Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers.arXiv preprint arXiv:2510.11370(2025)
arXiv 2025
-
[21]
Ziming Mao, Yihan Zhang, Chihan Cui, Zhen Huang, Kaichao You, Zhongjie Chen, Zhiying Xu, Zhenyu Gu, Scott Shenker, Costin Raiciu, Yang Zhou, and Ion Stoica. 2026. UCCL-EP: Portable Expert-Parallel Communication.arXiv preprint arXiv:2512.19849(2026). 14
arXiv 2026
-
[22]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Lan- guage Models on Preemptible Instances. InProceedings of the 29th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2024
-
[23]
Microsoft Azure. 2024. Azure LLM Inference Trace. https://github.com/Azure/AzurePublicDataset/blob/master/ AzureLLMInferenceDataset2024.md
2024
-
[24]
NVIDIA. 2023. TensorRT-LLM: A TensorRT Toolbox for Optimized Large Language Model Inference.https://github.com/NVIDIA/ TensorRT-LLM
2023
-
[25]
OpenAI, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, Vlad...
Pith/arXiv arXiv 2025
-
[26]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st International Symposium on Computer Architecture (ISCA)
2024
-
[27]
Perplexity-AI. 2025. Efficient and Portable Mixture-of-Experts Com- munication.https://github.com/perplexityai/pplx-kernels
2025
-
[28]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. DeepSpeed-MoE: Advancing Mixture-of-Experts Infer- ence and Training to Power Next-Generation AI Scale. InProceedings of the 39th International Conference on Machine Learning (ICML)
2022
-
[29]
SemiAnalysis. 2025. InferenceX: LLM Inference Performance Bench- marks.https://inferencex.semianalysis.com/inference
2025
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
Pith/arXiv arXiv 2024
-
[32]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of the 5th International Conference on Learning Representa- tions (ICLR)
2017
-
[33]
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, Haibin Lin, Xin Liu, and Chuan Wu. 2026. Laminar: A Scalable Asynchro- nous RL Post-Training Framework. InProceedings of the 21st European Conference on Computer Systems (EuroSys)
2026
-
[34]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybrid- Flow: A Flexible and Efficient RLHF Framework. InProceedings of the 20th European Conference on Computer Systems (EuroSys)
2025
-
[35]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053(2020)
Pith/arXiv arXiv 2020
-
[36]
Siddharth Singh, Olatunji Ruwase, Ammar Ahmad Awan, Samyam Rajbhandari, Yuxiong He, and Abhinav Bhatele. 2023. A Hybrid Tensor- Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training. InProceedings of the 37th ACM International Conference on Supercomputing (ICS)
2023
-
[37]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chun- ing Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Hao- tian Zhao, Haoyu Lu, Haoze Li, ...
Pith/arXiv arXiv 2025
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
-
[39]
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[40]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Cus- tomizable Attention Engine for LLM Inference Serving. InProceedings of the 8th Conference on Machine Learning and Systems (MLSys)
2025
-
[41]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
2022
-
[42]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[43]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library.https://github.com/ deepseek-ai/DeepEP
2025
-
[44]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InPro- ceedings of the Advances in Neural Information Processing Systems 37 (NeurIPS)
2024
-
[45]
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, and Daxin Jiang. 2025. StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation.arXiv preprint arXiv:2504.15930(2025)
arXiv 2025
-
[46]
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, and Xin Jin. 2025. Optimizing RLHF Training for Large Language Models with Stage Fusion. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI). 16 A Rollout Workload Distribution Figure 14 plo...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.