Structure Before Collapse: Transient semantic geometry in next-token prediction
Pith reviewed 2026-06-26 05:11 UTC · model grok-4.3
The pith
Semantic geometry emerges early in next-token prediction before models reach the symmetric neural collapse state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
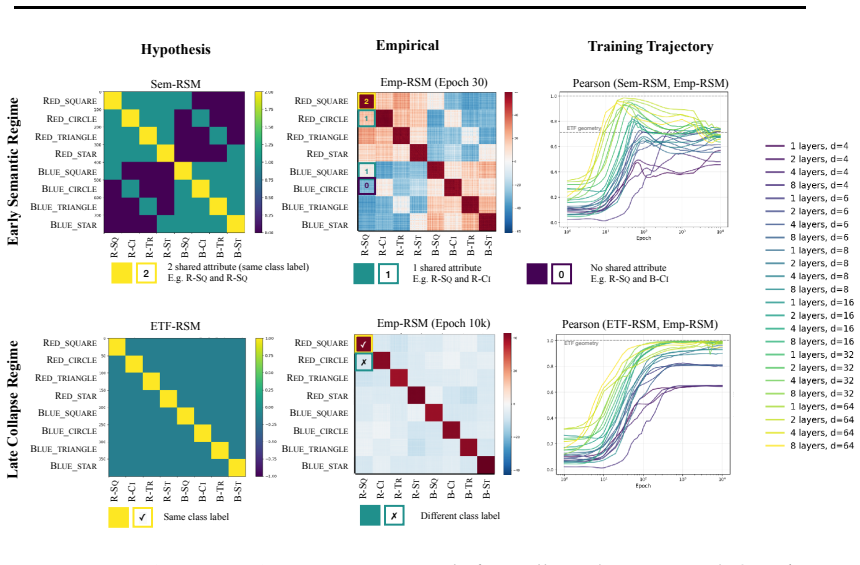
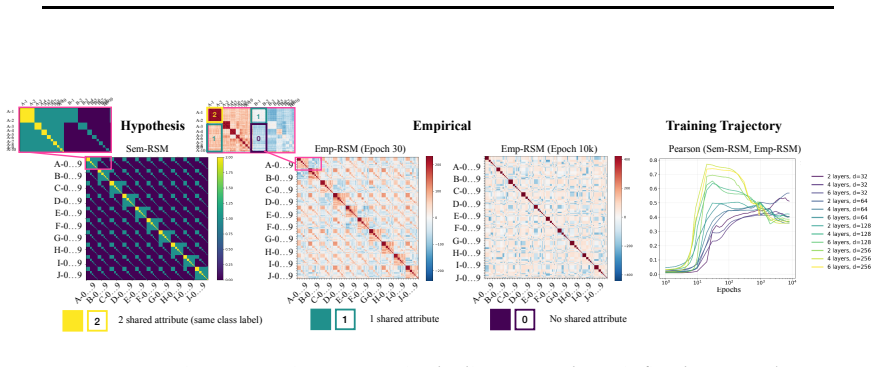
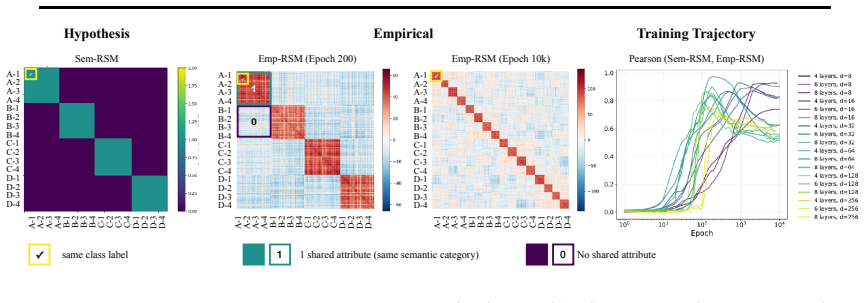
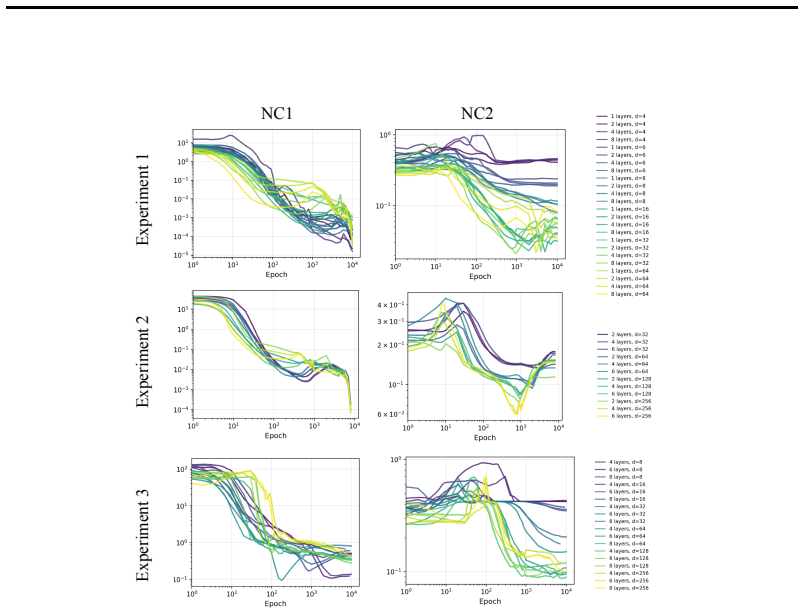
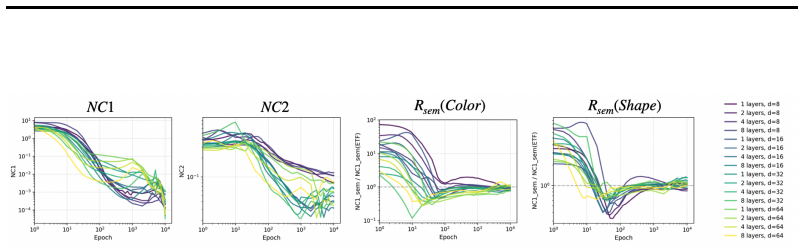
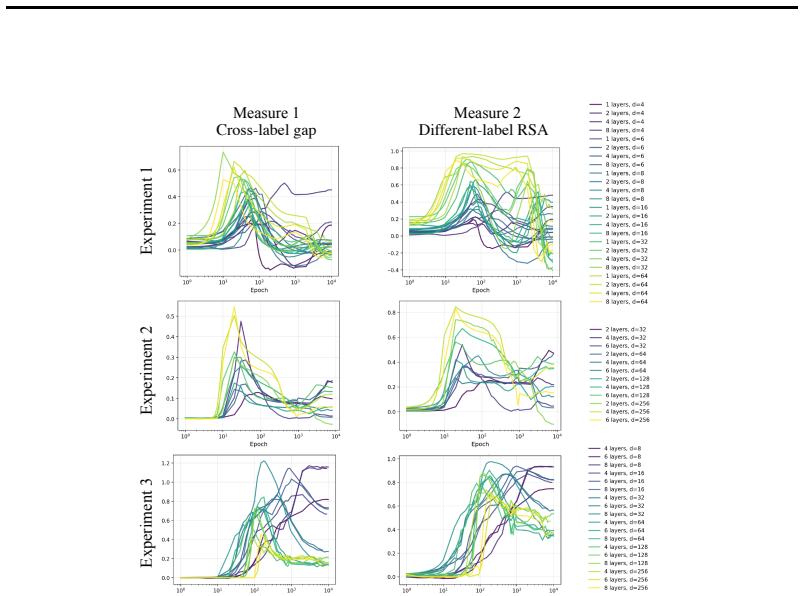
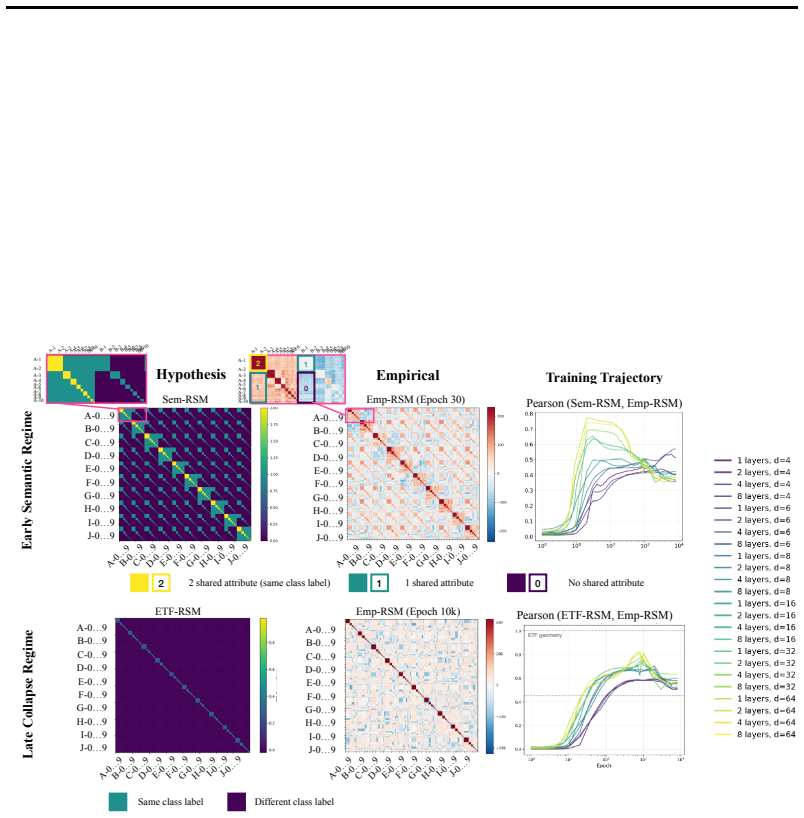
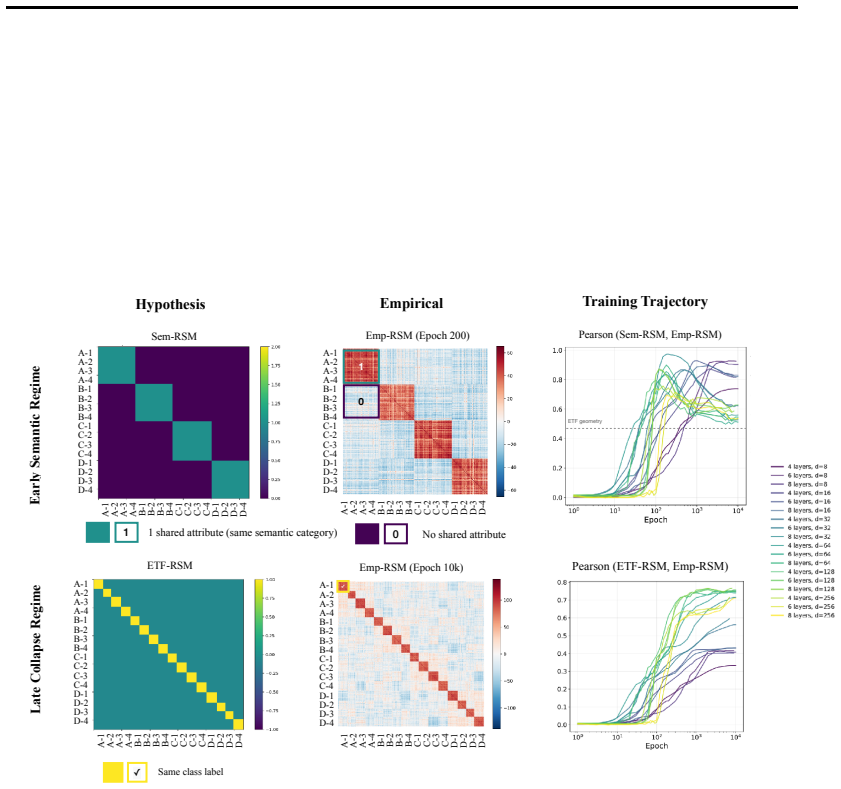
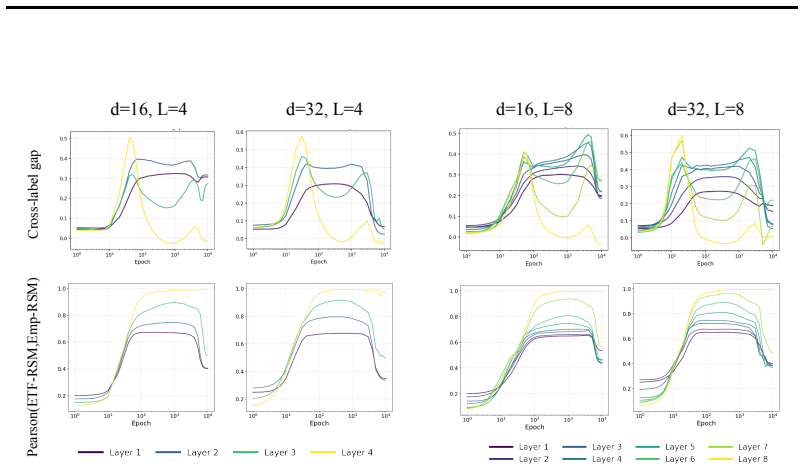
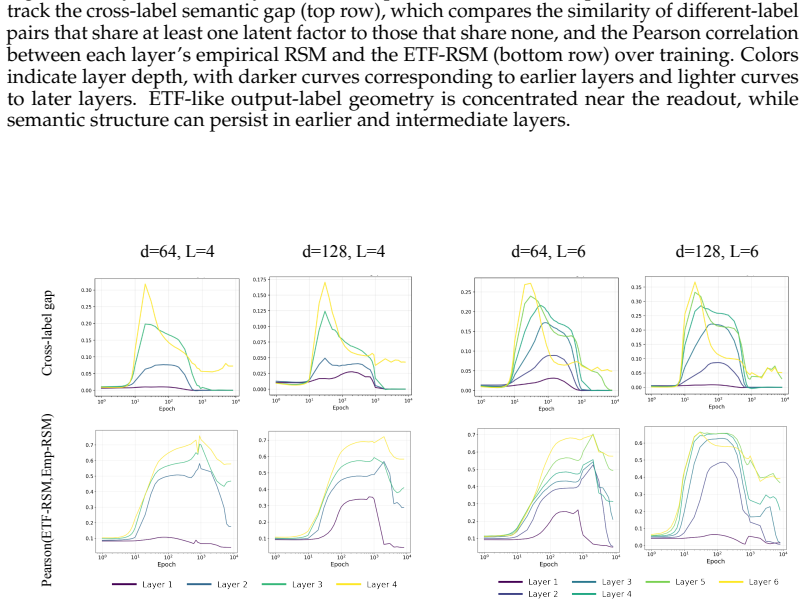
In three controlled synthetic settings with latent semantic factors mapped to distinct one-hot labels, gradient descent produces representations that cluster according to shared attributes early in training. These clusters are visible in Gram matrix analysis and persist until sufficient training drives the model to the symmetric configuration where all class representations are equidistant, consistent with neural collapse predictions. A modification to the unconstrained features model is proposed to account for this emergent geometry.
What carries the argument
The transient semantic geometry in which representations cluster by latent input attributes before equalizing, tracked through Gram matrix analysis.
If this is right
- Representations initially reflect shared latent attributes among inputs rather than depending solely on their one-hot labels.
- The symmetric equidistant state predicted by neural collapse is reached only after an initial structured phase.
- Gram matrix analysis can detect the duration of the semantic clustering phase.
- A modified unconstrained features model can reproduce both the early clustering and the later collapse.
Where Pith is reading between the lines
- If similar early clustering occurs during pretraining on natural text, it could explain how language models acquire semantic categories despite sparse label overlap.
- Varying model capacity or stopping training early might preserve more of the semantic structure for downstream use.
- The same transient clustering could appear in other one-hot supervised tasks that contain hidden similarities among inputs.
Load-bearing premise
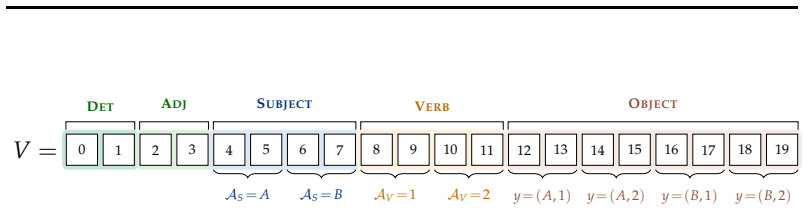
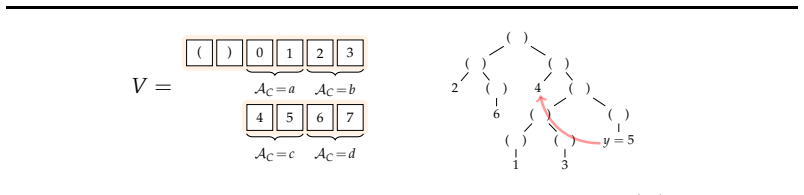
The three synthetic controlled settings with latent semantic factors and distinct one-hot labels sufficiently capture the relevant training dynamics of next-token prediction in language models on natural data.
What would settle it
Training a next-token model on one of the described synthetic datasets and observing either no early clustering by latent factors in the representations or no later transition to equal separation.
Figures
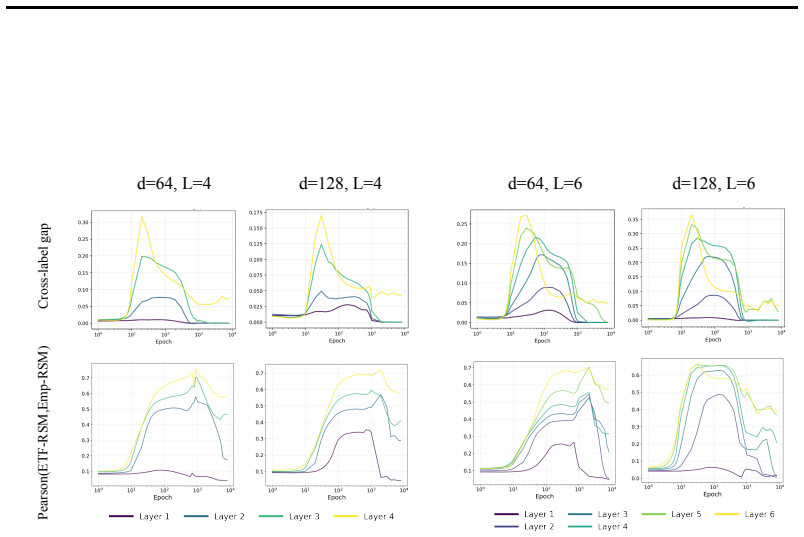
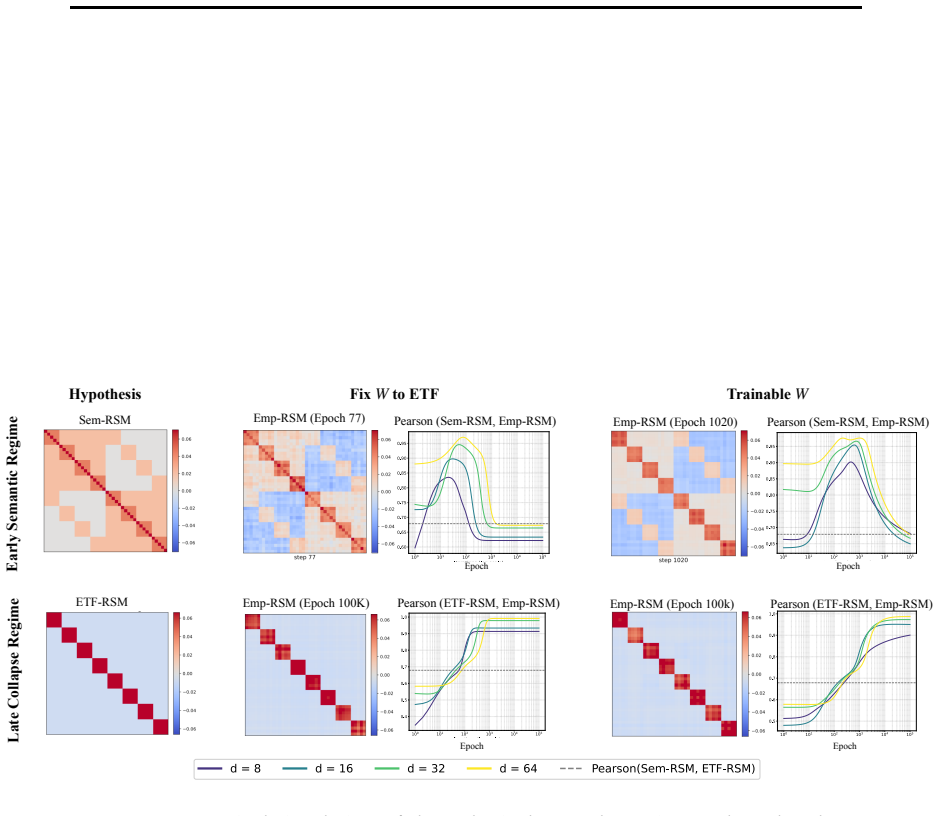
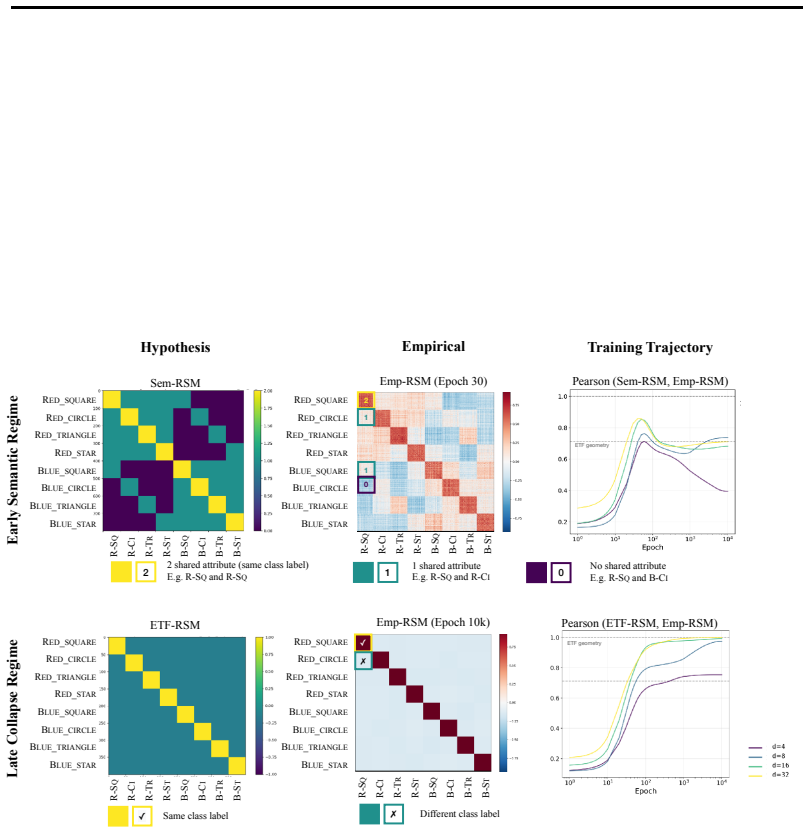
read the original abstract
Neural Collapse predicts that balanced one-hot classification pushes model representations to be equally far from each other; a symmetric configuration that depends only on the output label and ignores any semantic similarity in the inputs. This creates a puzzle: next-token prediction language models are trained predominantly (as context length increases) with one-hot labels: the same context is very unlikely to appear twice in training with different labels. However, they clearly learn latent structural features. That is, despite the one-hot training regime, a language model's contextual embeddings represent the fact that the next word in ''Mary broke the ___'' is likely to be filled by tokens in the latent classes of a) medium-sized, b) rigid, c) inanimate nouns. How does gradient descent find such categorical semantic structure when co-occurrence statistics collapse to one-hot sparsity, eliminating any shared next-tokens among different contexts? To investigate this tension we identify three synthetic controlled settings where inputs have latent semantic factors but are mapped to distinct one-hot labels. We find that semantic geometry emerges early in training, and that representations cluster by shared attributes despite receiving no explicit supervision to do so. This structure is transient: with sufficient capacity and time, the model eventually reaches the predicted symmetric state where all representations are equally separated. We study this phase transition through Gram matrix analysis and propose a preliminary modification to the commonly used unconstrained features model to capture the emergent semantic geometry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that despite the one-hot nature of next-token prediction (which should drive Neural Collapse to symmetric, label-dependent representations), semantic geometry emerges early in training: in three synthetic controlled settings with latent semantic factors mapped to distinct one-hot labels, representations cluster by shared attributes with no explicit supervision. This structure is transient; with sufficient capacity and time the model reaches the predicted symmetric state. The phase transition is analyzed via Gram matrices, and a preliminary modification to the unconstrained-features model is proposed to capture the emergent geometry.
Significance. If the central empirical observation holds, the work addresses a genuine tension between Neural Collapse predictions and the semantic structure learned by language models. The controlled synthetic experiments and Gram-matrix analysis isolate the effect of latent factors under one-hot supervision and identify a transient phase before collapse; this is a concrete, falsifiable contribution to the NC literature. Credit is due for the reproducible synthetic protocol and the attempt to extend the unconstrained-features model.
major comments (2)
- [Abstract] Abstract and experimental sections: the central claim that the observed early clustering explains semantic structure in next-token prediction on natural data rests on the assumption that the three synthetic settings (distinct one-hot targets for inputs sharing latent factors) capture the relevant dynamics. This assumption is load-bearing because the Gram-matrix analysis and the proposed unconstrained-features modification are derived under strict one-hot separation; any residual next-token overlap present in natural text could alter the predicted phase transition.
- [Results] Experimental results: the abstract and results report only qualitative observations of clustering and collapse. No quantitative metrics (e.g., within-cluster vs. between-cluster distances, silhouette scores, or Gram-matrix eigenvalue trajectories with error bars across random seeds) are supplied, making it impossible to assess the statistical reliability or timing of the reported transient geometry.
minor comments (2)
- The description of the proposed modification to the unconstrained-features model would benefit from an explicit equation or pseudocode showing how the semantic-factor term is added to the loss.
- Dataset generation details (exact latent-factor cardinalities, context lengths, and vocabulary sizes for the three synthetic settings) should be stated explicitly to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential contribution and for the constructive major comments. We respond to each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the central claim that the observed early clustering explains semantic structure in next-token prediction on natural data rests on the assumption that the three synthetic settings (distinct one-hot targets for inputs sharing latent factors) capture the relevant dynamics. This assumption is load-bearing because the Gram-matrix analysis and the proposed unconstrained-features modification are derived under strict one-hot separation; any residual next-token overlap present in natural text could alter the predicted phase transition.
Authors: The synthetic protocols are constructed precisely to enforce the one-hot separation that defines the Neural Collapse regime while still embedding latent semantic factors, thereby isolating the mechanism that could resolve the stated tension. We do not claim these settings are a complete proxy for natural text; rather, they demonstrate that transient semantic geometry is possible under the strict one-hot condition that dominates next-token prediction. Any effect of residual overlaps in natural data would be a natural extension, but lies outside the scope of the controlled study. We will revise the abstract and discussion sections to state this scope more explicitly. revision: partial
-
Referee: [Results] Experimental results: the abstract and results report only qualitative observations of clustering and collapse. No quantitative metrics (e.g., within-cluster vs. between-cluster distances, silhouette scores, or Gram-matrix eigenvalue trajectories with error bars across random seeds) are supplied, making it impossible to assess the statistical reliability or timing of the reported transient geometry.
Authors: The referee correctly notes the absence of quantitative metrics. In the revised manuscript we will add silhouette scores, within- versus between-cluster distance ratios, and Gram-matrix eigenvalue trajectories plotted with error bars across multiple random seeds to provide statistical support for the timing and reliability of the observed phase transition. revision: yes
Circularity Check
No significant circularity; claims rest on empirical synthetic experiments and analysis.
full rationale
The paper investigates the tension between Neural Collapse and semantic structure in next-token prediction via three synthetic controlled settings where inputs have latent factors but map to distinct one-hot labels. It reports empirical observations of early clustering by attributes, followed by eventual symmetric collapse, analyzed via Gram matrices and a proposed modification to the unconstrained features model. No load-bearing step reduces by construction to its inputs, self-citation chains, or fitted parameters renamed as predictions; the central results are direct experimental findings under the stated one-hot regime rather than derived equivalences.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Information and Inference: A Journal of the IMA , volume=
Robust implicit regularization via weight normalization , author=. Information and Inference: A Journal of the IMA , volume=. 2024 , publisher=
2024
-
[2]
The Thirty Sixth Annual Conference on Learning Theory , pages=
The implicit bias of batch normalization in linear models and two-layer linear convolutional neural networks , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
2023
-
[3]
arXiv preprint arXiv:2410.04887 , year=
Wide neural networks trained with weight decay provably exhibit neural collapse , author=. arXiv preprint arXiv:2410.04887 , year=
-
[4]
arXiv preprint arXiv:2505.15239 , year=
Neural collapse is globally optimal in deep regularized resnets and transformers , author=. arXiv preprint arXiv:2505.15239 , year=
-
[5]
Journal of Machine Learning Research , volume=
The implicit bias of gradient descent on separable data , author=. Journal of Machine Learning Research , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Norm matters: efficient and accurate normalization schemes in deep networks , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Machine Learning , pages=
Are neurons actually collapsed? on the fine-grained structure in neural representations , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
Advances in Neural Information Processing Systems , volume=
Linguistic collapse: Neural collapse in (large) language models , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2505.00661 , year=
On the generalization of language models from in-context learning and finetuning: a controlled study , author=. arXiv preprint arXiv:2505.00661 , year=
-
[10]
Journal of Artificial Intelligence Research , volume=
Compositionality decomposed: How do neural networks generalise? , author=. Journal of Artificial Intelligence Research , volume=
-
[11]
Transactions of the Association for Computational Linguistics , volume=
Does syntax need to grow on trees? sources of hierarchical inductive bias in sequence-to-sequence networks , author=. Transactions of the Association for Computational Linguistics , volume=. 2020 , publisher=
2020
-
[12]
arXiv preprint arXiv:2109.12036 , year=
Transformers generalize linearly , author=. arXiv preprint arXiv:2109.12036 , year=
-
[13]
Transactions of the Association for Computational Linguistics , volume=
Learning syntax without planting trees: Understanding hierarchical generalization in transformers , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[14]
arXiv preprint arXiv:2503.21676 , year=
How do language models learn facts? dynamics, curricula and hallucinations , author=. arXiv preprint arXiv:2503.21676 , year=
-
[15]
arXiv preprint arXiv:2505.18091 , year=
Data mixing can induce phase transitions in knowledge acquisition , author=. arXiv preprint arXiv:2505.18091 , year=
-
[16]
arXiv preprint arXiv:2601.22510 , year=
Shattered Compositionality: Counterintuitive Learning Dynamics of Transformers for Arithmetic , author=. arXiv preprint arXiv:2601.22510 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Towards a theory of how the structure of language is acquired by deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2410.11474 , year=
How transformers get rich: Approximation and dynamics analysis , author=. arXiv preprint arXiv:2410.11474 , year=
-
[19]
arXiv preprint arXiv:2412.04619 , year=
Sometimes i am a tree: Data drives unstable hierarchical generalization , author=. arXiv preprint arXiv:2412.04619 , year=
-
[20]
Psychonomic bulletin & review , volume=
Zipf’s word frequency law in natural language: A critical review and future directions , author=. Psychonomic bulletin & review , volume=. 2014 , publisher=
2014
-
[21]
, author=
N-gram Counts and Language Models from the Common Crawl. , author=
-
[22]
Computer Speech & Language , volume=
A bit of progress in language modeling , author=. Computer Speech & Language , volume=. 2001 , publisher=
2001
-
[23]
The Thirteenth International Conference on Learning Representations,
Ximing Lu and Melanie Sclar and Skyler Hallinan and Niloofar Mireshghallah and Jiacheng Liu and Seungju Han and Allyson Ettinger and Liwei Jiang and Khyathi Raghavi Chandu and Nouha Dziri and Yejin Choi , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[24]
Papadimitriou, Isabel and Jurafsky, Dan , editor =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , month =. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.554 , pages =
-
[25]
arXiv preprint arXiv:2603.10055 , year=
Training Language Models via Neural Cellular Automata , author=. arXiv preprint arXiv:2603.10055 , year=
-
[26]
2023 , volume=
Physics of Language Models: Part 1, Learning Hierarchical Language Structures , author=. 2023 , volume=
2023
-
[27]
The Eleventh International Conference on Learning Representations , year=
Characterizing intrinsic compositionality in transformers with Tree Projections , author=. The Eleventh International Conference on Learning Representations , year=
-
[28]
arXiv preprint arXiv:2510.02524 , year=
Unraveling Syntax: How Language Models Learn Context-Free Grammars , author=. arXiv preprint arXiv:2510.02524 , year=
-
[29]
Implicit representations of meaning in neural language models , author=. Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (Volume 1: Long papers) , pages=
-
[30]
The Eleventh International Conference on Learning Representations , year =
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task , author =. The Eleventh International Conference on Learning Representations , year =
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Between circuits and chomsky: Pre-pretraining on formal languages imparts linguistic biases , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
2023 , journal =
Injecting structural hints: Using language models to study inductive biases in language learning , author =. 2023 , journal =
2023
-
[33]
Shai, Adam S. and Marzen, Sarah E. and Teixeira, Lucas and Oldenziel, Alexander Gietelink and Riechers, Paul M. , booktitle =. Transformers Represent Belief State Geometry in their Residual Stream , url =. 2024 , pdf =. doi:10.52202/079017-2387 , editor =
-
[34]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Language models learn rare phenomena from less rare phenomena: The case of the missing AANNs , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[35]
Mission: Impossible Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2024 , address =. doi:10.18653/v1/2024.acl-long.787 , pages =
-
[36]
Transactions of the Association for Computational Linguistics , volume=
Filtered corpus training (FiCT) shows that language models can generalize from indirect evidence , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[37]
Semantics and linguistic theory , pages=
More structural analogies between pronouns and tenses , author=. Semantics and linguistic theory , pages=
-
[38]
1985 , publisher=
Logical form: Its structure and derivation , author=. 1985 , publisher=
1985
-
[39]
, author=
Polarity sensitivity as inherent scope relations. , author=. 1979 , publisher=
1979
-
[40]
Chomsky, Noam , title =
-
[41]
1976 , school=
The syntactic domain of anaphora , author=. 1976 , school=
1976
-
[42]
PLoS computational biology , volume=
A toolbox for representational similarity analysis , author=. PLoS computational biology , volume=. 2014 , publisher=
2014
-
[43]
Frontiers in systems neuroscience , volume=
Representational similarity analysis-connecting the branches of systems neuroscience , author=. Frontiers in systems neuroscience , volume=. 2008 , publisher=
2008
-
[44]
arXiv preprint arXiv:2505.08348 , year=
Geometry of Semantics in Next-token Prediction , author=. arXiv preprint arXiv:2505.08348 , year=
-
[45]
arXiv preprint arXiv:2110.02796 , year=
An unconstrained layer-peeled perspective on neural collapse , author=. arXiv preprint arXiv:2110.02796 , year=
-
[46]
arXiv preprint arXiv:2502.04664 , year=
Implicit Bias of SignGD and Adam on Multiclass Separable Data , author=. arXiv preprint arXiv:2502.04664 , year=
-
[47]
Linear algebra and its applications , volume=
Concavity of certain maps on positive definite matrices and applications to Hadamard products , author=. Linear algebra and its applications , volume=. 1979 , publisher=
1979
-
[48]
2013 , publisher=
Matrix analysis , author=. 2013 , publisher=
2013
-
[49]
Advances in neural information processing systems , volume=
Neural word embedding as implicit matrix factorization , author=. Advances in neural information processing systems , volume=
-
[50]
arXiv preprint arXiv:1811.02564 , year=
On exponential convergence of sgd in non-convex over-parametrized learning , author=. arXiv preprint arXiv:1811.02564 , year=
-
[51]
arXiv preprint arXiv:2402.05738 , year=
Implicit bias and fast convergence rates for self-attention , author=. arXiv preprint arXiv:2402.05738 , year=
-
[52]
First Conference on Language Modeling , year=
Implicit Geometry of Next-token Prediction: From Language Sparsity Patterns to Model Representations , author=. First Conference on Language Modeling , year=
-
[53]
arXiv preprint arXiv:2406.10650 , year=
The Implicit Bias of Adam on Separable Data , author=. arXiv preprint arXiv:2406.10650 , year=
-
[54]
arXiv preprint arXiv:2405.13718 , year=
Upper and lower memory capacity bounds of transformers for next-token prediction , author=. arXiv preprint arXiv:2405.13718 , year=
-
[55]
arXiv e-prints , pages=
The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains , author=. arXiv e-prints , pages=
-
[56]
arXiv preprint arXiv:2404.04454 , year=
Implicit Bias of AdamW: ell\_ infty Norm Constrained Optimization , author=. arXiv preprint arXiv:2404.04454 , year=
-
[57]
The 22nd international conference on artificial intelligence and statistics , pages=
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
2019
-
[58]
Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
Glove: Global vectors for word representation , author=. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
2014
-
[59]
Are Transformers with One Layer Self-Attention Using Low-Rank Weight Matrices Universal Approximators? , author=
-
[60]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Effects of Parameter Norm Growth During Transformer Training: Inductive Bias from Gradient Descent , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[61]
2023 , url=
Speech and Language Processing , author=. 2023 , url=
2023
-
[62]
Gemini: A Family of Highly Capable Multimodal Models , author=. , year=
-
[63]
arXiv preprint arXiv:2110.06914 , year=
What Happens after SGD Reaches Zero Loss?--A Mathematical Framework , author=. arXiv preprint arXiv:2110.06914 , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Label noise sgd provably prefers flat global minimizers , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
arXiv preprint arXiv:2402.04161 , year=
Attention with markov: A framework for principled analysis of transformers via markov chains , author=. arXiv preprint arXiv:2402.04161 , year=
-
[66]
arXiv preprint arXiv:2405.04517 , year=
xLSTM: Extended Long Short-Term Memory , author=. arXiv preprint arXiv:2405.04517 , year=
-
[67]
International Conference on Artificial Intelligence and Statistics , pages=
Mechanics of next token prediction with self-attention , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[68]
arXiv preprint arXiv:2312.10794 , year=
A mathematical perspective on Transformers , author=. arXiv preprint arXiv:2312.10794 , year=
-
[69]
arXiv preprint arXiv:2212.14052 , year=
Hungry hungry hippos: Towards language modeling with state space models , author=. arXiv preprint arXiv:2212.14052 , year=
-
[70]
International Conference on Machine Learning , pages=
Same pre-training loss, better downstream: Implicit bias matters for language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[71]
arXiv preprint arXiv:2312.00752 , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
-
[72]
Bell system technical journal , volume=
Prediction and entropy of printed English , author=. Bell system technical journal , volume=. 1951 , publisher=
1951
-
[73]
Joule , volume=
The growing energy footprint of artificial intelligence , author=. Joule , volume=. 2023 , publisher=
2023
-
[74]
arXiv , pages=
GPT-4 technical report , author=. arXiv , pages=
-
[75]
2023 , url =
Deep Ganguli and Nicholas Schiefer and Marina Favaro and Jack Clark , title =. 2023 , url =
2023
-
[76]
arXiv preprint arXiv:2303.15056 , year=
Chatgpt outperforms crowd-workers for text-annotation tasks , author=. arXiv preprint arXiv:2303.15056 , year=
-
[77]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[78]
International Conference on Machine Learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[79]
Can Generative Artificial Intelligence Improve Social Science? , author=
-
[80]
arXiv preprint arXiv:2309.08108 , year=
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting , author=. arXiv preprint arXiv:2309.08108 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.