Streaming Interventions: Can Video Large Language Models Correct Mistakes as They Occur?
Pith reviewed 2026-06-27 16:50 UTC · model grok-4.3
The pith
Fine-tuning video LLMs on synthetic examples of cooking mistakes improves their ability to intervene proactively during tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that transforming non-interactive cooking videos into supervised examples of mistakes paired with appropriately timed interventions creates effective training data for teaching video LLMs to deliver proactive corrections, and that fine-tuning on this data raises performance on a dedicated benchmark for step-by-step task guidance, especially for smaller models suited to edge deployment.
What carries the argument
A counterfactual synthetic dataset that turns standard cooking videos into labeled sequences of mistakes and timed interventions for supervised fine-tuning of video LLMs.
If this is right
- Video LLMs achieve higher accuracy on reactive mistake-correction benchmarks after exposure to the synthetic training examples.
- Smaller models show the clearest improvements, supporting deployment on resource-limited edge hardware for real-time assistance.
- The approach directly tackles the absence of mistake-and-intervention data in existing cooking video collections.
- Proactive intervention becomes feasible for realistic, step-by-step guidance scenarios that current models handle poorly.
Where Pith is reading between the lines
- The same transformation technique could generate training data for guidance in other sequential physical tasks such as assembly or repair if comparable video sources exist.
- On-device models trained this way might lower the rate of user errors in instructional settings by catching problems earlier than cloud-only systems.
- Testing whether the learned intervention timing transfers to entirely new task domains would reveal the breadth of the synthetic-data method.
- Combining the fine-tuned models with live user feedback loops could further refine correction timing without additional manual labeling.
Load-bearing premise
Examples of mistakes and interventions created by editing existing cooking videos will train models that generalize to genuine user errors during live, interactive sessions.
What would settle it
Running the fine-tuned models on recordings of real users performing cooking tasks live while receiving guidance and measuring how often the models correctly flag and correct actual mistakes in those unscripted sessions.
Figures



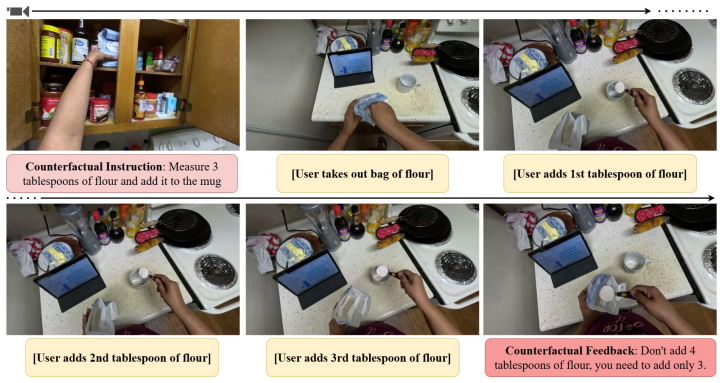

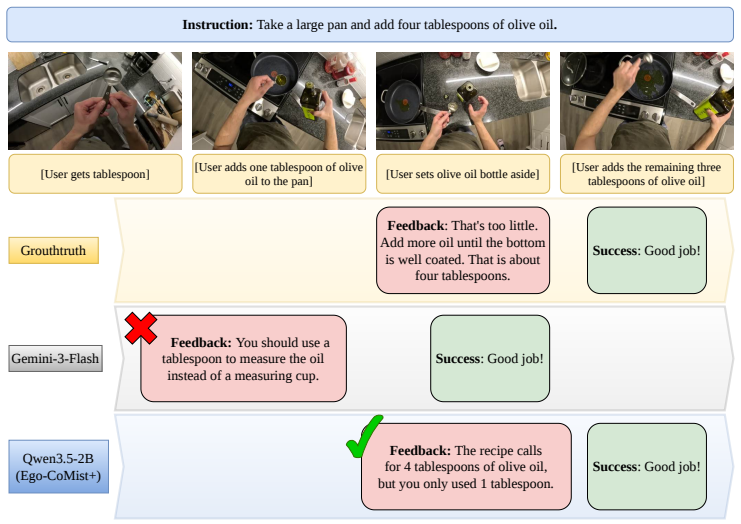

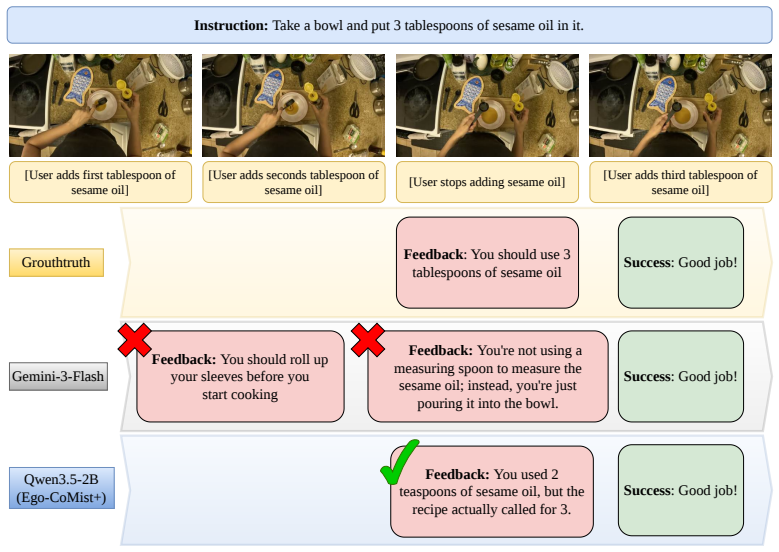
read the original abstract
Learning everyday skills, like cooking a dish, relies increasingly on instructional media such as online videos. This opens the door to the use of video (and multimodal) large language models (LLMs) as task guidance assistants. A crucial capability for the real-world success of a prospective task guidance assistant is it's ability to intervene proactively as soon as a mistake is apparent in order to guide the user. To evaluate this crucial capability, we introduce Ego-MC-Bench (Mistake Corrections), a benchmark for evaluating reactive, step-by-step task guidance in realistic cooking scenarios. Extensive experiments show that Ego-MC-Bench is highly challenging for state-of-the-art video LLMs. We argue that a key reason is the limited availability of training data for fine-tuning models on this task. Although there exists a wide range of cooking video datasets, existing datasets lack examples of mistakes along with appropriately timed interventions. To help address this data limitation, we also introduce Ego-CoMist, a counterfactual synthetic dataset created by transforming non -interactive cooking videos into supervised training examples showing proactive interventions. We show that fine-tuning on Ego-CoMist yields performance gains especially for smaller and more efficient video LLMs that are well suited for delivering assistance on edge devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current video LLMs struggle with proactive, step-by-step mistake correction in realistic cooking tasks; it introduces the Ego-MC-Bench benchmark to evaluate this capability and the Ego-CoMist synthetic dataset (created by inserting mistakes and timed interventions into non-interactive videos) to address the lack of suitable training data; experiments show that fine-tuning on Ego-CoMist produces performance gains, especially for smaller and more efficient models suitable for edge deployment.
Significance. If the synthetic data construction produces a faithful proxy for real user errors and the reported gains transfer, the benchmark and dataset would be useful resources for developing interactive task-guidance systems. The emphasis on gains for smaller models is relevant for practical on-device applications. The work directly targets a data gap for reactive intervention capabilities.
major comments (2)
- [Ego-CoMist construction] Ego-CoMist construction section: the central claim that transforming non-interactive videos produces supervised examples that enable generalization to live user mistakes rests on an unvalidated mapping; no comparison to real-time user error distributions, timings, or live interaction traces is described, leaving the transferability of fine-tuning gains to the intended deployment setting untested.
- [Experiments] Experiments section (and abstract): the headline result that fine-tuning yields gains (especially for smaller models) is presented without the quantitative metrics, baselines, error bars, dataset statistics, or ablation details needed to evaluate effect sizes and reliability; this information is load-bearing for assessing whether the improvements are substantive and model-size-specific.
minor comments (1)
- [Abstract] Abstract: 'it's ability' should read 'its ability'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we address each major comment point-by-point, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Ego-CoMist construction] Ego-CoMist construction section: the central claim that transforming non-interactive videos produces supervised examples that enable generalization to live user mistakes rests on an unvalidated mapping; no comparison to real-time user error distributions, timings, or live interaction traces is described, leaving the transferability of fine-tuning gains to the intended deployment setting untested.
Authors: We agree that the synthetic construction of Ego-CoMist relies on an assumed mapping from non-interactive videos to live mistake scenarios without direct empirical validation against real user error distributions or interaction traces. The paper positions Ego-CoMist as a counterfactual proxy to address the absence of suitable supervised data, and reports gains on the Ego-MC-Bench benchmark. A full validation against live traces would require a separate user-study data collection effort outside the current scope. In revision we will add an explicit limitations paragraph discussing the assumptions underlying the synthetic data and the untested transfer to live deployment. revision: partial
-
Referee: [Experiments] Experiments section (and abstract): the headline result that fine-tuning yields gains (especially for smaller models) is presented without the quantitative metrics, baselines, error bars, dataset statistics, or ablation details needed to evaluate effect sizes and reliability; this information is load-bearing for assessing whether the improvements are substantive and model-size-specific.
Authors: We will revise the experiments section to present all quantitative results with error bars, full baseline comparisons, dataset statistics, and ablation studies in a single consolidated table. We will also update the abstract to include the key numerical findings (e.g., relative gains by model size) so that the headline claim is supported by the reported metrics. revision: yes
Circularity Check
No circularity: empirical benchmark and dataset introduction
full rationale
The paper is a purely empirical study that introduces Ego-MC-Bench and the synthetic Ego-CoMist dataset, then reports fine-tuning gains on video LLMs. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental results that can be independently reproduced from the released data rather than reducing to self-definition or prior author work by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkow...
2022
-
[3]
Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2, 2023
2023
-
[4]
Can foundation models watch, talk and guide you step by step to make a cake? InEMNLP Findings, 2023
Yuwei Bao, Keunwoo Peter Yu, Yichi Zhang, Shane Storks, Itamar Bar-Yossef, Alexander De La Iglesia, Megan Su, Xiao-Lin Zheng, and Joyce Chai. Can foundation models watch, talk and guide you step by step to make a cake? InEMNLP Findings, 2023
2023
-
[5]
Can multi-modal llms provide live step-by-step task guidance? InNeurIPS, 2025
Apratim Bhattacharyya, Bicheng Xu, Sanjay Haresh, Reza Pourreza, Litian Liu, Sunny Panchal, Pulkit Madan, Leonid Sigal, and Roland Memisevic. Can multi-modal llms provide live step-by-step task guidance? InNeurIPS, 2025
2025
-
[6]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InCVPR, 2024
2024
-
[7]
Livecc: Learning video llm with streaming speech transcription at scale
Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, and Mike Zheng Shou. Livecc: Learning video llm with streaming speech transcription at scale. InCVPR, 2025
2025
-
[8]
Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100. InIJCV, 2022
2022
-
[9]
Gemini 3 Flash
Google Deepmind. “Gemini 3 Flash.”. https://deepmind.google/models/gemini/ flash/, 2025. [Online; accessed May-2026]
2025
-
[10]
Streaming video question-answering with in-context video kv-cache retrieval
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, Hao Jiang, et al. Streaming video question-answering with in-context video kv-cache retrieval. InICLR, 2025
2025
-
[11]
Xin Ding, Hao Wu, Yifan Yang, Shiqi Jiang, Donglin Bai, Zhibo Chen, and Ting Cao. Stream- mind: Unlocking full frame rate streaming video dialogue through event-gated cognition.CoRR, abs/2503.06220, 2025
arXiv 2025
-
[12]
Qwen3 technical report.CoRR, abs/2505.09388, 2025
An Yang et al. Qwen3 technical report.CoRR, abs/2505.09388, 2025
Pith/arXiv arXiv 2025
-
[13]
Bai et. al. Qwen3-vl technical report.CoRR, abs/2511.21631, 2025
Pith/arXiv arXiv 2025
-
[14]
Grauman et. al. Ego4d: Around the world in 3,000 hours of egocentric video. InCVPR, 2022
2022
-
[15]
Shuai Bai et. al. Qwen2.5-vl technical report.CoRR, abs/2502.13923, 2025
Pith/arXiv arXiv 2025
-
[16]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, 2025
2025
-
[17]
Vispeak: Visual instruction feedback in streaming videos
Shenghao Fu, Qize Yang, Yuan-Ming Li, Yi-Xing Peng, Kun-Yu Lin, Xihan Wei, Jian-Fang Hu, Xiaohua Xie, and Wei-Shi Zheng. Vispeak: Visual instruction feedback in streaming videos. In ICCV, 2025. 10
2025
-
[18]
The llama 3 herd of models.CoRR, abs/2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.CoRR, abs/2407.21783, 2024
Pith/arXiv arXiv 2024
-
[19]
Ego4d: Around the world in 3, 000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagara- jan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, et al. Ego4d: Around the...
2022
-
[20]
Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Tri- antafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives. CoRR, abs/2311.18259, 2023
arXiv 2023
-
[22]
LION-FS: fast & slow video- language thinker as online video assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, and Liqiang Nie. LION-FS: fast & slow video- language thinker as online video assistant. InCVPR, 2025
2025
-
[23]
Yifei Li, Junbo Niu, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding?CoRR, abs/2501.05510, 2025
arXiv 2025
-
[24]
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. CoRR, abs/2411.03628, 2024
arXiv 2024
-
[25]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InICCV, 2019
2019
-
[26]
Zhenyu Ning, Guangda Liu, Qihao Jin, Wenchao Ding, Minyi Guo, and Jieru Zhao. Livevlm: Efficient online video understanding via streaming-oriented KV cache and retrieval.CoRR, abs/2505.15269, 2025
Pith/arXiv arXiv 2025
-
[27]
Introducing GPT-5.2
OpenAI. “Introducing GPT-5.2.”. https://openai.com/index/introducing-gpt-5-2/ ,
-
[28]
[Online; accessed March-2025]
2025
-
[29]
What to say and when to say it: Live fitness coaching as a testbed for situated interaction
Sunny Panchal, Apratim Bhattacharyya, Guillaume Berger, Antoine Mercier, Cornelius Böhm, Florian Dietrichkeit, Reza Pourreza, Xuanlin Li, Pulkit Madan, Mingu Lee, Mark Todorovich, Ingo Bax, and Roland Memisevic. What to say and when to say it: Live fitness coaching as a testbed for situated interaction. InNeurIPS, 2024
2024
-
[30]
What to say and when to say it: Live fitness coaching as a testbed for situated interaction
Sunny Panchal, Apratim Bhattacharyya, Guillaume Berger, Antoine Mercier, Cornelius Bohm, Florian Dietrichkeit, Reza Pourreza, Xuanlin Li, Pulkit Madan, Mingu Lee, Mark Todorovich, Ingo Bax, and Roland Memisevic. What to say and when to say it: Live fitness coaching as a testbed for situated interaction. InNeurIPS, 2024
2024
-
[31]
Ragan, Nicholas Ruozzi, Yu Xiang, and Vibhav Gogate
Rohith Peddi, Shivvrat Arya, Bharath Challa, Likhitha Pallapothula, Akshay Vyas, Bhavya Gouripeddi, Qifan Zhang, Jikai Wang, Vasundhara Komaragiri, Eric D. Ragan, Nicholas Ruozzi, Yu Xiang, and Vibhav Gogate. Captaincook4d: A dataset for understanding errors in procedural activities. InNeurIPS, 2024
2024
-
[32]
Qwen3.5: Towards Native Multimodal Agents
QwenTeam. “Qwen3.5: Towards Native Multimodal Agents.”. https://qwen.ai/blog?id= qwen3.5, 2026. [Online; accessed May-2026]
2026
-
[33]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities. InCVPR, 2022. 11
2022
-
[34]
A simple baseline for streaming video understanding.CoRR, abs/2604.02317, 2026
Yujiao Shen, Shulin Tian, Jingkang Yang, and Ziwei Liu. A simple baseline for streaming video understanding.CoRR, abs/2604.02317, 2026
arXiv 2026
-
[35]
Ego4d goal-step: Toward hierarchical understanding of procedural activities
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Torresani. Ego4d goal-step: Toward hierarchical understanding of procedural activities. In NeurIPS, 2023
2023
-
[36]
COIN: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. COIN: A large-scale dataset for comprehensive instructional video analysis. In CVPR, 2019
2019
-
[37]
Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.CoRR, abs/2507.06261, 2025
Pith/arXiv arXiv 2025
-
[38]
Gemini: A family of highly capable multimodal models.CoRR, abs/2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: A family of highly capable multimodal models.CoRR, abs/2312.11805, 2023
Pith/arXiv arXiv 2023
-
[39]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.CoRR, abs/2403.05530, 2024
Pith/arXiv arXiv 2024
-
[40]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.CoRR, abs/2409.12191, 2024
Pith/arXiv arXiv 2024
-
[41]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.CoRR, abs/2508.18265, 2025
Pith/arXiv arXiv 2025
-
[42]
Holoassist: an egocentric human interaction dataset for interactive AI assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, and Marc Pollefeys. Holoassist: an egocentric human interaction dataset for interactive AI assistants in the real world. InICCV, 2023
2023
-
[43]
Om- nimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts, 2025
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Om- nimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts, 2025
2025
-
[44]
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Xiao Wang, Keze Wang, and Liang Lin. Towards top-down reasoning: An explainable multi-agent approach for visual question answering.CoRR, abs/2311.17331, 2025
arXiv 2025
-
[45]
Longvideobench: A benchmark for long-context interleaved video-language understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding. InNeurIPS, 2024
2024
-
[46]
Streaming video instruction tuning.CoRR, abs/2512.21334, 2025
Jiaer Xia, Peixian Chen, Mengdan Zhang, Xing Sun, and Kaiyang Zhou. Streaming video instruction tuning.CoRR, abs/2512.21334, 2025
Pith/arXiv arXiv 2025
-
[47]
Qwen3-omni technical report.CoRR, abs/2501.13826, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.CoRR, abs/2501.13826, 2025
Pith/arXiv arXiv 2025
-
[48]
Streamingvlm: Real-time understanding for infinite video streams.CoRR, abs/2510.09608, 2025
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. Streamingvlm: Real-time understanding for infinite video streams.CoRR, abs/2510.09608, 2025
Pith/arXiv arXiv 2025
-
[49]
Zhenyu Yang, Yuhang Hu, Zemin Du, Dizhan Xue, Shengsheng Qian, Jiahong Wu, Fan Yang, Weiming Dong, and Changsheng Xu. Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding.CoRR, abs/2502.10810, 2025
arXiv 2025
-
[50]
Videollama 3: Frontier multimodal foundation models for image and video understanding, 2025
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. Videollama 3: Frontier multimodal foundation models for image and video understanding, 2025. 12
2025
-
[51]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory-based real-time understanding for long video streams.CoRR, abs/2406.08085, 2025
arXiv 2025
-
[52]
Proactive assistant dialogue generation from streaming egocentric videos
Yichi Zhang, Xin Luna Dong, Zhaojiang Lin, Andrea Madotto, Anuj Kumar, Babak Damavandi, Joyce Chai, and Seungwhan Moon. Proactive assistant dialogue generation from streaming egocentric videos. InEMNLP, 2025
2025
-
[53]
turn-based
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. InAAAI, 2018. 13 A Appendix Here we provide: 1. Additional examples from our EGO-MC-BENCHbenchmark. 2. Additional qualitative examples from state of the art models on our EGO-MC-BENCHbenchmark. 3. Additional details of the evaluation of “tur...
2018
-
[54]
Preparation Error: A setup mistake before executing the step . Using the wrong or dirty uten- sil, not washing/peeling/draining ingredients, insufficient draining of fluid, cutting/chopping without peeling which makes correct execution difficult or unsafe
-
[55]
Mixing up teaspoons and tablespoons, misreading a scale, or miscounting items leads to off ratios and predictable taste or texture problems
Measurement Error: An error in quantity — wrong counts, volumes, weights, or units. Mixing up teaspoons and tablespoons, misreading a scale, or miscounting items leads to off ratios and predictable taste or texture problems
-
[56]
Not preheating, using the wrong mi- crowave power, overheating oil, or adding cold liquid when warm is required often causes burning, undercooking, or split emulsions
Temperature Error: A mistake in heat level or thermal state — the applied temperature, starting temperature, or thermal transition is wrong. Not preheating, using the wrong mi- crowave power, overheating oil, or adding cold liquid when warm is required often causes burning, undercooking, or split emulsions
-
[57]
turn-based
Timing Error: A mistake in duration – over- or under-doing a step or skipping required rests, proofs, or cooling periods. Overcooking, underblending, or cutting resting time short typically yields incorrect doneness or unstable textures. Do not repeat previously detected mistakes. Here are the feedbacks corresponding to previ- ously detected mistakes:[pre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.