Two-Fidelity Best-Action Identification for Stochastic Minimax Tree
Pith reviewed 2026-06-28 15:17 UTC · model grok-4.3
The pith
The 2FFS algorithm identifies the best action in stochastic minimax trees at fixed confidence by adaptively mixing cheap biased evaluations with expensive accurate ones and proves a polynomial cost bound in tree depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
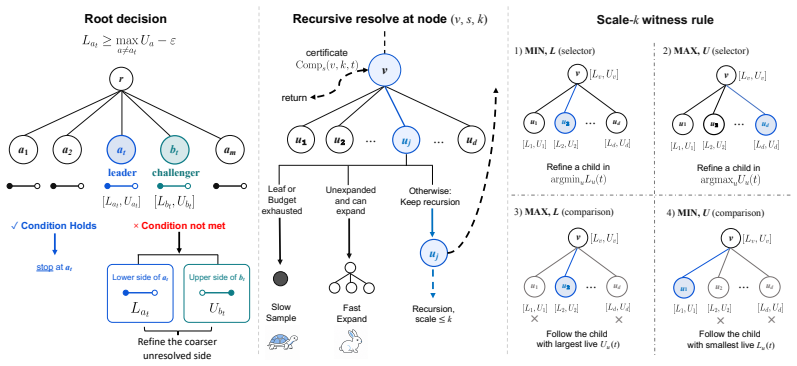
2FFS brings multi-fidelity bandit ideas into trees by combining minimax-style fast expansion with MCTS-style stochastic sampling and an adaptive rule that decides when to trust cheap biased evaluations versus when to invoke expensive accurate evaluations for local certification; the resulting procedure satisfies fixed-confidence correctness, guarantees finite stopping for exact identification, and admits a polynomial-depth cost upper bound for trees of arbitrary depth.
What carries the argument
The 2FFS adaptive switching rule that decides between cheap biased heuristic evaluations for rapid expansion and expensive accurate evaluations for local certification.
If this is right
- Fixed-confidence correctness is guaranteed for the returned action.
- The algorithm stops after a finite number of evaluations for any fixed tree.
- Total cost remains bounded by a polynomial in tree depth.
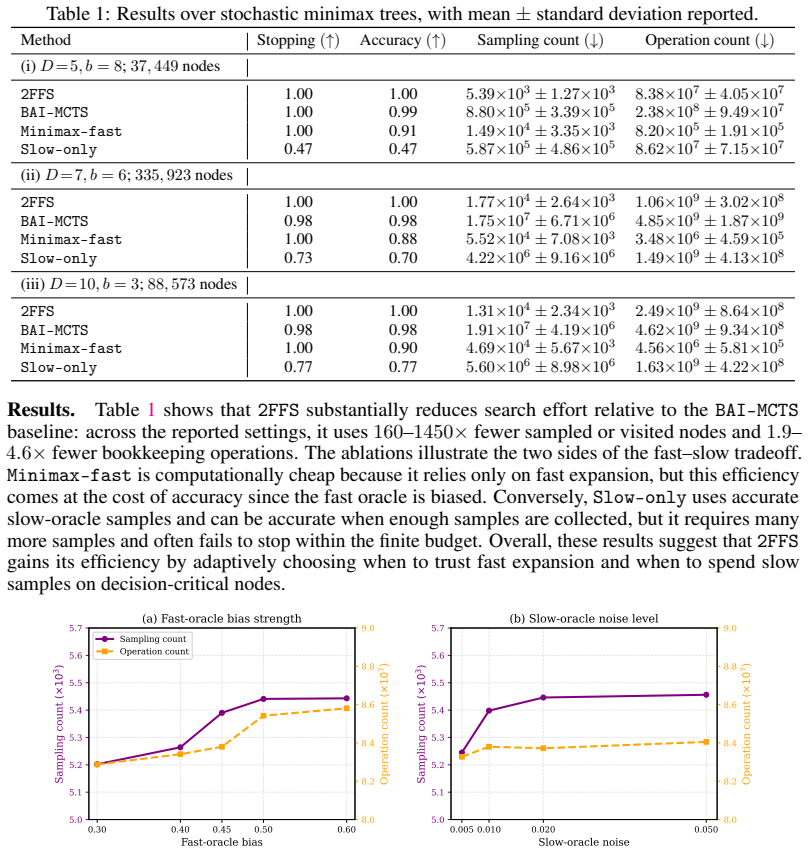
- Empirical sample and operation counts are lower than those of a standard BAI-MCTS baseline on the tested stochastic trees.
Where Pith is reading between the lines
- The same switching logic could be applied to trees whose leaves are evaluated by expensive language-model rollouts rather than exact simulation.
- The polynomial bound suggests that two-fidelity search remains tractable even when heuristic bias grows with depth, provided the expensive evaluations can still certify local subtrees.
- If the bias of the cheap evaluations is bounded in a known way, tighter concentration inequalities might replace the current stopping thresholds.
Load-bearing premise
The adaptive rule for switching between the two fidelities continues to preserve the fixed-confidence guarantee and the polynomial cost bound no matter how deep the tree becomes.
What would settle it
A sequence of stochastic trees of increasing depth in which 2FFS either stops with the wrong action or consumes more than polynomially many expensive evaluations.
Figures
read the original abstract
We study fixed-confidence best-action identification (BAI) in stochastic minimax trees. This problem is increasingly relevant in modern AI planning, where deep minimax search and Monte Carlo Tree Search (MCTS) with language model long rollouts face a fundamental tradeoff: heuristic evaluations are cheap but biased, while accurate rollouts are reliable but prohibitively expensive. We propose 2FFS, a two-fidelity tree-search algorithm that brings multi-fidelity flat bandit ideas into trees. The algorithm combines minimax-style fast expansion with MCTS-style stochastic sampling, adaptively deciding when to exploit cheap biased evaluations and when to invoke expensive accurate evaluations for local certification. We prove fixed-confidence correctness, establish finite stopping for exact identification, and give a polynomial-depth cost upper bound for general-depth trees. Across numerical stochastic-tree experiments, 2FFS uses substantially fewer samples and computational operations comparing to existing BAI-MCTS baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the 2FFS algorithm for fixed-confidence best-action identification in stochastic minimax trees. It integrates multi-fidelity ideas by adaptively using cheap biased low-fidelity evaluations for fast expansion and expensive high-fidelity evaluations for certification. The authors claim to establish correctness with fixed confidence, finite stopping for exact identification, a polynomial cost bound in tree depth, and demonstrate empirical sample efficiency gains over BAI-MCTS baselines in numerical experiments.
Significance. If the polynomial cost bound holds under the stated assumptions, this work would be significant for applications in AI planning involving deep minimax search with costly accurate evaluations, such as those using language model rollouts. The theoretical contributions of proving fixed-confidence guarantees and finite stopping times for tree-structured problems extend multi-fidelity bandit methods to more complex settings. The empirical results indicate practical utility, though the significance depends on verifying the analysis against potential bias issues in deep trees.
major comments (1)
- [Theoretical results on cost bound] The derivation of the polynomial-depth cost upper bound (stated in the abstract) requires explicit handling of how the adaptive switching rule prevents super-polynomial high-fidelity invocations due to uncontrolled bias accumulation across depths; without bounding depth-dependent bias-variance interactions, the claim that the bound holds for general-depth trees is at risk.
minor comments (1)
- [Abstract] The abstract contains a grammatical error: 'comparing to' should read 'compared to'.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our work on two-fidelity best-action identification in stochastic minimax trees. We address the single major comment below.
read point-by-point responses
-
Referee: The derivation of the polynomial-depth cost upper bound (stated in the abstract) requires explicit handling of how the adaptive switching rule prevents super-polynomial high-fidelity invocations due to uncontrolled bias accumulation across depths; without bounding depth-dependent bias-variance interactions, the claim that the bound holds for general-depth trees is at risk.
Authors: We appreciate the referee's focus on the cost bound analysis. The proof of the polynomial-depth upper bound (Theorem 4, Section 4) incorporates the adaptive switching rule by defining high-fidelity invocations via a bias-adjusted concentration bound. Specifically, the switching threshold at each node accounts for the low-fidelity bias term (Assumption 2, which states the bias is a fixed property of the evaluator and independent of depth). This prevents uncontrolled accumulation because the number of high-fidelity calls per level is limited by the fixed-confidence requirement and the recursive minimax structure; an inductive argument then yields an overall polynomial dependence on depth D. Depth-dependent variance interactions are controlled through the finite stopping time property established earlier in the analysis. We maintain that the bound holds for general-depth trees under the stated assumptions and do not view the claim as at risk. To improve clarity, we will add a short remark in the proof sketch highlighting the role of the depth-independent bias assumption. revision: partial
Circularity Check
No circularity: claims rest on new algorithmic construction and external-style analysis
full rationale
The provided abstract and reader's summary contain no equations, fitted parameters, or self-citations that reduce the stated proofs (fixed-confidence correctness, finite stopping, polynomial-depth cost bound) to inputs by construction. The algorithm 2FFS is presented as a novel combination of existing ideas with new adaptive switching, and the bounds are claimed as derived results rather than redefinitions or renamings. No load-bearing step matches any of the enumerated circularity patterns; the work is self-contained against the described benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard stochastic assumptions (e.g., bounded or sub-Gaussian rewards) typical for fixed-confidence BAI.
invented entities (1)
-
2FFS algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kandasamy, G
K. Kandasamy, G. Dasarathy, B. Poczos, and J. Schneider. The multi-fidelity multi-armed bandit.NeurIPS, 2016
2016
-
[2]
Poiani, A
R. Poiani, A. M. Metelli, and M. Restelli. Multi-fidelity best-arm identification.NeurIPS, 2022
2022
-
[3]
X. Wang, Q. Wu, W. Chen, and J. Lui. Multi-fidelity multi-armed bandits revisited.NeurIPS, 2023
2023
-
[4]
Poiani, R
R. Poiani, R. Degenne, E. Kaufmann, A. M. Metelli, and M. Restelli. Optimal multi-fidelity best-arm identification.NeurIPS, 2024
2024
-
[5]
Kaufmann and W
E. Kaufmann and W. M. Koolen. Monte-carlo tree search by best arm identification.NeurIPS, 2017
2017
-
[6]
D. E. Knuth and R. W. Moore. An analysis of alpha-beta pruning.Artificial Intelligence, 1975
1975
-
[7]
G. M. Baudet. An analysis of the full alpha-beta pruning algorithm.STOC, 1978
1978
-
[8]
Kocsis and C
L. Kocsis and C. Szepesvári. Bandit based monte-carlo planning.ECML, 2006
2006
-
[9]
Lanctot, M
M. Lanctot, M. H. M. Winands, T. Pepels, and N. R. Sturtevant. Monte carlo tree search with heuristic evaluations using implicit minimax backups.2014 IEEE Conference on Computational Intelligence and Games, 2014
2014
-
[10]
J. Pearl. On the nature of pathology in game searching.Artificial Intelligence, 1983
1983
-
[11]
Kandasamy, G
K. Kandasamy, G. Dasarathy, J. B. Oliva, J. Schneider, and B. Poczos. Gaussian process bandit optimisation with multi-fidelity evaluations.NeurIPS, 2016
2016
-
[12]
Kandasamy, G
K. Kandasamy, G. Dasarathy, J. Schneider, and B. Póczos. Multi-fidelity bayesian optimisation with continuous approximations.ICML, 2017
2017
-
[13]
Garivier and E
A. Garivier and E. Kaufmann. Optimal best arm identification with fixed confidence.COLT, 2016
2016
-
[14]
S. R. Howard, A. Ramdas, J. McAuliffe, and J. Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics, 2021
2021
-
[15]
Kaufmann and W
E. Kaufmann and W. M. Koolen. Mixture martingales revisited with applications to sequential tests and confidence intervals.JMLR, 2021
2021
-
[16]
Audibert, S
J.-Y . Audibert, S. Bubeck, and R. Munos. Best arm identification in multi-armed bandits.COLT, 2010
2010
-
[17]
Jamieson, M
K. Jamieson, M. Malloy, R. Nowak, and S. Bubeck. lil’ ucb: An optimal exploration algorithm for multi-armed bandits.COLT, 2014
2014
-
[18]
Kaufmann, O
E. Kaufmann, O. Cappé, and A. Garivier. On the complexity of best-arm identification in multi-armed bandit models.JMLR, 2016
2016
-
[19]
Gabillon, M
V . Gabillon, M. Ghavamzadeh, and A. Lazaric. Best arm identification: A unified approach to fixed budget and fixed confidence.NeurIPS, 2012
2012
-
[20]
Kalyanakrishnan, A
S. Kalyanakrishnan, A. Tewari, P. Auer, and P. Stone. Pac subset selection in stochastic multi-armed bandits.ICML, 2012
2012
-
[21]
Even-Dar, S
E. Even-Dar, S. Mannor, and Y . Mansour. Action elimination and stopping conditions for the multi-armed bandit and reinforcement learning problems.JMLR, 2006
2006
-
[22]
Poloczek, J
M. Poloczek, J. Wang, and P. Frazier. Multi-information source optimization.NeurIPS, 2017
2017
-
[23]
S. Li, W. Xing, R. Kirby, and S. Zhe. Multi-fidelity bayesian optimization via deep neural networks.NeurIPS, 2020. 10
2020
-
[24]
R. Sen, K. Kandasamy, and S. Shakkottai. Multi-fidelity black-box optimization with hierarchi- cal partitions.ICML, 2018
2018
-
[25]
Fiegel, V
C. Fiegel, V . Gabillon, and M. Valko. Adaptive multi-fidelity optimization with fast learning rates.AISTATS, 2020
2020
-
[26]
R. Sen, K. Kandasamy, and S. Shakkottai. Noisy blackbox optimization using multi-fidelity queries: A tree search approach.AISTATS, 2019
2019
-
[27]
Degenne, W
R. Degenne, W. M. Koolen, and P. Ménard. Non-asymptotic pure exploration by solving games. NeurIPS, 2019
2019
-
[28]
Ghosh, M
D. Ghosh, M. K. Hanawal, and N. Zlatanov. Fixed budget best arm identification in unimodal bandits.TMLR, 2024
2024
-
[29]
Poiani, M
R. Poiani, M. Jourdan, E. Kaufmann, and R. Degenne. Best-arm identification in unimodal bandits.AISTATS, 2025
2025
-
[30]
Kanarios, Q
K. Kanarios, Q. Zhang, and L. Ying. Cost aware best arm identification.RLC, 2024
2024
-
[31]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization.JMLR, 2018
2018
-
[32]
Jamieson and A
K. Jamieson and A. Talwalkar. Non-stochastic best arm identification and hyperparameter optimization.AISTATS, 2016
2016
-
[33]
Falkner, A
S. Falkner, A. Klein, and F. Hutter. Bohb: Robust and efficient hyperparameter optimization at scale.ICML, 2018
2018
-
[34]
L. Li, K. Jamieson, A. Rostamizadeh, E. Gonina, J. Ben-Tzur, M. Hardt, B. Recht, and A. Talwalkar. A system for massively parallel hyperparameter tuning.MLSys, 2020
2020
-
[35]
H. E. Robbins. Some aspects of the sequential design of experiments.Bulletin of the American Mathematical Society, 58:527–535, 1952
1952
-
[36]
Bonfiglio, P
L. Bonfiglio, P. Perdikaris, S. Brizzolara, and G. E. Karniadakis. Multi-fidelity optimization of super-cavitating hydrofoils.Computer Methods in Applied Mechanics and Engineering, 2018
2018
-
[37]
Réthoré, P
P.-E. Réthoré, P. Fuglsang, G. C. Larsen, T. Buhl, T. J. Larsen, and H. A. Madsen. Topfarm: Multi-fidelity optimization of wind farms.Wind Energy, 2014
2014
-
[38]
Zheng, T
L. Zheng, T. L. Hedrick, and R. Mittal. A multi-fidelity modelling approach for evaluation and optimization of wing stroke aerodynamics in flapping flight.Journal of Fluid Mechanics, 2013
2013
-
[39]
Z. Tang, D. Rybin, and T.-H. Chang. Zeroth-order optimization meets human feedback: Provable learning via ranking oracles.ICLR, 2024
2024
-
[40]
P. Chen, X. Chen, W. Yin, and T. Lin. ComPO: Preference alignment via comparison oracles. NeurIPS, 2025
2025
-
[41]
T. Lin, C. Jin, and M. I. Jordan. Two-timescale gradient descent ascent algorithms for nonconvex minimax optimization.JMLR, 2025
2025
-
[42]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081): 633–638, 2025
2025
-
[43]
P. Chen, X. Li, Z. Li, X. Chen, and T. Lin. Stepwise guided policy optimization: Coloring your incorrect reasoning in GRPO.TMLR, 2026
2026
-
[44]
Z. Li, C. Chen, T. Yang, T. Ding, R. Sun, G. Zhang, W. Huang, and Z.-Q. Luo. Knapsack RL: Unlocking exploration of LLMs via optimizing budget allocation.ICML, 2026
2026
-
[45]
P. Chen, X. Li, Z. Li, W. Yin, X. Chen, and T. Lin. Exploration vs exploitation: Rethinking rlvr through clipping, entropy, and spurious reward.ICLR, 2026. 11
2026
-
[46]
Reward-free Alignment for Conflicting Objectives
Peter L Chen, Xiaopeng Li, Xi Chen, and Tianyi Lin. Reward-free alignment for conflicting objectives.arXiv preprint arXiv:2602.02495, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
C. Park, Z. Chen, A. Ozdaglar, and K. Zhang. Post-training llms as better decision-making agents: A regret-minimization approach.ICML, 2026. 12 A Further Related Works and Limitations Multi-fidelity bandits and optimization.Multi-fidelity methods study how to allocate queries across information sources with different costs and accuracies. In flat bandit m...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.