Communicability-Inspired Positional Encoding (CIPE)
Pith reviewed 2026-06-25 21:27 UTC · model grok-4.3
The pith
By construction, CIPE positional encodings make their inner products recover communicability, turning global multi-path graph connectivity into attention-ready similarities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
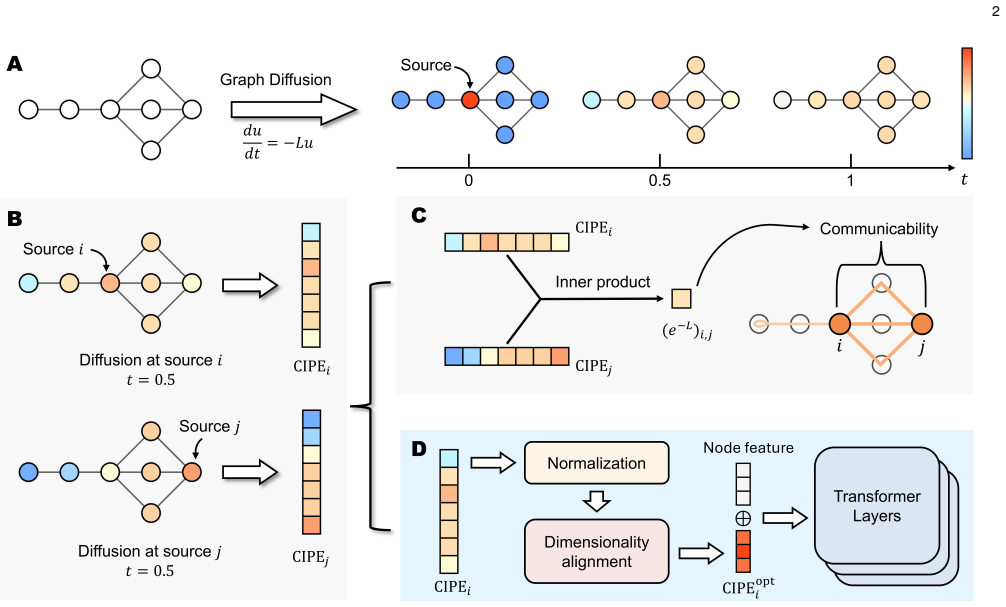
CIPE is constructed from communicability such that the inner product of the positional encodings for any pair of nodes recovers the communicability value between them. This converts the global multi-path connectivity information carried by the communicability matrix into an attention-compatible similarity geometry. Dimensionality alignment then maps the graph-size-dependent encodings to a prescribed dimension while preserving the induced inner-product relations.
What carries the argument
Communicability matrix, whose entries sum normalized contributions over all paths of all lengths; CIPE vectors are chosen so their dot products equal these entries.
If this is right
- Self-attention can directly exploit a global, all-path measure of node relatedness without additional graph layers.
- The same construction improves both structure-agnostic Transformers and those already equipped with graph biases.
- Dimensionality alignment makes the geometry usable in any fixed-dimension attention model.
- Competing positional encodings often produce only marginal benefits once a graph bias is already present.
Where Pith is reading between the lines
- Other path-aggregating measures could be substituted for communicability if their matrices admit similar factorizations.
- The geometry might combine with node features or edge weights without requiring retraining of the alignment step.
- Efficient approximations to communicability would be needed for very large graphs if the method is to scale.
- The approach suggests attention mechanisms gain more from dense global similarities than from strictly local neighborhood encodings.
Load-bearing premise
Communicability supplies the right scalar of structural relatedness for self-attention, and dimensionality alignment preserves enough of the original geometry to keep downstream performance intact.
What would settle it
Measure the inner products of the aligned CIPE vectors and find that they deviate substantially from the original communicability values, or observe that removing graph structure from the input eliminates the reported performance gains.
Figures
read the original abstract
Positional encodings (PEs) are essential for Transformers. Yet designing effective PEs for non-Euclidean graphs remains challenging. Such encodings should ideally induce an Attention-Compatible Geometry for self-attention: not merely describing graph structure, but defining a geometry whose inner products reflect meaningful structural relatedness. To realize this geometry, we propose Communicability-Inspired Positional Encoding (CIPE), built from communicability, a measure between pairs of nodes that aggregates contributions from paths of all lengths. By construction, CIPE inner products recover communicability, converting global multi-path connectivity into an attention-ready similarity geometry. For practical Transformer training, we introduce dimensionality alignment, mapping graph-size-dependent CIPE representations to prescribed dimensions while faithfully preserving the induced geometry. Empirically, CIPE improves structure-agnostic Transformers by 35.5% on average across seven benchmarks, outperforming representative PEs; it also consistently improves structure-biased graph Transformers, where competing PEs often yield only marginal benefits. These results position CIPE as a principled framework for attention-compatible graph positional encodings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Communicability-Inspired Positional Encoding (CIPE) for Transformers on graphs. Encodings are constructed from communicability (sum of all-path contributions) so that inner products exactly recover the communicability matrix, yielding an attention-compatible similarity geometry. A dimensionality-alignment mapping then reduces the graph-size-dependent vectors to a fixed dimension while claiming to preserve this geometry. Experiments report a 35.5% average improvement on seven benchmarks over structure-agnostic Transformers, with consistent gains also for structure-biased graph Transformers.
Significance. If the dimensionality alignment preserves the communicability Gram matrix without material distortion, the method would supply a principled route from global multi-path connectivity to attention scores. The reported empirical gains indicate practical value on the tested benchmarks, but the absence of any quantitative check on geometry preservation leaves the central theoretical motivation unverified.
major comments (2)
- [dimensionality alignment procedure (abstract and method sections)] The load-bearing claim that dimensionality alignment 'faithfully preserves the induced geometry' (abstract) receives no supporting measurement. No Frobenius error, Spearman rank correlation, or other metric is supplied between the original communicability Gram matrix and the reduced matrix on any of the seven benchmark graphs. Without such a check, it is impossible to know whether attention scores actually operate on the advertised multi-path geometry.
- [experiments / results] The empirical headline (35.5% average gain) is presented without error bars, variance across runs, or an ablation that isolates the contribution of the alignment step versus the raw communicability construction. This weakens the ability to attribute gains specifically to the claimed geometry.
minor comments (2)
- [method] Specify the exact dimensionality-alignment technique (PCA, truncation, learned linear map, etc.) with pseudocode or an equation so that the procedure is reproducible from the text alone.
- [experiments] Clarify whether the reported improvements are relative to a fixed baseline Transformer or include multiple random seeds; add this detail to Table 1 or the corresponding results table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative validation of the dimensionality alignment and improved experimental reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [dimensionality alignment procedure (abstract and method sections)] The load-bearing claim that dimensionality alignment 'faithfully preserves the induced geometry' (abstract) receives no supporting measurement. No Frobenius error, Spearman rank correlation, or other metric is supplied between the original communicability Gram matrix and the reduced matrix on any of the seven benchmark graphs. Without such a check, it is impossible to know whether attention scores actually operate on the advertised multi-path geometry.
Authors: We agree that the absence of quantitative verification leaves the geometry-preservation claim unverified. In the revised manuscript we will add explicit measurements (Frobenius norm of the difference, Spearman rank correlation, and relative Frobenius error) between the original communicability Gram matrix and the aligned matrix, computed on all seven benchmark graphs. These results will be reported in a new subsection of the experiments and referenced from the abstract and method sections. revision: yes
-
Referee: [experiments / results] The empirical headline (35.5% average gain) is presented without error bars, variance across runs, or an ablation that isolates the contribution of the alignment step versus the raw communicability construction. This weakens the ability to attribute gains specifically to the claimed geometry.
Authors: We acknowledge that the current results lack error bars and component-wise ablations. In the revision we will rerun all experiments with at least five random seeds, report means and standard deviations, and add an ablation table that compares (i) structure-agnostic Transformer, (ii) CIPE without dimensionality alignment, and (iii) full CIPE. This will allow readers to assess the isolated contribution of the alignment step. revision: yes
Circularity Check
CIPE inner products recover communicability by explicit construction of the vectors
specific steps
-
self definitional
[Abstract]
"By construction, CIPE inner products recover communicability, converting global multi-path connectivity into an attention-ready similarity geometry."
The encoding vectors are defined such that their inner products equal the communicability matrix; the claimed recovery is therefore true by the definition of the vectors rather than obtained from external data, first principles, or independent derivation.
full rationale
The paper's core claim that CIPE supplies an attention-compatible geometry whose inner products equal communicability is stated as holding 'by construction.' This makes the advertised recovery definitional rather than a derived or predictive result. The dimensionality-alignment step is asserted to preserve the geometry without distortion, but the abstract supplies neither an isometry proof nor a quantitative error bound; however, the primary circularity is the self-definitional recovery itself. No other load-bearing steps reduce to self-citation or fitted inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- dimensionality alignment mapping
axioms (1)
- domain assumption Communicability (sum of weighted contributions over all paths) is an appropriate scalar for structural relatedness inside self-attention.
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[2]
Why self- attention? a targeted evaluation of neural machine translation architectures,
G. Tang, M. M ¨uller, A. R. Gonzales, and R. Sennrich, “Why self- attention? a targeted evaluation of neural machine translation architectures,” inProceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 4263–4272
2018
-
[3]
Bert: Pre- training of deep bidirectional transformers for language under- standing,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre- training of deep bidirectional transformers for language under- standing,” inProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[4]
Overview of the transformer-based models for nlp tasks,
A. Gillioz, J. Casas, E. Mugellini, and O. Abou Khaled, “Overview of the transformer-based models for nlp tasks,” in2020 15th Conference on computer science and information systems (FedCSIS). IEEE, 2020, pp. 179–183
2020
-
[5]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[6]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM computing surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[7]
Self-attention with relative position representations,
P . Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,”arXiv preprint arXiv:1803.02155, 2018
Pith/arXiv arXiv 2018
-
[8]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P . J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[9]
Train short, test long: Attention with linear biases enables input length extrapolation,
O. Press, N. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=R8sQPpGCv0
2022
-
[10]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neuro- computing, vol. 568, p. 127063, 2024
2024
-
[11]
Position information in transformers: An overview,
P . Dufter, M. Schmitt, and H. Sch ¨utze, “Position information in transformers: An overview,”Computational Linguistics, vol. 48, no. 3, pp. 733–763, 2022
2022
-
[12]
Geometric deep learning: Grids, groups, graphs, geodesics, and gauges,
M. M. Bronstein, J. Bruna, T. Cohen, and P . Veliˇckovi´c, “Geometric deep learning: Grids, groups, graphs, geodesics, and gauges,” arXiv preprint arXiv:2104.13478, 2021
Pith/arXiv arXiv 2021
-
[13]
Weisfeiler-lehman graph kernels
N. Shervashidze, P . Schweitzer, E. J. Van Leeuwen, K. Mehlhorn, and K. M. Borgwardt, “Weisfeiler-lehman graph kernels.”Journal of Machine Learning Research, vol. 12, no. 9, 2011
2011
-
[14]
It’s who you know: graph mining using recursive structural features,
K. Henderson, B. Gallagher, L. Li, L. Akoglu, T. Eliassi-Rad, H. Tong, and C. Faloutsos, “It’s who you know: graph mining using recursive structural features,” inProceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 2011, pp. 663–671
2011
-
[15]
Rolx: structural role extraction & mining in large graphs,
K. Henderson, B. Gallagher, T. Eliassi-Rad, H. Tong, S. Basu, L. Akoglu, D. Koutra, C. Faloutsos, and L. Li, “Rolx: structural role extraction & mining in large graphs,” inProceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, 2012, pp. 1231–1239
2012
-
[16]
Benchmarking graph neural networks,
V . P . Dwivedi, C. K. Joshi, A. T. Luu, T. Laurent, Y. Bengio, and X. Bresson, “Benchmarking graph neural networks,”Journal of Machine Learning Research, vol. 24, no. 43, pp. 1–48, 2023
2023
-
[17]
Graph positional and structural encoder,
S. Cant ¨urk, R. Liu, O. Lapointe-Gagn ´e, V . L´etourneau, G. Wolf, D. Beaini, and L. Ramp ´aˇsek, “Graph positional and structural encoder,”arXiv preprint arXiv:2307.07107, 2023
arXiv 2023
-
[18]
Cycle invariant positional encoding for graph representation learning,
Z. Yan, T. Ma, L. Gao, Z. Tang, C. Chen, and Y. Wang, “Cycle invariant positional encoding for graph representation learning,” inLearning on Graphs Conference. PMLR, 2024, pp. 4–1
2024
-
[19]
A generalization of transformer networks to graphs,
V . P . Dwivedi and X. Bresson, “A generalization of transformer networks to graphs,”arXiv preprint arXiv:2012.09699, 2020
arXiv 2012
-
[20]
On the stability of expressive positional encodings for graphs,
Y. Huang, W. Lu, J. Robinson, Y. Yang, M. Zhang, S. Jegelka, and P . Li, “On the stability of expressive positional encodings for graphs,”arXiv preprint arXiv:2310.02579, 2023
arXiv 2023
-
[21]
Rethinking graph transformers with spectral attention,
D. Kreuzer, D. Beaini, W. Hamilton, V . L´etourneau, and P . Tossou, “Rethinking graph transformers with spectral attention,”Advances in Neural Information Processing Systems, vol. 34, pp. 21 618–21 629, 2021
2021
-
[22]
Graphit: Encoding graph structure in transformers,
G. Mialon, D. Chen, M. Selosse, and J. Mairal, “Graphit: Encoding graph structure in transformers,”arXiv preprint arXiv:2106.05667, 2021
arXiv 2021
-
[23]
Recipe for a general, powerful, scalable graph transformer,
L. Ramp ´aˇsek, M. Galkin, V . P . Dwivedi, A. T. Luu, G. Wolf, and D. Beaini, “Recipe for a general, powerful, scalable graph transformer,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 501–14 515, 2022
2022
-
[24]
Transformer for graphs: An overview from architecture perspective,
E. Min, R. Chen, Y. Bian, T. Xu, K. Zhao, W. Huang, P . Zhao, J. Huang, S. Ananiadou, and Y. Rong, “Transformer for graphs: An overview from architecture perspective,”arXiv preprint arXiv:2202.08455, 2022
arXiv 2022
-
[25]
Graph neural networks,
G. Corso, H. Stark, S. Jegelka, T. Jaakkola, and R. Barzilay, “Graph neural networks,”Nature Reviews Methods Primers, vol. 4, no. 1, p. 17, 2024
2024
-
[26]
Vertex similarity in networks,
E. A. Leicht, P . Holme, and M. E. Newman, “Vertex similarity in networks,”Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, vol. 73, no. 2, p. 026120, 2006
2006
-
[27]
Visualization and machine learning analysis of complex networks in hyperspherical space,
M. Pereda and E. Estrada, “Visualization and machine learning analysis of complex networks in hyperspherical space,”Pattern Recognition, vol. 86, pp. 320–331, 2019
2019
-
[28]
Communicability cosine distance: similarity and sym- metry in graphs/networks,
E. Estrada, “Communicability cosine distance: similarity and sym- metry in graphs/networks,”Computational and Applied Mathemat- ics, vol. 43, no. 1, p. 49, 2024
2024
-
[29]
Communicability in complex net- works,
E. Estrada and N. Hatano, “Communicability in complex net- works,”Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, vol. 77, no. 3, p. 036111, 2008
2008
-
[30]
Estrada,The Structure of Complex Networks: Theory and Applica- tions
E. Estrada,The Structure of Complex Networks: Theory and Applica- tions. New York: OUP Oxford, 2011
2011
-
[31]
Com- municability across evolving networks,
P . Grindrod, M. C. Parsons, D. J. Higham, and E. Estrada, “Com- municability across evolving networks,”Physical Review E, vol. 83, no. 4, p. 046120, 2011
2011
-
[32]
Hyper- spherical embedding of graphs and networks in communicability spaces,
E. Estrada, M. Sanchez-Lirola, and J. A. De La Pe ˜na, “Hyper- spherical embedding of graphs and networks in communicability spaces,”Discrete Applied Mathematics, vol. 176, pp. 53–77, 2014
2014
-
[33]
The physics of communi- cability in complex networks,
E. Estrada, N. Hatano, and M. Benzi, “The physics of communi- cability in complex networks,”Physics reports, vol. 514, no. 3, pp. 89–119, 2012. 11
2012
-
[34]
Communicability angle and the spatial efficiency of networks,
E. Estrada and N. Hatano, “Communicability angle and the spatial efficiency of networks,”SIAM Review, vol. 58, no. 4, pp. 692–715, 2016
2016
-
[35]
Moleculenet: a benchmark for molecular machine learning,
Z. Wu, B. Ramsundar, E. N. Feinberg, J. Gomes, C. Geniesse, A. S. Pappu, K. Leswing, and V . Pande, “Moleculenet: a benchmark for molecular machine learning,”Chemical science, vol. 9, no. 2, pp. 513–530, 2018
2018
-
[36]
Tudataset: A collection of benchmark datasets for learning with graphs,
C. Morris, N. M. Kriege, F. Bause, K. Kersting, P . Mutzel, and M. Neumann, “Tudataset: A collection of benchmark datasets for learning with graphs,” inICML 2020 Workshop on Graph Represen- tation Learning and Beyond (GRL+ 2020), 2020
2020
-
[37]
Communicability graph and com- munity structures in complex networks,
E. Estrada and N. Hatano, “Communicability graph and com- munity structures in complex networks,”Applied Mathematics and Computation, vol. 214, no. 2, pp. 500–511, 2009
2009
-
[38]
Communicability betweenness in complex networks,
E. Estrada, D. J. Higham, and N. Hatano, “Communicability betweenness in complex networks,”Physica A: Statistical Mechanics and its Applications, vol. 388, no. 5, pp. 764–774, 2009
2009
-
[39]
Complex networks in the euclidean space of commu- nicability distances,
E. Estrada, “Complex networks in the euclidean space of commu- nicability distances,”Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, vol. 85, no. 6, p. 066122, 2012
2012
-
[40]
Wavelets on graphs via spectral graph theory,
D. K. Hammond, P . Vandergheynst, and R. Gribonval, “Wavelets on graphs via spectral graph theory,”Applied and computational harmonic analysis, vol. 30, no. 2, pp. 129–150, 2011
2011
-
[41]
Computing the action of the matrix exponential, with an application to exponential integra- tors,
A. H. Al-Mohy and N. J. Higham, “Computing the action of the matrix exponential, with an application to exponential integra- tors,”SIAM journal on scientific computing, vol. 33, no. 2, pp. 488– 511, 2011
2011
-
[42]
Strategies for pre-training graph neural networks,
W. Hu, B. Liu, J. Gomes, M. Zitnik, P . Liang, V . Pande, and J. Leskovec, “Strategies for pre-training graph neural networks,” inInternational Conference on Learning Representations (ICLR), 2020
2020
-
[43]
Graph contrastive learning with augmentations,
Y. You, T. Chen, Y. Sui, T. Chen, Z. Wang, and Y. Shen, “Graph contrastive learning with augmentations,”Advances in neural in- formation processing systems, vol. 33, pp. 5812–5823, 2020
2020
-
[44]
Evaluating self-supervised learning for molecular graph embed- dings,
H. Wang, J. Kaddour, S. Liu, J. Tang, J. Lasenby, and Q. Liu, “Evaluating self-supervised learning for molecular graph embed- dings,”Advances in Neural Information Processing Systems, vol. 36, pp. 68 028–68 060, 2023
2023
-
[45]
Graphmae: Self-supervised masked graph autoencoders,
Z. Hou, X. Liu, Y. Cen, Y. Dong, H. Yang, C. Wang, and J. Tang, “Graphmae: Self-supervised masked graph autoencoders,” inPro- ceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, 2022, pp. 594–604
2022
-
[46]
Self-supervised graph-level representation learning with local and global struc- ture,
M. Xu, H. Wang, B. Ni, H. Guo, and J. Tang, “Self-supervised graph-level representation learning with local and global struc- ture,” inInternational conference on machine learning. PMLR, 2021, pp. 11 548–11 558
2021
-
[47]
Pushing the boundaries of molecular representation for drug discovery with the graph attention mecha- nism,
Z. Xiong, D. Wang, X. Liu, F. Zhong, X. Wan, X. Li, Z. Li, X. Luo, K. Chen, H. Jianget al., “Pushing the boundaries of molecular representation for drug discovery with the graph attention mecha- nism,”Journal of Medicinal Chemistry, vol. 63, no. 16, pp. 8749–8760, 2019
2019
-
[48]
Graph generative pre-trained transformer,
X. Chen, Y. Wang, J. He, Y. Du, S. Hassoun, X. Xu, and L. Liu, “Graph generative pre-trained transformer,” inInternational Con- ference on Machine Learning. PMLR, 2025, pp. 9176–9197
2025
-
[49]
Graph positional and structural en- coder,
S. Cant ¨urk, R. Liu, O. Lapointe-Gagn ´e, V . L´etourneau, G. Wolf, D. Beaini, and L. Ramp ´aˇsek, “Graph positional and structural en- coder,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 5533–5566
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.