RAVEN: A Regime-Aware Variable-context Expert Network for Financial Time Series Forecasting
Pith reviewed 2026-06-26 00:57 UTC · model grok-4.3
The pith
RAVEN determines per-sample context lengths for financial forecasts by routing nested windows to scale-specialized experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
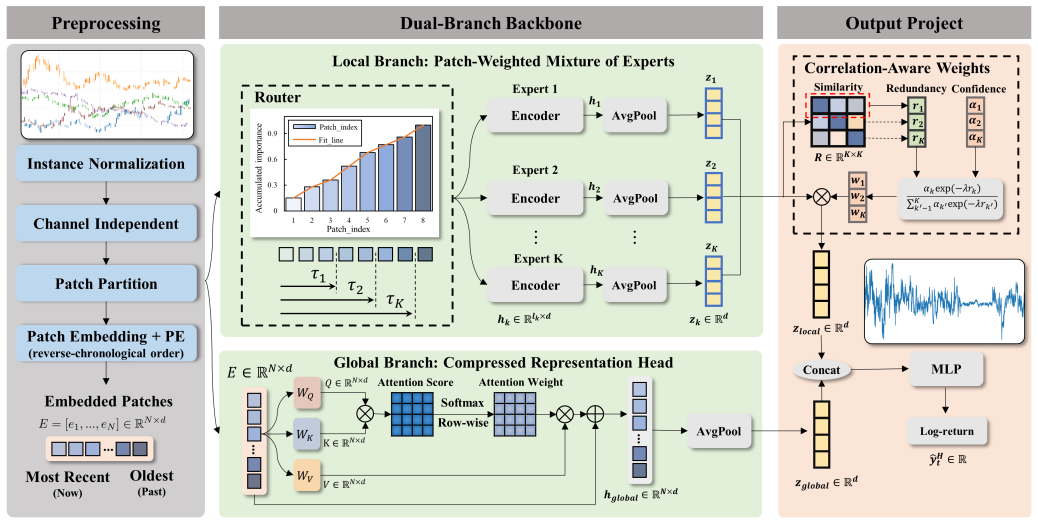
The paper claims that a fixed context window is mismatched to the time-varying optimal look-back of non-stationary price processes. RAVEN addresses this by constructing a hierarchy of nested contiguous windows whose lengths are determined by the data itself: patches are scored by learned importance in reverse chronological order, Cumulative Importance Thresholding selects the nested prefix windows, each is routed to a scale-specialized expert, a Global Compressed Representation branch runs in parallel over the full context, and Correlation-Aware Weighting aligns the variable-length outputs before aggregation.
What carries the argument
Cumulative Importance Thresholding (CIT), which scores patches in reverse chronological order by learned importance and selects nested prefix windows at a cumulative threshold.
If this is right
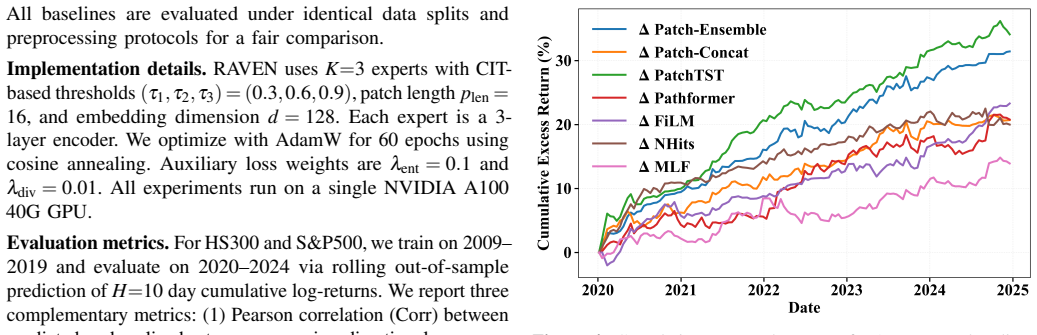
- Pearson correlation rises 9.2 percent on HS300 and 20.2 percent on S&P500 cumulative log-return forecasts.
- MSE drops 18.2 percent on fund sales forecasting.
- Best results appear in 14 of 16 metrics across four PEMS traffic data sets.
- Regime-dependent temporal dependencies are handled without a single fixed horizon.
Where Pith is reading between the lines
- The same nested-window routing could be tested on other non-stationary series such as electricity load or weather variables.
- If the importance scorer is replaced by a simple recency prior, the performance gap would reveal how much the learned scoring contributes.
- Extending the hierarchy to include non-contiguous windows might further reduce redundancy among experts.
Load-bearing premise
That importance scores learned on patches, when accumulated from most recent backward, will produce window lengths that match each sample's time-varying optimal look-back.
What would settle it
An experiment that replaces the CIT-selected windows with randomly chosen nested windows of the same length distribution and measures whether forecasting gains disappear.
Figures
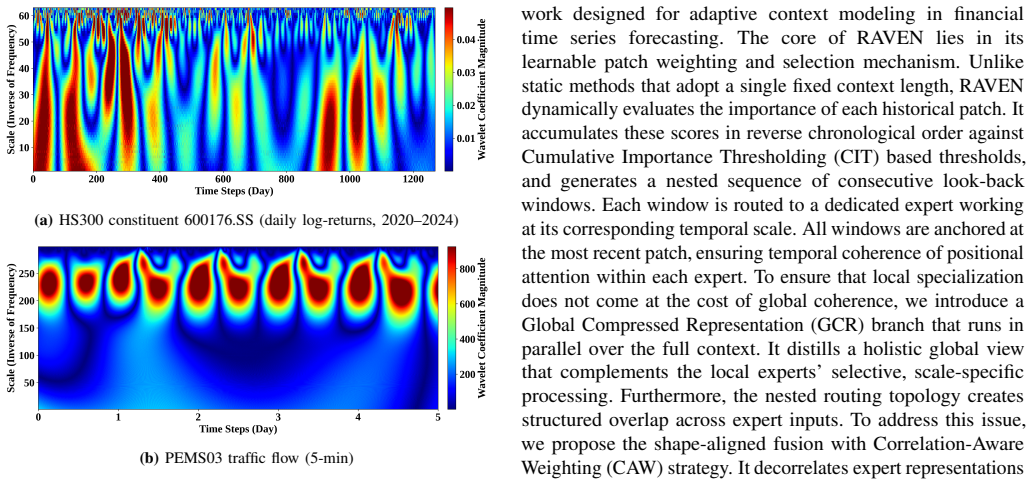
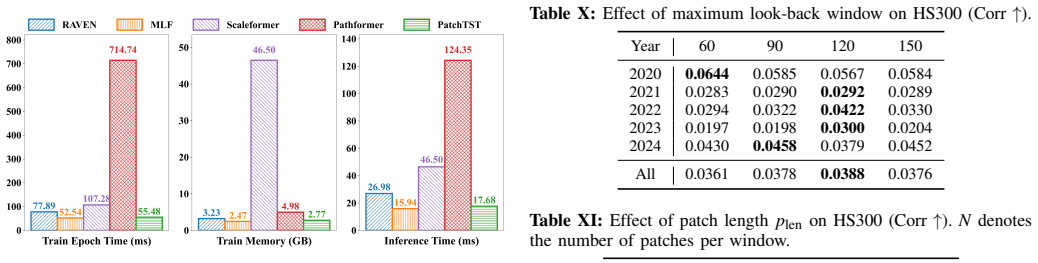
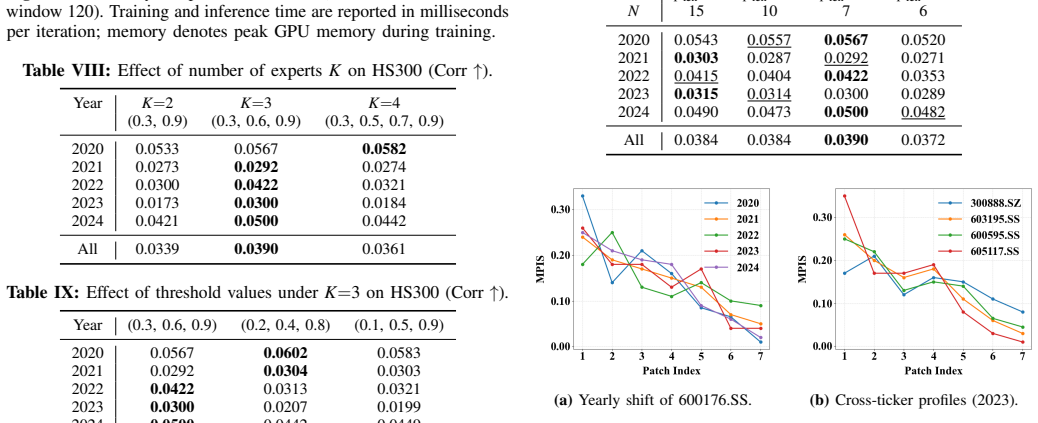
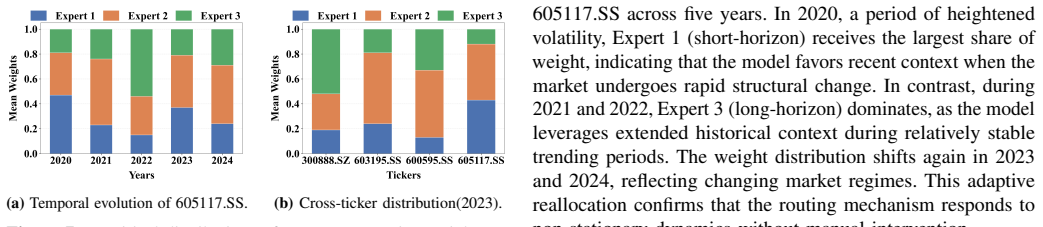
read the original abstract
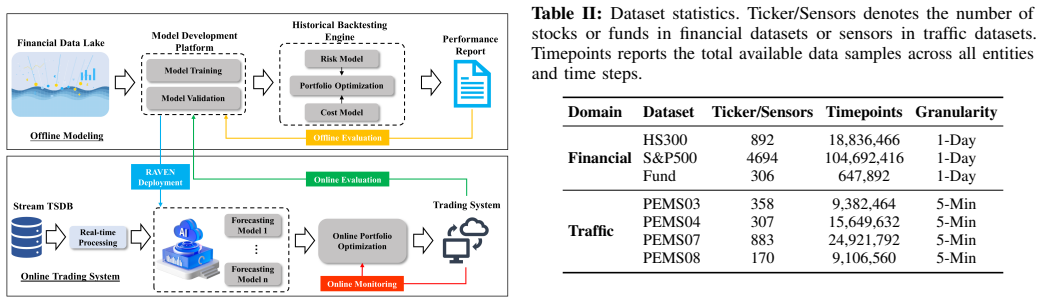
Financial time series forecasting presents structural challenges absent from standard benchmarks. Log-returns are non-stationary, exhibit exceptionally low signal-to-noise (SNR) ratios, and are governed by regime-dependent temporal dependencies. We identify a key limitation of state-of-the-art (SOTA) time series models in financial settings. A fixed context window is mismatched to the time-varying optimal look-back of non-stationary price processes. We propose the Regime-Aware Variable-context Expert Network (RAVEN), a Mixture-of-Experts framework designed to adaptively determine the temporal context for each input sample. Instead of relying on a fixed look-back horizon, RAVEN constructs a hierarchy of nested contiguous windows whose lengths are determined by the data itself. Specifically, RAVEN scores patches by learned importance in reverse chronological order and applies the Cumulative Importance Thresholding (CIT) mechanism to derive nested prefix windows, each routed to a scale-specialized expert. A Global Compressed Representation (GCR) branch runs in parallel over the full context, preserving global temporal coherence that local experts cannot guarantee. Because the nested routing induces structured overlap among expert inputs, we introduce a Correlation-Aware Weighting (CAW) to align variable-length expert outputs and penalize pairwise cosine similarity prior to aggregation. Experiments on cumulative log-return prediction (HS300, S&P500) and fund sales forecasting demonstrate that RAVEN achieves SOTA performances, improves Pearson correlation by 9.2% on HS300 and 20.2% on S&P500, and reduces MSE by 18.2% on fund sales forecasting, while achieving the best results in 14 of 16 metrics on four PEMS traffic benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAVEN, a Mixture-of-Experts architecture for financial time series forecasting that adaptively determines per-sample temporal context via a Cumulative Importance Thresholding (CIT) mechanism: patches are scored by learned importance in reverse chronological order to form nested prefix windows routed to scale-specialized experts. A parallel Global Compressed Representation (GCR) branch preserves global coherence, and Correlation-Aware Weighting (CAW) aligns variable-length outputs while penalizing cosine similarity. The paper claims this addresses the mismatch of fixed context windows with regime-dependent dependencies in non-stationary, low-SNR log-return series, reporting SOTA results including 9.2% Pearson correlation improvement on HS300, 20.2% on S&P500, 18.2% MSE reduction on fund sales forecasting, and best performance in 14 of 16 metrics across four PEMS traffic benchmarks.
Significance. If the CIT mechanism reliably recovers time-varying optimal look-backs rather than arbitrary patterns, the variable-context MoE design could offer a practical way to handle regime shifts in financial forecasting where fixed windows are suboptimal. The addition of GCR and CAW to manage overlap and coherence is a reasonable engineering response to the nested routing. Evaluation on both financial and non-financial (PEMS) benchmarks provides some breadth, though significance hinges on confirming that reported gains are attributable to the adaptive context rather than capacity or regularization effects alone.
major comments (2)
- [Abstract] Abstract (CIT mechanism paragraph): The assertion that learned reverse-chronological patch importances followed by Cumulative Importance Thresholding produce nested prefix windows whose lengths match each sample's time-varying optimal look-back is presented without any ablation, diagnostic (e.g., window-length histograms per regime), or sensitivity analysis on the threshold value; if this alignment does not hold, the variable-context routing, GCR, and CAW cannot explain the claimed Pearson/MSE gains and the improvements could arise from other factors.
- [Abstract] Abstract (experimental claims): The reported metric improvements (9.2% Pearson on HS300, 20.2% on S&P500, 18.2% MSE on fund sales, best in 14/16 PEMS metrics) are stated without error bars, number of runs, dataset statistics, or explicit comparisons isolating the CIT variable-context component against strong fixed-window MoE baselines, which is required to establish that the architectural choices drive the SOTA results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental claims. We address each point below and will revise the manuscript accordingly to strengthen the evidence for the CIT mechanism and the attribution of performance gains.
read point-by-point responses
-
Referee: [Abstract] Abstract (CIT mechanism paragraph): The assertion that learned reverse-chronological patch importances followed by Cumulative Importance Thresholding produce nested prefix windows whose lengths match each sample's time-varying optimal look-back is presented without any ablation, diagnostic (e.g., window-length histograms per regime), or sensitivity analysis on the threshold value; if this alignment does not hold, the variable-context routing, GCR, and CAW cannot explain the claimed Pearson/MSE gains and the improvements could arise from other factors.
Authors: We agree that the abstract presents the CIT alignment claim without accompanying diagnostics. In the revised manuscript we will add (i) ablation studies removing or replacing CIT, (ii) histograms of selected window lengths stratified by detected market regimes, and (iii) sensitivity plots for the cumulative-importance threshold. These additions will directly test whether the learned nested prefixes correspond to regime-dependent optimal look-backs and will clarify the contribution of variable-context routing relative to GCR and CAW. revision: yes
-
Referee: [Abstract] Abstract (experimental claims): The reported metric improvements (9.2% Pearson on HS300, 20.2% on S&P500, 18.2% MSE on fund sales, best in 14/16 PEMS metrics) are stated without error bars, number of runs, dataset statistics, or explicit comparisons isolating the CIT variable-context component against strong fixed-window MoE baselines, which is required to establish that the architectural choices drive the SOTA results.
Authors: We acknowledge that the abstract omits error bars, run counts, and component-isolating ablations. The full paper already reports multiple random seeds and basic dataset statistics; we will augment the experimental section with (i) mean ± std over the reported seeds, (ii) explicit fixed-window MoE baselines that keep all other RAVEN components identical, and (iii) an ablation table that isolates the CIT variable-context branch. These results will be summarized in the abstract revision as well. revision: yes
Circularity Check
No circularity: empirical architecture with no self-referential derivations or fitted predictions
full rationale
The paper presents an empirical neural architecture (Mixture-of-Experts with CIT, GCR, CAW) whose performance claims rest on experimental results rather than any closed-form derivation. No equations are supplied that define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The central mechanism (learned reverse-chronological patch importance + CIT) is an architectural choice whose validity is tested empirically on HS300, S&P500, and PEMS benchmarks; it does not reduce to the reported Pearson/MSE gains by construction. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (2)
- patch importance scoring weights
- CIT threshold value
axioms (1)
- domain assumption Financial log-returns are governed by regime-dependent temporal dependencies that a fixed context window cannot capture.
Reference graph
Works this paper leans on
-
[1]
Timesqueeze: Dynamic patching for efficient time series forecasting,
S. K. Ankireddy, N. Seleznev, N. H. Nguyen, Y . Wu, S. Kumar, F. Huang, and C. B. Bruss, “Timesqueeze: Dynamic patching for efficient time series forecasting,” CoRR, vol. abs/2603.11352, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.11352
-
[2]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, A. C. Türkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. Pineda-Arango, S. Kapoor, J. Zschiegner, D. C. Maddix, H. Wang, M. W. Mahoney, K. Torkkola, A. G. Wilson, M. Bohlke-Schneider, and B. Wang, “Chronos: Learning the language of time series,” Trans. Mach. Learn. Res., vol. 2024, 2024. [Online]. Available: h...
2024
-
[3]
Machine learning strategies for time series forecasting,
G. Bontempi, S. B. Taieb, and Y . L. Borgne, “Machine learning strategies for time series forecasting,” in Business Intelligence - Second European Summer School, eBISS 2012, Brussels, Belgium, July 15-21, 2012, Tutorial Lectures, ser. Lecture Notes in Business Information Processing, M. Aufaure and E. Zimányi, Eds. Springer, 2012, pp. 62–77. [Online]. Ava...
-
[4]
NHITS: neural hierarchical interpolation for time series forecasting,
C. Challu, K. G. Olivares, B. N. Oreshkin, F. G. Ramírez, M. M. Canseco, and A. Dubrawski, “NHITS: neural hierarchical interpolation for time series forecasting,” in Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educati...
-
[5]
Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting,
P. Chen, Y . Zhang, Y . Cheng, Y . Shu, Y . Wang, Q. Wen, B. Yang, and C. Guo, “Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting,” in The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id...
2024
-
[6]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, B. Krishnapuram, M. Shah, A. J. Smola, C. C. Aggarwal, D. Shen, and R. Rastogi, Eds. ACM, 2016, pp. 785–794. [Online]. Available: https://doi...
-
[7]
K. Cho, B. van Merrienboer, Ç. Gülçehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT,a Specia...
-
[8]
A simple approximate long-memory model of realized volatility,
F. Corsi, “A simple approximate long-memory model of realized volatility,” Journal of financial econometrics, vol. 7, no. 2, pp. 174–196, 2009
2009
-
[9]
Comparing predictive accuracy,
F. X. Diebold and R. S. Mariano, “Comparing predictive accuracy,” Journal of Business & economic statistics, vol. 20, no. 1, pp. 134–144, 2002
2002
-
[10]
Finding structure in time,
J. L. Elman, “Finding structure in time,” Cogn. Sci., vol. 14, no. 2, pp. 179–211, 1990. [Online]. Available: https://doi.org/10.1207/ s15516709cog1402_1
1990
-
[11]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” J. Mach. Learn. Res., vol. 23, pp. 120:1–120:39, 2022. [Online]. Available: https://jmlr.org/papers/v23/21-0998.html
2022
-
[12]
Greedy function approximation: a gradient boosting machine,
J. H. Friedman, “Greedy function approximation: a gradient boosting machine,” Annals of statistics, pp. 1189–1232, 2001
2001
-
[13]
Empirical asset pricing via machine learning,
S. Gu, B. Kelly, and D. Xiu, “Empirical asset pricing via machine learning,” The Review of Financial Studies, vol. 33, no. 5, pp. 2223–2273, 2020
2020
-
[14]
Attention based spatial-temporal graph convolutional networks for traffic flow forecasting,
S. Guo, Y . Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial-temporal graph convolutional networks for traffic flow forecasting,” in The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances i...
-
[15]
Measuring the information content of stock trades,
J. Hasbrouck, “Measuring the information content of stock trades,” The Journal of Finance, vol. 46, no. 1, pp. 179–207, 1991
1991
-
[16]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
-
[17]
Lightgbm: A highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T. Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Ferg...
2017
-
[18]
Reversible instance normalization for accurate time-series forecasting against distribution shift,
T. Kim, J. Kim, Y . Tae, C. Park, J. Choi, and J. Choo, “Reversible instance normalization for accurate time-series forecasting against distribution shift,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. [Online]. Available: https: //openreview.net/forum?id=cGDAkQo1C0p
2022
-
[19]
Master: Market- guided stock transformer for stock price forecasting,
T. Li, Z. Liu, Y . Shen, X. Wang, H. Chen, and S. Huang, “Master: Market- guided stock transformer for stock price forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 38, no. 1, 2024, pp. 162–170
2024
-
[20]
Learning multiple stock trading patterns with temporal routing adaptor and optimal transport,
H. Lin, D. Zhou, W. Liu, and J. Bian, “Learning multiple stock trading patterns with temporal routing adaptor and optimal transport,” in KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14-18, 2021, F. Zhu, B. C. Ooi, and C. Miao, Eds. ACM, 2021, pp. 1017–1026. [Online]. Available: https://do...
-
[21]
Moirai-moe: Empowering time series foundation models with sparse mixture of experts,
X. Liu, J. Liu, G. Woo, T. Aksu, Y . Liang, R. Zimmermann, C. Liu, J. Li, S. Savarese, C. Xiong, and D. Sahoo, “Moirai-moe: Empowering time series foundation models with sparse mixture of experts,” in Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, ser. Proceedings of Machine Learning Research...
2025
-
[22]
itransformer: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itransformer: Inverted transformers are effective for time series forecasting,” in The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https: //openreview.net/forum?id=JePfAI8fah
2024
-
[23]
The adaptive markets hypothesis: Market efficiency from an evolutionary perspective,
A. W. Lo, “The adaptive markets hypothesis: Market efficiency from an evolutionary perspective,” Journal of Portfolio Management, Forthcoming, 2004
2004
-
[24]
Moderntcn: A modern pure convolution structure for general time series analysis,
D. Luo and X. Wang, “Moderntcn: A modern pure convolution structure for general time series analysis,” in The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=vpJMJerXHU
2024
-
[25]
Wpmixer: Efficient multi-resolution mixing for long-term time series forecasting,
M. M. N. Murad, M. Aktukmak, and Y . Yilmaz, “Wpmixer: Efficient multi-resolution mixing for long-term time series forecasting,” in Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Symposium on Educational Advances in Artificial Intelligence, AAAI 2025, Phil...
-
[26]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=Jbdc0vTOcol
2023
-
[27]
Fredformer: Frequency debiased transformer for time series forecasting,
X. Piao, Z. Chen, T. Murayama, Y . Matsubara, and Y . Sakurai, “Fredformer: Frequency debiased transformer for time series forecasting,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29, 2024, R. Baeza-Yates and F. Bonchi, Eds. ACM, 2024, pp. 2400–2410. [Online]. Available: h...
-
[28]
Financial time series forecasting with deep learning : A systematic literature review: 2005-2019,
O. B. Sezer, M. U. Gudelek, and A. M. Özbayoglu, “Financial time series forecasting with deep learning : A systematic literature review: 2005-2019,” Appl. Soft Comput., vol. 90, p. 106181, 2020. [Online]. Available: https://doi.org/10.1016/j.asoc.2020.106181 13
-
[29]
Scaleformer: Iterative multi-scale refining transformers for time series forecasting,
M. A. Shabani, A. H. Abdi, L. Meng, and T. Sylvain, “Scaleformer: Iterative multi-scale refining transformers for time series forecasting,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=sCrnllCtjoE
2023
-
[30]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” in 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. [Online]. Available: https:/...
2017
-
[31]
Time-moe: Billion-scale time series foundation models with mixture of experts,
X. Shi, S. Wang, Y . Nie, D. Li, Z. Ye, Q. Wen, and M. Jin, “Time-moe: Billion-scale time series foundation models with mixture of experts,” in The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=e1wDDFmlVu
2025
-
[32]
Kronos: A foundation model for the language of financial markets,
Y . Shi, Z. Fu, S. Chen, B. Zhao, W. Xu, C. Zhang, and J. Li, “Kronos: A foundation model for the language of financial markets,” in Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Advances in Artificial Intelligence, AAAI 2026, Singapor...
-
[33]
Learning pattern- specific experts for time series forecasting under patch-level distribution shift,
Y . Sun, Z. Xie, E. Eldele, D. Chen, Q. Hu, and M. Wu, “Learning pattern- specific experts for time series forecasting under patch-level distribution shift,” in Advances in Neural Information Processing Systems, D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, Eds., vol. 38. Curran Associates, Inc., 2025, pp. 91 810–91 844....
2025
-
[34]
CARD: channel aligned robust blend transformer for time series forecasting,
X. Wang, T. Zhou, Q. Wen, J. Gao, B. Ding, and R. Jin, “CARD: channel aligned robust blend transformer for time series forecasting,” in The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=MJksrOhurE
2024
-
[35]
Asymptotic inference about predictive ability,
K. D. West, “Asymptotic inference about predictive ability,” Econometrica, vol. 64, no. 5, pp. 1067–1084, 1996
1996
-
[36]
Timesnet: Temporal 2d-variation modeling for general time series analysis,
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “Timesnet: Temporal 2d-variation modeling for general time series analysis,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=ju_Uqw384Oq
2023
-
[37]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,” in Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and ...
2021
-
[38]
W. Xu, W. Liu, L. Wang, Y . Xia, J. Bian, J. Yin, and T. Liu, “HIST: A graph-based framework for stock trend forecasting via mining concept-oriented shared information,” CoRR, vol. abs/2110.13716, 2021. [Online]. Available: https://arxiv.org/abs/2110.13716
arXiv 2021
-
[39]
Finmultitime: A four-modal bilingual dataset for financial time-series analysis,
W. Xu, D. Xiang, Y . Liu, X. Wang, Y . Ma, L. Zhang, C. Xu, and J. Zhang, “Finmultitime: A four-modal bilingual dataset for financial time-series analysis,” CoRR, vol. abs/2506.05019, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.05019
-
[40]
Qlib: An ai-oriented quantitative investment platform,
X. Yang, W. Liu, D. Zhou, J. Bian, and T. Liu, “Qlib: An ai-oriented quantitative investment platform,” CoRR, vol. abs/2009.11189, 2020. [Online]. Available: https://arxiv.org/abs/2009.11189
arXiv 2009
-
[41]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” in Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, D...
-
[42]
Multi-period learning for financial time series forecasting,
X. Zhang, Z. Huang, Y . Wu, X. Lu, E. Qi, Y . Chen, Z. Xue, Q. Wang, P. Wang, and W. Wang, “Multi-period learning for financial time series forecasting,” in Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .1,KDD 2025, Toronto, ON, Canada, August 3-7, 2025, Y . Sun, F. Chierichetti, H. W. Lauw, C. Perlich, W. H. Tok,...
-
[43]
Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting,
Y . Zhang and J. Yan, “Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=vSVLM2j9eie
2023
-
[44]
Doubleadapt: A meta-learning approach to incremental learning for stock trend forecasting,
L. Zhao, S. Kong, and Y . Shen, “Doubleadapt: A meta-learning approach to incremental learning for stock trend forecasting,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, A. K. Singh, Y . Sun, L. Akoglu, D. Gunopulos, X. Yan, R. Kumar, F. Ozcan, and J. Ye, Eds. AC...
-
[45]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advan...
-
[46]
Film: Frequency improved legendre memory model for long-term time series forecasting,
T. Zhou, Z. Ma, X. Wang, Q. Wen, L. Sun, T. Yao, W. Yin, and R. Jin, “Film: Frequency improved legendre memory model for long-term time series forecasting,” in Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo,...
2022
-
[47]
Fedformer: Frequency enhanced decomposed transformer for long- term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “Fedformer: Frequency enhanced decomposed transformer for long- term series forecasting,” in International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, and S....
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.