SIGMA: Semantic-Difference Instruction-Grounding Mask Annotator for Text-Driven Image Manipulation Localization
Pith reviewed 2026-06-29 14:02 UTC · model grok-4.3
The pith
SIGMA recovers pixel masks for text-driven image edits from existing editing pairs using semantic differencing and instruction grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
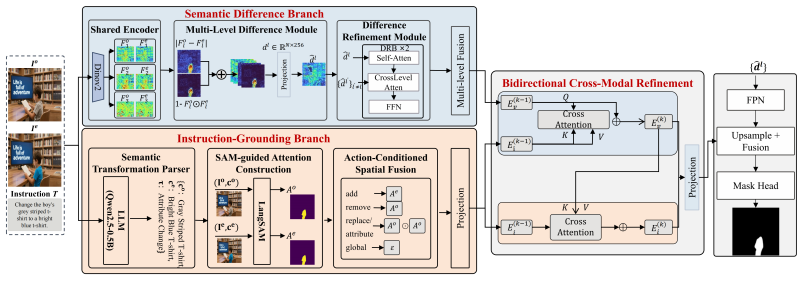
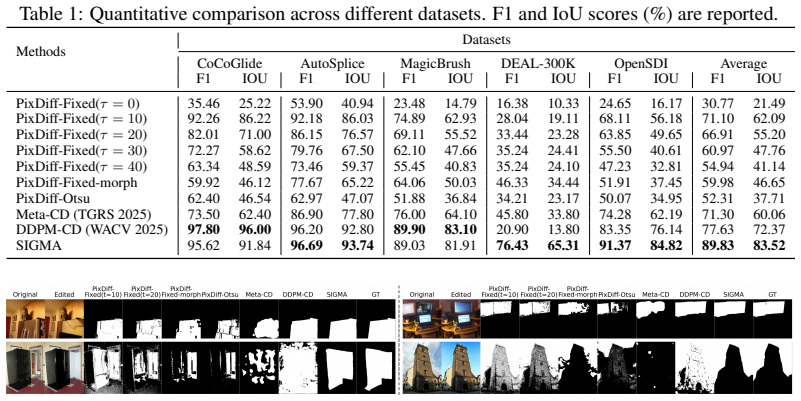
SIGMA performs semantic-feature differencing inside a vision foundation backbone and injects an instruction-derived spatial prior into that stream via bidirectional cross-modal refinement, amplifying the difference signal at intended-edit regions when the editor realizes user intent. It is trained first by supervising on inpainting masks, then in a second stage that uses VAE-roundtrip noise calibration, EMA self-training, and an edit-noise disentanglement loss to close the diffusion domain shift. The method produces masks that outperform prior automatic generators by 12.20 percent F1 and 11.16 percent IoU on five benchmarks and yields a 1.1 million sample IML training corpus from public edit
What carries the argument
Bidirectional cross-modal refinement that injects an instruction-derived spatial prior into semantic-feature differencing inside a vision foundation backbone.
If this is right
- SIGMA outperforms existing automatic mask generators by 12.20 percent F1 and 11.16 percent IoU on five benchmarks.
- Applied to public editing corpora it produces a 1.1 million sample IML training set.
- That set improves six diverse detectors by 18.34 percent F1 across five datasets.
- It converts previously unused editing pairs into a model-agnostic supervisory resource for IML.
Where Pith is reading between the lines
- The same differencing-plus-instruction pattern could be tested on other paired image tasks such as object removal or style transfer where explicit masks are also missing.
- If the method depends on faithful realization of intent, performance will drop on editing models that frequently ignore parts of the prompt; a controlled comparison on such models would quantify the drop.
- The two-stage training that closes the diffusion shift could be applied to other domain-gap problems in mask prediction without new labeled data.
Load-bearing premise
The image editor faithfully realizes the user's intent so the instruction can correctly mark the intended regions amid diffusion noise.
What would settle it
Collect a set of text-driven edits in which the output visibly deviates from the prompt (unintended color shifts or added objects) and measure whether SIGMA masks still match human ground truth at the same rate as on faithful edits.
Figures






read the original abstract
Text-driven image editing has advanced rapidly, but reliably localizing these manipulations requires image manipulation localization (IML) models trained on large pixel-annotated datasets, and there is still no low-cost way to obtain such training data at scale. We observe that these data already exist in disguise: public editing datasets contain millions of structurally identical (original, edited) pairs to IML training samples, lacking only pixel-level masks. Recovering these masks automatically is non-trivial: pixel differencing is overwhelmed by diffusion-induced perturbations across all pixels, and instruction-only grounding localizes only what the prompt describes, missing unintended editor side-effects. We propose SIGMA (Semantic-difference Instruction-Grounding Mask Annotator), which performs semantic-feature differencing in a vision foundation backbone and injects an instruction-derived spatial prior into this visual stream via bidirectional cross-modal refinement, amplifying the difference signal at intended-edit regions when the editor faithfully realizes user intent. SIGMA is trained in two complementary stages: Stage I supervises on inpainting masks; Stage II closes the diffusion-domain shift via VAE-roundtrip noise calibration, EMA self-training, and an edit-noise disentanglement loss. SIGMA outperforms existing automatic mask generators on five benchmarks (+12.20% F1, +11.16% IoU). When applied to public editing corpora, it produces a ~1.1M IML training set that improves six diverse detectors by +18.34% F1 across five datasets, turning previously unused editing data into a model-agnostic supervisory resource for IML. We'll release the full codebase as soon as the paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SIGMA, a two-stage method for automatic pixel-level mask annotation of text-driven image manipulations from existing (original, edited) pairs. It performs semantic-feature differencing in a vision backbone, injects an instruction-derived spatial prior via bidirectional cross-modal refinement, and trains first on inpainting supervision then on VAE-roundtrip noise calibration, EMA self-training, and edit-noise disentanglement to close diffusion domain shift. It reports +12.20% F1 / +11.16% IoU gains over prior automatic mask generators on five benchmarks and shows that the resulting ~1.1M-mask dataset improves six diverse IML detectors by +18.34% F1 across five datasets. The codebase will be released upon acceptance.
Significance. If the reported gains are robust, the work converts large existing editing corpora into a model-agnostic supervisory resource for IML, addressing the scarcity of pixel-annotated training data. The explicit commitment to releasing full code and the use of standard foundation models plus reproducible training stages are strengths that would support follow-on work.
major comments (3)
- [§4 and Table 2] §4 (Experiments) and Table 2: the central claim of +12.20% F1 / +11.16% IoU superiority rests on the two-stage pipeline reliably amplifying only faithful edits; however, the manuscript provides no ablation isolating the contribution of the edit-noise disentanglement loss versus the VAE-roundtrip calibration, leaving open whether residual diffusion artifacts correlated with edits remain.
- [§3.2 and §4.3] §3.2 (Stage II) and downstream results in §4.3: the claim that the generated 1.1M masks improve six detectors by +18.34% F1 assumes the masks contain no systematic false-positive/negative structure; without quantitative analysis of mask error patterns on held-out editing pairs or comparison against oracle masks, this assumption is unverified and load-bearing for the dataset-utility conclusion.
- [§4] §4 (Experiments): the reported quantitative gains do not indicate whether they are means over multiple random seeds, whether error bars are shown, or whether statistical significance tests were performed; this detail is required to substantiate the benchmark and downstream claims.
minor comments (2)
- [§3.1] Notation for the bidirectional cross-modal refinement module is introduced without an explicit equation or diagram reference in the method section, making the precise injection of the spatial prior difficult to follow.
- [Abstract] The abstract states that the full codebase will be released, but the manuscript does not specify the exact license or repository URL placeholder that will be used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, acknowledging where the manuscript is incomplete and committing to revisions that strengthen the claims without misrepresentation.
read point-by-point responses
-
Referee: [§4 and Table 2] §4 (Experiments) and Table 2: the central claim of +12.20% F1 / +11.16% IoU superiority rests on the two-stage pipeline reliably amplifying only faithful edits; however, the manuscript provides no ablation isolating the contribution of the edit-noise disentanglement loss versus the VAE-roundtrip calibration, leaving open whether residual diffusion artifacts correlated with edits remain.
Authors: We agree that an explicit ablation isolating the edit-noise disentanglement loss from the VAE-roundtrip calibration is missing and would better substantiate that only faithful edits are amplified. The current manuscript treats Stage II as a joint procedure addressing complementary aspects of domain shift. We will add this ablation study to the revised version, reporting incremental contributions of each term. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 (Stage II) and downstream results in §4.3: the claim that the generated 1.1M masks improve six detectors by +18.34% F1 assumes the masks contain no systematic false-positive/negative structure; without quantitative analysis of mask error patterns on held-out editing pairs or comparison against oracle masks, this assumption is unverified and load-bearing for the dataset-utility conclusion.
Authors: The referee correctly identifies that the manuscript relies on indirect evidence from downstream gains rather than direct mask-quality diagnostics. No quantitative error-pattern analysis or oracle comparison is present. We will add such an analysis on held-out pairs in the revision to directly verify the masks. revision: yes
-
Referee: [§4] §4 (Experiments): the reported quantitative gains do not indicate whether they are means over multiple random seeds, whether error bars are shown, or whether statistical significance tests were performed; this detail is required to substantiate the benchmark and downstream claims.
Authors: The reported numbers are from single runs; the manuscript does not state this or provide error bars or significance tests. We will add explicit clarification of the single-run nature and, where additional compute permits, include multi-seed means, standard deviations, and significance tests in the revision. revision: partial
Circularity Check
No significant circularity detected in the presented derivation
full rationale
The abstract and method description outline semantic-feature differencing in a vision backbone, bidirectional cross-modal refinement for injecting an instruction-derived spatial prior, and two-stage training (Stage I inpainting supervision; Stage II VAE-roundtrip calibration, EMA self-training, edit-noise disentanglement). No equations, fitted parameters renamed as predictions, or self-citations are quoted that would reduce any claimed output (e.g., the +12.20% F1 gains or the ~1.1M dataset) to inputs by construction. The performance numbers are presented as empirical results on external benchmarks and downstream detectors rather than tautological re-expressions of training losses or prior author results. The central pipeline therefore remains self-contained against external evaluation and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. InstructPix2Pix: Learning To Follow Image Editing Instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023
2023
-
[2]
Prompt-to-Prompt Image Editing with Cross-Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-Prompt Image Editing with Cross-Attention Control. InThe Eleventh International Conference on Learning Representations, September 2022
2022
-
[3]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Di Chang, Mingdeng Cao, Yichun Shi, Bo Liu, Shengqu Cai, Shijie Zhou, Weilin Huang, Gordon Wetzstein, Mohammad Soleymani, and Peng Wang. Bytemorph: Benchmarking instruction-guided image editing with non-rigid motions.arXiv preprint arXiv:2506.03107, 2025
-
[8]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26125–26135, 2025
2025
-
[9]
Sida: Social media image deepfake detection, localiza- tion and explanation with large multimodal model
Zhenglin Huang, Jinwei Hu, Xiangtai Li, Yiwei He, Xingyu Zhao, Bei Peng, Baoyuan Wu, Xiaowei Huang, and Guangliang Cheng. Sida: Social media image deepfake detection, localiza- tion and explanation with large multimodal model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28831–28841, 2025
2025
-
[10]
Rethinking image editing detection in the era of generative ai revolution
Zhihao Sun, Haipeng Fang, Juan Cao, Xinying Zhao, and Danding Wang. Rethinking image editing detection in the era of generative ai revolution. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3538–3547, 2024
2024
-
[11]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
2024
-
[12]
ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features
Yue Wu, Wael AbdAlmageed, and Premkumar Natarajan. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9543–9552, 2019. 10
2019
-
[13]
TruFor: Leveraging All-Round Clues for Trustworthy Image Forgery Detection and Localization
Fabrizio Guillaro, Davide Cozzolino, Avneesh Sud, Nicholas Dufour, and Luisa Verdoliva. TruFor: Leveraging All-Round Clues for Trustworthy Image Forgery Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20606–20615, 2023
2023
-
[14]
Hi- erarchical Fine-Grained Image Forgery Detection and Localization
Xiao Guo, Xiaohong Liu, Zhiyuan Ren, Steven Grosz, Iacopo Masi, and Xiaoming Liu. Hi- erarchical Fine-Grained Image Forgery Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3155–3165, 2023
2023
-
[15]
DiffForensics: Leveraging Diffusion Prior to Image Forgery Detection and Localization
Zeqin Yu, Jiangqun Ni, Yuzhen Lin, Haoyi Deng, and Bin Li. DiffForensics: Leveraging Diffusion Prior to Image Forgery Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12765–12774, 2024
2024
-
[16]
Lei Su, Xiaochen Ma, Xuekang Zhu, Chaoqun Niu, Zeyu Lei, and Ji-Zhe Zhou. Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization Through Spare-Coding Transformer.Proceedings of the AAAI Conference on Artificial Intelligence, 39(7):7024–7032, 2025
2025
-
[17]
FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, and Jian Zhang. FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models. InThe Thirteenth International Conference on Learning Representations, October 2024
2024
-
[18]
ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipu- lation Detection
Zhihao Sun, Haoran Jiang, Haoran Chen, Yixin Cao, Xipeng Qiu, Zuxuan Wu, and Yu-Gang Jiang. ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipu- lation Detection. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
Legion: Learning to ground and explain for synthetic image detection
Hengrui Kang, Siwei Wen, Zichen Wen, Junyan Ye, Weijia Li, Peilin Feng, Baichuan Zhou, Bin Wang, Dahua Lin, Linfeng Zhang, et al. Legion: Learning to ground and explain for synthetic image detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18937–18947, 2025
2025
-
[20]
Hsu and S
Y . Hsu and S. Chang. Detecting image splicing using geometry invariants and camera character- istics consistency. InIEEE Inter. Conf. Multim. Expo, pages 549–552. IEEE, 2006
2006
-
[21]
J. Dong, W. Wang, and T. Tan. Casia image tampering detection evaluation database. InIEEE China Summit Inter. Conf. Signal Info. Proc., pages 422–426, 2013
2013
-
[22]
IMD2020: A large-scale annotated dataset tailored for detecting manipulated images
Adam Novozamsky, Babak Mahdian, and Stanislav Saic. IMD2020: A large-scale annotated dataset tailored for detecting manipulated images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, pages 71–80, 2020
2020
-
[23]
DEFACTO: Image and face manipulation dataset
Gaël Mahfoudi, Badr Tajini, Florent Retraint, Frederic Morain-Nicolier, Jean Luc Dugelay, and PIC Marc. DEFACTO: Image and face manipulation dataset. InProceedings of the European Signal Processing Conference, pages 1–5, 2019
2019
-
[24]
AutoSplice: A Text-Prompt Manipulated Image Dataset for Media Forensics
Shan Jia, Mingzhen Huang, Zhou Zhou, Yan Ju, Jialing Cai, and Siwei Lyu. AutoSplice: A Text-Prompt Manipulated Image Dataset for Media Forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 893–903, 2023
2023
-
[25]
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
2023
-
[26]
Rui Zhang, Hongxia Wang, Hangqing Liu, Yang Zhou, and Qiang Zeng. Deal-300k: Diffusion- based editing area localization with a 300k-scale dataset and frequency-prompted baseline. arXiv preprint arXiv:2511.23377, 2025
-
[27]
OpenSDI: Spotting Diffusion-Generated Images in the Open World
Yabin Wang, Zhiwu Huang, and Xiaopeng Hong. OpenSDI: Spotting Diffusion-Generated Images in the Open World. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4291–4301, 2025. 11
2025
-
[28]
Wele Gedara Chaminda Bandara and Vishal M. Patel. A Transformer-Based Siamese Network for Change Detection. InIGARSS 2022 - 2022 IEEE International Geoscience and Remote Sensing Symposium, pages 207–210, 2022
2022
-
[29]
Combining SAM With Limited Data for Change Detection in Remote Sensing.IEEE Transactions on Geoscience and Remote Sensing, 63:1–11, 2025
Junyu Gao, Da Zhang, Feiyu Wang, Lichen Ning, Zhiyuan Zhao, and Xuelong Li. Combining SAM With Limited Data for Change Detection in Remote Sensing.IEEE Transactions on Geoscience and Remote Sensing, 63:1–11, 2025
2025
-
[30]
Wele Gedara Chaminda Bandara, Nithin Gopalakrishnan Nair, and Vishal M. Patel. DDPM-CD: Denoising Diffusion Probabilistic Models as Feature Extractors for Remote Sensing Change Detection. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5250–5262, 2025
2025
-
[31]
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[33]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Wei Chow, Linfeng Li, Lingdong Kong, Zefeng Li, Qi Xu, Hang Song, Tian Ye, Xian Wang, Jinbin Bai, Shilin Xu, et al. Editmgt: Unleashing potentials of masked generative transformers in image editing.arXiv preprint arXiv:2512.11715, 2025
-
[35]
Omniedit: Building image editing generalist models through specialist supervision
Cong Wei, Zheyang Xiong, Weiming Ren, Xeron Du, Ge Zhang, and Wenhu Chen. Omniedit: Building image editing generalist models through specialist supervision. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[36]
Promptfix: You prompt and we fix the photo.Advances in Neural Information Processing Systems, 37:40000–40031, 2024
Yongsheng Yu, Ziyun Zeng, Hang Hua, Jianlong Fu, and Jiebo Luo. Promptfix: You prompt and we fix the photo.Advances in Neural Information Processing Systems, 37:40000–40031, 2024
2024
-
[37]
Zooming in on fakes: A novel dataset for localized ai-generated image detection with forgery amplification approach
Lvpan Cai, Haowei Wang, Jiayi Ji, Yanshu Zhoumen, Shen Chen, Taiping Yao, and Xiaoshuai Sun. Zooming in on fakes: A novel dataset for localized ai-generated image detection with forgery amplification approach. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2534–2542, 2026
2026
-
[38]
CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing
Myung-Joon Kwon, In-Jae Yu, Seung-Hun Nam, and Heung-Kyu Lee. CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing. In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 375–384, 2021
2021
-
[39]
MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3539–3553, March 2023
Chengbo Dong, Xinru Chen, Ruohan Hu, Juan Cao, and Xirong Li. MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3539–3553, March 2023
2023
-
[40]
Al Hammadi, and Jizhe Zhou
Xiaochen Ma, Bo Du, Zhuohang Jiang, Xia Du, Ahmed Y . Al Hammadi, and Jizhe Zhou. IML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer, November 2024
2024
-
[41]
Xiaohong Liu, Yaojie Liu, Jun Chen, and Xiaoming Liu. Pscc-net: Progressive spatio-channel correlation network for image manipulation detection and localization.IEEE Transactions on Circuits and Systems for Video Technology, 32(11):7505–7517, 2022. 12
2022
-
[42]
Towards generalizable and robust image tampering localization with multi-task learning and contrastive learning.Expert Systems with Applications, 270:126492, April 2025
Haodong Li, Peiyu Zhuang, Yang Su, and Jiwu Huang. Towards generalizable and robust image tampering localization with multi-task learning and contrastive learning.Expert Systems with Applications, 270:126492, April 2025
2025
-
[43]
remove the cat
Xiaochen Ma, Xuekang Zhu, Lei Su, Bo Du, Zhuohang Jiang, Bingkui Tong, Zeyu Lei, Xinyu Yang, Chi-Man Pun, Jiancheng Lv, et al. Imdl-benco: A comprehensive benchmark and codebase for image manipulation detection & localization.Advances in Neural Information Processing Systems, 37:134591–134613, 2025. A Scale Disparity between Image Editing and IML Datasets...
2025
-
[44]
add a bird
"global" Definitions: - add: a new object/concept is introduced. - remove: an existing object/concept is deleted. - attribute change: same object identity, only attribute/state/color/pose/ expression/action/style detail changes. - replace: one object/concept is swapped with another object/concept. - global: whole-image change (e.g., weather, season, style...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.